Pushdown agrégé groupé
Envoi de données SentryOne au calculateur DTU Azure SQL Database
Journalisation minimale avec INSERT…SELECT dans les tables Heap
Introduction aux statistiques d'attente
Match le plus proche, partie 1
Améliorer les performances des UDF avec NULL ON NULL INPUT
Utiliser le suivi de la causalité pour comprendre l'exécution des requêtes
Match le plus proche, partie 2
Cloner des bases de données avec PSDatabaseClone
Introduction aux niveaux de compatibilité et à l'estimation de la cardinalité
Match le plus proche, partie 3
Migrer d'AnswerHub vers WordPress :Une histoire de 10 technologies
T-SQL Tuesday #106 :déclencheurs INSTEAD OF
Îles spéciales
Que faire (ou ne pas faire) concernant les principales statistiques d'attente
Solutions de lecteur au défi des îles spéciales
Comprendre les vidages de tampon de journal
Seuils d'optimisation – Regroupement et agrégation de données, partie 2
L'importance des lignes de base
Seuils d'optimisation – Regroupement et agrégation de données, partie 3
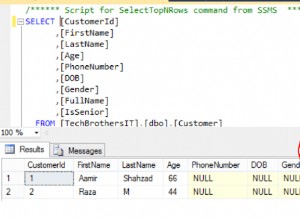
Comment ajouter une colonne calculée dans la table SQL Server - Tutoriel SQL Server / T-SQL Partie 47
Sqlserver
Répartition d'Oracle Cloud – Coûts d'hébergement de base de données sur OCI
Oracle
En regardant la base de données sur heroku
PostgreSQL
Comment migrer des travaux SQL Server d'une instance SQL Server vers une autre
Sqlserver
Connectez-vous à une base de données heroku avec pgadmin
PostgreSQL
Comment utiliser la fonction SQL SUM
Database