Cet article est le troisième d'une série sur les seuils d'optimisation pour le regroupement et l'agrégation des données. Dans la partie 1, j'ai couvert l'algorithme Stream Aggregate pré-ordonné. Dans la partie 2, j'ai couvert l'algorithme Sort + Stream Aggregate non préordonné. Dans cette partie, je couvre l'algorithme Hash Match (Aggregate), que j'appellerai simplement Hash Aggregate. Je fournis également un résumé et une comparaison entre les algorithmes que je couvre dans la partie 1, la partie 2 et la partie 3.
J'utiliserai le même exemple de base de données appelé PerformanceV3, que j'ai utilisé dans les articles précédents de la série. Assurez-vous simplement qu'avant d'exécuter les exemples de l'article, vous exécutez d'abord le code suivant pour supprimer quelques index inutiles :
SUPPRIMER L'INDEX idx_nc_sid_od_cid SUR dbo.Orders ;SUPPRIMER L'INDEX idx_unc_od_oid_i_cid_eid SUR dbo.Orders ;
Les deux seuls index qui doivent rester sur cette table sont idx_cl_od (cluster avec orderdate comme clé) et PK_Orders (non cluster avec orderid comme clé).
Agrégat de hachage
L'algorithme Hash Aggregate organise les groupes dans une table de hachage basée sur une fonction de hachage choisie en interne. Contrairement à l'algorithme Stream Aggregate, il n'a pas besoin de consommer les lignes dans l'ordre du groupe. Considérez la requête suivante (nous l'appellerons la requête 1) comme exemple (forçant un agrégat de hachage et un plan de série) :
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
La figure 1 montre le plan pour la requête 1.
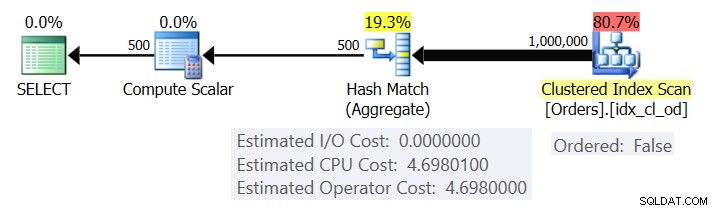
Figure 1 :Plan pour la requête 1
Le plan analyse les lignes de l'index clusterisé à l'aide d'une propriété Ordered :False (l'analyse n'est pas nécessaire pour fournir les lignes ordonnées par la clé d'index). Typiquement, l'optimiseur préfère balayer l'index de couverture le plus étroit, qui dans notre cas se trouve être l'index clusterisé. Le plan construit une table de hachage avec les colonnes groupées et les agrégats. Notre requête demande un agrégat COUNT de type INT. Le plan le calcule en fait comme une valeur de type BIGINT, d'où l'opérateur Compute Scalar, appliquant une conversion implicite en INT.
Microsoft ne partage pas publiquement les algorithmes de hachage qu'ils utilisent. Il s'agit d'une technologie très propriétaire. Néanmoins, afin d'illustrer le concept, supposons que SQL Server utilise la fonction de hachage % 250 (modulo 250) pour notre requête ci-dessus. Avant de traiter les lignes, notre table de hachage contient 250 compartiments représentant les 250 résultats possibles de la fonction de hachage (0 à 249). Lorsque SQL Server traite chaque ligne, il applique la fonction de hachage
orderid empid ------- ----- 320 330 5660 253820 3850 11000 255700 31240 253350 4400 255
La figure 2 montre trois états de la table de hachage :avant le traitement des lignes, après le traitement des 5 premières lignes et après le traitement des 10 premières lignes. Chaque élément de la liste liée contient le tuple (empid, COUNT(*)).
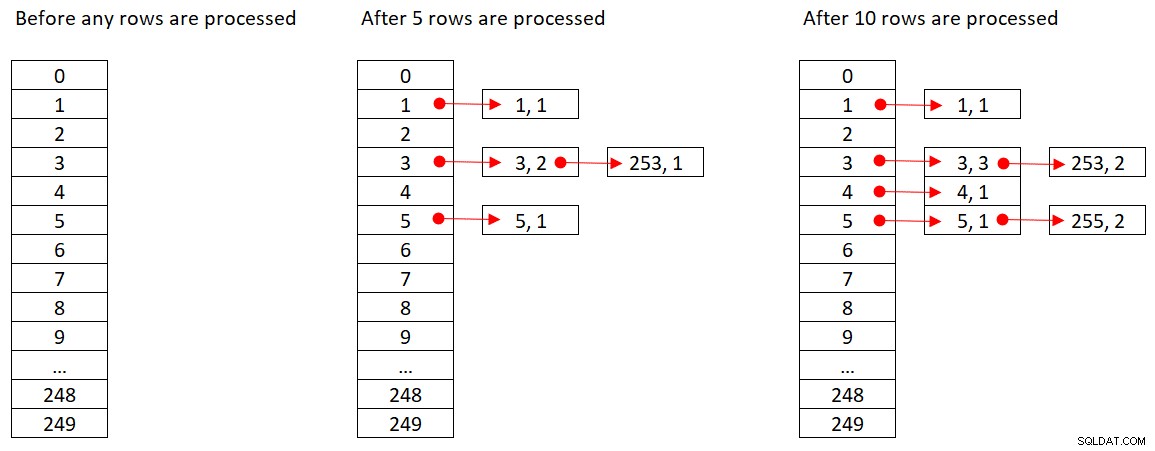
Figure 2 :États de la table de hachage
Une fois que l'opérateur Hash Aggregate a fini de consommer toutes les lignes d'entrée, la table de hachage contient tous les groupes avec l'état final de l'agrégat.
Comme l'opérateur Sort, l'opérateur Hash Aggregate nécessite une allocation de mémoire, et s'il manque de mémoire, il doit se répandre sur tempdb; cependant, alors que le tri nécessite une allocation de mémoire proportionnelle au nombre de lignes à trier, le hachage nécessite une allocation de mémoire proportionnelle au nombre de groupes. Ainsi, en particulier lorsque l'ensemble de regroupement a une densité élevée (petit nombre de groupes), cet algorithme nécessite beaucoup moins de mémoire que lorsqu'un tri explicite est requis.
Considérez les deux requêtes suivantes (appelez-les Requête 1 et Requête 2) :
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
La figure 3 compare les allocations de mémoire pour ces requêtes.

Figure 3 :Plans pour la requête 1 et la requête 2
Notez la grande différence entre les allocations de mémoire dans les deux cas.
En ce qui concerne le coût de l'opérateur Hash Aggregate, en revenant à la figure 1, notez qu'il n'y a pas de coût d'E/S, mais uniquement un coût CPU. Ensuite, essayez de désosser la formule de coût du processeur en utilisant des techniques similaires à celles que j'ai couvertes dans les parties précédentes de la série. Les facteurs qui peuvent potentiellement affecter le coût de l'opérateur sont le nombre de lignes d'entrée, le nombre de groupes de sortie, la fonction d'agrégation utilisée et ce que vous regroupez (cardinalité de l'ensemble de regroupement, types de données utilisés).
Vous vous attendez à ce que cet opérateur ait un coût de démarrage en préparation de la construction de la table de hachage. Vous vous attendez également à ce qu'il évolue de manière linéaire par rapport au nombre de lignes et de groupes. C'est effectivement ce que j'ai trouvé. Cependant, alors que les coûts des opérateurs Stream Aggregate et Sort ne sont pas affectés par ce que vous regroupez, il semble que le coût de l'opérateur Hash Aggregate l'est, à la fois en termes de cardinalité de l'ensemble de regroupement et des types de données utilisés.
Pour observer que la cardinalité de l'ensemble de regroupement affecte le coût de l'opérateur, vérifiez les coûts CPU des opérateurs Hash Aggregate dans les plans pour les requêtes suivantes (appelez-les Requête 3 et Requête 4) :
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1 );
Bien sûr, vous voulez vous assurer que le nombre estimé de lignes d'entrée et de groupes de sortie est le même dans les deux cas. Les plans estimés pour ces requêtes sont illustrés à la figure 4.
Figure 4 :Plans pour la requête 3 et la requête 4
Comme vous pouvez le voir, le coût CPU de l'opérateur Hash Aggregate est de 0,16903 lors du regroupement par une colonne entière et de 0,174016 lors du regroupement par deux colonnes entières, toutes choses étant égales par ailleurs. Cela signifie que la cardinalité de l'ensemble de regroupement affecte effectivement le coût.
Quant à savoir si le type de données de l'élément groupé affecte le coût, j'ai utilisé les requêtes suivantes pour vérifier cela (appelez-les Query 5, Query 6 et Query 7) :
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT CAST (id de commande AS BIGINT) % CAST (1000 AS BIGINT) AS grp, MAX (date de commande) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST (id de commande AS BIGINT) % CAST (1000 AS BIGINT) OPTION(HASH GROUP, MAXDOP 1);
Les plans pour les trois requêtes ont le même nombre estimé de lignes d'entrée et de groupes de sortie, mais ils obtiennent tous des coûts CPU estimés différents (0,121766, 0,16903 et 0,171716), par conséquent, le type de données utilisé affecte le coût.
Le type de fonction d'agrégat semble également avoir un impact sur le coût. Par exemple, considérez les deux requêtes suivantes (appelez-les Requête 8 et Requête 9) :
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Le coût CPU estimé pour l'agrégat de hachage dans le plan pour la requête 8 est de 0,166344 et dans la requête 9 est de 0,16903.
Il pourrait être intéressant d'essayer de déterminer exactement de quelle manière la cardinalité de l'ensemble de regroupement, les types de données et la fonction d'agrégat utilisée affectent le coût ; Je n'ai tout simplement pas approfondi cet aspect du coût. Ainsi, après avoir choisi l'ensemble de regroupement et la fonction d'agrégation pour votre requête, vous pouvez procéder à l'ingénierie inverse de la formule d'établissement des coûts. Par exemple, procédons à l'ingénierie inverse de la formule de coût du processeur pour l'opérateur Hash Aggregate lors du regroupement par une seule colonne d'entiers et du renvoi de l'agrégat MAX(orderdate). La formule devrait être :
Coût CPU de l'opérateur =En utilisant les techniques que j'ai démontrées dans les articles précédents de la série, j'ai obtenu la formule de rétro-ingénierie suivante :
Coût CPU de l'opérateur =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Vous pouvez vérifier l'exactitude de la formule à l'aide des requêtes suivantes :
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
J'obtiens les résultats suivants :
numrows numgroups predictedcost estimatecost----------- ----------- -------------- ------- ------- 100000 1000 0.703315 0.703316100000 2000 0.721023 0.721024200000 3000 1.40659 1.40659200000 6000 1.45972 1.45972500000La formule semble être parfaite.
Résumé et comparaison des coûts
Nous avons maintenant les formules de coût pour les trois stratégies disponibles :Stream Aggregate précommandé, Sort + Stream Aggregate et Hash Aggregate. Le tableau suivant résume et compare les caractéristiques de coût des trois algorithmes :
| Formule | @numrows * 0.0000006 + @numgroups * 0.0000005 | 0.0112613 + Petit nombre de lignes : 9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06 Grand nombre de lignes : 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0.0000006 + @numgroups * 0.0000005 | 0.017749 + @numrows * 0.00000667857 + @numgroups * 0.0000177087
* Regroupement par colonne d'entier unique, renvoyant MAX( |
| Mise à l'échelle | linéaire | n log n | linéaire |
| Coût d'E/S de démarrage | aucun | 0.0112613 | aucun |
| Coût du processeur de démarrage | aucun | ~ 0.0001 | 0.017749 |
Selon ces formules, la figure 5 montre la façon dont chacune des stratégies évolue pour différents nombres de lignes d'entrée, en utilisant un nombre fixe de groupes de 500 comme exemple.
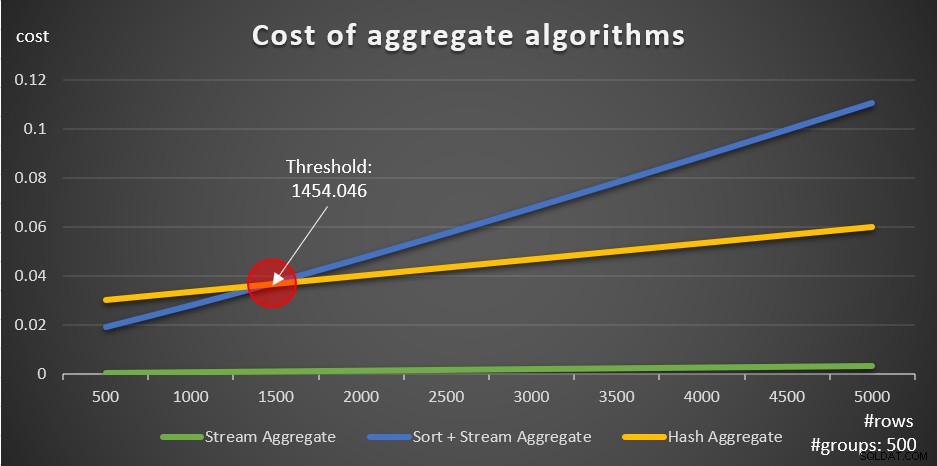
Figure 5 :Coût des algorithmes d'agrégation
Vous pouvez clairement voir que si les données sont pré-ordonnées, par exemple, dans un index de couverture, la stratégie pré-ordonnée Stream Aggregate est la meilleure option, quel que soit le nombre de lignes impliquées. Par exemple, supposons que vous deviez interroger la table Orders et calculer la date de commande maximale pour chaque employé. Vous créez l'index de recouvrement suivant :
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
Voici cinq requêtes, émulant une table Orders avec différents nombres de lignes (10 000, 20 000, 30 000, 40 000 et 50 000) :
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
La figure 6 montre les plans de ces requêtes.
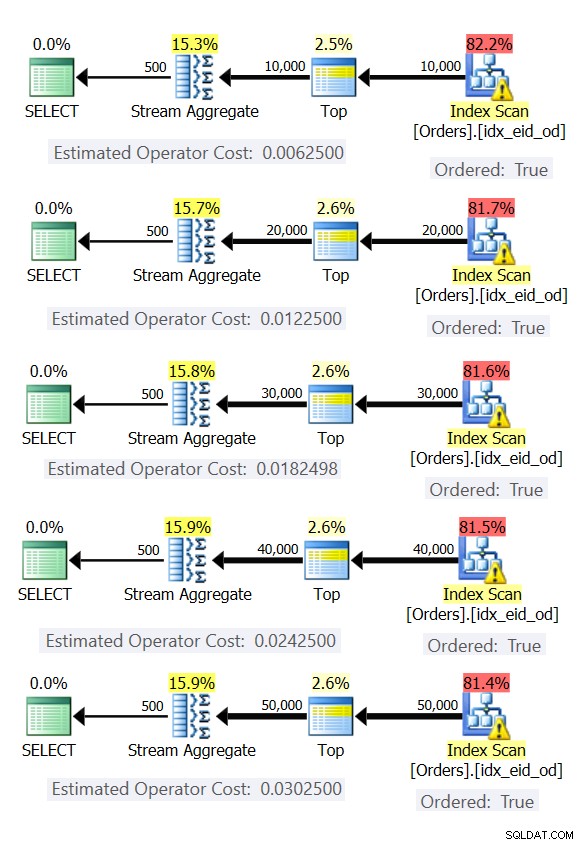
Figure 6 :Plans avec stratégie Stream Aggregate précommandée
Dans tous les cas, les plans effectuent une analyse ordonnée de l'index de couverture et appliquent l'opérateur Stream Aggregate sans avoir besoin d'un tri explicite.
Utilisez le code suivant pour supprimer l'index que vous avez créé pour cet exemple :
DÉPOSER L'INDEX idx_eid_od SUR dbo.Orders ;
L'autre chose importante à noter à propos des graphiques de la figure 5 est ce qui se passe lorsque les données ne sont pas préordonnées. Cela se produit lorsqu'il n'y a pas d'index de couverture en place, ainsi que lorsque vous regroupez par expressions manipulées par opposition aux colonnes de base. Il existe un seuil d'optimisation - dans notre cas à 1454,046 lignes - en dessous duquel la stratégie Sort + Stream Aggregate a un coût inférieur, et sur ou au-dessus duquel la stratégie Hash Aggregate a un coût inférieur. Cela est dû au fait que le premier a un coût de démarrage inférieur, mais évolue de manière n log n, tandis que le second a un coût de démarrage plus élevé mais évolue de manière linéaire. Cela rend le premier préféré avec un petit nombre de lignes d'entrée. Si nos formules de rétro-ingénierie sont exactes, les deux requêtes suivantes (appelez-les Requête 10 et Requête 11) devraient obtenir des plans différents :
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Les plans de ces requêtes sont illustrés à la figure 7.
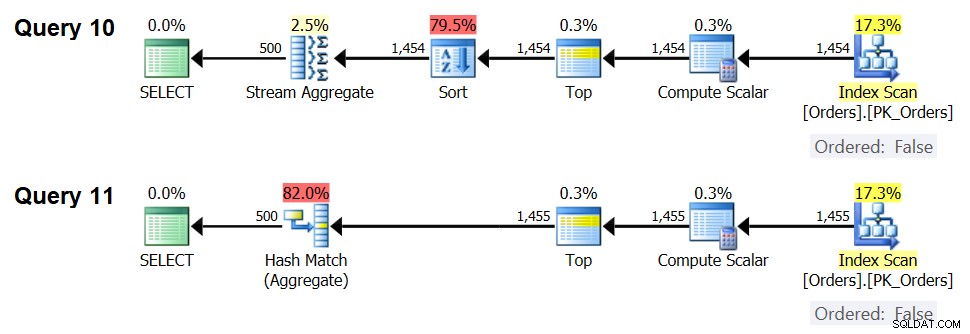
Figure 7 :Plans pour la requête 10 et la requête 11
En effet, avec 1 454 lignes d'entrée (en dessous du seuil d'optimisation), l'optimiseur préfère naturellement l'algorithme Sort + Stream Aggregate pour la requête 10, et avec 1 455 lignes d'entrée (au-dessus du seuil d'optimisation), l'optimiseur préfère naturellement l'algorithme Hash Aggregate pour la requête 11 .
Potentiel pour l'opérateur Adaptive Aggregate
L'un des aspects délicats des seuils d'optimisation réside dans les problèmes de détection de paramètres lors de l'utilisation de requêtes sensibles aux paramètres dans des procédures stockées. Considérez la procédure stockée suivante comme exemple :
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INTAS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid>=@initialorderid GROUP BY empid;GO
Vous créez l'index optimal suivant pour prendre en charge la requête de procédure stockée :
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
Vous avez créé l'index avec orderid comme clé pour prendre en charge le filtre de plage de la requête et inclus empid pour la couverture. Il s'agit d'une situation dans laquelle vous ne pouvez pas vraiment créer un index qui prend en charge à la fois le filtre de plage et dont les lignes filtrées sont préordonnées par l'ensemble de regroupement. Cela signifie que l'optimiseur devra faire un choix entre les algorithmes Sort + stream Aggregate et Hash Aggregate. D'après nos formules d'établissement des coûts, le seuil d'optimisation se situe entre 937 et 938 lignes d'entrée (disons, 937,5 lignes).
Supposons que vous exécutiez la procédure stockée pour la première fois avec un ID de commande initial d'entrée qui vous donne un petit nombre de correspondances (inférieur au seuil) :
EXEC dbo.EmpOrders @initialorderid =999991 ;
SQL Server produit un plan qui utilise l'algorithme Sort + Stream Aggregate et met le plan en cache. Les exécutions suivantes réutilisent le plan mis en cache, quel que soit le nombre de lignes impliquées. Par exemple, l'exécution suivante a un nombre de correspondances au-dessus du seuil d'optimisation :
EXEC dbo.EmpOrders @initialorderid =990001 ;
Pourtant, il réutilise le plan mis en cache malgré le fait qu'il n'est pas optimal pour cette exécution. C'est un problème classique de détection de paramètres.
SQL Server 2017 introduit des fonctionnalités de traitement adaptatif des requêtes, conçues pour faire face à de telles situations en déterminant lors de l'exécution de la requête la stratégie à utiliser. Parmi ces améliorations figure un opérateur de jointure adaptative qui, lors de l'exécution, détermine s'il faut activer un algorithme de boucle ou de hachage en fonction d'un seuil d'optimisation calculé. Notre histoire d'agrégation demande un opérateur d'agrégation adaptatif similaire, qui, lors de l'exécution, ferait un choix entre une stratégie d'agrégation de tri + flux et une stratégie d'agrégation de hachage, basée sur un seuil d'optimisation calculé. La figure 8 illustre un pseudo plan basé sur cette idée.
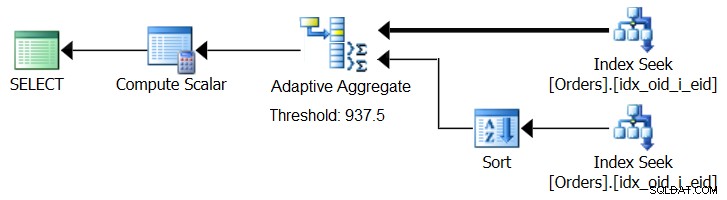
Figure 8 :Pseudo plan avec opérateur Adaptive Aggregate
Pour l'instant, pour obtenir un tel plan, vous devez utiliser Microsoft Paint. Mais comme le concept de traitement adaptatif des requêtes est si intelligent et fonctionne si bien, il est raisonnable de s'attendre à voir d'autres améliorations dans ce domaine à l'avenir.
Exécutez le code suivant pour supprimer l'index que vous avez créé pour cet exemple :
DÉPOSER L'INDEX idx_oid_i_eid SUR dbo.Orders ;
Conclusion
Dans cet article, j'ai couvert le coût et la mise à l'échelle de l'algorithme Hash Aggregate et je l'ai comparé avec les stratégies Stream Aggregate et Sort + Stream Aggregate. J'ai décrit le seuil d'optimisation qui existe entre les stratégies Sort + Stream Aggregate et Hash Aggregate. Avec un petit nombre de lignes d'entrée, le premier est préféré et avec un grand nombre de lignes, le second. J'ai également décrit la possibilité d'ajouter un opérateur Adaptive Aggregate, similaire à l'opérateur Adaptive Join déjà implémenté, pour aider à gérer les problèmes de détection de paramètres lors de l'utilisation de requêtes sensibles aux paramètres. Le mois prochain, je poursuivrai la discussion en abordant les considérations de parallélisme et les cas nécessitant des réécritures de requêtes.