Le mois dernier, j'ai couvert un défi des îles spéciales. La tâche consistait à identifier les périodes d'activité pour chaque ID de service, en tolérant un écart allant jusqu'à un nombre de secondes d'entrée (@allowedgap ). La mise en garde était que la solution devait être compatible avec les versions antérieures à 2012, vous ne pouviez donc pas utiliser des fonctions telles que LAG et LEAD, ou des fonctions de fenêtre agrégées avec un cadre. J'ai reçu un certain nombre de solutions très intéressantes publiées dans les commentaires de Toby Ovod-Everett, Peter Larsson et Kamil Kosno. Assurez-vous de passer en revue leurs solutions car elles sont toutes très créatives.
Curieusement, un certain nombre de solutions s'exécutaient plus lentement avec l'index recommandé que sans. Dans cet article, je propose une explication à cela.
Même si toutes les solutions étaient intéressantes, je voulais ici me concentrer sur la solution de Kamil Kosno, qui est développeur ETL chez Zopa. Dans sa solution, Kamil a utilisé une technique très créative pour émuler LAG et LEAD sans LAG ni LEAD. Vous trouverez probablement cette technique pratique si vous devez effectuer des calculs de type LAG/LEAD à l'aide d'un code compatible avec les versions antérieures à 2012.
Pourquoi certaines solutions sont-elles plus rapides sans l'index recommandé ?
Pour rappel, j'ai suggéré d'utiliser l'index suivant pour soutenir les solutions au défi :
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Ma solution compatible avant 2012 était la suivante :
DECLARER @allowedgap AS INT =66 ; -- en secondes WITH C1 AS( SELECT logid, serviceid, logtime AS s, -- important, 's'> 'e', pour une commande ultérieure DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog),C2 AS( SELECT logid, serviceid, logtime, eventtype, counteach, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth FROM C1 UNPIVOT(logtime FOR eventtype IN (s, e)) AS U),C3 AS( SELECT serviceid, eventtype, logtime, (ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp FROM C2 CROSS APPLY ( VALUES( CASE WHEN eventtype ='s' THEN counteach - (countboth - counteach) WHEN eventtype ='e' THEN (countboth - counteach) - counteach END ) ) AS A(countactive) WHERE ( eventtype ='s' AND countactive =1) OR (eventtype ='e' AND countactive =0))SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtimeFROM C3 PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P ;
La figure 1 présente le plan de ma solution avec l'index recommandé en place.
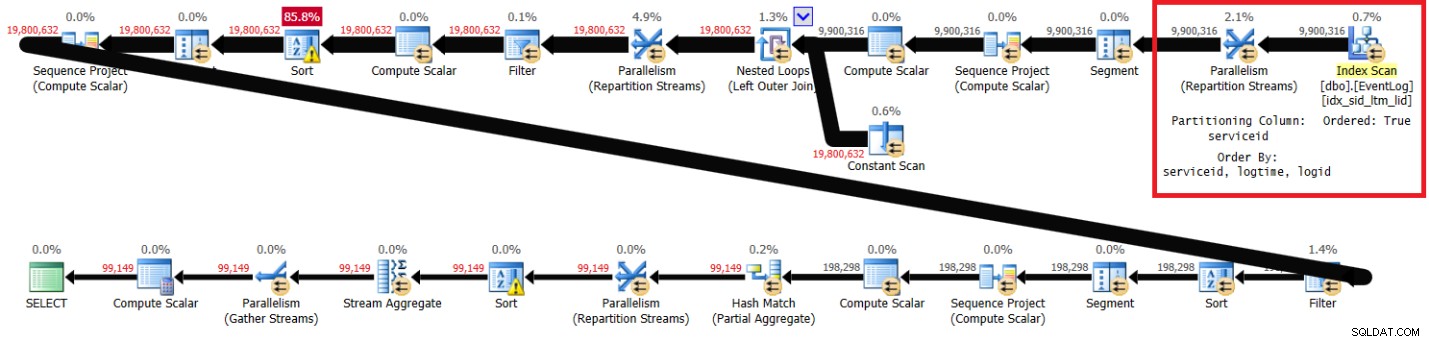 Figure 1 :Planifier la solution d'Itzik avec l'index recommandé
Figure 1 :Planifier la solution d'Itzik avec l'index recommandé
Notez que le plan analyse l'index recommandé dans l'ordre des clés (la propriété Ordered est True), partitionne les flux par serviceid à l'aide d'un échange préservant l'ordre, puis applique le calcul initial des numéros de ligne en fonction de l'ordre de l'index sans qu'il soit nécessaire de trier. Voici les statistiques de performances que j'ai obtenues pour l'exécution de cette requête sur mon ordinateur portable (temps écoulé, temps CPU et attente maximale exprimés en secondes) :
écoulé :43, CPU :60, lectures logiques :144 120, attente maximale :CXPACKET :166
J'ai ensuite supprimé l'index recommandé et relancé la solution :
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog ;
J'ai obtenu le plan illustré à la figure 2.
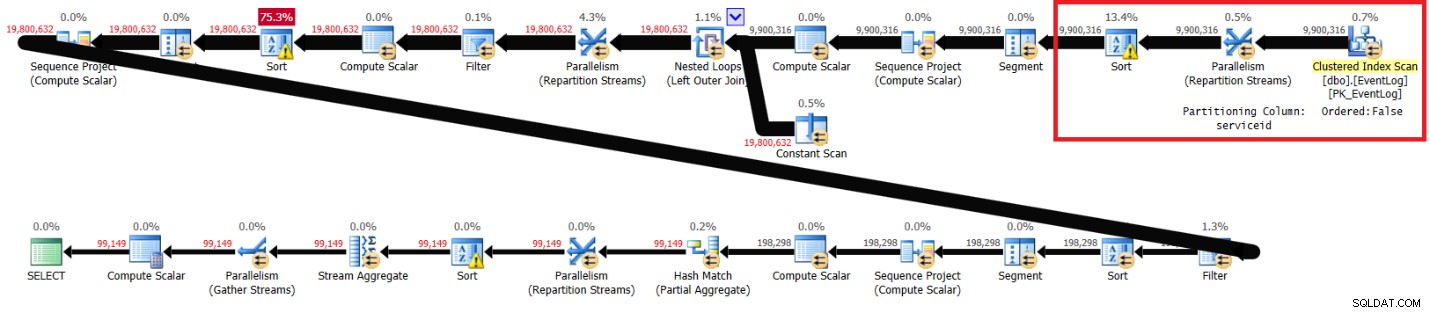 Figure 2 :Plan pour la solution d'Itzik sans index recommandé
Figure 2 :Plan pour la solution d'Itzik sans index recommandé
Les sections surlignées dans les deux plans montrent la différence. Le plan sans l'index recommandé effectue une analyse non ordonnée de l'index clusterisé, partitionne les flux par serviceid à l'aide d'un échange non préservant l'ordre, puis trie les lignes selon les besoins de la fonction de fenêtre (par serviceid, logtime, logid). Le reste du travail semble être le même dans les deux plans. On pourrait penser que le plan sans l'index recommandé devrait être plus lent car il a un tri supplémentaire que l'autre plan n'a pas. Mais voici les statistiques de performances que j'ai obtenues pour ce forfait sur mon ordinateur portable :
écoulé :31, CPU :89, lectures logiques :172 598, CXPACKET attend :84
Il y a plus de temps CPU impliqué, ce qui est en partie dû au tri supplémentaire; il y a plus d'E/S impliquées, probablement en raison de débordements de tri supplémentaires ; cependant, le temps écoulé est environ 30 % plus rapide. Qu'est-ce qui pourrait expliquer cela ? Une façon d'essayer de comprendre cela consiste à exécuter la requête dans SSMS avec l'option Live Query Statistics activée. Lorsque j'ai fait cela, l'opérateur Parallelism (Repartition Streams) le plus à droite a terminé en 6 secondes sans l'index recommandé et en 35 secondes avec l'index recommandé. La principale différence est que le premier obtient les données pré-ordonnées à partir d'un index et constitue un échange préservant l'ordre. Ce dernier obtient les données non ordonnées et n'est pas un échange préservant l'ordre. Les échanges préservant l'ordre ont tendance à être plus chers que ceux qui ne préservent pas l'ordre. De plus, au moins dans la partie la plus à droite du plan jusqu'au premier tri, le premier fournit les lignes dans le même ordre que la colonne de partitionnement d'échange, de sorte que tous les threads ne traitent pas vraiment les lignes en parallèle. Ce dernier fournit les lignes non ordonnées, de sorte que tous les threads traitent les lignes véritablement en parallèle. Vous pouvez voir que l'attente la plus élevée dans les deux plans est CXPACKET, mais dans le premier cas, le temps d'attente est le double de celui du second, ce qui vous indique que la gestion du parallélisme dans ce dernier cas est plus optimale. Il pourrait y avoir d'autres facteurs en jeu auxquels je ne pense pas. Si vous avez d'autres idées qui pourraient expliquer la surprenante différence de performances, n'hésitez pas à les partager.
Sur mon ordinateur portable, cela a entraîné une exécution sans que l'index recommandé soit plus rapide que celui avec l'index recommandé. Pourtant, sur une autre machine de test, c'était l'inverse. Après tout, vous avez un tri supplémentaire, avec un potentiel de déversement.
Par curiosité, j'ai testé une exécution en série (avec l'option MAXDOP 1) avec l'index recommandé en place, et j'ai obtenu les statistiques de performances suivantes sur mon ordinateur portable :
écoulé :42, CPU :40, lectures logiques :143 519
Comme vous pouvez le voir, le temps d'exécution est similaire au temps d'exécution de l'exécution parallèle avec l'index recommandé en place. Je n'ai que 4 processeurs logiques dans mon ordinateur portable. Bien sûr, votre kilométrage peut varier selon le matériel. Le fait est qu'il vaut la peine de tester différentes alternatives, y compris avec et sans l'indexation qui, selon vous, devrait aider. Les résultats sont parfois surprenants et contre-intuitifs.
La solution de Kamil
J'ai été vraiment intrigué par la solution de Kamil et j'ai particulièrement aimé la façon dont il émulait LAG et LEAD avec une technique compatible pré-2012.
Voici le code implémentant la première étape de la solution :
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_timeFROM dbo.EventLog ;
Ce code génère la sortie suivante (affichant uniquement les données pour serviceid 1) :
serviceid logtime end_time start_time---------- -------------------- --------- ---- -------1 2018-09-12 08:00:00 1 01 2018-09-12 08:01:01 2 11 2018-09-12 08:01:59 3 21 2018-09-12 08 :03:00 4 31 2018-09-12 08:05:00 5 41 2018-09-12 08:06:02 6 5...
Cette étape calcule deux numéros de ligne séparés pour chaque ligne, partitionnés par serviceid et classés par logtime. Le numéro de ligne actuel représente l'heure de fin (appelez-le end_time), et le numéro de ligne actuel moins un représente l'heure de début (appelez-le start_time).
Le code suivant implémente la deuxième étape de la solution :
WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U ;
Cette étape génère la sortie suivante :
serviceid logtime rownum time_type---------- -------------------- ------- ------ -----1 2018-09-12 08:00:00 0 start_time1 2018-09-12 08:00:00 1 end_time1 2018-09-12 08:01:01 1 start_time1 2018-09-12 08:01 :01 2 end_time1 2018-09-12 08:01:59 2 start_time1 2018-09-12 08:01:59 3 end_time1 2018-09-12 08:03:00 3 start_time1 2018-09-12 08:03:00 4 end_time1 2018-09-12 08:05:00 4 start_time1 2018-09-12 08:05:00 5 end_time1 2018-09-12 08:06:02 5 start_time1 2018-09-12 08:06:02 6 end_time ...
Cette étape divise chaque ligne en deux lignes, en dupliquant chaque entrée de journal, une fois pour le type d'heure start_time et une autre pour end_time. Comme vous pouvez le voir, outre les numéros de ligne minimum et maximum, chaque numéro de ligne apparaît deux fois :une fois avec l'heure de journalisation de l'événement en cours (start_time) et une autre avec l'heure de journalisation de l'événement précédent (end_time).
Le code suivant implémente la troisième étape de la solution :
WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P ;
Ce code génère la sortie suivante :
serviceid rownum start_time end_time----------- -------------------- ------------ --------------- ---------------------------1 0 2018-09-12 08 :00:00 NULL1 1 2018-09-12 08:01:01 2018-09-12 08:00:001 2 2018-09-12 08:01:59 2018-09-12 08:01:011 3 2018- 09-12 08:03:00 2018-09-12 08:01:591 4 2018-09-12 08:05:00 2018-09-12 08:03:001 5 2018-09-12 08:06:02 2018-09-12 08:05:001 6 NUL 2018-09-12 08:06:02...
Cette étape fait pivoter les données, en regroupant des paires de lignes avec le même numéro de ligne et en renvoyant une colonne pour l'heure actuelle du journal des événements (start_time) et une autre pour l'heure précédente du journal des événements (end_time). Cette partie émule efficacement une fonction LAG.
Le code suivant implémente la quatrième étape de la solution :
DECLARER @allowedgap AS INT =66 ; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grpFROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT( MAX(logtime) FOR time_type IN(start_time, end_time)) AS PWHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap;
Ce code génère la sortie suivante :
serviceid rownum start_time end_time start_time_grp end_time_grp---------- ------- -------------------- ---- ---------------- --------------- -------------1 0 2018-09- 12 08:00:00 NULL 1 01 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 11 6 NULL 2018-09-12 08:06:02 3 2...Cette étape filtre les paires où la différence entre l'heure de fin précédente et l'heure de début actuelle est supérieure à l'écart autorisé, et les lignes avec un seul événement. Vous devez maintenant connecter l'heure de début de chaque ligne actuelle à l'heure de fin de la ligne suivante. Cela nécessite un calcul de type LEAD. Pour y parvenir, le code, encore une fois, crée des numéros de ligne séparés, mais cette fois le numéro de ligne actuel représente l'heure de début (start_time_grp ) et le numéro de ligne actuel moins un représente l'heure de fin (end_time_grp).
Comme précédemment, l'étape suivante (numéro 5) consiste à dé-pivoter les lignes. Voici le code implémentant cette étape :
DECLARER @allowedgap AS INT =66 ; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Plages as ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT *FROM Ranges UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U ;Sortie :
serviceid rownum start_time end_time grp grp_type---------- ------- -------------------- ---- ---------------- ---- ---------------1 0 2018-09-12 08:00:00 NULL 0 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp1 0 2018-09-12 08:00:00 NULL 1 start_time_grp1 6 NULL 2018-09-12 08:06:02 2 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp1 6 NULL 2018-09-12 08:06:02 3 start_time_grp...Comme vous pouvez le constater, la colonne grp est unique pour chaque île au sein d'un ID de service.
L'étape 6 est la dernière étape de la solution. Voici le code implémentant cette étape, qui est également le code complet de la solution :
DECLARER @allowedgap AS INT =66 ; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Plages as ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT serviceid, MIN(start_time) AS start_time , MAX(end_time) AS end_timeFROM Ranges UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS UGROUP BY serviceid, grpHAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL);Cette étape génère la sortie suivante :
id_service start_time end_time----------- --------------------------- ------ ---------------------1 2018-09-12 08:00:00 2018-09-12 08:03:001 2018-09-12 08:05 :00 2018-09-12 08:06:02...Cette étape regroupe les lignes par serviceid et grp, filtre uniquement les groupes pertinents et renvoie l'heure de début minimale comme début de l'îlot et l'heure de fin maximale comme fin de l'îlot.
La figure 3 présente le plan que j'ai obtenu pour cette solution avec l'index recommandé :
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);Planifiez avec l'index recommandé dans la figure 3.
Figure 3 :Planifier la solution de Kamil avec l'index recommandé
Voici les statistiques de performances que j'ai obtenues pour cette exécution sur mon ordinateur portable :
écoulé :44, CPU :66, lectures logiques :72979, attente maximale :CXPACKET :148J'ai ensuite supprimé l'index recommandé et relancé la solution :
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog ;J'ai obtenu le plan illustré à la figure 4 pour l'exécution sans l'index recommandé.
Figure 4 :Plan pour la solution de Kamil sans index recommandé
Voici les statistiques de performances que j'ai obtenues pour cette exécution :
écoulé :30, CPU :85, lectures logiques :94 813, attente maximale :CXPACKET :70Les temps d'exécution, les temps CPU et les temps d'attente CXPACKET sont très similaires à ma solution, bien que les lectures logiques soient inférieures. La solution de Kamil s'exécute également plus rapidement sur mon ordinateur portable sans l'index recommandé, et il semble que cela soit dû à des raisons similaires.
Conclusion
Les anomalies sont une bonne chose. Ils vous rendent curieux et vous poussent à rechercher la cause profonde du problème et, par conséquent, à apprendre de nouvelles choses. Il est intéressant de voir que certaines requêtes, sur certaines machines, s'exécutent plus rapidement sans l'indexation recommandée.
Merci encore à Toby, Peter et Kamil pour vos solutions. Dans cet article, j'ai couvert la solution de Kamil, avec sa technique créative pour émuler LAG et LEAD avec des numéros de ligne, non pivotants et pivotants. Vous trouverez cette technique utile lorsque vous avez besoin de calculs de type LAG et LEAD qui doivent être pris en charge sur des environnements antérieurs à 2012.