Lors du PASS Summit il y a quelques semaines, Microsoft a publié CTP2.1 de SQL Server 2019, et l'une des principales améliorations de fonctionnalités incluses dans le CTP est Scalar UDF Inlining. Avant cette version, je voulais jouer avec la différence de performances entre l'inlining des UDF scalaires et l'exécution RBAR (ligne par ligne agonisante) des UDF scalaires dans les versions antérieures de SQL Server et je suis tombé sur une option de syntaxe pour le CRÉER UNE FONCTION déclaration dans la documentation en ligne de SQL Server que je n'avais jamais vue auparavant.
Le DDL pour CREATE FUNCTION prend en charge une clause WITH pour les options de fonction et en lisant la documentation en ligne, j'ai remarqué que la syntaxe comprenait ce qui suit :
-- Clauses de fonction Transact-SQL::= { [ ENCRYPTION ] | [ SCHEMABINDING ] | [ RENVOIE NULL SUR ENTREE NULL | APPELÉ SUR ENTREE NULLE ] | [ EXECUTE_AS_Clause ] }
J'étais vraiment curieux de connaître le RETURNS NULL ON NULL INPUT option de fonction, j'ai donc décidé de faire des tests. J'ai été très surpris de découvrir qu'il s'agit en fait d'une forme d'optimisation UDF scalaire qui est présente dans le produit depuis au moins SQL Server 2008 R2.
Il s'avère que si vous savez qu'un UDF scalaire renverra toujours un résultat NULL lorsqu'une entrée NULL est fournie, l'UDF doit TOUJOURS être créé avec le RETURNS NULL ON NULL INPUT , car alors SQL Server n'exécute même pas du tout la définition de la fonction pour les lignes où l'entrée est NULL, ce qui la court-circuite et évite l'exécution inutile du corps de la fonction.
Pour vous montrer ce comportement, je vais utiliser une instance SQL Server 2017 avec la dernière mise à jour cumulative qui lui est appliquée et le AdventureWorks2017 base de données de GitHub (vous pouvez la télécharger ici) qui est livrée avec un dbo.ufnLeadingZeros fonction qui ajoute simplement des zéros non significatifs à la valeur d'entrée et renvoie une chaîne de huit caractères qui inclut ces zéros non significatifs. Je vais créer une nouvelle version de cette fonction qui inclut le RETURNS NULL ON NULL INPUT afin que je puisse la comparer à la fonction d'origine pour les performances d'exécution.
USE [AdventureWorks2017];GO CREATE FUNCTION [dbo].[ufnLeadingZeros_new]( @Value int ) RETURNS varchar(8) WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT AS BEGIN DECLARE @ReturnValue varchar(8); SET @ReturnValue =CONVERT(varchar(8), @Value); SET @ReturnValue =REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue ; RETOUR (@ReturnValue); FINIR; ALLER Afin de tester les différences de performances d'exécution au sein du moteur de base de données des deux fonctions, j'ai décidé de créer une session d'événements étendus sur le serveur pour suivre le sqlserver.module_end événement, qui se déclenche à la fin de chaque exécution de l'UDF scalaire pour chaque ligne. Cela me permet de démontrer la sémantique de traitement ligne par ligne et de suivre le nombre de fois où la fonction a été réellement invoquée pendant le test. J'ai décidé de collecter également le sql_batch_completed et sql_statement_completed événements et tout filtrer par session_id pour m'assurer que je ne capturais que les informations relatives à la session sur laquelle j'exécutais réellement les tests (si vous souhaitez reproduire ces résultats, vous devrez modifier le 74 à tous les endroits du code ci-dessous pour n'importe quel ID de session votre test code sera en cours d'exécution). La session d'événement utilise TRACK_CAUSALITY afin qu'il soit facile de compter le nombre d'exécutions de la fonction via activity_id.seq_no valeur pour les événements (qui augmente de un pour chaque événement qui satisfait le session_id filtre).
CREATE EVENT SESSION [Session72] ON SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_batch_completed( WHERE ( [package0].[equal_uint64]([sqlserver].[session_id],(74)))), AJOUTER UN ÉVÉNEMENT sqlserver.sql_batch_starting( OÙ ([package0].[equal_uint64]([sqlserver].[session_id],(74) ))), AJOUTER L'ÉVÉNEMENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), AJOUTER L'ÉVÉNEMENT sqlserver.sql_statement_starting( WHERE ([package0].[equal_uint64] ([sqlserver].[session_id],(74)))) AVEC (TRACK_CAUSALITY=ON) ALLER
Une fois que j'ai démarré la session d'événement et ouvert la visionneuse de données en direct dans Management Studio, j'ai exécuté deux requêtes ; un utilisant la version originale de la fonction pour ajouter des zéros à CurrencyRateID colonne dans Sales.SalesOrderHeader table, et la nouvelle fonction pour produire la sortie identique mais en utilisant le RETURNS NULL ON NULL INPUT option, et j'ai capturé les informations du plan d'exécution réel à des fins de comparaison.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader ; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader ; ALLER
L'examen des données des événements étendus a montré quelques choses intéressantes. Tout d'abord, la fonction d'origine a été exécutée 31 465 fois (à partir du nombre de module_end événements) et le temps CPU total pour sql_statement_completed l'événement était de 204 ms avec une durée de 482 ms.
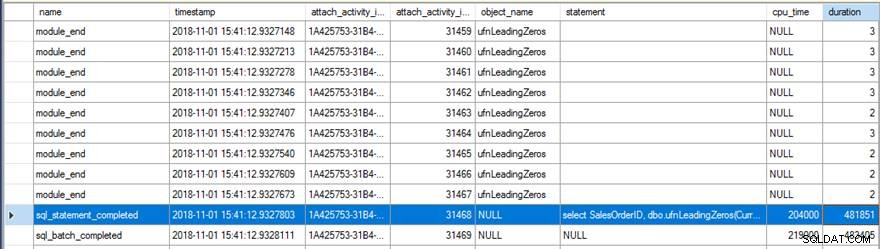
La nouvelle version avec le RETURNS NULL ON NULL INPUT l'option spécifiée n'a été exécutée que 13 976 fois (encore une fois, à partir du nombre de module_end événements) et le temps CPU pour sql_statement_completed l'événement a duré 78 ms avec une durée de 359 ms.

J'ai trouvé cela intéressant, donc pour vérifier le nombre d'exécutions, j'ai exécuté la requête suivante pour compter NOT NULL lignes de valeur, lignes de valeur NULL et lignes de total dans Sales.SalesOrderHeader tableau.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT(*) FROM Sales.SalesOrderHeader ;
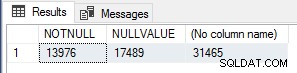
Ces chiffres correspondent exactement au nombre de module_end événements pour chacun des tests, il s'agit donc certainement d'une optimisation des performances très simple pour les UDF scalaires qui doivent être utilisées si vous savez que le résultat de la fonction sera NULL si les valeurs d'entrée sont NULL, pour court-circuiter/contourner l'exécution de la fonction entièrement pour ces lignes.
Les informations QueryTimeStats dans les plans d'exécution réels reflètent également les gains de performances :
Il s'agit d'une réduction assez significative du temps CPU seul, ce qui peut être un problème important pour certains systèmes.
L'utilisation d'UDF scalaires est un anti-modèle de conception bien connu pour les performances et il existe une variété de méthodes pour réécrire le code afin d'éviter leur utilisation et leur impact sur les performances. Mais s'ils sont déjà en place et ne peuvent pas être facilement modifiés ou supprimés, recréez simplement l'UDF avec le RETURNS NULL ON NULL INPUT L'option pourrait être un moyen très simple d'améliorer les performances s'il y a beaucoup d'entrées NULL dans l'ensemble de données où l'UDF est utilisé.