Nous avons récemment lancé un nouveau site d'assistance, où vous pouvez poser des questions, soumettre des commentaires sur les produits ou des demandes de fonctionnalités, ou ouvrir des tickets d'assistance. Une partie de l'objectif était de centraliser tous les endroits où nous offrions de l'aide à la communauté. Cela comprenait le site de questions-réponses SQLPerformance.com, où Paul White, Hugo Kornelis et bien d'autres ont aidé à résoudre vos questions les plus compliquées sur le réglage des requêtes et le plan d'exécution, depuis février 2013. Je vous dis avec des sentiments mitigés que le Le site de questions-réponses a été fermé.
Il y a cependant un avantage. Vous pouvez désormais poser ces questions difficiles sur le nouveau forum d'assistance. Si vous recherchez l'ancien contenu, eh bien, il est toujours là, mais il a l'air un peu différent. Pour diverses raisons que je n'aborderai pas aujourd'hui, une fois que nous avons décidé de supprimer le site de questions-réponses d'origine, nous avons finalement décidé d'héberger simplement tout le contenu existant sur un site WordPress en lecture seule, plutôt que de le migrer vers le back-end. du nouveau site.
Cet article ne traite pas des raisons de cette décision.
Je me sentais vraiment mal de la rapidité avec laquelle le site de réponses devait se déconnecter, le DNS commuté et le contenu migré. Comme une bannière d'avertissement a été mise en place sur le site mais qu'AnswerHub ne l'a pas rendue visible, cela a été un choc pour de nombreux utilisateurs. Je voulais donc m'assurer que je conservais correctement autant de contenu que possible, et je voulais que ce soit correct. Ce message est ici parce que j'ai pensé qu'il serait intéressant de parler du processus réel, du nombre de technologies différentes impliquées dans sa réalisation et de montrer le résultat. Je ne m'attends pas à ce qu'aucun d'entre vous bénéficie de ce bout en bout, car il s'agit d'un chemin de migration relativement obscur, mais plutôt comme un exemple de lier un tas de technologies ensemble pour accomplir une tâche. Cela me rappelle également que beaucoup de choses ne finissent pas par être aussi simples qu'elles en ont l'air avant de commencer.
Le TL;DR est ceci:j'ai passé beaucoup de temps et d'efforts à faire en sorte que le contenu archivé soit beau, même si j'essaie toujours de récupérer les derniers messages qui sont arrivés vers la fin. J'ai utilisé ces technologies :
- Perle
- SQL Server
- PowerShell
- Transmettre (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
D'où le titre. Si vous voulez un gros morceau de détails sanglants, les voici. Si vous avez des questions ou des commentaires, veuillez nous contacter ou commenter ci-dessous.
AnswerHub a fourni un fichier de vidage de 665 Mo à partir de la base de données MySQL qui hébergeait le contenu Q&R. Chaque éditeur que j'ai essayé s'est étouffé dessus, alors j'ai d'abord dû le diviser en un fichier par table en utilisant ce script Perl pratique de Jared Cheney. Les tables dont j'avais besoin s'appelaient network11_nodes (questions, réponses et commentaires), network11_authoritables (utilisateurs) et network11_managed_files (toutes les pièces jointes, y compris les téléchargements de plans) :perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Maintenant, ceux-ci n'étaient pas extrêmement rapides à charger dans SSMS, mais au moins là, je pouvais utiliser Ctrl +H pour changer (par exemple) ceci :
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
À ceci :
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Ensuite, je pourrais charger les données dans SQL Server pour pouvoir les manipuler. Et croyez-moi, je l'ai manipulé.
Ensuite, j'ai dû récupérer toutes les pièces jointes. Vous voyez, le fichier de vidage MySQL que j'ai reçu du fournisseur contenait un gazillion INSERT instructions, mais aucun des fichiers de plan réels que les utilisateurs avaient téléchargés - la base de données n'avait que les chemins relatifs vers les fichiers. J'ai utilisé T-SQL pour créer une série de commandes PowerShell qui appelleraient Invoke-WebRequest pour récupérer tous les fichiers et les stocker localement (de nombreuses façons de dépouiller ce chat, mais c'était très facile). À partir de ceci :
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Cela a donné cet ensemble de commandes (ainsi qu'une pré-commande pour résoudre ce problème TLS); le tout s'est déroulé assez rapidement, mais je ne recommande pas cette approche pour toute combinaison de {ensemble massif de fichiers} et/ou {faible bande passante} :
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Cela a téléchargé presque toutes les pièces jointes mais, certes, certaines ont été manquées en raison d'erreurs sur l'ancien site lors de leur téléchargement initial. Ainsi, sur le nouveau site, vous pouvez parfois voir une référence à une pièce jointe qui n'existe pas.
Ensuite, j'ai utilisé Panic Transmit 5 pour télécharger le temp dossier vers le nouveau site, et maintenant, lorsque le contenu est téléchargé, des liens vers /s/temp/1-proc.pesession continuera à fonctionner.
Ensuite, je suis passé au SSL. Afin de demander un certificat sur le nouveau site WordPress, nous avons dû mettre à jour le DNS pour answers.sqlperformance.com pour pointer vers le CNAME sur notre hébergeur WordPress, WPEngine. C'était une sorte de poule et d'œuf ici - nous avons dû subir des temps d'arrêt pour les URL https, qui échoueraient sans certificat sur le nouveau site. C'était correct parce que le certificat sur l'ancien site avait expiré, donc vraiment, nous n'étions pas plus mal lotis. J'ai également dû attendre pour le faire jusqu'à ce que j'aie téléchargé tous les fichiers de l'ancien site, car une fois le DNS basculé, il n'y aurait aucun moyen d'y accéder, sauf par une porte dérobée.
Pendant que j'attendais que le DNS se propage, j'ai commencé à travailler sur la logique pour extraire toutes les questions, réponses et commentaires dans quelque chose de consommable dans WordPress. Non seulement les schémas de table étaient différents de WordPress, mais les types d'entités sont également très différents. Ma vision était de combiner chaque question - et toutes les réponses et/ou commentaires - en un seul message.
La partie délicate est que la table des nœuds contient simplement les trois types de contenu dans la même table, avec les références parent et parent d'origine ("maître"). Leur code frontal utilise probablement une sorte de curseur pour parcourir et afficher le contenu dans un ordre hiérarchique et chronologique. Je n'aurais pas ce luxe dans WordPress, j'ai donc dû enchaîner le code HTML d'un seul coup. À titre d'exemple, voici à quoi ressemblaient les données :
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Je ne pouvais pas trier par identifiant, ou type, ou par parent, car parfois un commentaire viendrait plus tard sur une réponse précédente, la première réponse ne serait pas toujours la réponse acceptée, et ainsi de suite. Je voulais cette sortie (où ++ représente un niveau d'indentation) :
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
J'ai commencé à écrire un CTE récursif et,
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Résultats :
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Génie. J'ai vérifié sur place une douzaine d'autres personnes et j'étais heureux de passer à l'étape suivante. J'ai remercié Andy abondamment, plusieurs fois, mais permettez-moi de le refaire :Merci Andy !
Maintenant que je pouvais renvoyer l'ensemble dans l'ordre qui me plaisait, je devais effectuer quelques manipulations de la sortie pour appliquer des éléments HTML et des noms de classe qui me permettraient de marquer les questions, les réponses, les commentaires et l'indentation de manière significative. L'objectif final était une sortie qui ressemblait à ceci (et gardez à l'esprit qu'il s'agit de l'un des cas les plus simples) :
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Je ne passerai pas en revue le nombre ridicule d'itérations que j'ai dû traverser pour arriver à une forme fiable de cette sortie pour les plus de 5 000 articles (ce qui s'est traduit par près de 1 000 messages une fois que tout a été collé). En plus de cela, j'avais besoin de les générer sous la forme de INSERT déclarations que je pouvais ensuite coller dans phpMyAdmin sur le site WordPress, ce qui signifiait adhérer à leur diagramme de syntaxe bizarre. Ces déclarations devaient inclure d'autres informations supplémentaires requises par WordPress, mais non présentes ou exactes dans les données sources (comme post_type ). Et cette console d'administration expirerait avec trop de données, j'ai donc dû la découper en ~ 750 insertions à la fois. Voici la procédure avec laquelle je me suis retrouvé (ce n'est pas vraiment pour apprendre quoi que ce soit de spécifique, juste une démonstration de la quantité de manipulation des données importées était nécessaire) :
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO La sortie de cela n'est pas complète et n'est pas encore prête à être insérée dans WordPress :
 Exemple de sortie (cliquez pour agrandir)
Exemple de sortie (cliquez pour agrandir)
J'aurais besoin d'une aide supplémentaire de C # pour transformer le contenu réel (y compris le démarquage) en HTML et CSS que je pourrais mieux contrôler, et écrire la sortie (un tas de INSERT déclarations qui incluaient un tas de code HTML) aux fichiers sur le disque que je pouvais ouvrir et coller dans phpMyAdmin. Pour le HTML, texte brut + démarquage qui commençait comme ceci :
SELECT quelque chose de dbo.sometable ;
[1] :https://ailleurs
Devrait devenir ceci :
Il y a un article de blog ici qui en parle, et aussi cet article .
SÉLECTIONNER quelque chose dans dbo.sometable ; Pour y parvenir, j'ai demandé l'aide de MarkdownSharp, une bibliothèque open source provenant de Stack Overflow qui gère une grande partie de la conversion markdown-to-HTML. C'était un bon ajustement pour mes besoins, mais pas parfait; Il me faudrait encore effectuer d'autres manipulations :
- MarkdownSharp n'autorise pas des choses comme
target=_blank, donc je devrais les injecter moi-même après le traitement ; - le code (tout ce qui est précédé de quatre espaces) hérite des wrappers
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Oui, c'est un vilain tas de code, mais cela m'a finalement amené à l'ensemble de sortie qui ne ferait pas vomir phpMyAdmin, et que WordPress présenterait bien (assez). J'ai simplement appelé le programme C# plusieurs fois avec les différentes plages de paramètres :
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Ensuite, j'ai ouvert chacun des fichiers, les ai collés dans phpMyAdmin et j'ai appuyé sur GO :
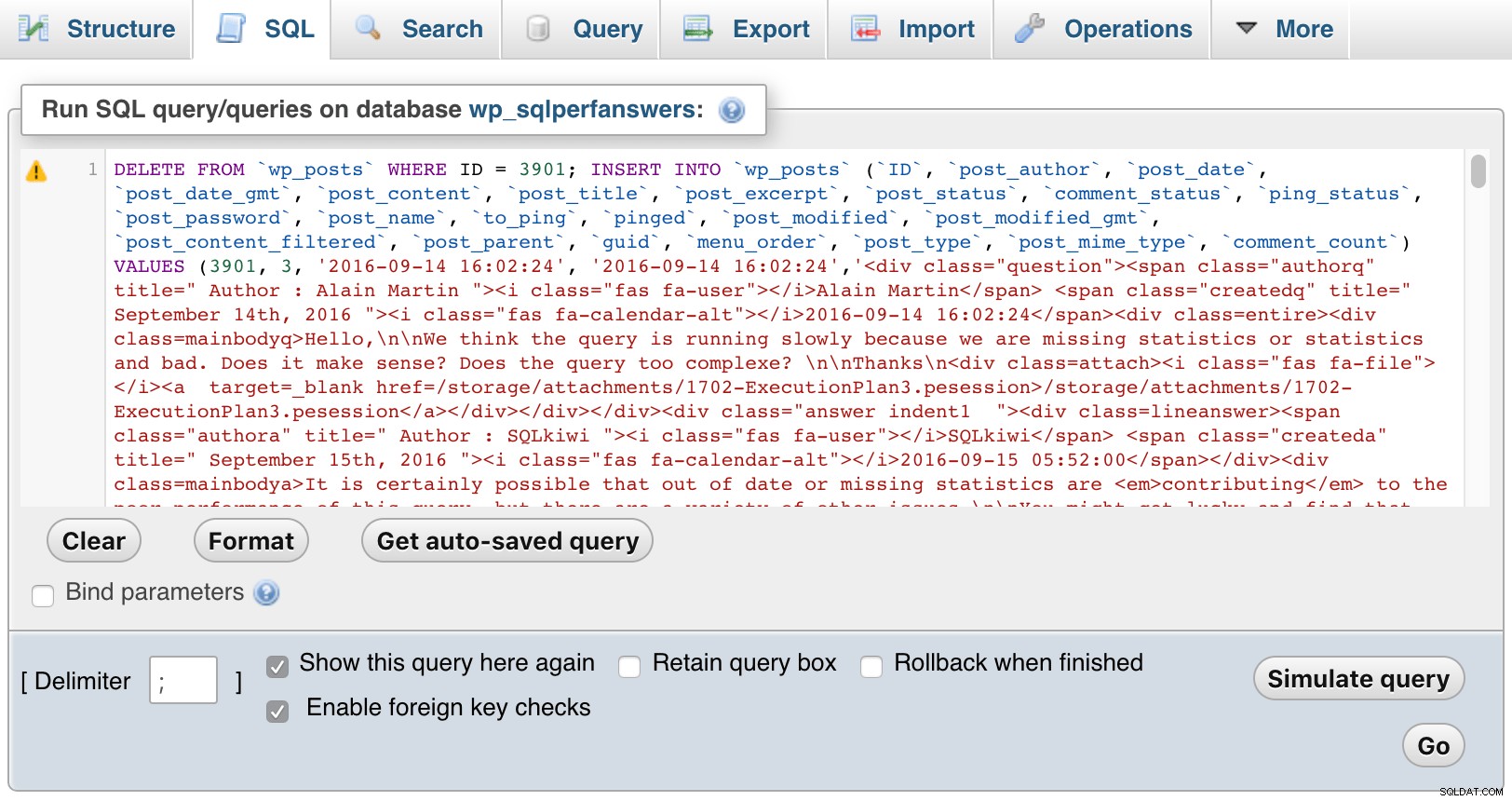 phpMyAdmin (cliquez pour agrandir)
phpMyAdmin (cliquez pour agrandir) Bien sûr, j'ai dû ajouter du CSS dans WordPress pour aider à différencier les questions, les commentaires et les réponses, et également pour mettre en retrait les commentaires pour afficher les réponses aux questions et aux réponses, imbriquer les commentaires répondant aux commentaires, etc. Voici à quoi ressemble un extrait lorsque vous explorez les questions d'un mois :
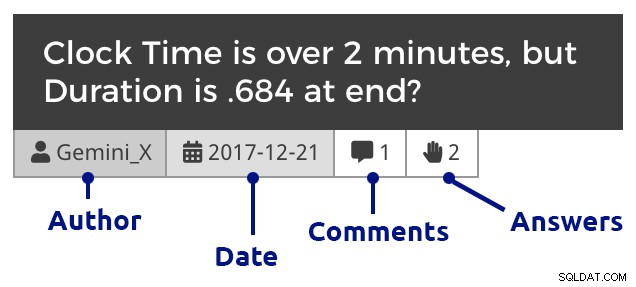 Titre de question (cliquez pour agrandir)
Titre de question (cliquez pour agrandir) Et puis un exemple de publication, montrant des images intégrées, plusieurs pièces jointes, des commentaires imbriqués et une réponse :
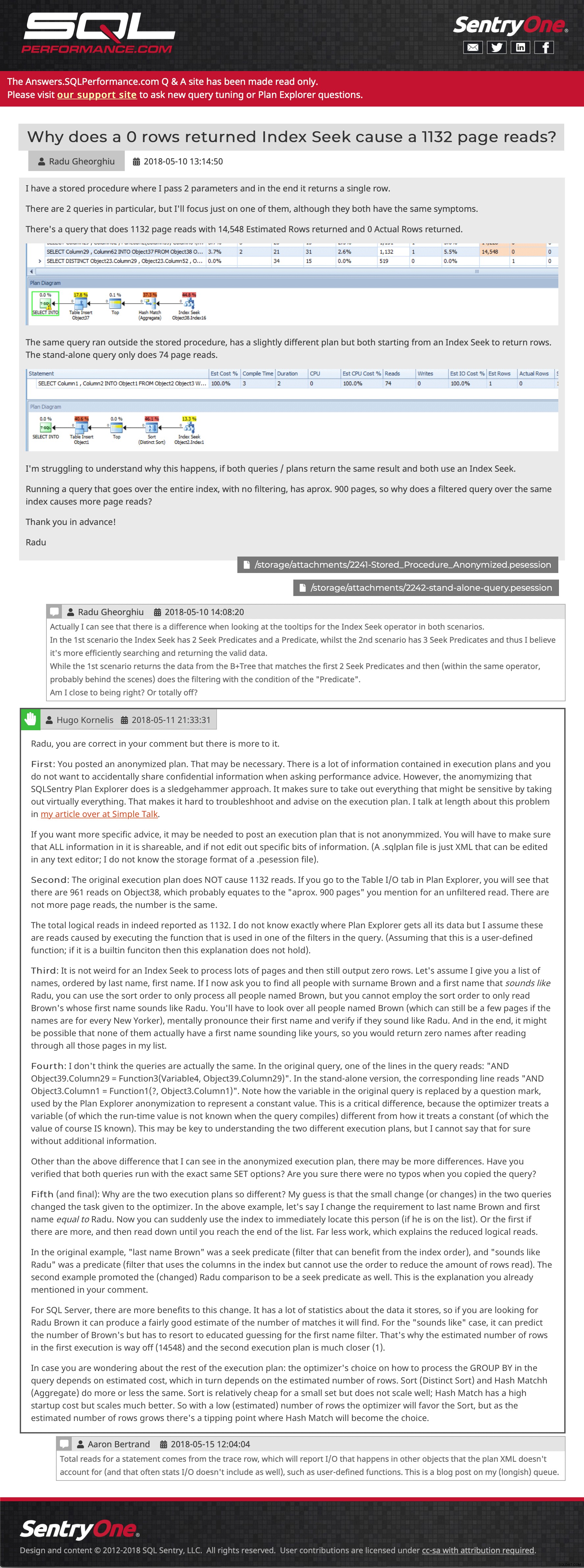 Exemple de question et de réponse (cliquez pour y accéder)
Exemple de question et de réponse (cliquez pour y accéder) J'essaie toujours de récupérer quelques messages qui ont été soumis au site après la dernière sauvegarde, mais je vous invite à parcourir. Veuillez nous faire savoir si vous remarquez quelque chose qui manque ou qui n'est pas à sa place, ou même simplement pour nous dire que le contenu vous est toujours utile. Nous espérons réintroduire la fonctionnalité de téléchargement de plans à partir de Plan Explorer, mais cela nécessitera un travail d'API sur le nouveau site d'assistance, donc je n'ai pas d'ETA pour vous aujourd'hui.
- Answers.SQLPerformance.com