Les tâches d'écarts et d'îlots sont des défis d'interrogation classiques dans lesquels vous devez identifier des plages de valeurs manquantes et des plages de valeurs existantes dans une séquence. La séquence est souvent basée sur une date, ou des valeurs de date et d'heure, qui devraient normalement apparaître à intervalles réguliers, mais certaines entrées sont manquantes. La tâche des écarts recherche les périodes manquantes et la tâche des îles recherche les périodes existantes. J'ai couvert de nombreuses solutions aux lacunes et aux tâches des îles dans mes livres et articles du passé. Récemment, mon ami Adam Machanic m'a présenté un nouveau défi spécial pour les îles et le résoudre a nécessité un peu de créativité. Dans cet article, je présente le défi et la solution que j'ai trouvé.
Le défi
Dans votre base de données, vous gardez une trace des services pris en charge par votre entreprise dans une table appelée CompanyServices, et chaque service signale normalement environ une fois par minute qu'il est en ligne dans une table appelée EventLog. Le code suivant crée ces tables et les remplit avec de petits ensembles d'exemples de données :
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
La table EventLog est actuellement remplie avec les données suivantes :
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
La tâche spéciale des îlots consiste à identifier les périodes de disponibilité (servies, starttime, endtime). Le hic, c'est qu'il n'y a aucune garantie qu'un service signalera qu'il est en ligne exactement à chaque minute; vous êtes censé tolérer un intervalle allant jusqu'à, disons, 66 secondes à partir de l'entrée de journal précédente et la considérer toujours comme faisant partie de la même période de disponibilité (île). Au-delà de 66 secondes, la nouvelle entrée de journal démarre une nouvelle période de disponibilité. Ainsi, pour les exemples de données d'entrée ci-dessus, votre solution est censée renvoyer l'ensemble de résultats suivant (pas nécessairement dans cet ordre) :
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Remarquez, par exemple, comment l'entrée de journal 5 démarre une nouvelle île puisque l'intervalle depuis l'entrée de journal précédente est de 120 secondes (> 66), tandis que l'entrée de journal 6 ne démarre pas une nouvelle île puisque l'intervalle depuis l'entrée précédente est de 62 secondes ( <=66). Un autre problème est qu'Adam voulait que la solution soit compatible avec les environnements pré-SQL Server 2012, ce qui en fait un défi beaucoup plus difficile, car vous ne pouvez pas utiliser les fonctions d'agrégation de fenêtre avec un cadre pour calculer les totaux cumulés et les fonctions de fenêtre de décalage. comme LAG et LEAD.Comme d'habitude, je suggère d'essayer de résoudre le défi vous-même avant de regarder mes solutions. Utilisez les petits ensembles d'exemples de données pour vérifier la validité de vos solutions. Utilisez le code suivant pour remplir vos tables avec de grands ensembles d'exemples de données (500 services, environ 10 millions d'entrées de journal pour tester les performances de vos solutions) :
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Les résultats que je fournirai pour les étapes de mes solutions supposeront les petits ensembles d'exemples de données, et les chiffres de performance que je fournirai supposeront les grands ensembles.
Toutes les solutions que je vais présenter bénéficient de l'index suivant :
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Bonne chance !
Solution 1 pour SQL Server 2012+
Avant d'aborder une solution compatible avec les environnements pré-SQL Server 2012, je vais en aborder une qui nécessite au minimum SQL Server 2012. Je l'appellerai Solution 1.
La première étape de la solution consiste à calculer un indicateur appelé isstart qui vaut 0 si l'événement ne démarre pas une nouvelle île, et 1 sinon. Ceci peut être réalisé en utilisant la fonction LAG pour obtenir l'heure du journal de l'événement précédent et en vérifiant si la différence de temps en secondes entre les événements précédents et actuels est inférieure ou égale à l'écart autorisé. Voici le code implémentant cette étape :
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Ce code génère la sortie suivante :
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Ensuite, un simple total cumulé du drapeau isstart produit un identifiant d'île (je l'appellerai grp). Voici le code implémentant cette étape :
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Ce code génère la sortie suivante :
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Enfin, vous regroupez les lignes par ID de service et identifiant d'îlot et renvoyez les temps de journal minimum et maximum comme heure de début et heure de fin de chaque îlot. Voici la solution complète :
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
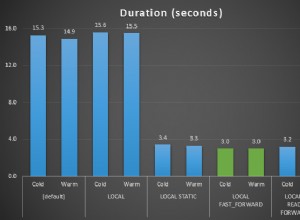
GROUP BY serviceid, grp; Cette solution a pris 41 secondes sur mon système et a produit le plan illustré à la figure 1.
 Figure 1 :Planifier la solution 1
Figure 1 :Planifier la solution 1
Comme vous pouvez le voir, les deux fonctions de fenêtre sont calculées en fonction de l'ordre de l'index, sans avoir besoin d'un tri explicite.
Si vous utilisez SQL Server 2016 ou une version ultérieure, vous pouvez utiliser l'astuce que je couvre ici pour activer l'opérateur Window Aggregate en mode batch en créant un index columnstore filtré vide, comme ceci :
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
La même solution ne prend maintenant que 5 secondes pour se terminer sur mon système, produisant le plan illustré à la figure 2.
 Figure 2 :Planifier la solution 1 à l'aide de l'opérateur Window Aggregate en mode batch
Figure 2 :Planifier la solution 1 à l'aide de l'opérateur Window Aggregate en mode batch
Tout cela est formidable, mais comme mentionné, Adam recherchait une solution pouvant fonctionner sur des environnements antérieurs à 2012.
Avant de continuer, assurez-vous de supprimer l'index columnstore pour le nettoyage :
DROP INDEX idx_cs ON dbo.EventLog;
Solution 2 pour les environnements antérieurs à SQL Server 2012
Malheureusement, avant SQL Server 2012, nous n'avions pas de support pour les fonctions de fenêtre de décalage comme LAG, ni pour le calcul des totaux cumulés avec les fonctions d'agrégation de fenêtre avec un cadre. Cela signifie que vous devrez travailler beaucoup plus dur pour trouver une solution raisonnable.
L'astuce que j'ai utilisée consiste à transformer chaque entrée de journal en un intervalle artificiel dont l'heure de début est l'heure de journal de l'entrée et dont l'heure de fin est l'heure de journal de l'entrée plus l'écart autorisé. Vous pouvez ensuite traiter la tâche comme une tâche classique de conditionnement d'intervalles.
La première étape de la solution calcule les délimiteurs d'intervalle artificiels et les numéros de ligne marquant les positions de chacun des types d'événements (counteach). Voici le code implémentant cette étape :
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Ce code génère la sortie suivante :
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
L'étape suivante consiste à transformer les intervalles en une séquence chronologique d'événements de début et de fin, identifiés respectivement comme types d'événement « s » et « e ». Notez que le choix des lettres s et e est important ('s' > 'e' ). Cette étape calcule les numéros de ligne marquant l'ordre chronologique correct des deux types d'événements, qui sont maintenant entrelacés (countboth). Dans le cas où un intervalle se termine exactement là où un autre commence, en positionnant l'événement de début avant l'événement de fin, vous les regrouperez. Voici le code implémentant cette étape :
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Ce code génère la sortie suivante :
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Comme mentionné, counteach marque la position de l'événement uniquement parmi les événements du même type, et countboth marque la position de l'événement parmi les événements combinés entrelacés des deux types.
La magie est ensuite gérée par l'étape suivante :calculer le nombre d'intervalles actifs après chaque événement en fonction de counteach et countboth. Le nombre d'intervalles actifs correspond au nombre d'événements de début qui se sont produits jusqu'à présent moins le nombre d'événements de fin qui se sont produits jusqu'à présent. Pour les événements de début, counteach vous indique combien d'événements de début se sont produits jusqu'à présent, et vous pouvez déterminer combien se sont terminés jusqu'à présent en soustrayant counteach de countboth. Ainsi, l'expression complète vous indiquant combien d'intervalles sont actifs est alors :
counteach - (countboth - counteach)
Pour les événements de fin, counteach vous indique combien d'événements de fin se sont produits jusqu'à présent, et vous pouvez déterminer combien ont commencé jusqu'à présent en soustrayant counteach de countboth. Ainsi, l'expression complète vous indiquant combien d'intervalles sont actifs est alors :
(countboth - counteach) - counteach
À l'aide de l'expression CASE suivante, vous calculez la colonne countactive en fonction du type d'événement :
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END Dans la même étape, vous filtrez uniquement les événements représentant les débuts et les fins d'intervalles condensés. Les débuts d'intervalles condensés ont un type 's' et un countactive 1. Les fins d'intervalles condensés ont un type 'e' et un countactive 0.
Après le filtrage, il vous reste des paires d'événements de début et de fin d'intervalles condensés, mais chaque paire est divisée en deux lignes, une pour l'événement de début et une autre pour l'événement de fin. Par conséquent, la même étape calcule l'identifiant de la paire en utilisant les numéros de ligne, avec la formule (rownum - 1) / 2 + 1.
Voici le code implémentant cette étape :
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Ce code génère la sortie suivante :
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
La dernière étape fait pivoter les paires d'événements dans une ligne par intervalle et soustrait l'écart autorisé de l'heure de fin pour régénérer l'heure d'événement correcte. Voici le code complet de la solution :
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Cette solution a pris 43 secondes pour se terminer sur mon système et a généré le plan illustré à la figure 3.
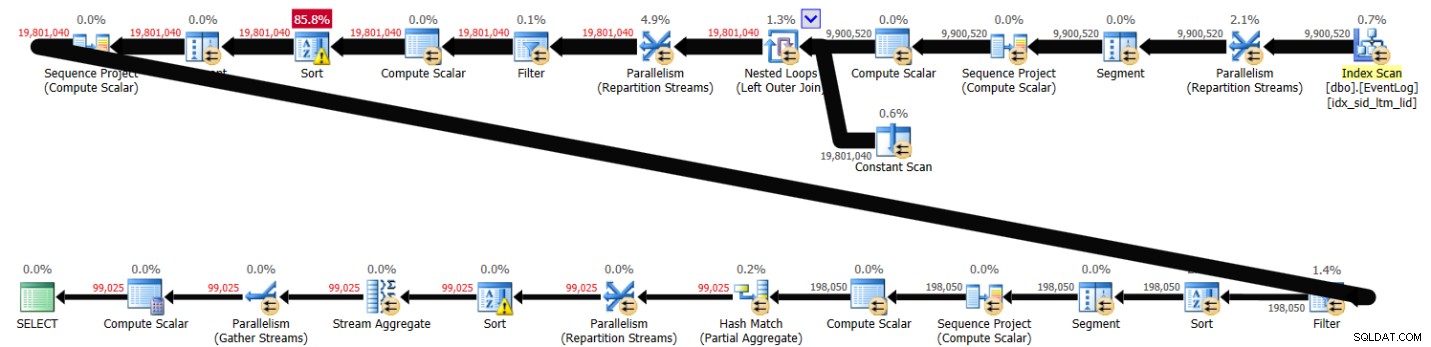 Figure 3 :Planifier la solution 2
Figure 3 :Planifier la solution 2
Comme vous pouvez le voir, le premier calcul du numéro de ligne est calculé en fonction de l'ordre de l'index, mais les deux suivants impliquent un tri explicite. Pourtant, les performances ne sont pas si mauvaises étant donné qu'il y a environ 10 000 000 de lignes impliquées.
Même si le but de cette solution est d'utiliser un environnement pré-SQL Server 2012, juste pour le plaisir, j'ai testé ses performances après avoir créé un index columnstore filtré pour voir comment il se comporte avec le traitement par lots activé :
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Avec le traitement par lots activé, cette solution a pris 29 secondes pour se terminer sur mon système, produisant le plan illustré à la figure 4.
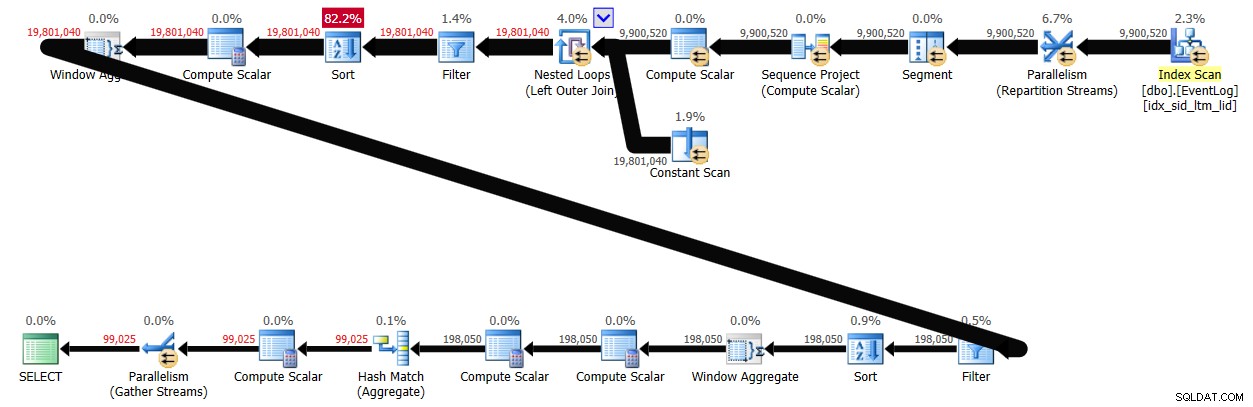
Conclusion
Il est naturel que plus votre environnement est limité, plus il devient difficile de résoudre des tâches d'interrogation. Le défi spécial des îles d'Adam est beaucoup plus facile à résoudre sur les nouvelles versions de SQL Server que sur les anciennes. Mais ensuite, vous vous forcez à utiliser des techniques plus créatives. Ainsi, à titre d'exercice, pour améliorer vos compétences en matière d'interrogation, vous pouvez relever des défis que vous connaissez déjà, mais imposer intentionnellement certaines restrictions. Vous ne savez jamais dans quels types d'idées intéressantes vous pourriez tomber !