Pour le mardi T-SQL de ce mois-ci, Steve Jones (@way0utwest) nous a demandé de parler de nos meilleures ou pires expériences de déclenchement. S'il est vrai que les déclencheurs sont souvent mal vus, voire craints, ils ont plusieurs cas d'utilisation valables, notamment :
- Audit (avant 2016 SP1, lorsque cette fonctionnalité est devenue gratuite dans toutes les éditions)
- Application des règles métier et de l'intégrité des données, lorsqu'elles ne peuvent pas être facilement mises en œuvre dans des contraintes et que vous ne voulez pas qu'elles dépendent du code de l'application ou des requêtes DML elles-mêmes
- Maintenir les versions historiques des données (avant la capture des données modifiées, le suivi des modifications et les tables temporelles)
- Mise en file d'attente des alertes ou traitement asynchrone en réponse à une modification spécifique
- Autoriser les modifications de vues (via des déclencheurs INSTEAD OF)
Ce n'est pas une liste exhaustive, juste un bref récapitulatif de quelques scénarios que j'ai vécus où les déclencheurs étaient la bonne réponse à l'époque.
Lorsque des déclencheurs sont nécessaires, j'aime toujours explorer l'utilisation des déclencheurs INSTEAD OF plutôt que des déclencheurs AFTER. Oui, il s'agit d'un peu plus de travail initial*, mais ils présentent des avantages assez importants. En théorie, au moins, la perspective d'empêcher une action (et ses conséquences de log) de se produire semble beaucoup plus efficace que de la laisser se produire puis de l'annuler.
*Je dis cela parce que vous devez coder à nouveau l'instruction DML dans le déclencheur ; c'est pourquoi ils ne sont pas appelés déclencheurs AVANT. La distinction est importante ici, car certains systèmes implémentent de véritables déclencheurs AVANT, qui s'exécutent simplement en premier. Dans SQL Server, un déclencheur INSTEAD OF annule effectivement l'instruction qui l'a déclenché.
Imaginons que nous ayons une table simple pour stocker les noms de compte. Dans cet exemple, nous allons créer deux tables afin de pouvoir comparer deux déclencheurs différents et leur impact sur la durée de la requête et l'utilisation du journal. Le concept est que nous avons une règle métier :le nom du compte n'est pas présent dans une autre table, qui représente les "mauvais" noms, et le déclencheur est utilisé pour appliquer cette règle. Voici la base de données :
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO Et les tableaux :
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
Et, enfin, les déclencheurs. Pour plus de simplicité, nous ne traitons que des insertions, et à la fois après et au lieu de cas, nous allons simplement abandonner tout le lot si un seul nom enfreint notre règle :
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Maintenant, pour tester les performances, nous allons simplement essayer d'insérer 100 000 noms dans chaque table, avec un taux d'échec prévisible de 10 %. En d'autres termes, 90 000 noms sont corrects, les 10 000 autres échouent au test et entraînent l'annulation ou l'absence d'insertion du déclencheur en fonction du lot.
Tout d'abord, nous devons faire un peu de nettoyage avant chaque lot :
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Avant de commencer la viande de chaque lot, nous allons compter les lignes dans le journal des transactions et mesurer la taille et l'espace libre. Ensuite, nous passerons par un curseur pour traiter les 100 000 lignes dans un ordre aléatoire, en essayant d'insérer chaque nom dans la table appropriée. Lorsque nous aurons terminé, nous mesurerons à nouveau le nombre de lignes et la taille du journal, et vérifierons la durée.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Résultats (moyenne sur 5 exécutions de chaque lot) :
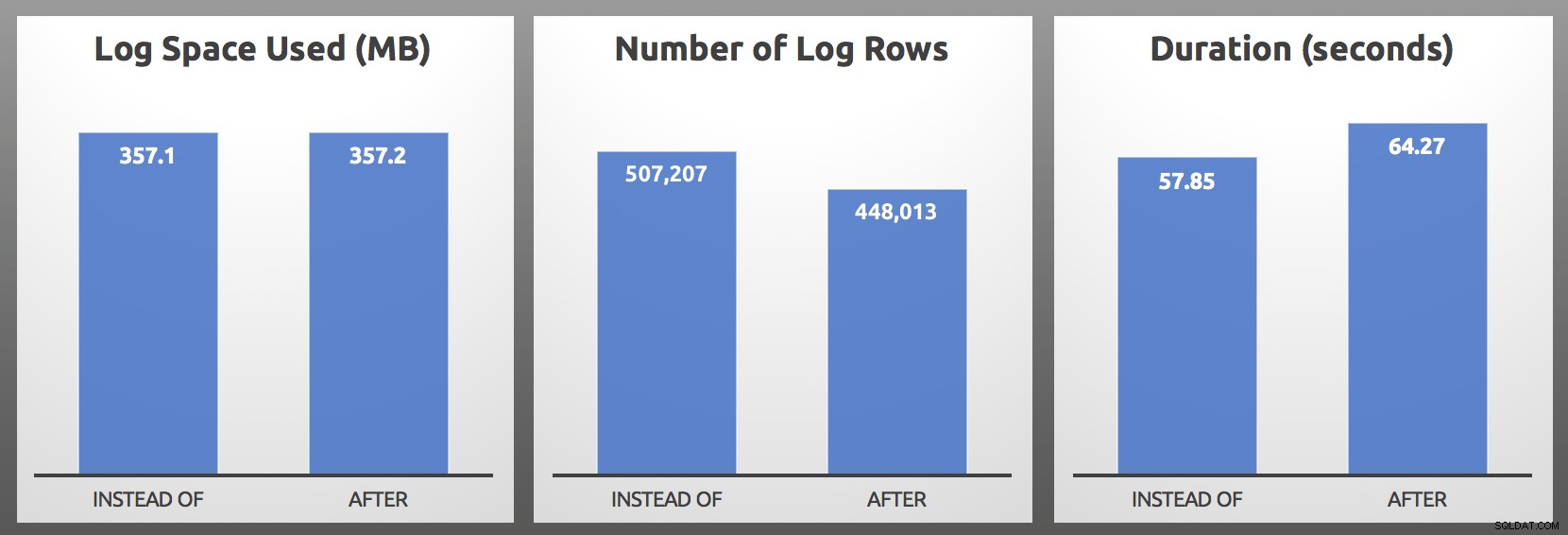 APRÈS vs. AU LIEU :Résultats
APRÈS vs. AU LIEU :Résultats
Lors de mes tests, l'utilisation du journal était de taille presque identique, avec plus de 10 % de lignes de journal supplémentaires générées par le déclencheur INSTEAD OF. J'ai creusé un peu à la fin de chaque lot :
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
Et voici un résultat typique (j'ai mis en évidence les principaux deltas) :
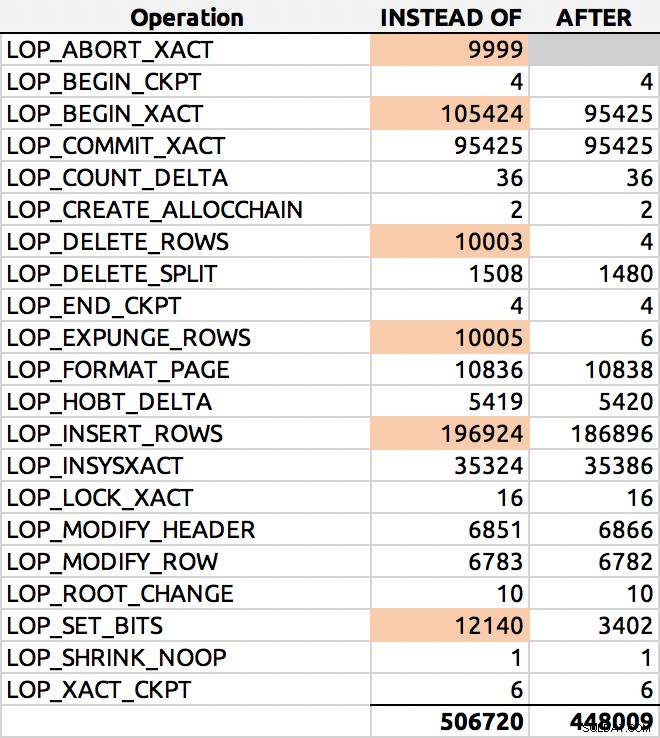 Répartition des lignes du journal
Répartition des lignes du journal
J'approfondirai cela une autre fois.
Mais quand on s'y met…
… la mesure la plus importante sera presque toujours la durée , et dans mon cas, le déclencheur INSTEAD OF a fonctionné au moins 5 secondes plus vite dans chaque test en tête-à-tête. Au cas où tout cela vous semble familier, oui, j'en ai déjà parlé, mais à l'époque, je n'avais pas observé ces mêmes symptômes avec les lignes de journal.
Notez qu'il ne s'agit peut-être pas de votre schéma ou de votre charge de travail exacts, vous pouvez avoir un matériel très différent, votre simultanéité peut être plus élevée et votre taux d'échec peut être beaucoup plus élevé (ou inférieur). Mes tests ont été effectués sur une machine isolée avec beaucoup de mémoire et des SSD PCIe très rapides. Si votre journal se trouve sur un lecteur plus lent, les différences d'utilisation du journal peuvent l'emporter sur les autres métriques et modifier considérablement les durées. Tous ces facteurs (et bien d'autres !) peuvent affecter vos résultats, vous devez donc tester dans votre environnement.
Le point, cependant, est que les déclencheurs INSTEAD OF pourraient être mieux adaptés. Maintenant, si seulement nous pouvions obtenir des déclencheurs PLUTÔT QUE DDL…