Lorsque vous êtes profondément impliqué dans le dépannage d'un problème dans SQL Server, vous vous retrouvez parfois à vouloir connaître l'ordre exact dans lequel les requêtes ont été exécutées. Je vois cela avec des procédures stockées plus compliquées qui contiennent des couches de logique, ou dans des scénarios où il y a beaucoup de code redondant. Les événements étendus sont un choix naturel ici, car ils sont généralement utilisés pour capturer des informations sur l'exécution des requêtes. Vous pouvez souvent utiliser session_id et l'horodatage pour comprendre l'ordre des événements, mais il existe une option de session pour XE qui est encore plus fiable :suivre la causalité.
Lorsque vous activez le suivi de la causalité pour une session, il ajoute un GUID et un numéro de séquence à chaque événement, que vous pouvez ensuite utiliser pour parcourir l'ordre dans lequel les événements se sont produits. Les frais généraux sont minimes et peuvent représenter un gain de temps considérable dans de nombreux scénarios de dépannage.
Configurer
À l'aide de la base de données WideWorldImporters, nous allons créer une procédure stockée à utiliser :
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO
Ensuite, nous créerons une session d'événement :
CREATE EVENT SESSION [TrackQueries] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
WHERE ([sqlserver].[is_system]=(0))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([sqlserver].[is_system]=(0)))
ADD TARGET package0.event_file
(
SET filename=N'C:\temp\TrackQueries',max_file_size=(256)
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
); Nous allons également exécuter des requêtes ad hoc, nous capturons donc à la fois sp_statement_completed (instructions terminées dans une procédure stockée) et sql_statement_completed (instructions terminées qui ne se trouvent pas dans une procédure stockée). Notez que l'option TRACK_CAUSALITY pour la session est définie sur ON. Encore une fois, ce paramètre est spécifique à la session d'événement et doit être activé avant de la démarrer. Vous ne pouvez pas activer le paramètre à la volée, comme vous pouvez ajouter ou supprimer des événements et des cibles pendant l'exécution de la session.
Pour démarrer la session d'événement via l'interface utilisateur, faites un clic droit dessus et sélectionnez Démarrer la session.
Test
Dans Management Studio, nous exécuterons le code suivant :
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan'; Voici notre sortie XE :

Notez que la première requête exécutée, qui est en surbrillance, est SELECT @@SPID et a un GUID de FDCCB1CF-CA55-48AA-8FBA-7F5EBF870674. Nous n'avons pas exécuté cette requête, elle s'est produite en arrière-plan, et même si la session XE est configurée pour filtrer les requêtes système, celle-ci - pour une raison quelconque - est toujours capturée.
Les quatre lignes suivantes représentent le code que nous avons réellement exécuté. Il y a les deux requêtes de la procédure stockée, la procédure stockée elle-même, puis notre requête ad hoc. Tous ont le même GUID, ACBFFD99-2400-4AFF-A33F-351821667B24. À côté du GUID se trouve l'ID de séquence (seq) et les requêtes sont numérotées de un à quatre.
Dans notre exemple, nous n'avons pas utilisé GO pour séparer les instructions en différents lots. Remarquez comment la sortie change lorsque nous faisons cela :
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
GO
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan';
GO

Nous avons toujours le même nombre de lignes au total, mais nous avons maintenant trois GUID. Un pour le SELECT @@SPID (E8D136B8-092F-439D-84D6-D4EF794AE753), un pour les trois requêtes représentant la procédure stockée (F962B9A4-0665-4802-9E6C-B217634D8787) et un pour la requête ad hoc (5DD6A5FE -9702-4DE5-8467-8D7CF55B5D80).
C'est ce que vous verrez très probablement lorsque vous consulterez les données de votre application, mais cela dépend du fonctionnement de l'application. S'il utilise le regroupement de connexions et que les connexions sont réinitialisées régulièrement (ce qui est normal), chaque connexion aura son propre GUID.
Vous pouvez recréer cela à l'aide de l'exemple de code PowerShell ci-dessous :
while(1 -eq 1)
{
$SqlConn = New-Object System.Data.SqlClient.SqlConnection;
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;Integrated Security=True;Application Name = MyCoolApp";
$SQLConn.Open()
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT TOP 1 CustomerID FROM Sales.Customers ORDER BY NEWID();"
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlReader = $SqlCmd.ExecuteReader();
$Results = New-Object System.Collections.ArrayList;
while ($SqlReader.Read())
{
$Results.Add($SqlReader.GetSqlInt32(0)) | Out-Null;
}
$SqlReader.Close();
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "Sales.usp_CustomerTransactionInfo"
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CustomerID", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::Int;
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
$Names = New-Object System.Collections.Generic.List``1[System.String]
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT FullName FROM Application.People ORDER BY NEWID();";
$dr = $SqlCmd.ExecuteReader();
while($dr.Read())
{
$Names.Add($dr.GetString(0));
}
$SqlConn.Close();
$name = Get-Random -InputObject $Names;
$query = [String]::Format("SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = '{0}';", $name);
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $sqlconnection.CreateCommand();
$SqlCmd.CommandText = $query
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
} Voici un exemple de sortie d'événements étendus après avoir laissé le code s'exécuter un peu :

Il existe quatre GUID différents pour nos cinq déclarations, et si vous regardez le code ci-dessus, vous verrez qu'il y a quatre connexions différentes établies. Si vous modifiez la session d'événements pour inclure l'événement rpc_completed, vous pouvez voir les entrées avec exec sp_reset_connection.
Votre sortie XE dépendra de votre code et de votre application ; J'ai d'abord mentionné que cela était utile lors du dépannage de procédures stockées plus complexes. Prenons l'exemple suivant :
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetFullCustomerInfo]; GO CREATE PROCEDURE [Sales].[usp_GetFullCustomerInfo] @CustomerID INT AS SELECT [o].[CustomerID], [o].[OrderDate], [ol].[StockItemID], [ol].[Quantity], [ol].[UnitPrice] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID ORDER BY [o].[OrderDate] DESC; SELECT [o].[CustomerID], SUM([ol].[Quantity]*[ol].[UnitPrice]) FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID GROUP BY [o].[CustomerID] ORDER BY [o].[CustomerID] ASC; GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetCustomerData]; GO CREATE PROCEDURE [Sales].[usp_GetCustomerData] @CustomerID INT AS BEGIN SELECT * FROM [Sales].[Customers] EXEC [Sales].[usp_CustomerTransactionInfo] @CustomerID EXEC [Sales].[usp_GetFullCustomerInfo] @CustomerID END GO
Ici, nous avons deux procédures stockées, usp_TransctionInfo et usp_GetFullCustomerInfo, qui sont appelées par une autre procédure stockée, usp_GetCustomerData. Il n'est pas rare de voir cela, ou même de voir des niveaux supplémentaires d'imbrication avec des procédures stockées. Si nous exécutons usp_GetCustomerData depuis Management Studio, nous voyons ce qui suit :
EXEC [Sales].[usp_GetCustomerData] 981;

Ici, toutes les exécutions ont eu lieu sur le même GUID, BF54CD8F-08AF-4694-A718-D0C47DBB9593, et nous pouvons voir l'ordre d'exécution des requêtes de un à huit en utilisant la colonne seq. Dans les cas où plusieurs procédures stockées sont appelées, il n'est pas rare que la valeur de l'ID de séquence se chiffre en centaines ou en milliers.
Enfin, dans le cas où vous examinez l'exécution de la requête et que vous avez inclus le suivi de la causalité, et que vous trouvez une requête peu performante - parce que vous avez trié la sortie en fonction de la durée ou d'une autre métrique, notez que vous pouvez trouver l'autre requêtes en regroupant sur le GUID :
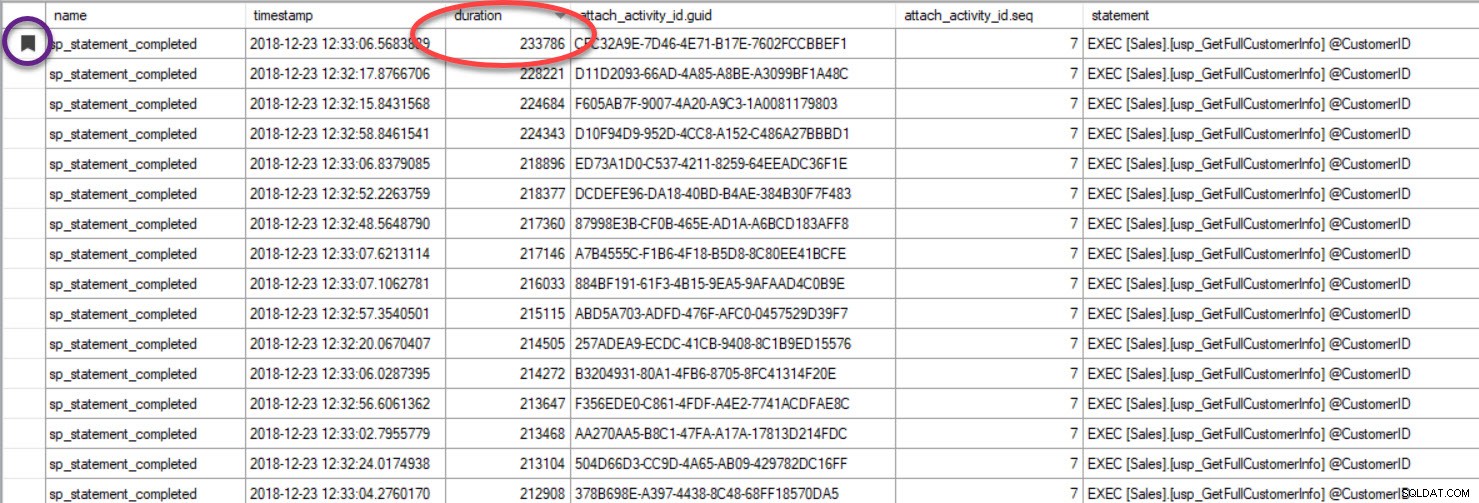
La sortie a été triée par durée (valeur la plus élevée entourée en rouge) et je l'ai mise en signet (en violet) à l'aide du bouton Basculer le signet. Si nous voulons voir les autres requêtes pour le GUID, groupez par GUID (Cliquez avec le bouton droit sur le nom de la colonne en haut, puis sélectionnez Grouper par cette colonne), puis utilisez le bouton Signet suivant pour revenir à notre requête :
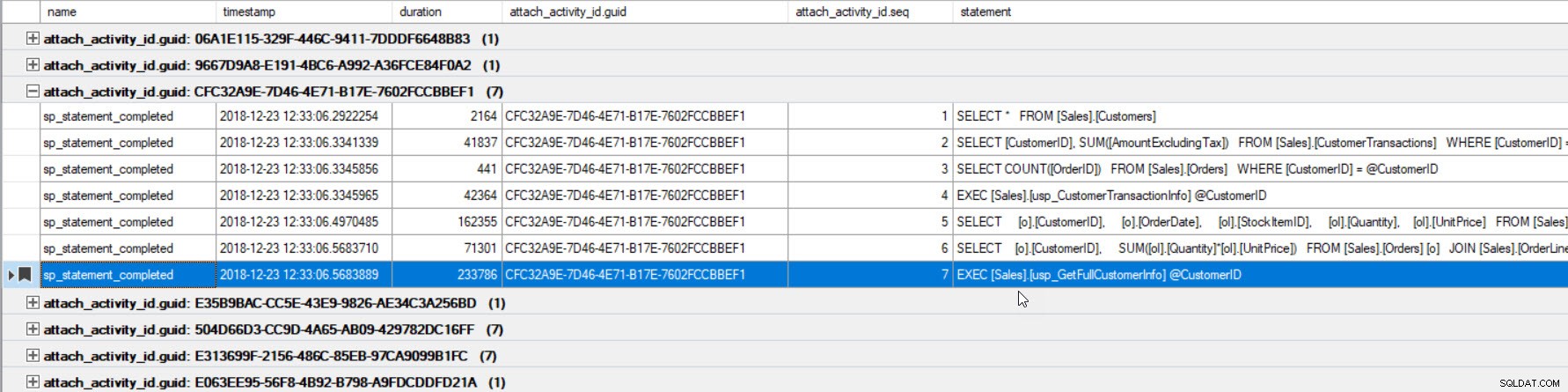
Nous pouvons maintenant voir toutes les requêtes exécutées dans la même connexion et dans l'ordre d'exécution.
Conclusion
L'option Suivre la causalité peut être extrêmement utile lors du dépannage des performances des requêtes et pour essayer de comprendre l'ordre des événements dans SQL Server. Il est également utile lors de la configuration d'une session d'événements qui utilise la cible pair_matching, pour vous assurer que vous faites correspondre le bon champ/action et trouvez le bon événement sans correspondance. Encore une fois, il s'agit d'un paramètre au niveau de la session, il doit donc être appliqué avant de démarrer la session d'événement. Pour une session en cours d'exécution, arrêtez la session d'événements, activez l'option, puis redémarrez-la.