Avez-vous déjà contacté Microsoft ou un partenaire Microsoft et discuté avec eux du coût d'une migration vers le cloud ? Si tel est le cas, vous avez peut-être entendu parler de la calculatrice Azure SQL Database DTU et vous avez peut-être également lu comment elle a été rétro-conçue par Andy Mallon. Le calculateur DTU est un outil gratuit que vous pouvez utiliser pour télécharger des métriques de performances à partir de votre serveur et utiliser les données pour déterminer le niveau de service approprié si vous deviez migrer ce serveur vers une base de données SQL Azure (ou vers un pool élastique de base de données SQL).
Pour ce faire, vous devez soit planifier, soit exécuter manuellement un script (ligne de commande ou Powershell, disponible en téléchargement sur le site Web du calculateur de DTU) pendant une période d'une charge de travail de production typique.
Si vous essayez d'analyser un environnement étendu ou si vous souhaitez analyser des données à partir de moments précis dans le temps, cela peut devenir une corvée. Dans de nombreux cas, de nombreux administrateurs de base de données disposent d'un outil de surveillance qui capture déjà des données de performances pour eux. Dans de nombreux cas, il capture probablement déjà les métriques nécessaires ou peut facilement être configuré pour capturer les données dont vous avez besoin. Aujourd'hui, nous allons voir comment tirer parti de SentryOne afin de pouvoir fournir les données appropriées au calculateur de DTU.
Pour commencer, examinons les informations extraites par l'utilitaire de ligne de commande et le script PowerShell disponibles sur le site Web de la calculatrice DTU ; il y a 4 compteurs de moniteur de performances qu'il capture :
- Processeur - % de temps processeur
- Disque logique – Lectures de disque/s
- Disque logique :écritures sur disque/s
- Base de données :octets de journal supprimés/s
La première étape consiste à déterminer si ces métriques sont déjà capturées dans le cadre de la collecte de données dans SQL Sentry. Pour la découverte, je suggère de lire ce billet de blog de Jason Hall, où il explique comment les données sont présentées et comment vous pouvez les interroger. Je ne vais pas passer en revue chaque étape ici, mais je vous encourage à lire et à mettre en signet toute cette série de blogs.
Lorsque j'ai parcouru la base de données SentryOne, j'ai constaté que 3 des 4 compteurs étaient déjà capturés par défaut. Le seul qui manquait était [Database – Log Bytes Flushed/sec] , donc je devais pouvoir l'activer. Il y avait un autre article de blog de Justin Randall qui expliquait comment faire cela.
En bref, vous pouvez interroger le [PerformanceAnalysisCounter] tableau.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Vous remarquerez que par défaut le [PerformanceAnalysisSampleIntervalID] est réglé sur 0 - cela signifie qu'il est désactivé. Vous devrez exécuter la commande suivante pour l'activer. Extrayez simplement l'ID de la requête SELECT que vous venez d'exécuter et utilisez-le dans cette MISE À JOUR :
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Après avoir exécuté la mise à jour, vous devrez redémarrer le ou les services de surveillance SentryOne pertinents pour cette cible, afin que les nouvelles données de compteur puissent être collectées.
Notez que j'ai défini le [PerformanceAnalysisSampleIntervalID] sur 1 pour que les données soient capturées toutes les 10 secondes, cependant, vous pouvez capturer ces données moins souvent pour minimiser la taille des données collectées au prix d'une moindre précision. Voir le [PerformanceAnalysisSampleInterval] tableau pour une liste de valeurs que vous pouvez utiliser.
Ne vous attendez pas à ce que les données commencent à affluer immédiatement dans les tables ; cela prendra du temps pour faire son chemin à travers le système. Vous pouvez vérifier la population avec la requête suivante :
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
Une fois que vous avez confirmé que les données s'affichent, vous devriez disposer de données pour chacune des métriques requises par le calculateur de DTU, bien que vous souhaitiez peut-être attendre pour les extraire jusqu'à ce que vous ayez un échantillon représentatif d'une charge de travail complète ou d'un cycle économique.
Si vous lisez le billet de blog de Jason, vous verrez que les données sont stockées dans diverses tables de synthèse et que chacune de ces tables de synthèse a des taux de rétention variables. Beaucoup d'entre eux sont inférieurs à ce que je voudrais si j'analyse les charges de travail sur une période donnée. Bien qu'il soit possible de les changer, ce n'est peut-être pas le plus sage. Étant donné que ce que je vous montre n'est pas pris en charge, vous voudrez peut-être éviter de trop bricoler les paramètres de SentryOne, car cela pourrait avoir un impact négatif sur les performances, la croissance ou les deux.
Afin de compenser cela, j'ai créé un script qui me permet d'extraire les données dont j'ai besoin pour les différentes tables de cumul et de stocker ces données dans leur propre emplacement, afin que je puisse contrôler ma propre rétention et ne pas interférer avec la fonctionnalité SentryOne.
TABLE :dbo.AzureDatabaseDTUData
J'ai créé une table appelée [AzureDatabaseDTUData] et stocké dans la base de données SentryOne. La procédure que j'ai créée générera automatiquement cette table si elle n'existe pas, il n'est donc pas nécessaire de le faire manuellement, sauf si vous souhaitez personnaliser son emplacement de stockage. Vous pouvez stocker cela dans une base de données séparée si vous le souhaitez, il vous suffira de modifier le script pour le faire. Le tableau ressemble à ceci :
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Procédure :dbo.Custom_CollectDTUDataForDevice
Il s'agit de la procédure stockée que vous pouvez utiliser pour extraire toutes les données spécifiques à la DTU en une seule fois (à condition que vous ayez collecté le compteur d'octets de journal pendant une durée suffisante) ou la programmer pour qu'elle s'ajoute périodiquement aux données collectées jusqu'à ce que vous êtes prêt à soumettre la sortie au calculateur DTU. Comme le tableau ci-dessus, la procédure est créée dans la base de données SentryOne, mais vous pouvez facilement la créer ailleurs, ajoutez simplement des noms en trois ou quatre parties aux références d'objet. L'interface de la procédure est la suivante :
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Remarque :Toute la procédure est un peu longue, elle est donc jointe à ce post (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Il y a quelques paramètres que vous pouvez utiliser. Chacun a une valeur par défaut, vous n'avez donc pas à les spécifier si vous êtes d'accord avec les valeurs par défaut.
- @DeviceID – Cela vous permet de spécifier si vous souhaitez collecter des données pour un serveur SQL spécifique ou pour tout. La valeur par défaut est -1, ce qui signifie copier tous les serveurs SQL surveillés. Si vous souhaitez uniquement exporter des informations pour une instance spécifique, recherchez le
DeviceIDcorrespondant à l'hôte dans le[dbo].[Device]table et transmettez cette valeur. Vous ne pouvez transmettre qu'un seul@DeviceIDà la fois, donc si vous voulez passer par un ensemble de serveurs, vous pouvez appeler la procédure plusieurs fois, ou vous pouvez modifier la procédure pour prendre en charge un ensemble de périphériques. - @DaysToPurge – Cela représente l'âge auquel vous souhaitez supprimer des données. La valeur par défaut est de 14 jours, ce qui signifie que vous n'extrairez que des données datant de moins de 14 jours, et toutes les données de plus de 14 jours dans votre tableau personnalisé seront supprimées.
Les quatre autres paramètres sont là pour la pérennité, au cas où les énumérations SentryOne pour les ID de compteur changent.
Quelques notes sur le script :
- Lorsque les données sont extraites, elles prennent la valeur maximale de la minute tronquée et l'exportent. Cela signifie qu'il y a une valeur par métrique par minute, mais c'est la valeur maximale capturée. Ceci est important en raison de la manière dont les données doivent être présentées au calculateur de DTU.
- La première fois que vous exécutez l'exportation, cela peut prendre un peu plus de temps. En effet, il extrait toutes les données possibles en fonction de vos valeurs de paramètres. À chaque exécution supplémentaire, les seules données extraites sont celles qui sont nouvelles depuis la dernière exécution, elles devraient donc être beaucoup plus rapides.
- Vous devrez programmer cette procédure pour qu'elle s'exécute selon un calendrier qui reste en avance sur le processus de purge SentryOne. Ce que j'ai fait, c'est juste créer un travail d'agent SQL à exécuter la nuit qui collecte toutes les nouvelles données depuis la nuit précédente.
- Étant donné que le processus de purge dans SentryOne peut varier en fonction de la métrique, vous pourriez vous retrouver avec des lignes dans votre copie qui ne contiennent pas les 4 compteurs pour une période donnée. Vous voudrez peut-être ne commencer à analyser vos données qu'à partir du moment où vous démarrez votre processus d'extraction.
- J'ai utilisé un bloc de code des procédures SentryOne existantes pour déterminer la table de cumul pour chaque compteur. J'aurais pu coder en dur les noms actuels des tables, cependant, en utilisant la méthode SentryOne, elle devrait être compatible avec toutes les modifications apportées aux processus de cumul intégrés.
Une fois vos données déplacées dans une table autonome, vous pouvez utiliser une requête PIVOT pour les transformer sous la forme attendue par le calculateur DTU.
Procédure :dbo.Custom_ExportDataForDTUCalculator
J'ai créé une autre procédure pour extraire les données au format CSV. Le code de cette procédure est également joint (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Il y a trois paramètres :
- @DeviceID – Smallint correspondant à l'un des appareils que vous collectez et que vous souhaitez soumettre au calculateur.
- @BeginTime – Datetime représentant l'heure de début, en heure locale; par exemple,
'2018-12-04 05:47:00.000'. La procédure sera traduite en UTC. S'il est omis, il sera collecté à partir de la valeur la plus ancienne du tableau. - @EndTime – Datetime représentant l'heure de fin, toujours en heure locale; par exemple,
'2018-12-06 12:54:00.000'. S'il est omis, il collectera jusqu'à la dernière valeur du tableau.
Un exemple d'exécution, pour obtenir toutes les données collectées pour SQLInstanceA entre le 4 décembre à 5h47 et le 6 décembre à 12h54.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Les données devront être exportées vers un fichier CSV. Ne vous préoccupez pas des données elles-mêmes ; Je me suis assuré de générer des résultats afin qu'il n'y ait aucune information d'identification sur votre serveur dans le fichier csv, juste des dates et des métriques.
Si vous exécutez la requête dans SSMS, vous pouvez cliquer avec le bouton droit et exporter les résultats; cependant, vous avez ici des options limitées et vous devrez manipuler la sortie pour obtenir le format attendu par le calculateur DTU. (N'hésitez pas à essayer et faites-moi savoir si vous trouvez un moyen de le faire.)
Je recommande simplement d'utiliser l'assistant d'exportation intégré à SSMS. Cliquez avec le bouton droit sur la base de données et accédez à Tâches -> Exporter des données. Pour votre source de données, utilisez "SQL Server Native Client" et pointez-le vers votre base de données SentryOne (ou partout où vous avez votre copie des données stockées). Pour votre destination, vous voudrez sélectionner "Flat File Destination". Naviguez jusqu'à un emplacement, donnez un nom au fichier et enregistrez le fichier au format CSV.
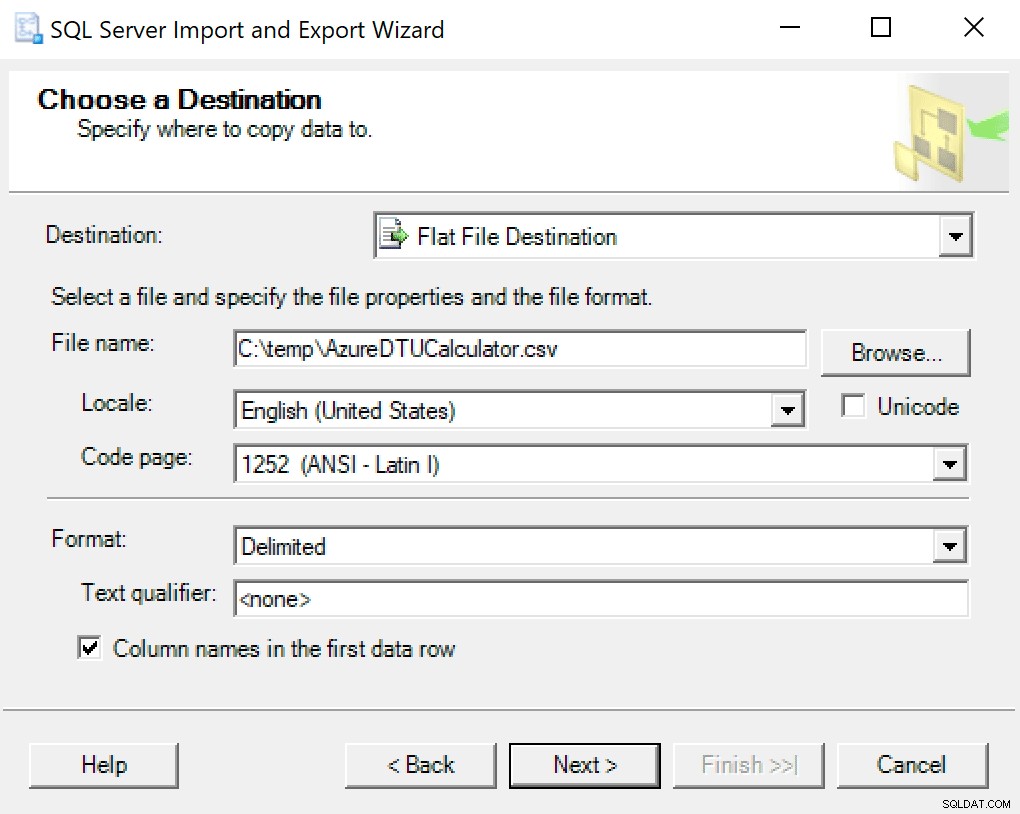
Prenez soin de ne pas toucher à la page de code ; certains peuvent renvoyer des erreurs. Je sais que 1252 fonctionne bien. Le reste des valeurs reste par défaut.
Sur l'écran suivant, sélectionnez l'option Écrire une requête pour spécifier les données à transférer .
Dans la fenêtre suivante, copiez l'appel de procédure avec vos paramètres définis. Cliquez sur suivant.
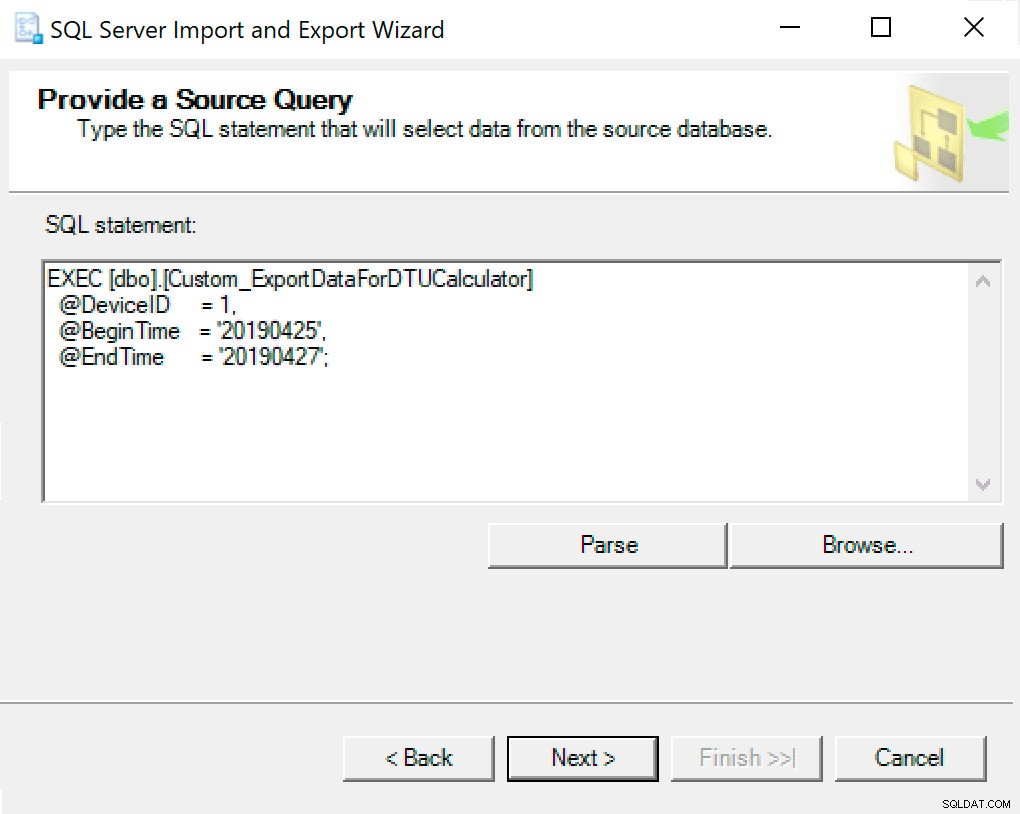
Lorsque vous arrivez à Configurer la destination du fichier plat, je laisse les options par défaut. Voici une capture d'écran au cas où la vôtre serait différente :
Frappez ensuite et courez immédiatement. Un fichier sera créé que vous utiliserez à la dernière étape.
REMARQUE :Vous pouvez créer un package SSIS à utiliser pour cela, puis transmettre vos valeurs de paramètres au package SSIS si vous allez le faire beaucoup. Cela vous éviterait de devoir passer par l'assistant à chaque fois.
Accédez à l'emplacement où vous avez enregistré le fichier et vérifiez qu'il s'y trouve. Lorsque vous l'ouvrez, il devrait ressembler à ceci :
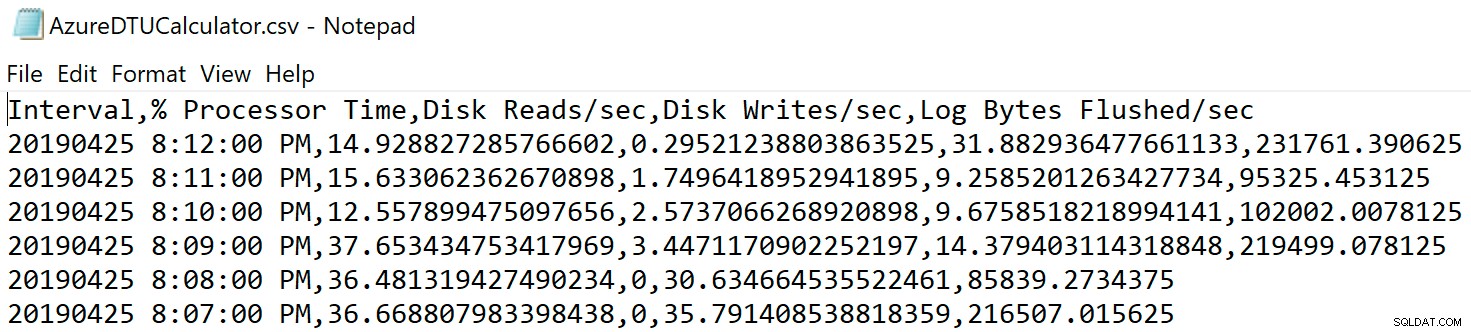
Ouvrez le site Web de la calculatrice DTU et faites défiler jusqu'à la partie qui dit "Téléchargez le fichier CSV et calculez". Entrez le nombre de cœurs dont dispose le serveur, téléchargez le fichier CSV et cliquez sur Calculer. Vous obtiendrez un ensemble de résultats comme celui-ci (cliquez sur une image pour zoomer) :
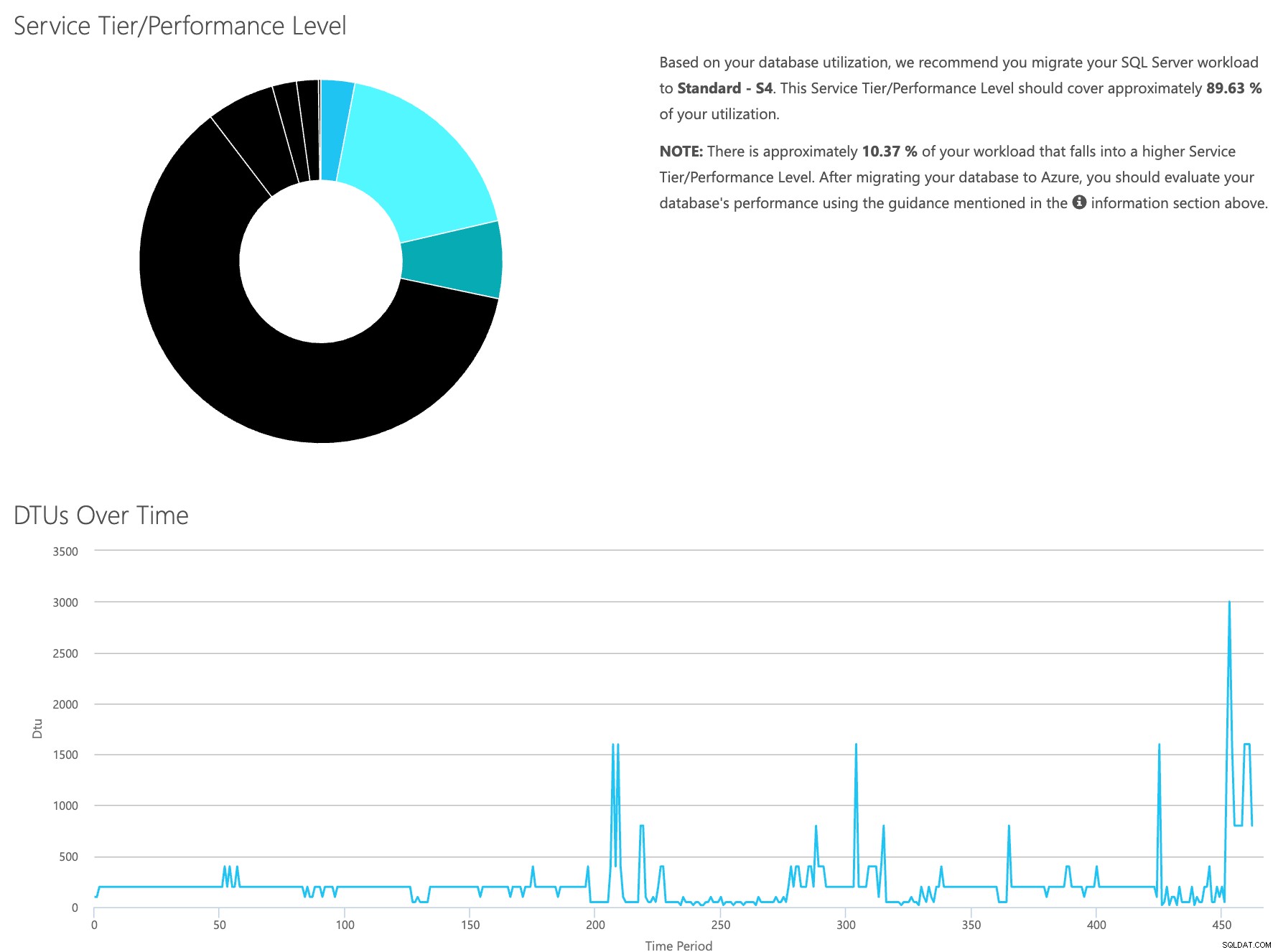
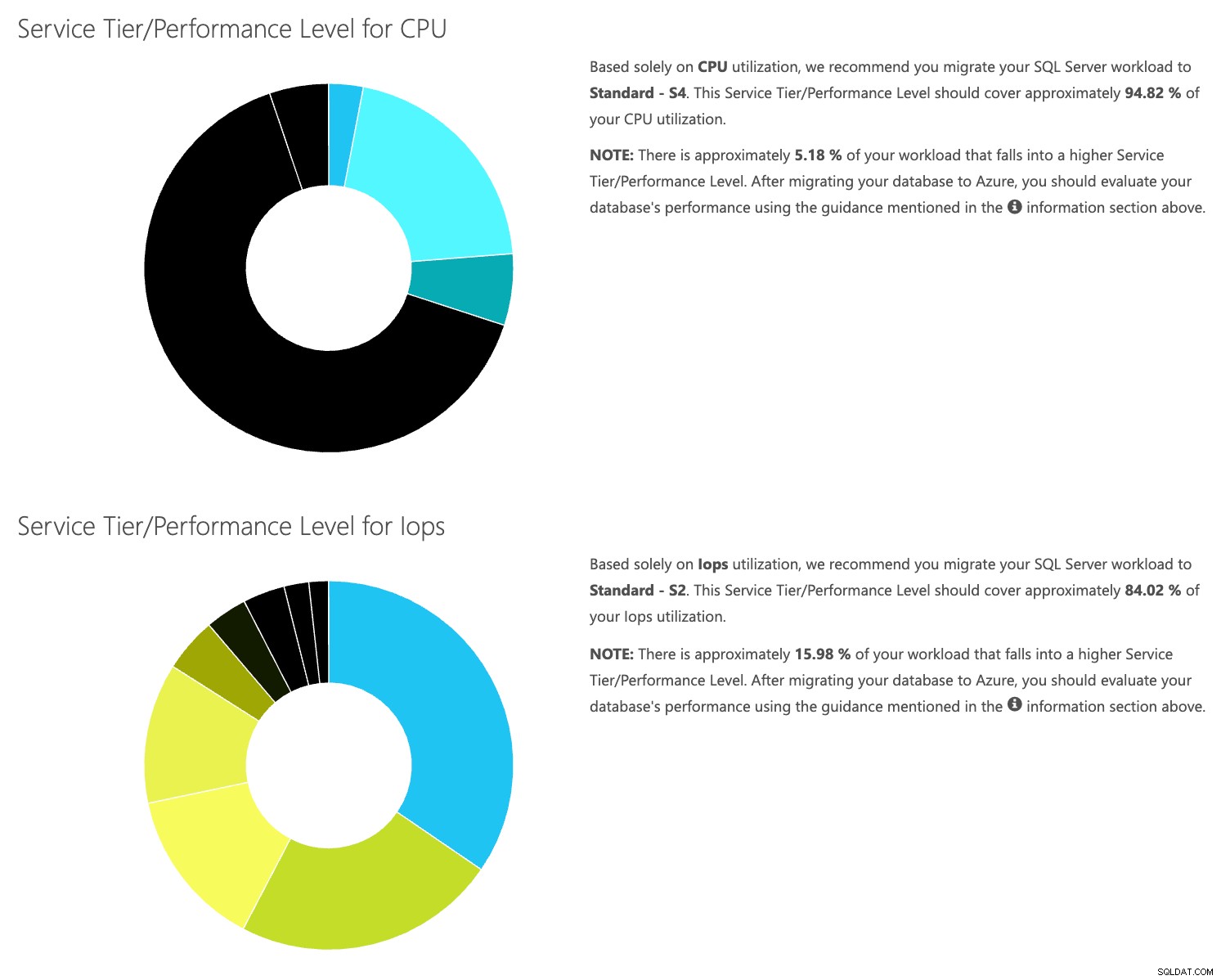
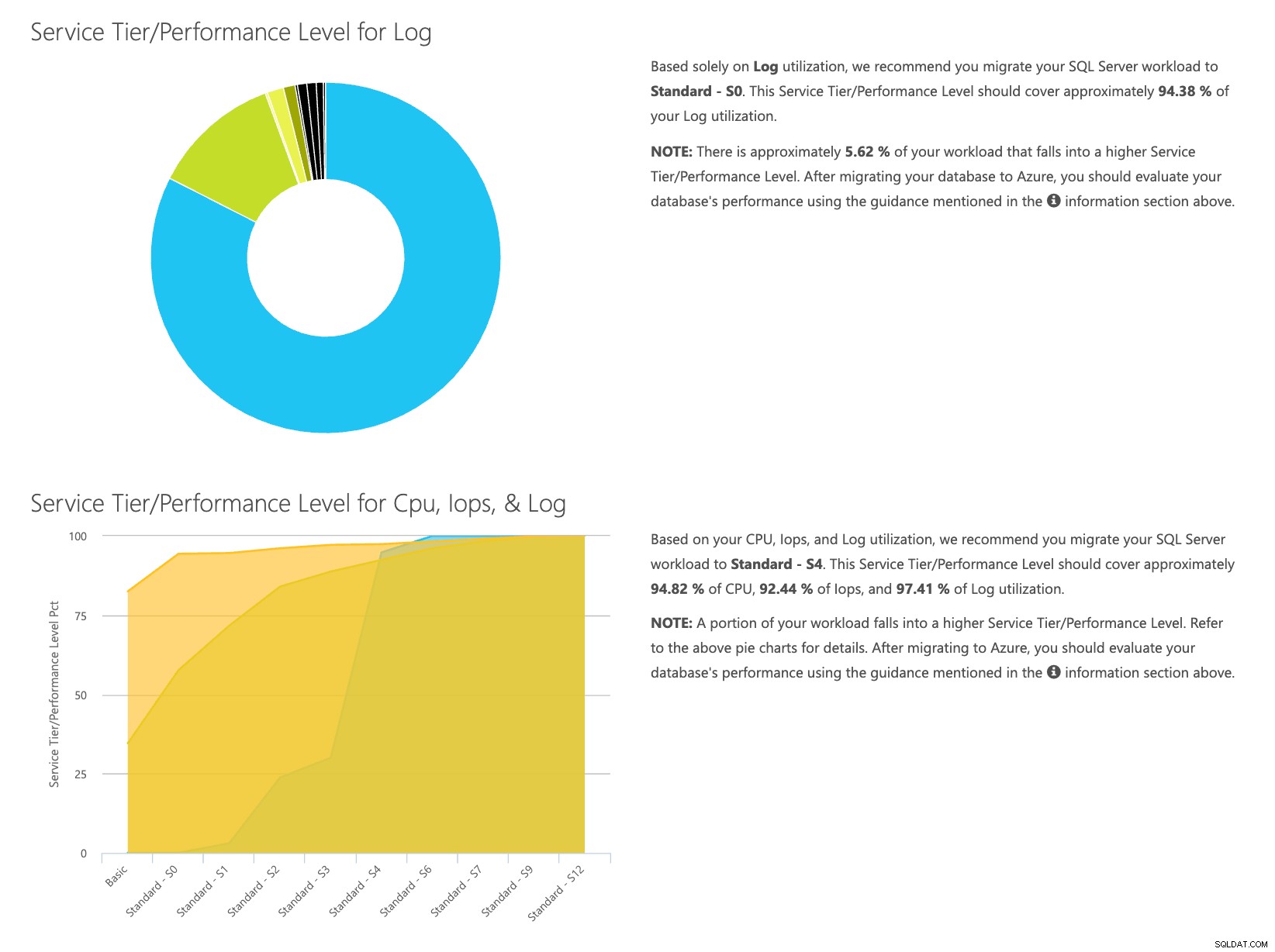
Étant donné que les données sont stockées séparément, vous pouvez analyser les charges de travail à différents moments, et vous pouvez le faire sans avoir à exécuter manuellement\planifier le script utilitaire de commande\powershell pour tout serveur que vous utilisez déjà SentryOne pour surveiller.
Pour récapituler brièvement les étapes, voici ce qu'il faut faire :
- Activez le compteur [Database – Log Bytes Flushed/sec] et vérifiez que les données sont collectées
- Copiez les données des tables SentryOne dans votre propre table (et planifiez-les le cas échéant).
- Exporter les données du nouveau tableau dans le bon format pour le calculateur DTU
- Téléchargez le fichier CSV dans le calculateur de DTU
Pour tout serveur/instance que vous envisagez de migrer vers le cloud et que vous surveillez actuellement avec SQL Sentry, il s'agit d'un moyen relativement simple d'estimer à la fois le type de niveau de service dont vous aurez besoin et le coût. Vous aurez toujours besoin de le surveiller une fois qu'il sera là-haut; pour cela, consultez SentryOne DB Sentry.
À propos de l'auteur
 Dustin Dorsey est actuellement ingénieur de gestion de base de données pour LifePoint Health, au sein duquel il dirige une équipe responsable de la gestion et de l'ingénierie des solutions dans les technologies de bases de données pour 90 hôpitaux. Il travaille avec et prend en charge SQL Server principalement dans le domaine de la santé depuis 2008 dans une capacité d'administration, d'architecture, de développement et de BI. Il est passionné par la recherche de moyens de résoudre les problèmes qui affligent le DBA quotidien et aime partager cela avec les autres. On peut le trouver en train de parler lors d'événements de la communauté SQL, ainsi que de bloguer sur DustinDorsey.com.
Dustin Dorsey est actuellement ingénieur de gestion de base de données pour LifePoint Health, au sein duquel il dirige une équipe responsable de la gestion et de l'ingénierie des solutions dans les technologies de bases de données pour 90 hôpitaux. Il travaille avec et prend en charge SQL Server principalement dans le domaine de la santé depuis 2008 dans une capacité d'administration, d'architecture, de développement et de BI. Il est passionné par la recherche de moyens de résoudre les problèmes qui affligent le DBA quotidien et aime partager cela avec les autres. On peut le trouver en train de parler lors d'événements de la communauté SQL, ainsi que de bloguer sur DustinDorsey.com.