En 2014, j'ai commencé une série d'articles de blog ici pour parler de types d'attente spécifiques et de ce qu'ils font et ne signifient pas. Cela m'a donné l'idée de créer les bibliothèques d'attente et de verrous que je maintiens (plus sur celles-ci plus tard).
Si vous lisez ceci et pensez "de quoi parle-t-il?" alors ce poste est pour vous. Je vais vous présenter les statistiques d'attente et vous expliquer à quel point elles sont essentielles pour le dépannage des performances de la charge de travail dans SQL Server.
Planification
L'exécution du code interne de SQL Server se fait à l'aide d'un mécanisme appelé threads . Chaque thread peut exécuter du code SQL Server et plusieurs threads se coordonnent lorsqu'une requête s'exécute en parallèle. Ces threads sont créés au démarrage de SQL Server, en fonction du nombre de cœurs de processeur disponibles pour SQL Server.
Les threads sont placés sur un planificateur lorsqu'une requête démarre, avec un planificateur par cœur de processeur, et ne quittez pas ce planificateur tant que la requête n'est pas terminée. Un planificateur comporte trois "parties" de base :
- Le processeur , qui a exactement un thread exécutant actuellement du code.
- La liste des serveurs , qui contient tous les threads bloqués, attendant qu'une ressource particulière soit disponible.
- La file d'attente exécutable , qui contient tous les threads capables de s'exécuter mais qui attendent d'être mis sur le processeur.
Les threads passent de l'état 1 à 2 à 3 à 1, autour et autour jusqu'à ce que la requête soit terminée.
Attend
De notre point de vue, la partie la plus intéressante de la planification est lorsqu'un thread doit attendre une ressource avant de pouvoir continuer. Voici quelques exemples :
- Un thread doit lire une page, et la page n'est pas en mémoire, donc le thread émet une E/S physique asynchrone et doit ensuite attendre, hors du processeur, jusqu'à ce que l'E/S se termine.
- Un thread doit acquérir un verrou partagé sur une ligne pour la lire, mais un autre thread détient déjà un verrou exclusif en conflit pendant qu'il met à jour la ligne.
Lorsqu'un thread rencontre le besoin d'une ressource qu'il ne peut pas obtenir, il n'a d'autre choix que de s'arrêter et d'attendre que la ressource soit disponible (le mécanisme de notification du thread sur la disponibilité des ressources dépasse le cadre de cet article). Lorsque cela se produit, SQL Server note pourquoi le thread a dû attendre et cela s'appelle le type d'attente . Voici quelques exemples :
- Lorsqu'un thread attend qu'une page soit lue en mémoire pour pouvoir être lue, le type d'attente est PAGEIOLATCH_SH (si le fil attend une page qu'il va changer, le type d'attente est PAGEIOLATCH_EX ).
- Lorsqu'un thread attend un verrou de partage sur une ligne, le type d'attente est LCK_M_S (verrouillage-mode-partage)
SQL Server garde également une trace de la durée d'attente du thread. C'est ce qu'on appelle le temps d'attente des ressources , et est généralement connu sous le nom de temps d'attente .
Statistiques d'attente
L'ensemble global de métriques indiquant combien de threads ont attendu quelles ressources et pendant combien de temps en moyenne est appelé statistiques d'attente . Ces informations sont extrêmement utiles pour dépanner les performances des charges de travail, car vous pouvez facilement identifier les goulots d'étranglement potentiels.
L'idée de base est que SQL Server dispose des informations sur la raison pour laquelle les threads doivent s'arrêter et attendre, et sur ce qu'ils attendent. Ainsi, plutôt que d'avoir à deviner par où commencer le dépannage, une analyse minutieuse des statistiques d'attente peut généralement vous orienter dans la direction à prendre.
Par exemple, si la majorité des attentes sur le serveur sont PAGEIOLATCH_SH , cela peut indiquer qu'il y a une pression de mémoire sur le serveur, ou que des requêtes effectuent des balayages de table volumineux au lieu d'utiliser des index non clusterisés, ou qu'il y a un problème avec le sous-système d'E/S sous-jacent, ou un certain nombre d'autres raisons.
Il existe un grand nombre de types d'attente, mais la plupart d'entre eux n'apparaissent pas très souvent, il existe donc un ensemble de base que vous verrez encore et encore sur vos serveurs. Il est essentiel de comprendre ce que cela signifie et comment les étudier afin de ne pas succomber à ce que j'appelle un «réglage des performances instinctif» et de perdre du temps et des efforts à essayer de résoudre un problème qui n'en est pas vraiment un. J'ai écrit une série d'articles de blog ici qui entrent dans les détails là-bas, et Aaron Bertrand a également écrit un article récapitulatif des 10 principales statistiques d'attente l'année dernière.
Suivi des attentes
Il existe plusieurs façons de suivre les temps d'attente. Le plus simple est de regarder quelles attentes se produisent sur le serveur en ce moment, en utilisant un script qui examine les sys.dm_os_waiting_tasks DMV. Vous pouvez trouver un script pour le faire ici, et qui a des URL générées automatiquement dans la bibliothèque d'attente.
Une autre façon consiste à examiner les statistiques d'attente agrégées pour l'ensemble du serveur, avec un script qui examine les sys.dm_os_wait_stats DMV. Vous pouvez trouver un script pour le faire ici, et qui a des URL générées automatiquement dans la bibliothèque d'attente. Vous devez cependant être prudent avec cette méthode, car cela affichera toutes les attentes qui se sont produites depuis le démarrage du serveur. Une meilleure façon est de suivre les attentes sur de petits intervalles, disons une demi-heure, et un script pour le faire est ici.
Vous pouvez également obtenir des statistiques d'attente à l'aide du complément Server Reports du nouvel outil Azure Data Studio et à l'aide de Query Store à partir de SQL Server 2017.
N'oubliez pas que vous devez toujours comprendre ce que signifient les types d'attente une fois que vous avez collecté les statistiques.
Ressources d'attente
Pour vous aider, et parce que Microsoft ne dispose pas de documentation sur la façon d'interpréter les statistiques d'attente, en 2016, j'ai publié une bibliothèque de types d'attente, avec des détails sur des centaines de types d'attente courants et comment les résoudre. Vous pouvez accéder à la bibliothèque à l'adresse https://www.SQLskills.com/help/waits. Et puis en 2017, SentryOne a créé un système automatisé pour fournir une infographie pour chaque page de la bibliothèque que vous pouvez rapidement utiliser pour voir si le type d'attente qui vous intéresse est vraiment courant ou non (voir ce post pour plus de détails) . Un exemple d'infographie est ci-dessous, pour le PAGEIOLATCH_SH type d'attente :
Sur l'axe horizontal se trouve une échelle (commutable entre linéaire et logarithmique) du pourcentage d'instances (surveillées à distance par SentryOne) qui ont connu cette attente au cours du mois calendaire précédent, et sur l'axe vertical se trouve le pourcentage de temps que les instances qui ont connu cette attente wait avait en fait un thread en attente de ce type d'attente.
Une autre ressource pour vous aider à comprendre les temps d'attente est un cours de formation en ligne que j'ai enregistré pour Pluralsight - voir ici.
À tout le moins, vous devriez lire les différents articles de blog dans les sections Statistiques d'attente et Suivi des attentes ci-dessus.
Suivi des attentes à l'aide des outils SentryOne
SQL Sentry suit automatiquement les attentes au niveau de l'instance au fil du temps, de sorte que vous n'ayez pas à attraper des attentes élevées "sur le coup". Quelqu'un s'est plaint d'un système lent hier après-midi ou d'un rapport qui a expiré mardi dernier ? Aucun problème. Vous pouvez creuser dans toutes les attentes à n'importe quel moment ou sur une plage, et les corréler avec diverses autres mesures de performances collectées à l'époque - qu'il s'agisse d'autres tendances sur le tableau de bord, comme la sauvegarde ou l'activité d'E/S de la base de données, sauter à tous les principales commandes SQL qui s'exécutaient dans la même fenêtre, enquêtant sur les blocages de longue durée, ou utilisez des lignes de base pour comparer le profil d'attente à d'autres périodes.
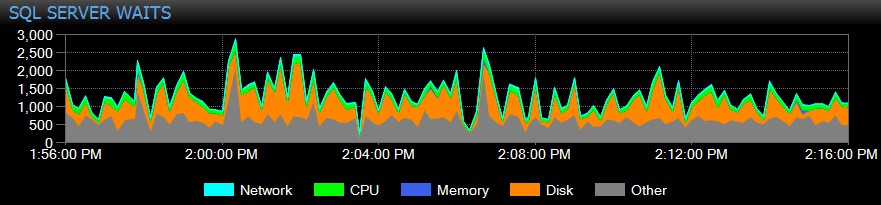
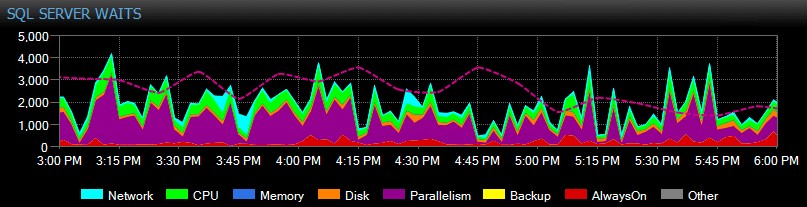
Vous pouvez même personnaliser les attentes collectées ou non, modifier les catégories présentées visuellement et créer des alertes intelligentes et/ou des réponses à des scénarios d'attente spécifiques. Beaucoup de nos clients utilisent SQL Sentry pour se concentrer sur les problèmes de performances réels liés aux attentes, car cela leur permet d'ignorer une grande partie du bruit qui n'est qu'une activité normale des threads SQL Server.
Résumé
Comme vous pouvez le voir dans les informations ci-dessus, les attentes se produisent toujours dans SQL Server, car c'est ainsi que fonctionnent la planification des threads et les systèmes multithreads. Ils sont l'un des outils les plus puissants de votre boîte à outils de dépannage, donc si vous ne les utilisez pas déjà, il est temps de commencer. La courbe d'apprentissage est courte et raide - une fois que vous avez exécuté les différentes requêtes et outils à quelques reprises, vous vous y habituerez rapidement, puis il s'agira de lire les guides pour les attentes que vous voyez et déterminer s'ils sont un problème ou non.
Bon dépannage !