En tant que consultant travaillant avec SQL Server, on me demande souvent d'examiner un serveur qui semble avoir des problèmes de performances. Lors du triage sur le serveur, je pose certaines questions, telles que :quelle est votre utilisation normale du processeur, quelles sont vos latences moyennes de disque, quelle est votre utilisation normale de la mémoire, etc. La réponse est généralement « nous ne savons pas » ou « nous ne collectons pas ces informations régulièrement ». Ne pas avoir de référence récente rend très difficile de savoir à quoi ressemble un comportement anormal. Si vous ne savez pas ce qu'est un comportement normal, comment savoir avec certitude si les choses vont mieux ou moins bien ? J'utilise souvent les expressions « si vous ne le surveillez pas, vous ne pouvez pas le mesurer » et « si vous ne le mesurez pas, vous ne pouvez pas le gérer ».
Du point de vue de la surveillance, au minimum, les organisations doivent surveiller les tâches ayant échoué telles que les sauvegardes, la maintenance des index, DBCC CHECKDB et toute autre tâche importante. Il est facile de configurer des notifications d'échec pour ceux-ci ; Cependant, vous avez également besoin d'un processus en place pour vous assurer que les travaux s'exécutent comme prévu. J'ai vu des travaux qui se bloquent et ne se terminent jamais. Une notification d'échec ne déclencherait pas d'alarme puisque le travail ne réussit ou n'échoue jamais.
À partir d'une base de performances, plusieurs indicateurs clés doivent être capturés. J'ai créé un processus que j'utilise avec des clients qui capture régulièrement des mesures clés et stocke ces valeurs dans une base de données d'utilisateurs. Mon processus est simple :une base de données dédiée avec des procédures stockées qui utilisent des scripts communs qui insèrent les jeux de résultats dans des tables. J'ai des travaux SQL Agent pour exécuter les procédures stockées à intervalles réguliers et un script de nettoyage pour purger les données de plus de X jours. Les métriques que je capture toujours incluent :
Espérance de vie des pages :PLE est probablement l'un des meilleurs moyens d'évaluer si votre système est soumis à une pression de mémoire interne. La plupart des systèmes ont des valeurs PLE qui fluctuent pendant les charges de travail normales. J'aime suivre la tendance de ces valeurs pour savoir quelles sont les valeurs minimales, moyennes et maximales. J'aime essayer de comprendre ce qui a causé la chute du PLE à certains moments de la journée pour voir si ces processus peuvent être réglés. Souvent, quelqu'un effectue une analyse de table et vide le pool de mémoire tampon. Être capable d'indexer correctement ces requêtes peut aider. Assurez-vous simplement que vous surveillez le bon compteur PLE - voir ici .
Utilisation du processeur :Le fait d'avoir une ligne de base pour l'utilisation du processeur vous permet de savoir si votre système subit soudainement une pression sur le processeur. Souvent, lorsqu'un utilisateur se plaint de problèmes de performances, il constate que le processeur semble élevé. Par exemple, si le processeur oscille autour de 80 %, ils pourraient trouver cela préoccupant, mais si le processeur était également à 80 % au cours de la même période les semaines précédentes lorsqu'aucun problème n'a été signalé, la probabilité que le processeur soit le problème est très faible. Le processeur de tendance ne sert pas uniquement à capturer les pics de processeur et à rester à une valeur constamment élevée. J'ai de nombreuses histoires sur le moment où j'ai été amené dans un pont de conférence de gravité un parce qu'il y avait un problème avec une application. En tant que DBA, je portais le chapeau de "Default Blame Acceptor". Lorsque l'équipe d'application a déclaré qu'il y avait un problème avec la base de données, c'était à moi de prouver que ce n'était pas le cas, le serveur de base de données était coupable jusqu'à preuve du contraire. Je me souviens très bien d'un incident où l'équipe d'application était convaincue que le serveur de base de données rencontrait des problèmes car les utilisateurs ne pouvaient pas se connecter. Ils avaient lu sur Internet que SQL Server pouvait souffrir d'une pénurie de pool de threads s'il refusait les connexions. J'ai sauté sur le serveur et j'ai commencé à regarder les ressources et les processus en cours d'exécution. En quelques minutes, j'ai signalé que le serveur en question s'ennuyait beaucoup. Sur la base de nos mesures de base, le processeur était généralement de 60 % et il était inactif d'environ 20 %, l'espérance de vie des pages était nettement supérieure à la normale, et il n'y avait aucun verrouillage ou blocage, les E/S avaient l'air bien, aucune erreur dans les journaux, et le nombre de sessions était d'environ 1/3 de leur nombre normal. J'ai ensuite fait le commentaire :"Il semble que les utilisateurs n'atteignent même pas le serveur de base de données." Cela a attiré l'attention des gens du réseau et ils ont réalisé qu'une modification qu'ils avaient apportée à l'équilibreur de charge ne fonctionnait pas correctement et ils ont déterminé que plus de 50 % des connexions étaient mal acheminées et ne parvenaient pas au serveur de base de données. Si je n'avais pas su quelle était la ligne de base, il nous aurait fallu beaucoup plus de temps pour atteindre la résolution.
E/S disque :La capture des métriques de disque est très importante. Le DMV sys.dm_io_virtual_file_stats est cumulatif depuis le dernier redémarrage du serveur. La capture de vos latences d'E/S sur un intervalle de temps vous donnera une référence de ce qui est normal pendant cette période. S'appuyer sur la valeur cumulée peut vous donner des données faussées provenant d'activités après les heures de bureau ou de longues périodes d'inactivité du système. Paul en a parlé ici .
Tailles des fichiers de base de données :Disposer d'un inventaire de vos bases de données comprenant la taille des fichiers, la taille utilisée, l'espace libre, etc. peut vous aider à prévoir la croissance de la base de données. On me demande souvent de prévoir la quantité de stockage nécessaire pour un serveur de base de données au cours de l'année à venir. Sans connaître la tendance de croissance hebdomadaire ou mensuelle, je n'ai aucun moyen de proposer intelligemment un chiffre. Une fois que j'ai commencé à suivre ces valeurs, je peux correctement suivre cette tendance. En plus des tendances, je pouvais également trouver quand il y avait une croissance inattendue de la base de données. Lorsque je constate une croissance inattendue et que j'enquête, je constate généralement que quelqu'un a dupliqué une table pour effectuer des tests (oui, en production !) Ou a effectué un autre processus ponctuel. Le suivi de ce type de données et la capacité de réagir en cas d'anomalies permettent de montrer que vous êtes proactif et que vous surveillez vos systèmes.
Statistiques d'attente :la surveillance des statistiques d'attente peut vous aider à déterminer la cause de certains problèmes de performances. De nombreux nouveaux administrateurs de base de données s'inquiètent lorsqu'ils commencent à rechercher des statistiques d'attente et ne réalisent pas que les attentes se produisent toujours, et c'est exactement la façon dont fonctionne le système de planification de SQL Server. Il y a aussi beaucoup d'attentes qui peuvent être considérées comme bénignes, ou pour la plupart inoffensives. Paul Randal exclut ces attentes pour la plupart inoffensives dans son script populaire de statistiques d'attente. Paul a également construit une vaste bibliothèque des différents types d'attente et classes de verrouillage avec des descriptions et d'autres informations sur le dépannage des attentes et des verrous.
J'ai documenté mon processus de collecte de données et vous pouvez trouver le code sur mon blog . En fonction de la situation et des types de problèmes qu'un client peut rencontrer, je peux également souhaiter capturer des mesures supplémentaires. Glenn Berry a blogué sur un processus qu'il a mis en place qui capture le nombre moyen de tâches, le nombre moyen de tâches exécutables, le nombre moyen d'E/S en attente, l'utilisation du processeur du processus SQL Server et l'espérance de vie moyenne des pages sur tous les nœuds NUMA. Une recherche rapide sur Internet fera apparaître plusieurs autres processus de collecte de données que les gens ont partagés, même l'équipe SQL Server Tiger a un processus qui utilise T-SQL et PowerShell.
L'utilisation d'une base de données personnalisée et la création de votre propre package de collecte de données est une solution valable pour capturer une ligne de base, mais la plupart d'entre nous ne sont pas dans le domaine de la création de solutions de surveillance SQL Server complètes. Il y a beaucoup plus qu'il serait utile de capturer, des choses comme les requêtes longues, les requêtes principales et les procédures stockées basées sur la mémoire, les E/S et le processeur, les blocages, la fragmentation des index, les transactions par seconde, et bien plus encore. Pour cela, je recommande toujours aux clients d'acheter un outil de surveillance tiers. Ces fournisseurs se spécialisent dans le suivi des dernières tendances et fonctionnalités de SQL Server afin que vous puissiez consacrer votre temps à vous assurer que SQL Server est aussi stable et rapide que possible.
Des solutions comme SQL Sentry (pour SQL Server) et DB Sentry (pour Azure SQL Database) capturent toutes ces métriques pour vous et vous permettent de créer facilement différentes lignes de base. Vous pouvez avoir une ligne de base normale, une fin de mois, une fin de trimestre, etc. Vous pouvez ensuite appliquer la ligne de base et voir visuellement en quoi les choses sont différentes. Plus important encore, vous pouvez configurer n'importe quel nombre d'alertes pour diverses conditions et être averti lorsque les métriques dépassent vos seuils.
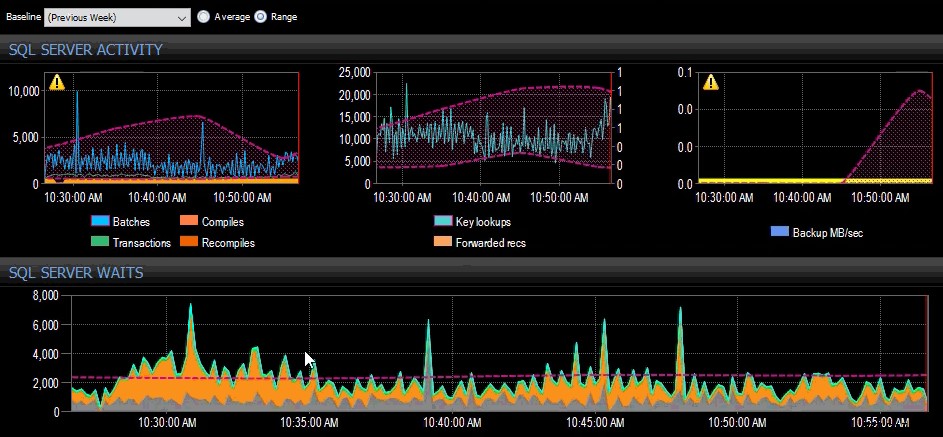 La référence de la semaine dernière a été appliquée à plusieurs métriques SQL Server sur le tableau de bord SQL Sentry.
La référence de la semaine dernière a été appliquée à plusieurs métriques SQL Server sur le tableau de bord SQL Sentry.
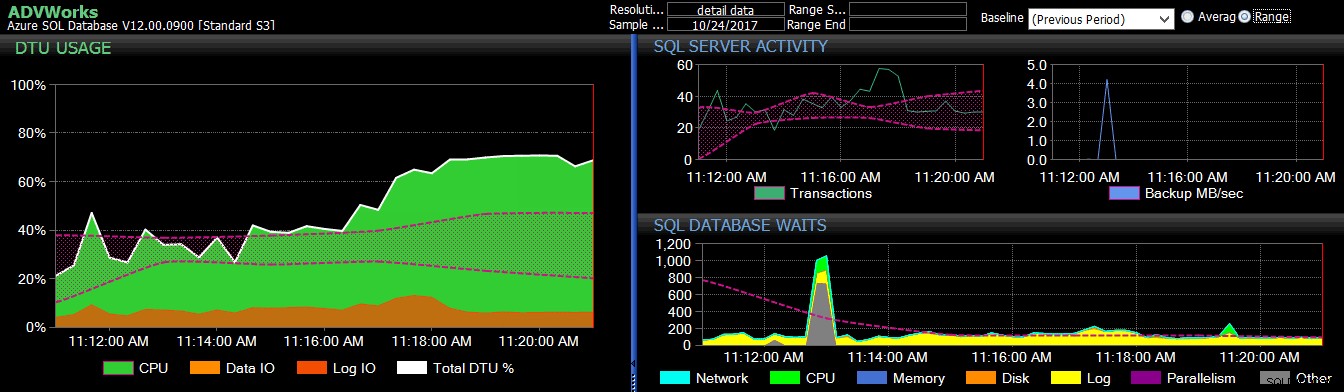 La référence de la période précédente s'appliquait à plusieurs métriques Azure SQL Database sur le tableau de bord DB Sentry.
La référence de la période précédente s'appliquait à plusieurs métriques Azure SQL Database sur le tableau de bord DB Sentry.
Pour plus d'informations sur les lignes de base dans SentryOne, consultez ces articles sur leur blog d'équipe, ou cette vidéo de 2 minutes du mardi . Vous souhaitez télécharger une version d'évaluation ? Ils vous ont également couvert .