L'un des termes les plus courants dans les discussions sur le réglage des performances de SQL Server est statistiques d'attente . Cela remonte à loin, même avant ce document Microsoft de 2006, "SQL Server 2005 Waits and Queues".
Les attentes ne sont absolument pas tout, et cette méthodologie n'est pas la seule façon de régler une instance, sans parler d'une requête individuelle. En fait, les attentes sont souvent inutiles lorsque tout ce que vous avez est la requête qui les a subies, et aucun contexte environnant, surtout longtemps après les faits. C'est parce que, très souvent, la chose qu'une requête attend n'est pas la faute de cette requête . Comme tout, il y a des exceptions, mais si vous choisissez un outil ou un script uniquement parce qu'il offre cette fonctionnalité très spécifique, je pense que vous vous rendez un mauvais service. J'ai tendance à suivre un conseil que Paul Randal m'a donné il y a quelque temps :
… généralement, je recommande de commencer par des attentes d'instance entières. Je ne commencerai jamais dépannage en examinant les attentes de requêtes individuelles.
De temps en temps, oui, vous voudrez peut-être approfondir une requête individuelle et voir ce qu'elle attend; en fait, Microsoft a récemment ajouté des statistiques d'attente au niveau de la requête à showplan pour faciliter cette analyse. Mais ces chiffres ne vous aideront généralement pas à ajuster les performances de votre instance dans son ensemble, à moins qu'ils ne vous aident à signaler quelque chose qui affecte également l'ensemble de votre charge de travail. Si vous voyez une requête d'hier qui a duré 5 minutes et que vous remarquez que son type d'attente était LCK_M_S , qu'allez-vous faire à ce sujet maintenant? Comment allez-vous retrouver ce qui bloquait réellement la requête et causait ce type d'attente ? Cela peut avoir été causé par une transaction qui n'a pas été validée pour une autre raison, mais vous ne pouvez pas voir cela si vous ne pouvez pas voir l'état de l'ensemble du système et que vous vous concentrez uniquement sur les requêtes individuelles et les attentes qu'elles ont subies.
Jason Hall (@SQLSaurus) a mentionné quelque chose en passant qui m'intéressait également. Il a déclaré que si les statistiques d'attente au niveau des requêtes étaient une partie si importante des efforts de réglage, cette méthodologie aurait été intégrée dans Query Store dès le départ. Il a été ajouté récemment (dans SQL Server 2017). Mais vous n'obtenez toujours pas de statistiques d'attente par exécution ; vous obtenez des moyennes au fil du temps, comme les statistiques de requête et les statistiques de procédure que vous voyez dans les DMV. Ainsi, des anomalies soudaines peuvent être apparentes sur la base d'autres mesures capturées par exécution de requête, mais pas sur la base des moyennes des temps d'attente qui sont tracées sur tous exécutions. Vous pouvez personnaliser la plage sur laquelle les attentes sont agrégées, mais sur les systèmes occupés, cela peut ne pas être suffisamment précis pour faire ce que vous pensez qu'il va faire pour vous.
Le but de cet article est de discuter de certains des types d'attente les plus courants que nous voyons dans notre clientèle, et du type d'actions que vous pouvez (et ne devriez pas) prendre lorsqu'elles se produisent. Nous avons une base de données de statistiques d'attente anonymes que nous collectons auprès de nos clients Cloud Sync depuis un certain temps, et depuis mai 2017, nous montrons à tout le monde à quoi cela ressemble sur la bibliothèque SQLskills Waits.
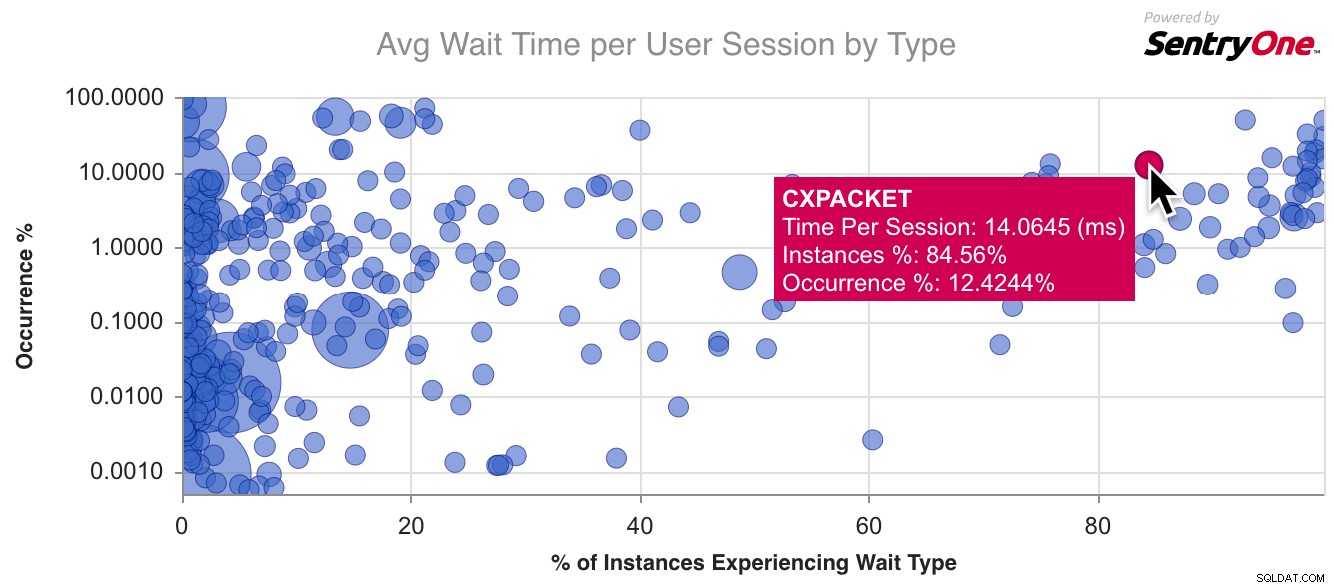
Paul parle de la raison d'être de la bibliothèque et aussi de notre intégration avec ce service gratuit. Fondamentalement, vous recherchez un type d'attente que vous rencontrez ou qui vous intéresse, et il explique ce que cela signifie et ce que vous pouvez faire à ce sujet. Nous complétons ces informations qualitatives par un graphique montrant la prévalence de l'attente actuelle parmi notre base d'utilisateurs, en la comparant à tous les autres types d'attente que nous voyons, afin que vous puissiez rapidement savoir si vous avez affaire à un type d'attente commun ou à quelque chose d'un peu plus exotique. (Gardez à l'esprit que SQL Sentry n'inclut pas les attentes bénignes, en arrière-plan et en file d'attente qui représentent du bruit et que la plupart des scripts sont filtrés, comme WAITFOR ou LAZYWRITER_SLEEP - ce ne sont tout simplement pas des sources de problèmes de performances.)
Voici un exemple de graphique pour CXPACKET , le type d'attente le plus courant :
J'ai commencé à aller un peu plus loin que cela, en cartographiant certains des types d'attente les plus courants et en notant certaines des propriétés qu'ils partageaient. Traduit en questions qu'un tuner pourrait avoir sur un type d'attente qu'il rencontre :
- Le type d'attente peut-il être résolu au niveau de la requête ?
- Le principal symptôme de l'attente est-il susceptible d'affecter d'autres requêtes ?
- Est-il probable que vous ayez besoin de plus d'informations en dehors du contexte d'une seule requête et des types d'attente rencontrés pour "résoudre" le problème ?
Lorsque j'ai décidé d'écrire cet article, mon objectif était simplement de regrouper les types d'attente les plus courants, puis de commencer à prendre des notes à leur sujet concernant les questions ci-dessus. Jason a tiré les plus courants de la bibliothèque, puis j'ai dessiné des égratignures de poulet sur un tableau blanc, que j'ai ensuite un peu rangé. Cette recherche initiale a conduit à une conférence que Jason a donnée sur la dernière croisière TechOutbound SQL en Alaska. Je suis un peu gêné qu'il ait organisé une discussion des mois avant que je puisse terminer ce post, alors allons-y. Voici les principales attentes que nous voyons (qui correspondent en grande partie à l'enquête de Paul de 2014), mes réponses aux questions ci-dessus et quelques commentaires sur chacune :
Pour interagir avec les liens du tableau ci-dessous, veuillez visiter cette page sur un écran plus large.
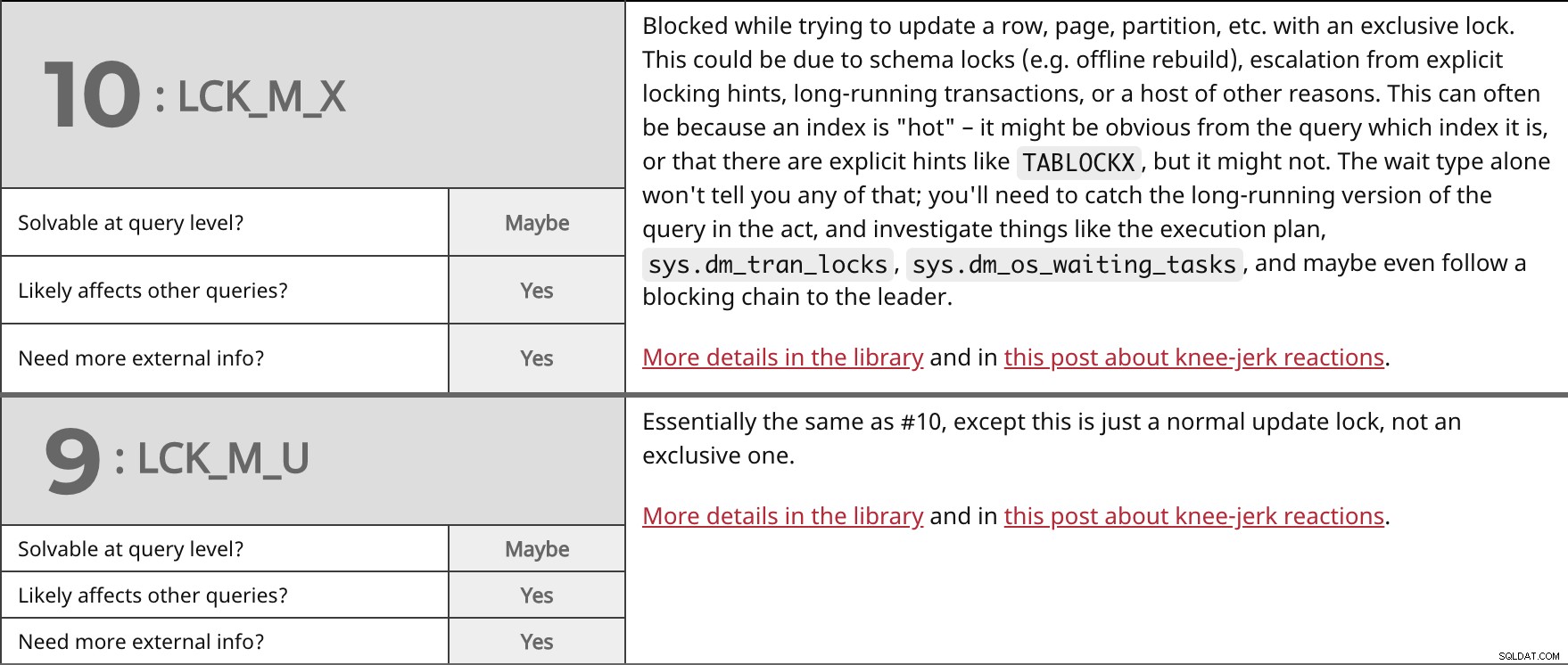
Bloqué lors de la tentative de mise à jour d'une ligne, d'une page, d'une partition, etc. avec un verrou exclusif. Cela peut être dû à des verrous de schéma (par exemple, une reconstruction hors ligne), à une escalade à partir d'indications de verrouillage explicites, à des transactions de longue durée ou à une foule d'autres raisons. Cela peut souvent être dû au fait qu'un index est "chaud" - il peut être évident d'après la requête de quel index il s'agit, ou qu'il existe des indices explicites comme TABLOCKX , mais peut-être pas. Le type d'attente seul ne vous dira rien de tout cela; vous devrez attraper la version longue de la requête dans l'acte et enquêter sur des choses comme le plan d'exécution, sys.dm_tran_locks , sys.dm_os_waiting_tasks , et peut-être même suivre une chaîne de blocage jusqu'au leader. Plus de détails dans la bibliothèque et dans cet article sur les réactions instinctives. | ||
| Résoluble au niveau de la requête ? | Peut-être | |
| Oui | ||
| Besoin de plus d'informations externes ? | Oui | |
|
Essentiellement le même que #10, sauf qu'il s'agit juste d'un verrou de mise à jour normal, pas exclusif. Plus de détails dans la bibliothèque et dans cet article sur les réactions instinctives. | ||
| Résoluble au niveau de la requête ? | Peut-être | |
| Oui | ||
| Besoin de plus d'informations externes ? | Oui | |
|
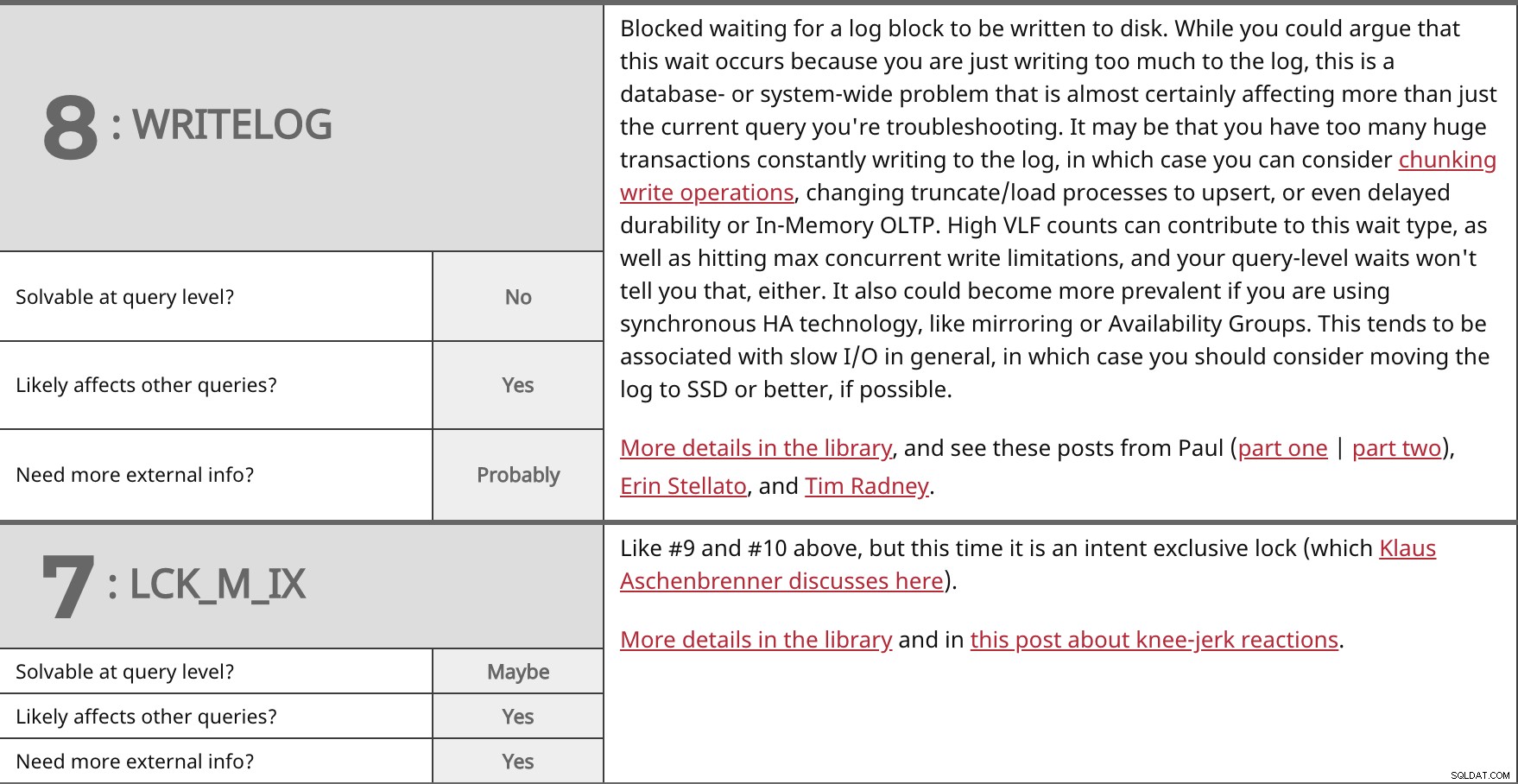
Bloqué en attente qu'un bloc de journal soit écrit sur le disque. Bien que vous puissiez affirmer que cette attente se produit parce que vous écrivez trop dans le journal, il s'agit d'un problème à l'échelle de la base de données ou du système qui affecte certainement plus que la requête actuelle que vous résolvez. Il se peut que vous ayez trop de transactions énormes qui écrivent constamment dans le journal, auquel cas vous pouvez envisager de regrouper les opérations d'écriture, de modifier les processus de troncature/chargement en upsert, ou même de retarder la durabilité ou l'OLTP en mémoire. Un nombre élevé de VLF peut contribuer à ce type d'attente, ainsi qu'à l'atteinte des limites maximales d'écriture simultanée, et vos attentes au niveau de la requête ne vous le diront pas non plus. Cela pourrait également devenir plus répandu si vous utilisez la technologie HA synchrone, comme la mise en miroir ou les groupes de disponibilité. Cela a tendance à être associé à des E/S lentes en général, auquel cas vous devriez envisager de déplacer le journal vers SSD ou mieux, si possible. Plus de détails dans la bibliothèque et consultez ces messages de Paul (première partie | deuxième partie), Erin Stellato et Tim Radney. | ||
| Résoluble au niveau de la requête ? | Non | |
| Oui | ||
| Besoin de plus d'informations externes ? | Probablement | |
|
Comme #9 et #10 ci-dessus, mais cette fois c'est un verrou exclusif d'intention (dont Klaus Aschenbrenner parle ici). Plus de détails dans la bibliothèque et dans cet article sur les réactions instinctives. | ||
| Résoluble au niveau de la requête ? | Peut-être | |
| Oui | ||
| Besoin de plus d'informations externes ? | Oui | |
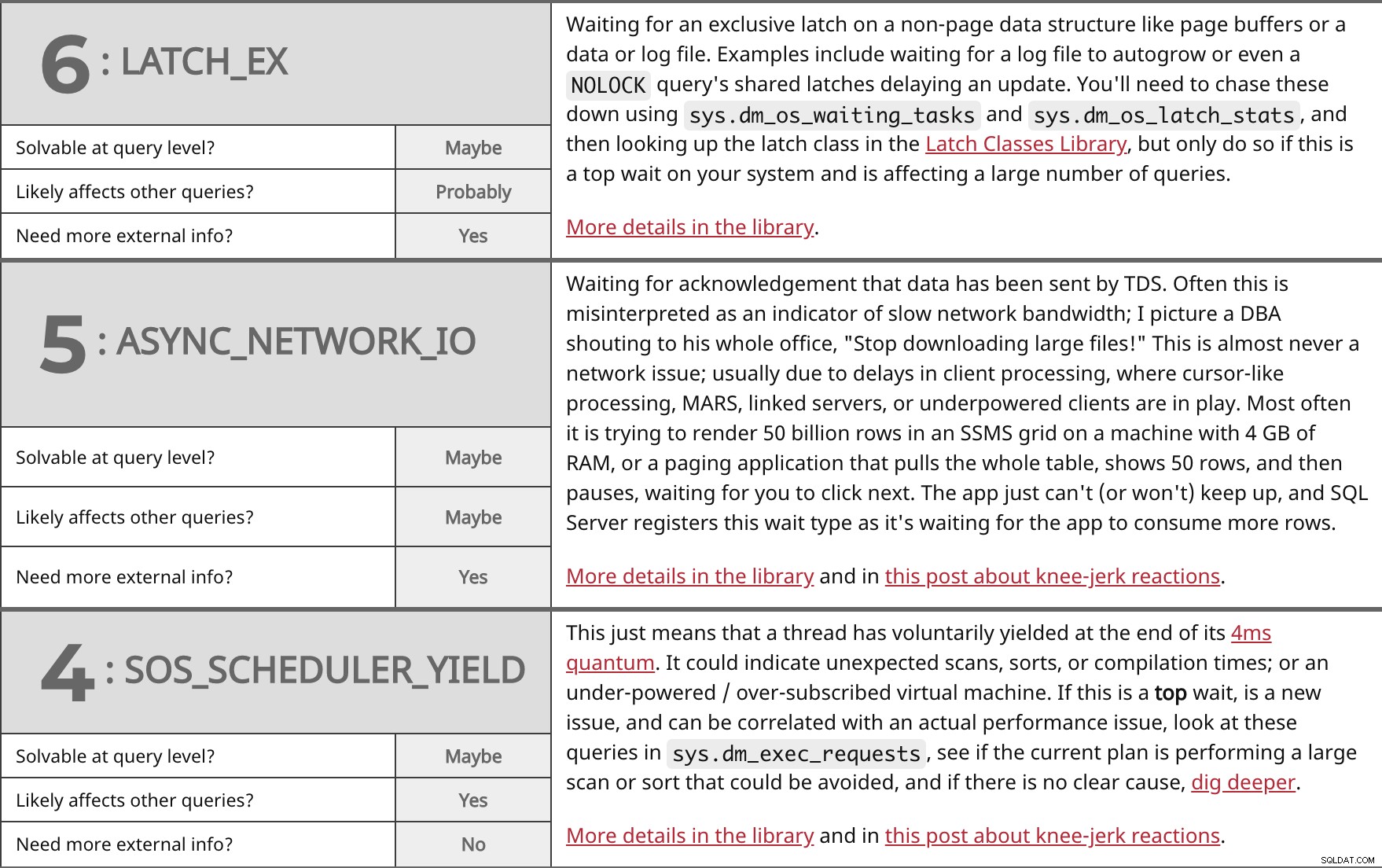
Attente d'un verrou exclusif sur une structure de données autre qu'une page, comme des tampons de page ou un fichier de données ou journal. Les exemples incluent l'attente d'un fichier journal pour croître automatiquement ou même un NOLOCK les verrous partagés de la requête retardant une mise à jour. Vous devrez les rechercher en utilisant sys.dm_os_waiting_tasks et sys.dm_os_latch_stats , puis recherchez la classe de verrouillage dans la bibliothèque de classes de verrouillage, mais ne le faites que s'il s'agit d'une attente majeure sur votre système et qu'elle affecte un grand nombre de requêtes. Plus de détails dans la bibliothèque. | ||
| Résoluble au niveau de la requête ? | Peut-être | |
| Probablement | ||
| Besoin de plus d'informations externes ? | Oui | |
|
Attente de la confirmation que les données ont été envoyées par TDS. Ceci est souvent interprété à tort comme un indicateur de bande passante réseau lente; J'imagine un DBA criant à tout son bureau :"Arrêtez de télécharger des fichiers volumineux !" Ce n'est presque jamais un problème de réseau; généralement en raison de retards dans le traitement du client, où le traitement de type curseur, MARS, des serveurs liés ou des clients sous-alimentés sont en jeu. Le plus souvent, il essaie de rendre 50 milliards de lignes dans une grille SSMS sur une machine avec 4 Go de RAM, ou une application de pagination qui extrait toute la table, affiche 50 lignes, puis s'arrête, en attendant que vous cliquiez sur suivant. L'application ne peut tout simplement pas (ou ne veut pas) suivre le rythme, et SQL Server enregistre ce type d'attente car il attend que l'application consomme plus de lignes. Plus de détails dans la bibliothèque et dans cet article sur les réactions instinctives. | ||
| Résoluble au niveau de la requête ? | Peut-être | |
| Peut-être | ||
| Besoin de plus d'informations externes ? | Oui | |
Cela signifie simplement qu'un thread a volontairement cédé à la fin de son quantum de 4 ms. Cela pourrait indiquer des analyses, des tris ou des temps de compilation inattendus ; ou une machine virtuelle sous-alimentée / sur-abonnée. S'il s'agit d'un haut attendez, est un nouveau problème et peut être corrélé à un problème de performances réel, regardez ces requêtes dans sys.dm_exec_requests , voyez si le plan actuel effectue une analyse ou un tri important qui pourrait être évité, et s'il n'y a pas de cause claire, creusez plus profondément. Plus de détails dans la bibliothèque et dans cet article sur les réactions instinctives. | ||
| Résoluble au niveau de la requête ? | Peut-être | |
| Oui | ||
| Besoin de plus d'informations externes ? | Non | |
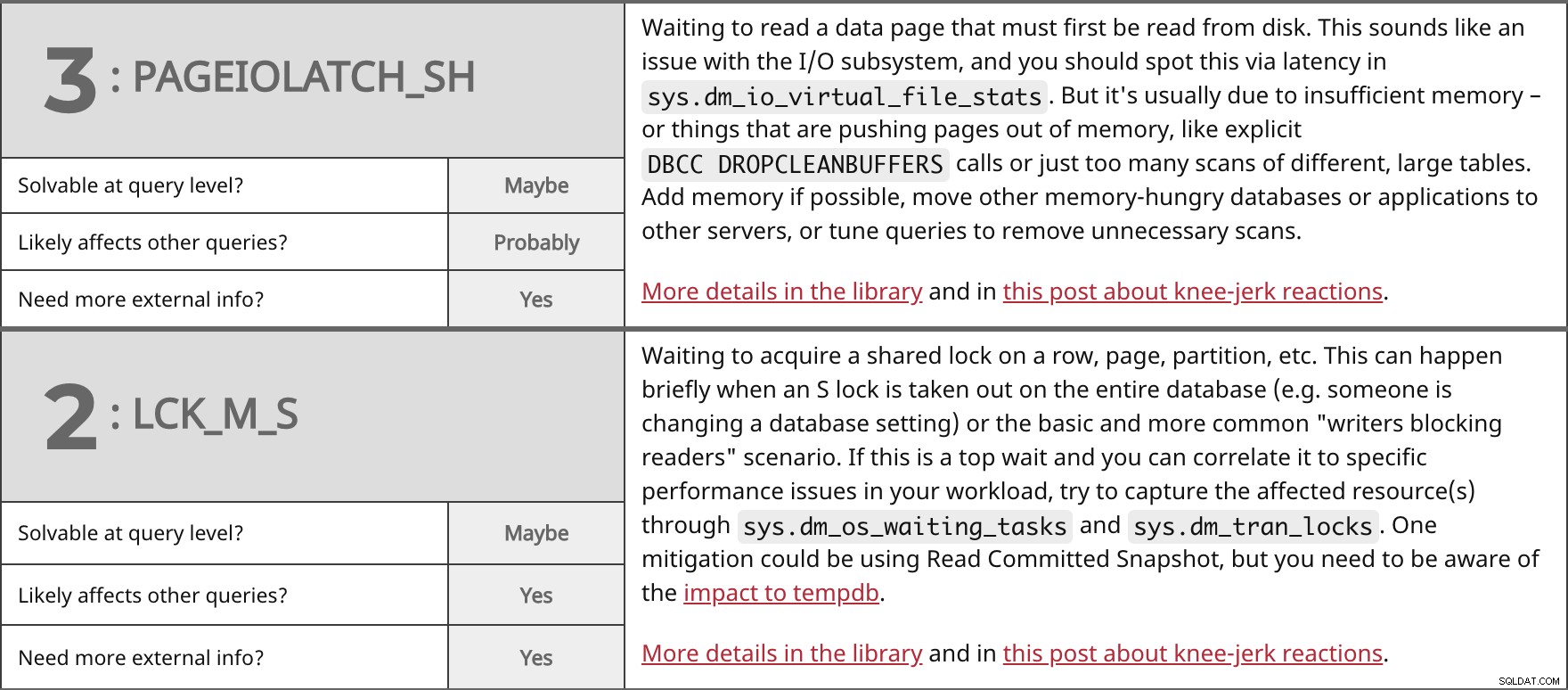
Attente de lecture d'une page de données qui doit d'abord être lue à partir du disque. Cela ressemble à un problème avec le sous-système d'E/S, et vous devriez le repérer via la latence dans sys.dm_io_virtual_file_stats . Mais cela est généralement dû à une mémoire insuffisante - ou à des éléments qui poussent les pages hors de la mémoire, comme les DBCC DROPCLEANBUFFERS explicites appels ou tout simplement trop de scans de grandes tables différentes. Ajoutez de la mémoire si possible, déplacez d'autres bases de données ou applications gourmandes en mémoire vers d'autres serveurs, ou réglez les requêtes pour supprimer les analyses inutiles. Plus de détails dans la bibliothèque et dans cet article sur les réactions instinctives. | ||
| Résoluble au niveau de la requête ? | Peut-être | |
| Probablement | ||
| Besoin de plus d'informations externes ? | Oui | |
Attente pour acquérir un verrou partagé sur une ligne, une page, une partition, etc. Cela peut se produire brièvement lorsqu'un verrou S est retiré sur l'ensemble de la base de données (par exemple, quelqu'un change un paramètre de base de données) ou le scénario de base et plus courant "les écrivains bloquent les lecteurs". S'il s'agit d'une attente majeure et que vous pouvez la corréler à des problèmes de performances spécifiques dans votre charge de travail, essayez de capturer la ou les ressources affectées via sys.dm_os_waiting_tasks et sys.dm_tran_locks . Une atténuation pourrait être d'utiliser Read Committed Snapshot, mais vous devez être conscient de l'impact sur tempdb. Plus de détails dans la bibliothèque et dans cet article sur les réactions instinctives. | ||
| Résoluble au niveau de la requête ? | Peut-être | |
| Oui | ||
| Besoin de plus d'informations externes ? | Oui | |
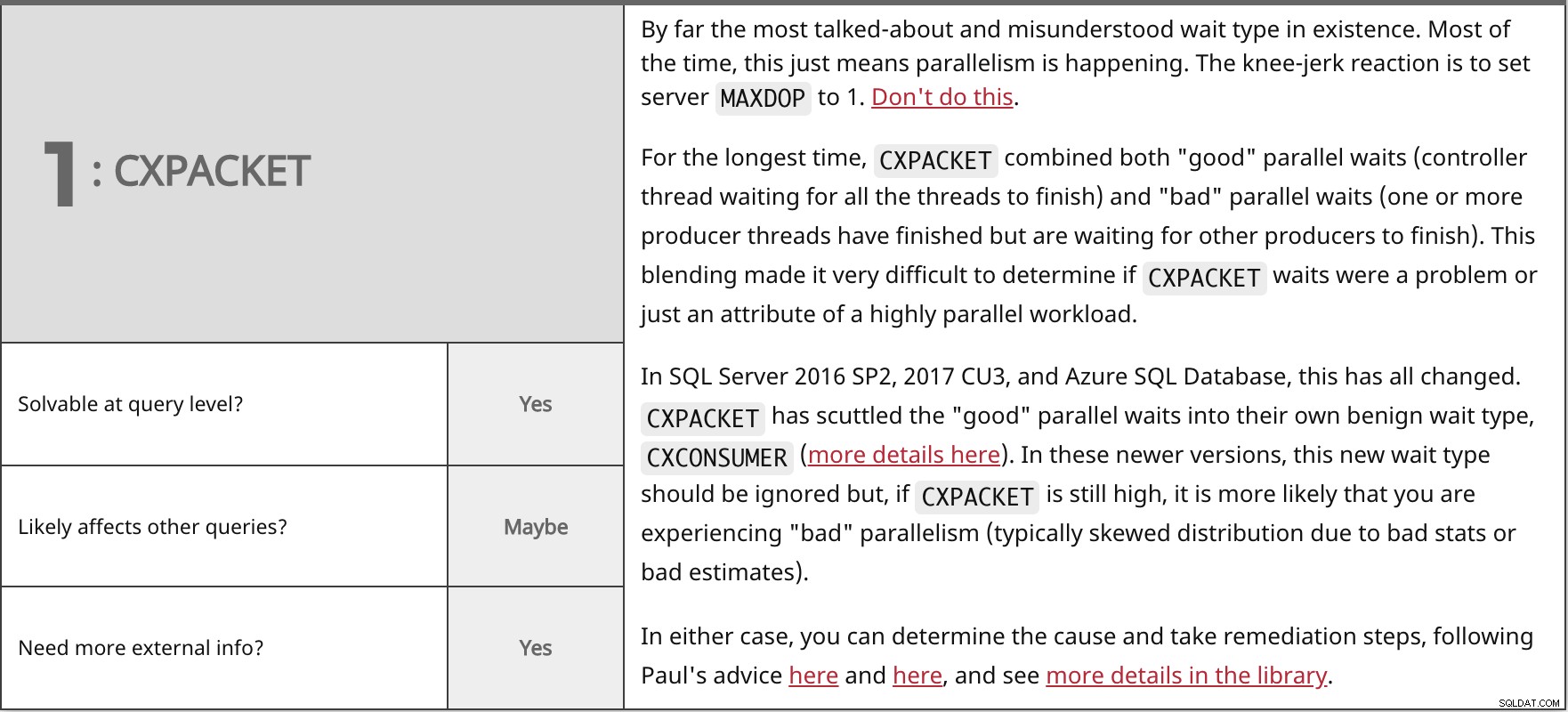
De loin le type d'attente dont on parle le plus et qui est le plus mal compris. La plupart du temps, cela signifie simplement que le parallélisme se produit. La réaction instinctive est de définir le serveur MAXDOP à 1. Ne faites pas ça.
Pendant très longtemps,
Dans SQL Server 2016 SP2, 2017 CU3 et Azure SQL Database, tout cela a changé. Dans les deux cas, vous pouvez déterminer la cause et prendre des mesures correctives, en suivant les conseils de Paul ici et ici, et voir plus de détails dans la bibliothèque. | ||
| Résoluble au niveau de la requête ? | Oui | |
| Peut-être | ||
| Besoin de plus d'informations externes ? | Oui | |
Résumé
Dans la plupart de ces cas, il est préférable d'examiner les attentes au niveau de l'instance et de se concentrer uniquement sur les attentes au niveau de la requête lorsque vous dépannez des requêtes spécifiques qui présentent des problèmes de performances, quel que soit le type d'attente. Ce sont des choses qui surgissent pour d'autres raisons, comme une longue durée, un processeur élevé ou des E/S élevées, et qui ne peuvent pas être expliquées par des choses plus simples (comme un balayage d'index groupé alors que vous vous attendiez à une recherche).
Même au niveau de l'instance, ne poursuivez pas chaque attente qui devient la première attente sur votre système ; vous allez TOUJOURS avoir une attente supérieure, et vous ne pourrez jamais arrêter de le chasser. Assurez-vous d'ignorer les attentes bénignes (Paul tient une liste) et ne vous souciez que des attentes que vous pouvez associer à un problème de performances réel que vous rencontrez. Si CXPACKET les attentes sont élevées, et alors? Existe-t-il d'autres symptômes que ce nombre "élevé" ou qui se trouve en haut de la liste ?
Tout dépend de la raison pour laquelle vous dépannez en premier lieu. Un seul utilisateur se plaint-il d'une seule instance d'une requête malveillante ? Votre serveur est à genoux ? Quelque chose entre les deux ? Dans le premier cas, bien sûr, savoir pourquoi une requête est lente peut être utile, mais il est assez coûteux de suivre (peu importe de les conserver indéfiniment) toutes les attentes associées à chaque requête, toute la journée, tous les jours, au cas où vous voulez revenir et les revoir plus tard. S'il s'agit d'un problème généralisé isolé à cette requête, vous devriez être en mesure de déterminer ce qui ralentit cette requête en l'exécutant à nouveau et en collectant le plan d'exécution, le temps de compilation et d'autres métriques d'exécution. S'il s'agit d'un événement ponctuel qui s'est produit mardi dernier, que vous attendiez ou non cette instance unique de la requête, vous ne pourrez peut-être pas résoudre le problème sans plus de contexte. Peut-être qu'il y a eu un blocage, mais vous ne saurez pas par quoi, ou peut-être qu'il y a eu un pic d'E/S, mais vous devrez rechercher ce problème séparément. Le type d'attente seul ne fournit généralement pas assez d'informations, sauf, au mieux, un pointeur vers autre chose.
Bien sûr, je dois gagner ma vie, ici aussi. Notre produit phare, SQL Sentry, adopte une approche holistique de la surveillance. Nous recueillons des statistiques d'attente à l'échelle de l'instance, les catégorisons pour vous et les affichons sur notre tableau de bord :
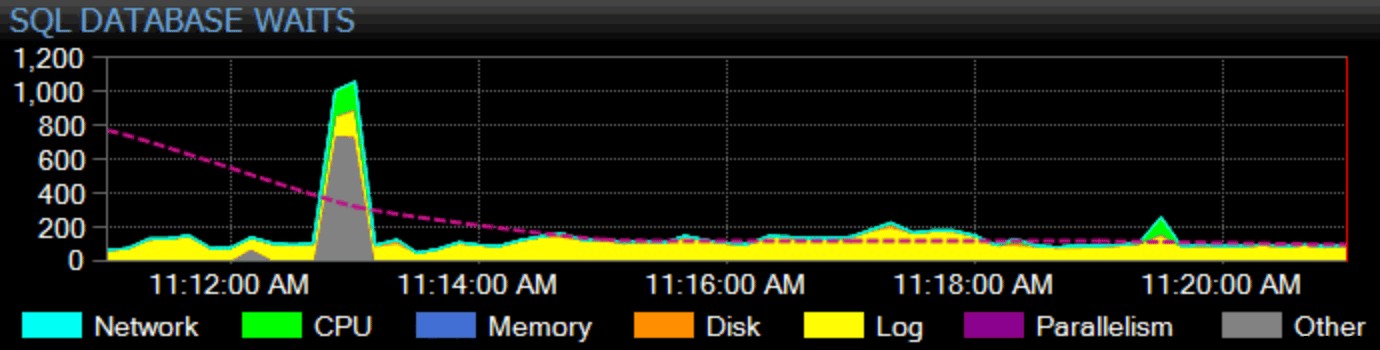
Vous pouvez personnaliser la façon dont chaque attente individuelle est classée et si cette catégorie apparaît ou non même sur le tableau de bord. Vous pouvez comparer les statistiques d'attente actuelles avec des lignes de base intégrées ou personnalisées, et même configurer des alertes ou des actions lorsqu'elles dépassent un écart défini par rapport à la ligne de base. Et, peut-être le plus important, vous pouvez consulter un point de données du passé et synchroniser l'intégralité du tableau de bord à ce moment-là, afin de pouvoir capturer tout le contexte environnant et toute autre situation pouvant avoir influencé le problème. Lorsque vous trouvez des éléments plus granulaires sur lesquels vous concentrer, comme le blocage, la latence élevée du disque ou les requêtes avec des E/S élevées ou une longue durée, vous pouvez explorer ces métriques et accéder assez rapidement à la racine du problème.
Pour plus d'informations sur les approches générales des statistiques d'attente et sur notre solution en particulier, vous pouvez consulter le livre blanc de Kevin Kline, Dépannage des statistiques d'attente SQL Server, et vous pouvez télécharger un webinaire en deux parties présenté par Paul Randal, Andy Yun (@SQLBek), et Andy Mallon (@AMtwo):
- Partie 1 :Dépannage des performances à l'aide des statistiques d'attente
- Partie 2 :Analyse rapide des statistiques d'attente avec SentryOne
Et si vous souhaitez essayer la plate-forme SentryOne, vous pouvez commencer ici avec une offre à durée limitée :
Téléchargez un essai gratuit de 15 jours