Introduction
Dans SQL Server 2012, l'agrégation groupée (vectorielle) pouvait utiliser l'exécution parallèle en mode batch, mais uniquement pour l'agrégation partielle (par thread). L'agrégat global associé s'exécutait toujours en mode ligne, après une répartition des flux échange.
SQL Server 2014 a ajouté la possibilité d'effectuer une agrégation groupée en mode batch parallèle dans un seul Hash Match Aggregate opérateur. Cela a éliminé le traitement inutile en mode ligne et supprimé le besoin d'un échange.
SQL Server 2016 a introduit le traitement en mode batch en série et le refoulement agrégé . Lorsque le refoulement réussit, l'agrégation est effectuée dans le Columnstore Scan opérateur lui-même, opérant éventuellement directement sur des données compressées, et tirant parti des instructions du processeur SIMD.
Les améliorations de performances possibles avec le refoulement agrégé peuvent être très substantielles. La documentation répertorie certaines des conditions requises pour obtenir le refoulement, mais il existe des cas où l'absence de "lignes agrégées localement" ne peut pas être entièrement expliquée à partir de ces seuls détails.
Cet article couvre des facteurs supplémentaires qui affectent le refoulement agrégé pour GROUP BY requêtes uniquement . Réduction agrégée scalaire (agrégation sans GROUP BY clause), le refoulement de filtre et le refoulement d'expression peuvent être couverts dans un prochain article.
Stockage Columnstore
La première chose à dire est que le refoulement agrégé ne s'applique qu'aux données compressées, donc les lignes dans un magasin delta ne sont pas éligibles. Au-delà, le refoulement peut dépendre du type de compression utilisé. Pour comprendre cela, il faut d'abord revoir le fonctionnement du stockage columnstore à un niveau élevé :
Un groupe de lignes compressé contient un segment de colonne pour chaque colonne. Les valeurs brutes des colonnes sont encodées dans un entier de 4 ou 8 octets en utilisant valeur ou dictionnaire encodage.
Encodage de valeur peut réduire le nombre de bits requis pour le stockage en traduisant les valeurs brutes à l'aide d'un décalage de base et d'un modificateur d'amplitude. Par exemple, les valeurs {1100, 1200, 1300} peuvent être stockées sous la forme (0, 1, 2) en mettant d'abord à l'échelle un facteur de 0,01 pour donner {11, 12, 13}, puis en rebasant sur 11 pour donner {0, 1, 2}.
Encodage du dictionnaire est utilisé lorsqu'il y a des valeurs en double. Il peut être utilisé avec des données non numériques. Chaque valeur unique est stockée dans un dictionnaire et se voit attribuer un identifiant entier. Les données de segment font alors référence aux numéros d'identification dans le dictionnaire au lieu des valeurs d'origine.
Après l'encodage, les données de segment peuvent être compressées davantage à l'aide de l'encodage de longueur d'exécution (RLE) et du bit-packing :
RLE remplace les éléments répétés par les données et le nombre de répétitions, par exemple {1, 1, 1, 1, 1, 2, 2, 2} pourrait être remplacé par {5×1, 3×2}. Les économies d'espace RLE augmentent avec la longueur des cycles répétés. Les petits tirages peuvent être contre-productifs.
Bit-packing stocke la forme binaire des données dans une fenêtre commune aussi étroite que possible. Par exemple, les nombres {7, 9, 15} sont stockés dans des entiers binaires (un seul octet pour l'espace) sous la forme {00000111, 00001001, 00001111}. Le regroupement de ces bits dans une fenêtre fixe de quatre bits donne le flux {011110011111}. Sachant qu'il y a une taille de fenêtre fixe signifie qu'il n'y a pas besoin de délimiteur.
L'encodage et la compression sont des étapes distinctes, de sorte que RLE et le bit-packing sont appliqués au résultat de l'encodage de valeur ou du codage de dictionnaire des données brutes. De plus, les données dans le même segment de colonne peuvent avoir un mélange de RLE et de compression bit-packing. Les données compressées RLE sont dites pures , et les données compressées en bits sont appelées impures . Un segment de colonne peut contenir à la fois des données pures et impures.
Les économies d'espace qui peuvent être réalisées grâce à l'encodage et à la compression peuvent dépendre de la commande. Tous les segments de colonne d'un groupe de lignes doivent être implicitement triés de la même manière afin que SQL Server puisse reconstruire efficacement des lignes complètes à partir des segments de colonne. Sachant que la ligne 123 est stockée à la même position (123) dans chaque segment de colonne signifie que le numéro de ligne n'a pas besoin d'être stocké.
L'un des inconvénients de cet arrangement est qu'un ordre de tri commun doit être choisi pour tous les segments de colonne d'un groupe de lignes. Un ordre particulier peut très bien convenir à une colonne, mais manquer des opportunités importantes dans d'autres colonnes. C'est clairement le cas avec la compression RLE. SQL Server utilise la technologie Vertipaq pour déterminer un bon moyen de trier les colonnes dans chaque groupe de lignes afin d'obtenir un bon résultat de compression global.
SQL Server utilise actuellement uniquement RLE dans un segment de colonne lorsqu'il y a un minimum de 64 valeurs répétitives contiguës. Les valeurs restantes dans le segment sont condensées en bits. Comme indiqué, le fait que les valeurs répétées apparaissent comme contiguës dans un segment de colonne dépend de l'ordre choisi pour le groupe de lignes.
SQL Server prend en charge le SIMD spécialisé déballage de bits pour les largeurs de bits de 1 à 10 inclus, 12 et 21 bits. SQL Server peut également utiliser des tailles d'entiers standard, par ex. 16, 32 et 64 bits avec bit-packing. Ces chiffres sont choisis parce qu'ils s'adaptent bien dans une unité 64 bits. Par exemple, une unité peut contenir trois sous-unités de 21 bits ou 5 sous-unités de 12 bits. SQL Server ne le fait pas franchir une limite de 64 bits lors du conditionnement des bits.
SIMD utilise des registres 256 bits lorsque le processeur prend en charge les instructions AVX2 et des registres 128 bits lorsque les instructions SSE4.2 sont disponibles. Sinon, un déballage non SIMD peut être utilisé.
Conditions refoulées agrégées groupées
La plupart des plans avec un Hash Match Aggregate opérateur directement au-dessus d'un Columnstore Scan l'opérateur sera potentiellement admissible à un refoulement agrégé groupé, sous réserve des conditions générales indiquées dans la documentation.
Des filtres et des expressions supplémentaires peuvent également parfois être ajoutés sans empêcher le refoulement des agrégats groupés. La règle générale est que le filtre ou l'expression doit également être capable de refouler (bien que des expressions compatibles puissent toujours apparaître dans un Compute Scalar séparé ). Comme indiqué dans l'introduction, ces aspects peuvent être traités en détail dans des articles distincts.
Il n'y a actuellement rien dans les plans d'exécution pour indiquer si un agrégat particulier a été considéré comme généralement compatible avec refoulement agrégé groupé ou non. Pourtant, lorsque le plan se qualifie généralement pour le pushdown agrégé groupé, les chemins de code pushdown (rapide) et non pushdown (lent) sont disponibles.
Chaque lot de sortie d'analyse (jusqu'à 900 lignes) prend une décision d'exécution entre les chemins de code rapides et lents. Cette flexibilité permet à autant de lots que possible de bénéficier du refoulement. Dans le pire des cas, aucun lot n'utilisera le raccourci au moment de l'exécution, malgré un plan "généralement compatible".
Le plan d'exécution affiche le résultat du traitement accéléré du refoulement sous la forme de 'lignes agrégées localement' sans sortie de ligne correspondante de l'analyse. Les lots à chemin lent apparaissent comme des lignes de sortie de l'analyse du magasin de colonnes comme d'habitude, l'agrégation étant effectuée par un opérateur distinct au lieu de l'analyse.
Une seule combinaison groupée d'agrégats et d'analyses peut envoyer certains lots sur le chemin rapide et d'autres sur le chemin lent, il est donc parfaitement possible de voir certaines lignes, mais pas toutes, agrégées localement. Lorsque le refoulement d'agrégat groupé réussit, chaque lot de sortie de l'analyse contient des clés de regroupement et un agrégat partiel représentant les lignes qui contribuent.
Vérifications détaillées
Il existe un certain nombre de vérifications d'exécution pour déterminer si le traitement pushdown peut être utilisé. Parmi les vérifications peu documentées figurent :
- Il ne doit y avoir aucune possibilité de débordement global .
- Tout élément impur (compressé par bits) clés de regroupement doit être pas plus large que 10 bits . Les clés de regroupement pures (encodées RLE) sont traitées comme ayant une largeur impure de zéro, elles présentent donc généralement peu d'obstacles.
- Le traitement pushdown doit continuer à être considéré comme utile , en utilisant une "mesure de bénéfice" mise à jour à la fin de chaque lot de sortie.
La possibilité de débordement agrégé est évaluée de manière prudente pour chaque lot en fonction du type d'agrégat, du type de données de résultat, des valeurs d'agrégation partielles actuelles et des informations sur les données d'entrée. Par exemple, SQL Server connaît les valeurs minimales et maximales des métadonnées de segment telles qu'elles sont exposées dans le DMV sys.column_store_segments . En cas de risque de débordement, le batch utilisera un traitement de chemin lent. C'est surtout un risque pour le SUM agrégé.
La restriction sur la largeur de clé de regroupement impure mérite d'être souligné. Cela ne s'applique qu'aux colonnes du GROUP BY clause qui sont effectivement utilisées dans le plan d'exécution comme base de regroupement. Ces ensembles ne sont pas toujours exactement les mêmes car l'optimiseur a la liberté de supprimer les colonnes de regroupement redondantes ou de réécrire les agrégats, tant que les résultats de la requête finale sont garantis pour correspondre à la spécification de la requête d'origine. En cas de disparité, ce sont les colonnes de regroupement indiquées dans le plan d'exécution qui importent.
La plus grande difficulté est de savoir si l'une des colonnes de regroupement est stockée à l'aide du bit-packing, et si c'est le cas, quelle largeur a été utilisée. Il serait également utile de savoir combien de valeurs ont été encodées à l'aide de RLE. Cette information pourrait se trouver dans les column_store_segments DMV, mais ce n'est pas le cas aujourd'hui. Autant que je sache, il n'existe actuellement aucun moyen documenté d'obtenir des informations sur le bit-packing et RLE à partir des métadonnées. Cela nous laisse chercher des alternatives sans papiers.
Recherche d'informations RLE et de bit-packing
Le DBCC CSINDEX non documenté peut nous donner les informations dont nous avons besoin. L'indicateur de trace 3604 doit être activé pour que cette commande produise une sortie dans l'onglet Messages SSMS. Étant donné les informations sur le segment de colonne qui nous intéresse, cette commande renvoie :
- Attributs de segment (similaire à
column_store_segments) - Informations RLE
- Signets dans les données RLE
- Informations sur les paquets de bits
Étant non documenté, il y a quelques bizarreries (comme devoir en ajouter un aux identifiants de colonne pour le magasin de colonnes en cluster, mais pas pour le magasin de colonnes non clusterisé), et même quelques erreurs mineures. Vous ne devez pas l'utiliser sur autre chose qu'un système de test personnel. Espérons qu'un jour, une méthode prise en charge pour accéder à ces données sera fournie à la place.
Exemples
La meilleure façon d'afficher DBCC CSINDEX et démontrer les points soulevés jusqu'à présent dans ce texte est de travailler à travers quelques exemples. Les scripts qui suivent supposent qu'il existe une table appelée dbo.Numbers dans la base de données actuelle qui contient des nombres entiers de 1 à au moins 16 384. Voici un script pour créer ma version standard de cette table avec dix millions d'entiers :
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULLBEGIN DROP TABLE dbo.Numbers;END;GOWITH Ten(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1) SELECT n =IDENTITY(int, 1, 1)INTO dbo.NumbersFROM Dix AS T10CROSS JOIN Dix AS T100CROSS JOIN Dix AS T1000CROSS JOIN Ten AS T10000CROSS JOIN Ten AS T100000CROSS JOIN Ten AS T1000000CROSS JOIN Ten AS T10000000ORDER BY n OFFSET 0 ROWS FETCH FIRST 10 * 1000 * 1000 ROWS ONLYOPTION (MAXDOP 1);GOALTER TABLE KEY CLUSTERED (n)WITH( SORT_IN_TEMPDB =ON, MAXDOP =1, FILLFACTOR =100);
Les exemples utilisent tous la même table de test de base :la première colonne c1 contient un numéro unique pour chaque ligne. La deuxième colonne c2 est rempli avec un certain nombre de doublons pour chacune d'un petit nombre de valeurs distinctes.
Un index clustered columnstore est créé après le remplissage des données afin que toutes les données de test se retrouvent dans un seul groupe de lignes compressé (pas de magasin delta). Il est construit en remplaçant un index clusterisé b-tree sur la colonne c2 pour encourager l'algorithme VertiPaq à considérer l'utilité du tri sur cette colonne dès le début. Voici la configuration de test de base :
USE Sandpit;GODROP TABLE IF EXISTS dbo.Test;GOCREATE TABLE dbo.Test( c1 entier NOT NULL, c2 entier NOT NULL);GODECLARE @values integer =512, @dupes integer =63; INSERT dbo.Test (c1, c2)SELECT N.n, N.n % @valuesFROM dbo.Numbers AS NWHERE N.n BETWEEN 1 AND @values * @dupes;GO-- Encourage VertiPaqCREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);GOCREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
Les deux variables correspondent au nombre de valeurs distinctes à insérer dans la colonne c2 , et le nombre de doublons pour chacune de ces valeurs.
La requête de test est un COUNT_BIG groupé très simple agrégation à l'aide de la colonne c2 comme clé :
-- La requête de testSELECT T.c2, numrows =COUNT_BIG(*)FROM dbo.Test AS TGROUP BY T.c2 ;
Les informations d'index Columnstore seront affichées à l'aide de DBCC CSINDEX après chaque exécution de requête test :
DECLARE @dbname sysname =DB_NAME(), @objectid integer =OBJECT_ID(N'dbo.Test', N'U'); DECLARE @rowsetid bigint =( SELECT P.hobt_id FROM sys.partitions AS P WHERE P.[object_id] =@objectid AND P.index_id =1 AND P.partition_number =1 ), @rowgroupid entier =0, @columnid entier =COLUMNPROPERTY (@objectid, N'c2', 'ColumnId') + 1 ; DBCC CSINDEX( @dbname, @rowsetid, @columnid, @rowgroupid, 1, -- show segment data 2, -- print option 0, -- start bitpack unit (inclusive) 2 -- end bitpack unit (exclusive));Les tests ont été exécutés sur la dernière version publiée de SQL Server disponible au moment de la rédaction :Microsoft SQL Server 2017 RTM-CU13-OD version 14.0.3049 Developer Edition (64 bits) sur Windows 10 Pro. Les choses devraient également fonctionner correctement sur la dernière version de SQL Server 2016.
Test 1 :Pushdown, clés impures 9 bits
Ce test utilise le script de population de données de test exactement comme écrit juste ci-dessus, produisant une table avec 32 256 lignes. Colonne
c1contient des nombres de 1 à 32 256.Colonne
c2contient 512 valeurs distinctes de 0 à 511 inclus. Chaque valeur dansc2est dupliqué 63 fois , mais ils n'apparaissent pas comme des blocs contigus lorsqu'ils sont affichés dansc1Commande; ils parcourent 63 fois les valeurs de 0 à 511.Compte tenu de la discussion précédente, nous nous attendons à ce que SQL Server stocke le
c2données de colonne en utilisant :
- Encodage du dictionnaire puisqu'il existe un nombre important de valeurs en double.
- Pas de RLE . Le nombre de doublons (63) par valeur n'atteint pas le seuil de 64 requis pour RLE.
- Bit-packing taille 9 . Les 512 entrées de dictionnaire distinctes tiennent exactement sur 9 bits (2^9 =512). Chaque unité 64 bits contiendra jusqu'à sept sous-unités 9 bits.
Tout cela est confirmé comme étant correct à l'aide du DBCC CSINDEX requête :
Les attributs de segment section de la sortie montre l'encodage du dictionnaire (type 2 ; les valeurs de encodingType sont tels que documentés sur sys.column_store_segments ).
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 RowCount =32256
La section RLE n'affiche aucune donnée RLE , seulement un pointeur vers la région condensée en bits et une entrée vide pour la valeur zéro :
En-tête RLE :
Type de lob =3 Nombre de tableaux RLE (en termes d'unités natives) =2
Taille d'entrée du tableau RLE =8
Données RLE :
Index =0 Bitpack Array Index =0 Count =32256
Index =1 Value =0 Count =0
L'en-tête de données Bitpack section montre bitpack taille 9 et 4 608 unités bitpack utilisées :
En-tête de données Bitpack :
Bitpack Entry Size =9 Bitpack Unit Count =4608 Bitpack MinId =3
Bitpack DataSize =36864
Les données Bitpack affiche les valeurs stockées dans les deux premières unités bitpack comme demandé par les deux derniers paramètres au DBCC CSINDEX commande. Rappelons que chaque unité de 64 bits peut contenir 7 sous-unités (numérotées de 0 à 6) de 9 bits chacune (7 x 9 =63 bits). Les 4 608 unités au total contiennent 4 608 * 7 =32 256 lignes :
Unité 0 Sous-unité 0 =383
Unité 0 Sous-unité 1 =255
Unité 0 Sous-unité 2 =127
Unité 0 Sous-unité 3 =510
Unité 0 Sous-unité 4 =381
Unité 0 Sous-Unité 5 =253
Unité 0 Sous-Unité 6 =125
Unité 1 Sous-unité 0 =508
Unité 1 Sous-unité 1 =379
Unité 1 Sous-unité 2 =251
Unité 1 Sous-unité 3 =123
Unité 1 Sous-unité 4 =506
Unité 1 Sous-Unité 5 =377
Unité 1 Sous-Unité 6 =249
Étant donné que les clés de regroupement utilisent le bit-packing avec une taille inférieure ou égale à 10 , nous nous attendons à un refoulement agrégé groupé travailler ici. En effet, le plan d'exécution montre que toutes les lignes ont été agrégées localement lors du Columnstore Index Scan opérateur :

Le xml du plan contient ActualLocallyAggregatedRows="32256" dans les informations d'exécution pour l'analyse de l'index.
Test 2 :pas de refoulement, clés impures 12 bits
Ce test modifie les @values paramètre à 1025, en gardant @dupes à 63. Cela donne un tableau de 64 575 lignes, avec 1 025 valeurs distinctes dans la colonne c2 allant de 0 à 1024 inclus. Chaque valeur dans c2 est dupliqué 63 fois .
SQL Server stocke le c2 données de colonne en utilisant :
- Encodage du dictionnaire puisqu'il existe un nombre important de valeurs en double.
- Pas de RLE . Le nombre de doublons (63) par valeur n'atteint pas le seuil de 64 requis pour RLE.
- Bit-packed avec la taille 12 . Les 1 025 entrées de dictionnaire distinctes ne tiennent pas tout à fait dans 10 bits (2 ^ 10 =1 024). Ils tiendraient en 11 bits, mais SQL Server ne prend pas en charge cette taille de compression de bits, comme mentionné précédemment. La plus petite taille suivante est de 12 bits. En utilisant des unités 64 bits avec des bordures dures pour le compactage des bits, pas plus de sous-unités 11 bits ne peuvent tenir dans 64 bits que les sous-unités 12 bits ne le feraient. Dans tous les cas, 5 sous-unités tiennent dans une unité 64 bits.
Le DBCC CSINDEX la sortie confirme l'analyse ci-dessus :
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 RowCount =64575
En-tête RLE :
Type de lob =3 Nombre de tableaux RLE (en termes d'unités natives) =2
Taille d'entrée de tableau RLE =8
Données RLE :
Index =0 Bitpack Array Index =0 Count =64575
Index =1 Value =0 Count =0
En-tête de données Bitpack :
Taille d'entrée Bitpack =12 Nombre d'unités Bitpack =12915 Bitpack MinId =3
Bitpack DataSize =103320
Données Bitpack :
Unité 0 Sous-Unité 0 =767
Unité 0 Sous-Unité 1 =510
Unité 0 Sous-Unité 2 =254
Unité 0 Sous-Unité 3 =1021
Unité 0 Sous-Unité 4 =765
Unité 1 Sous-Unité 0 =507
Unité 1 Sous-Unité 1 =250
Unité 1 Sous-Unité 2 =1019
Unité 1 Sous-Unité 3 =761
Unité 1 Sous-Unité 4 =505
Depuis l'impur les clés de regroupement ont une taille supérieure à 10 , nous nous attendons à un refoulement agrégé groupé ne pas travailler ici. Ceci est confirmé par le plan d'exécution montrant zéro lignes agrégées localement à l'analyse de l'index de Columnstore opérateur :
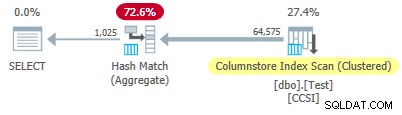
Les 64 575 lignes sont émises (par lots) par le Columnstore Index Scan et agrégées en mode batch par le Hash Match Aggregate opérateur. Les ActualLocallyAggregatedRows l'attribut est manquant dans les informations d'exécution du plan xml pour l'analyse de l'index.
Test 3 :Pushdown, clés pures
Ce test modifie le @dupes paramètre de 63 à 64 pour permettre RLE. Les @values est remplacé par 16 384 (le nombre maximal de lignes pouvant encore tenir dans un seul groupe de lignes). Le nombre exact choisi pour @values n'est pas important - le but est de générer 64 doublons de chaque valeur unique afin que RLE puisse être utilisé.
SQL Server stocke le c2 données de colonne en utilisant :
- Encodage du dictionnaire en raison des valeurs en double.
- RLE. Utilisé pour chaque valeur distincte puisque chacune atteint le seuil de 64.
- Pas de données compressées . S'il y en avait, il utiliserait la taille 16. La taille 12 n'est pas assez grande (2 ^ 12 =4 096 valeurs distinctes) et la taille 21 serait un gaspillage. Les 16 384 valeurs distinctes tiendraient dans 14 bits mais, comme auparavant, pas plus d'entre elles ne peuvent tenir dans une unité de 64 bits que dans des sous-unités de 16 bits.
Le DBCC CSINDEX la sortie confirme ce qui précède (seulement quelques entrées RLE et signets affichés pour des raisons d'espace):
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 RowCount =1048576
En-tête RLE :
Type de lob =3 Nombre de tableaux RLE (en termes d'unités natives) =16385
Taille d'entrée de tableau RLE =8
Données RLE :
Index =0 Valeur =3 Compte =64
Index =1 Valeur =1538 Compte =64
Index =2 Valeur =3072 Compte =64
Indice =3 Valeur =4608 Compte =64
Indice =4 Valeur =6142 Compte =64
…
Indice =16381 Valeur =8954 Compte =64
Indice =16382 Valeur =10489 Compte =64
Indice =16383 Valeur =12025 Comptage =64
Indice =16384 Valeur =0 Comptage =0
En-tête du signet :
Nombre de signets =65 Distance des signets =16384 Taille des signets =520
Données de signet :
Position =0 Index =64
Position =512 Index =16448
Position =1024 Index =32832
…
Position =31744 Index =1015872
Position =32256 Index =1032256
Position =32768 Indice =1048577
En-tête de données Bitpack :
Bitpack Entry Size =16 Bitpack Unit Count =0 Bitpack MinId =3
Bitpack DataSize =0
Étant donné que les clés de regroupement sont pures (RLE est utilisé), refoulement agrégé groupé est attendu ici. Le plan d'exécution le confirme en affichant toutes les lignes agrégées localement à l'analyse de l'index de Columnstore opérateur :
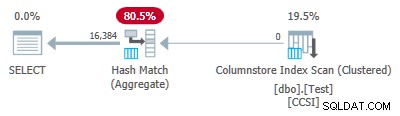
Le xml du plan contient ActualLocallyAggregatedRows="1048576" dans les informations d'exécution pour l'analyse de l'index.
Test 4 :Clés impures 10 bits
Ce test définit @values à 1024 et @dupes à 63, donnant un tableau de 64 512 lignes, avec 1 024 valeurs distinctes dans la colonne c2 avec des valeurs de 0 à 1 023 inclus. Chaque valeur dans c2 est dupliqué 63 fois .
Le plus important , l'index clusterisé b-tree est maintenant créé sur la colonne c1 au lieu de la colonne c2 . Le magasin de colonnes clusterisé remplace toujours l'index clusterisé b-tree. Voici la partie modifiée du script :
-- Notez la colonne c1 maintenant !CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1);GOCREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.TestWITH (MAXDOP =1, DROP_EXISTING =ON);
SQL Server stocke le c2 données de colonne en utilisant :
- Encodage du dictionnaire à cause des doublons.
- Pas de RLE . Le nombre de doublons (63) par valeur n'atteint pas le seuil de 64 requis pour RLE.
- Bit-packing avec la taille 10 . Les 1 024 entrées de dictionnaire distinctes correspondent exactement à 10 bits (2 ^ 10 =1 024). Six sous-unités de 10 bits chacune peuvent être stockées dans chaque unité de 64 bits.
Le DBCC CSINDEX la sortie est :
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 RowCount =64512
En-tête RLE :
Type de lob =3 Nombre de tableaux RLE (en termes d'unités natives) =2
Taille d'entrée de tableau RLE =8
Données RLE :
Index =0 Bitpack Array Index =0 Count =64512
Index =1 Value =0 Count =0
En-tête de données Bitpack :
Taille d'entrée Bitpack =10 Nombre d'unités Bitpack =10752 Bitpack MinId =3
Bitpack DataSize =86016
Données Bitpack :
Unité 0 Sous-unité 0 =766
Unité 0 Sous-unité 1 =509
Unité 0 Sous-unité 2 =254
Unité 0 Sous-unité 3 =1020
Unité 0 Sous-unité 4 =764
Unité 0 Sous-unité 5 =506
Unité 1 Sous-unité 0 =250
Unité 1 Sous-unité 1 =1018
Unité 1 Sous-unité 2 =760
Unité 1 Sous-unité 3 =504
Unité 1 Sous-unité 4 =247
Unité 1 Sous-unité 5 =1014
Depuis l'impur les clés de regroupement utilisent une taille inférieure ou égale à 10, nous nous attendrions à un refoulement agrégé groupé travailler ici. Mais ce n'est pas ce qui se passe . Le plan d'exécution montre que 54 612 des 64 512 lignes ont été agrégées au Hash Match Aggregate opérateur :
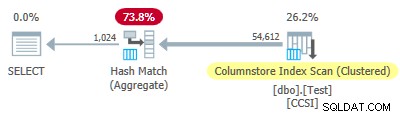
Le xml du plan contient ActualLocallyAggregatedRows="9900" dans les informations d'exécution pour l'analyse de l'index. Cela signifie refoulement agrégé groupé a été utilisé pour 9 900 lignes, mais pas pour les 54 612 autres !
Le mécanisme de rétroaction
SQL Server a démarré en utilisant le refoulement d'agrégat groupé pour cette exécution, car les clés de regroupement impures répondaient aux critères de 10 bits ou moins. Cela a duré un total de 11 lots (de 900 lignes chacun =9 900 lignes au total). À ce stade, un mécanisme de rétroaction mesurant l'efficacité du repoussage agrégé groupé a décidé que cela ne fonctionnait pas et l'a désactivé . Les lots restants ont tous été traités avec le refoulement désactivé.
Les commentaires comparent essentiellement le nombre de lignes agrégées au nombre de groupes produits. Il commence par une valeur de 100 et est ajusté à la fin de chaque lot de sortie de refoulement. Si la valeur tombe à 10 ou moins, le refoulement est désactivé pour l'opération de regroupement en cours.
La « mesure des avantages de la poussée vers le bas » est réduite plus ou moins en fonction de la gravité de l'effort d'agrégation poussé vers le bas. S'il y a moins de 8 lignes par clé de regroupement en moyenne dans le lot de sortie, la valeur actuelle de l'avantage est réduite de 22 %. S'il y en a plus de 8 mais moins de 16, la métrique est réduite de 11 %.
D'un autre côté, si les choses s'améliorent et que 16 lignes ou plus par clé de regroupement sont ensuite rencontrées pour un lot de sortie, la métrique est réinitialisée à 100 et continue d'être ajustée à mesure que des lots agrégés partiels sont produits par l'analyse.
Les données de ce test ont été présentées dans un ordre particulièrement inutile pour le refoulement en raison de l'index clusterisé b-tree d'origine sur la colonne c1 . Lorsqu'elles sont présentées de cette manière, les valeurs de la colonne c2 commencent à 0 et incrémentent de 1 jusqu'à atteindre 1 023, puis recommencent le cycle. Les 1 023 valeurs distinctes sont plus que suffisantes pour garantir que chaque lot de sortie de 900 lignes ne contient qu'une seule ligne partiellement agrégée pour chaque clé. Ce n'est pas un état heureux.
S'il y avait eu 64 doublons par valeur au lieu de 63, SQL Server aurait envisagé de trier par c2 lors de la construction de l'index columnstore, et ainsi produit la compression RLE. Dans l'état actuel des choses, la pénalité de 22 % entre en vigueur après chaque lot. À partir de 100 et en utilisant la même arithmétique d'entiers arrondis, la séquence de valeurs métriques est la suivante :
-- @metric :=FLOOR(@metric * 0.78 + 0.5);-- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Le onzième lot réduit la métrique à 10 ou moins, et le refoulement est désactivé. Les 11 lots de 900 lignes représentent les 9 900 lignes agrégées localement indiquées dans le plan d'exécution.
Variation avec 900 valeurs distinctes
Le même comportement peut être observé dans le test 4 avec aussi peu que 901 valeurs distinctes, en supposant que les lignes soient présentées dans le même ordre inutile.
Modification des @values paramètre à 900 tout en gardant tout le reste identique a un effet dramatique sur le plan d'exécution :
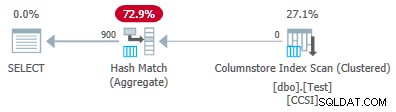
Désormais, les 900 groupes sont agrégés lors de l'analyse ! Les propriétés du plan xml affichent ActualLocallyAggregatedRows="56700" . En effet, le refoulement d'agrégats groupés conserve 900 clés de regroupement et agrégats partiels dans un seul lot. Il ne rencontre jamais une nouvelle valeur de clé ne faisant pas partie du lot, il n'y a donc aucune raison de démarrer un nouveau lot de sortie.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Note: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.