Considérez la requête AdventureWorks suivante qui renvoie les ID de transaction de la table d'historique pour l'ID de produit 421 :
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
L'optimiseur de requête trouve rapidement un plan d'exécution efficace avec une estimation de cardinalité (nombre de lignes) qui est exactement correcte, comme indiqué dans SQL Sentry Plan Explorer :

Supposons maintenant que nous souhaitions rechercher les ID de transaction d'historique pour le produit AdventureWorks nommé "Metal Plate 2". Il existe de nombreuses façons d'exprimer cette requête dans T-SQL. Une formulation naturelle est :
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Le plan d'exécution est le suivant :
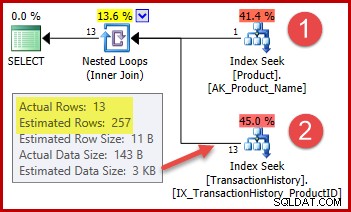
La stratégie est :
- Recherchez l'ID de produit dans la table Product à partir du nom donné
- Rechercher des lignes pour cet ID de produit dans le tableau Historique
L'estimation du nombre de lignes pour l'étape 1 est tout à fait correcte car l'index utilisé est déclaré unique et indexé uniquement sur le nom du produit. Le test d'égalité sur "Metal Plate 2" est donc garanti de retourner exactement une ligne (ou zéro ligne si nous spécifions un nom de produit qui n'existe pas).
L'estimation de 257 lignes en surbrillance pour la deuxième étape est moins précise :seules 13 lignes sont réellement rencontrées. Cet écart est dû au fait que l'optimiseur ne sait pas quel ID de produit particulier est associé au produit nommé "Metal Plate 2". Il traite la valeur comme inconnue, générant une estimation de cardinalité à l'aide des informations de densité moyenne. Le calcul utilise des éléments de l'objet de statistiques ci-dessous :
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
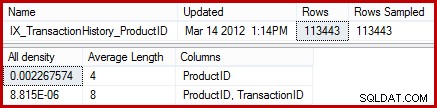
Les statistiques montrent que le tableau contient 113 443 lignes avec 441 ID de produit uniques (1 / 0,002267574 =441). En supposant que la distribution des lignes entre les ID de produit est uniforme, l'estimation de cardinalité s'attend à ce qu'un ID de produit corresponde à (113443/441) =257,24 lignes en moyenne. Il s'avère que la distribution n'est pas particulièrement uniforme; il n'y a que 13 lignes pour le produit "Metal Plate 2".
Un aparté
Vous pensez peut-être que l'estimation de 257 lignes devrait être plus précise. Par exemple, étant donné que les ID et les noms de produit sont tous deux contraints d'être uniques, SQL Server pourrait automatiquement conserver des informations sur cette relation un-à-un. Il saura alors que "Metal Plate 2" est associé à l'ID de produit 479 et utilisera cette information pour générer une estimation plus précise à l'aide de l'histogramme ProductID :
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
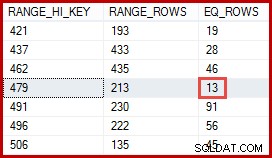
Une estimation de 13 lignes dérivée de cette manière aurait été tout à fait correcte. Néanmoins, l'estimation de 257 lignes n'était pas déraisonnable, compte tenu des informations statistiques disponibles et des hypothèses simplificatrices normales (comme la distribution uniforme) appliquées par l'estimation de la cardinalité aujourd'hui. Les estimations exactes sont toujours intéressantes, mais les estimations "raisonnables" sont également parfaitement acceptables.
Combiner les deux requêtes
Disons que nous voulons maintenant voir tous les ID d'historique des transactions où l'ID de produit est 421 OU le nom du produit est "Metal Plate 2". Une façon naturelle de combiner les deux requêtes précédentes est :
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Le plan d'exécution est un peu plus complexe maintenant, mais il contient toujours des éléments reconnaissables des plans à prédicat unique :
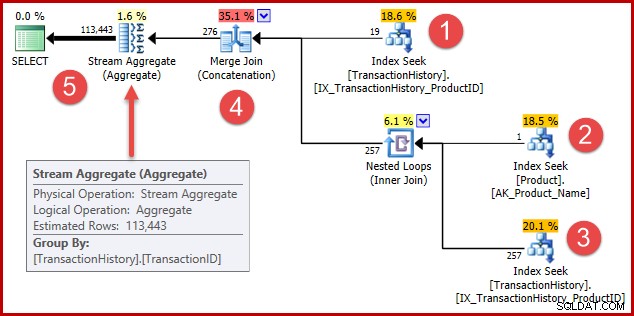
La stratégie est :
- Rechercher les enregistrements d'historique pour le produit 421
- Rechercher l'identifiant de produit pour le produit nommé "Metal Plate 2"
- Rechercher les enregistrements d'historique pour l'ID de produit trouvé à l'étape 2
- Combinez les lignes des étapes 1 et 3
- Supprimez tous les doublons (car le produit 421 pourrait aussi être celui nommé "Metal Plate 2")
Les étapes 1 à 3 sont exactement les mêmes que précédemment. Les mêmes estimations sont produites pour les mêmes raisons. L'étape 4 est nouvelle, mais très simple :elle concatène 19 lignes attendues avec 257 lignes attendues, pour donner une estimation de 276 lignes.
L'étape 5 est la plus intéressante. L'agrégat de flux de suppression des doublons a une entrée estimée à 276 lignes et une sortie estimée à 113 443 lignes. Un agrégat qui produit plus de lignes qu'il n'en reçoit semble impossible, n'est-ce pas ?
* Vous verrez ici une estimation de 102 099 lignes si vous utilisez le modèle d'estimation de cardinalité antérieur à 2014.
Le bogue d'estimation de la cardinalité
L'estimation impossible de Stream Aggregate dans notre exemple est causée par un bogue dans l'estimation de la cardinalité. C'est un exemple intéressant, nous allons donc l'explorer un peu en détail.
Suppression de sous-requêtes
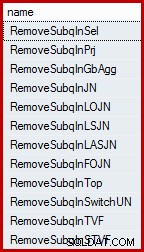
Vous serez peut-être surpris d'apprendre que l'optimiseur de requête SQL Server ne fonctionne pas directement avec les sous-requêtes. Ils sont supprimés de l'arbre de requête logique au début du processus de compilation et remplacés par une construction équivalente avec laquelle l'optimiseur est configuré pour travailler et raisonner. L'optimiseur a un certain nombre de règles qui suppriment les sous-requêtes. Ceux-ci peuvent être répertoriés par nom à l'aide de la requête suivante (le DMV référencé est peu documenté, mais non pris en charge) :
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Résultats (sur SQL Server 2014) :
La requête de test combinée a deux prédicats ("sélections" en termes relationnels) sur la table d'historique, reliés par OR . L'un de ces prédicats inclut une sous-requête. Le sous-arbre entier (prédicats et sous-requête) est transformé par la première règle de la liste ("supprimer la sous-requête dans la sélection") en une semi-jointure sur l'union des prédicats individuels. Bien qu'il ne soit pas possible de représenter exactement le résultat de cette transformation interne à l'aide de la syntaxe T-SQL, il est assez proche de :
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); Il est un peu regrettable que mon approximation T-SQL de l'arborescence interne après la suppression de la sous-requête contienne une sous-requête, mais dans le langage du processeur de requêtes, ce n'est pas le cas (c'est une semi-jointure). Si vous préférez voir le formulaire interne brut au lieu de ma tentative d'équivalent T-SQL, soyez assuré que cela arrivera momentanément.
L'indicateur de requête non documenté inclus dans le T-SQL ci-dessus est là pour empêcher une transformation ultérieure pour ceux d'entre vous qui souhaitent voir la logique transformée sous forme de plan d'exécution. Les annotations ci-dessous montrent les positions des deux prédicats après transformation :
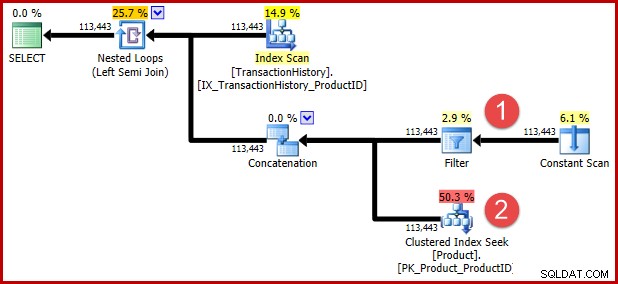
L'intuition derrière la transformation est qu'une ligne d'historique est qualifiée si l'un des prédicats est satisfait. Quelle que soit l'utilité de mon illustration approximative de T-SQL et de mon plan d'exécution, j'espère qu'il est au moins raisonnablement clair que la réécriture exprime la même exigence que la requête d'origine.
Je dois souligner que l'optimiseur ne génère pas littéralement une syntaxe T-SQL alternative ou ne produit pas de plans d'exécution complets à des étapes intermédiaires. Les représentations T-SQL et du plan d'exécution ci-dessus sont uniquement destinées à aider à la compréhension. Si vous êtes intéressé par les détails bruts, la représentation interne promise de l'arbre de requête transformé (légèrement modifiée pour plus de clarté/d'espace) est :
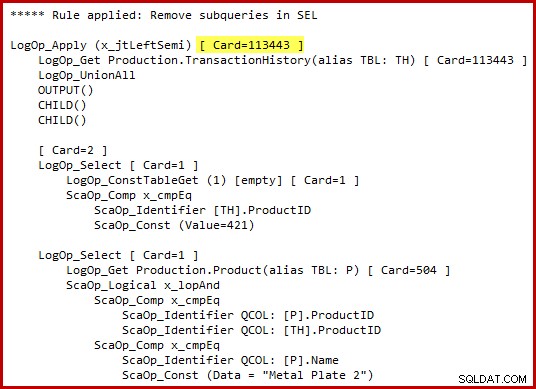
Remarquez l'estimation de cardinalité d'application de semi-jointure en surbrillance. Il est de 113 443 lignes avec l'estimateur de cardinalité de 2014 (102 099 lignes avec l'ancien CE). Gardez à l'esprit que la table d'historique d'AdventureWorks contient 113 443 lignes au total, ce qui représente une sélectivité de 100 % (90 % pour l'ancien CE).
Nous avons vu précédemment que l'application de l'un ou l'autre de ces prédicats seul ne donne qu'un petit nombre de correspondances :19 lignes pour l'ID de produit 421 et 13 lignes (estimées à 257) pour "Metal Plate 2". En estimant que la disjonction (OR) des deux prédicats renverra toutes les lignes de la table de base semble entièrement dingue.
Détails du bogue
Les détails du calcul de sélectivité pour la semi-jointure ne sont visibles que dans SQL Server 2014 lors de l'utilisation du nouvel estimateur de cardinalité avec l'indicateur de trace (non documenté) 2363. Il est probablement possible de voir quelque chose de similaire avec les événements étendus, mais la sortie de l'indicateur de trace est plus pratique. à utiliser ici. La section pertinente de la sortie est illustrée ci-dessous :
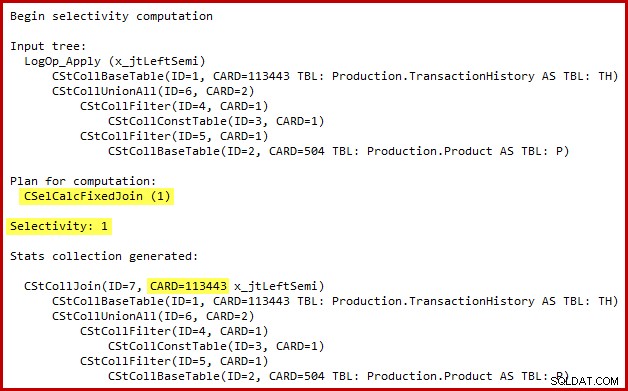
L'estimateur de cardinalité utilise le calculateur de jointure fixe avec une sélectivité de 100 %. Par conséquent, la cardinalité de sortie estimée de la semi-jointure est la même que son entrée, ce qui signifie que les 113 443 lignes de la table d'historique sont censées être qualifiées.
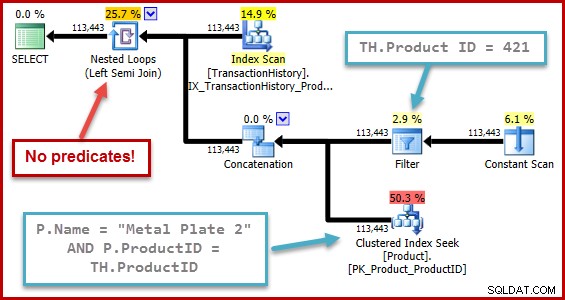
La nature exacte du bogue est que le calcul de la sélectivité de la semi-jointure manque tous les prédicats positionnés au-delà d'une union dans l'arbre d'entrée. Dans l'illustration ci-dessous, l'absence de prédicats sur la semi-jointure elle-même signifie que chaque ligne sera qualifiée ; il ignore l'effet des prédicats sous la concaténation (union all).
Ce comportement est d'autant plus surprenant si l'on considère que le calcul de la sélectivité opère sur une représentation arborescente que l'optimiseur a lui-même générée (la forme de l'arbre et le positionnement des prédicats résultent de la suppression de la sous-requête).
Un problème similaire se produit avec l'estimateur de cardinalité d'avant 2014, mais l'estimation finale est plutôt fixée à 90 % de l'entrée de semi-jointure estimée (pour des raisons divertissantes liées à une estimation de prédicat fixe inversée de 10 % qui est trop détournée pour obtenir dans).
Exemples
Comme mentionné ci-dessus, ce bogue se manifeste lorsque l'estimation est effectuée pour une semi-jointure avec des prédicats associés positionnés au-delà d'une union all. Le fait que cet arrangement interne se produise lors de l'optimisation des requêtes dépend de la syntaxe T-SQL d'origine et de la séquence précise des opérations d'optimisation internes. Les exemples suivants montrent certains cas où le bogue se produit et ne se produit pas :
Exemple 1
Ce premier exemple intègre une modification triviale de la requête de test :
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Le plan d'exécution estimé est :
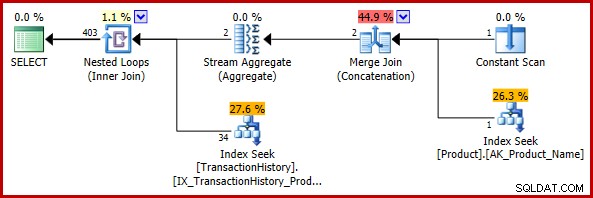
L'estimation finale de 403 lignes est incohérente avec les estimations d'entrée de la jointure de boucles imbriquées, mais elle reste raisonnable (au sens évoqué précédemment). Si le bogue avait été rencontré, l'estimation finale serait de 113 443 lignes (ou 102 099 lignes lors de l'utilisation du modèle CE antérieur à 2014).
Exemple 2
Au cas où vous étiez sur le point de vous précipiter et de réécrire toutes vos comparaisons constantes sous forme de sous-requêtes triviales pour éviter ce bogue, regardez ce qui se passe si nous apportons un autre changement trivial, cette fois en remplaçant le test d'égalité dans le deuxième prédicat par IN. Le sens de la requête reste inchangé :
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Le bogue renvoie :
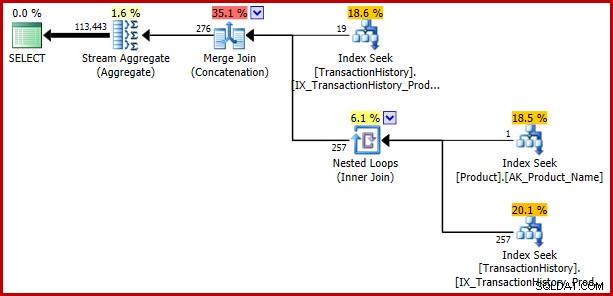
Exemple 3
Bien que cet article se soit jusqu'à présent concentré sur un prédicat disjonctif contenant une sous-requête, l'exemple suivant montre que la même spécification de requête exprimée à l'aide de EXISTS et UNION ALL est également vulnérable :
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Plan d'exécution :
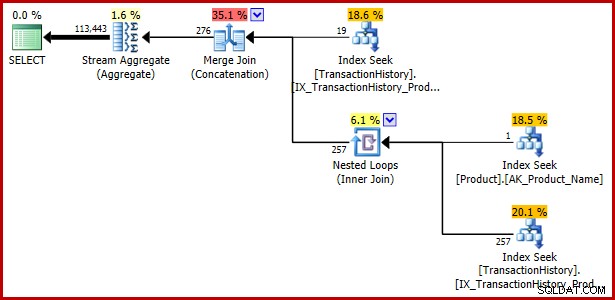
Exemple 4
Voici deux autres façons d'exprimer la même requête logique en T-SQL :
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Aucune des requêtes ne rencontre le bogue, et les deux produisent le même plan d'exécution :
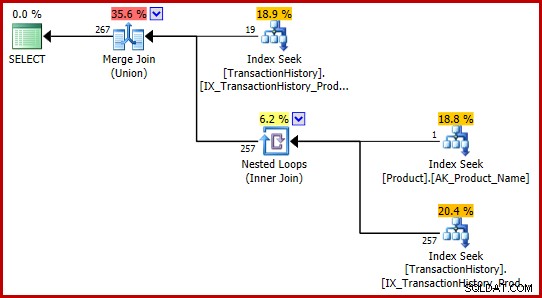
Ces formulations T-SQL produisent un plan d'exécution avec des estimations entièrement cohérentes (et raisonnables).
Exemple 5
Vous vous demandez peut-être si l'estimation inexacte est importante. Dans les cas présentés jusqu'ici, ce n'est pas le cas, du moins pas directement. Des problèmes surviennent lorsque le bogue se produit dans une requête plus importante et que l'estimation incorrecte affecte les décisions de l'optimiseur ailleurs. À titre d'exemple peu étendu, envisagez de renvoyer les résultats de notre requête de test dans un ordre aléatoire :
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Le plan d'exécution montre que l'estimation incorrecte affecte les opérations ultérieures. C'est par exemple la base de l'allocation mémoire réservée au tri :
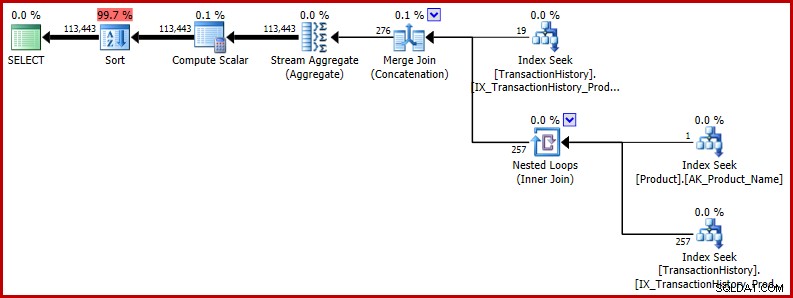
Si vous souhaitez voir un exemple plus réel de l'impact potentiel de ce bogue, jetez un œil à cette question récente de Richard Mansell sur le site de questions et réponses de SQLPerformance.com, answers.SQLPerformance.com.
Résumé et réflexions finales
Ce bogue est déclenché lorsque l'optimiseur effectue une estimation de cardinalité pour une semi-jointure, dans des circonstances spécifiques. Il s'agit d'un bogue difficile à repérer et à contourner pour un certain nombre de raisons :
- Il n'y a pas de syntaxe T-SQL explicite pour spécifier une semi-jointure, il est donc difficile de savoir à l'avance si une requête particulière sera vulnérable à ce bogue.
- L'optimiseur peut introduire une semi-jointure dans une grande variété de circonstances, qui ne sont pas toutes des candidats évidents à la semi-jointure.
- La semi-jointure problématique est souvent transformée en quelque chose d'autre par une activité ultérieure de l'optimiseur, nous ne pouvons donc même pas compter sur la présence d'une opération de semi-jointure dans le plan d'exécution final.
- Toutes les estimations de cardinalité bizarres ne sont pas causées par ce bogue. En effet, de nombreux exemples de ce type sont un effet secondaire attendu et inoffensif du fonctionnement normal de l'optimiseur.
- L'estimation de sélectivité de semi-jointure erronée sera toujours de 90 % ou 100 % de son entrée, mais cela ne correspondra généralement pas à la cardinalité d'une table utilisée dans le plan. De plus, la cardinalité d'entrée de semi-jointure utilisée dans le calcul peut même ne pas être visible dans le plan d'exécution final.
- Il existe généralement de nombreuses façons d'exprimer la même requête logique dans T-SQL. Certains d'entre eux déclencheront le bogue, tandis que d'autres ne le feront pas.
Ces considérations rendent difficile l'offre de conseils pratiques pour repérer ou contourner ce bogue. Il vaut certainement la peine de vérifier les plans d'exécution pour les estimations "scandaleuses" et d'enquêter sur les requêtes dont les performances sont bien pires que prévu, mais les deux peuvent avoir des causes qui ne sont pas liées à ce bogue. Cela dit, il convient de vérifier particulièrement les requêtes qui incluent une disjonction de prédicats et une sous-requête. Comme le montrent les exemples de cet article, ce n'est pas la seule façon de rencontrer le bogue, mais je m'attends à ce qu'il soit courant.
Si vous avez la chance d'exécuter SQL Server 2014, avec le nouvel estimateur de cardinalité activé, vous pourrez peut-être confirmer le bogue en vérifiant manuellement la sortie de l'indicateur de trace 2363 pour une estimation de sélectivité fixe de 100 % sur une semi-jointure, mais c'est peu pratique. Naturellement, vous ne voudrez pas utiliser des indicateurs de trace non documentés sur un système de production.
Le rapport de bogue User Voice pour ce problème peut être trouvé ici. Veuillez voter et commenter si vous souhaitez que ce problème soit examiné (et éventuellement résolu).