En avril, j'ai écrit sur certaines méthodes natives de SQL Server qui peuvent être utilisées pour suivre les mises à jour automatiques des statistiques. Les trois options que j'ai fournies étaient SQL Trace, Extended Events et des instantanés de sys.dm_db_stats_properties. Bien que ces trois options restent viables (même dans SQL Server 2014, bien que ma principale recommandation soit toujours XE), une option supplémentaire que j'ai remarquée lors de l'exécution de certains tests récemment est SQL Sentry Plan Explorer.
Beaucoup d'entre vous utilisent Plan Explorer simplement pour lire des plans d'exécution, ce qui est très bien. Il présente de nombreux avantages par rapport à Management Studio lorsqu'il s'agit de réviser des plans - des petites choses, comme la possibilité de trier les principaux opérateurs et de voir facilement les problèmes d'estimation de cardinalité, à des avantages plus importants, comme la gestion de plans complexes et volumineux et la possibilité d'en sélectionner un déclaration dans un lot pour faciliter l'examen du plan. Mais derrière les visuels qui facilitent la dissection des plans, Plan Explorer offre également la possibilité d'exécuter une requête et d'afficher le plan réel (plutôt que de l'exécuter dans Management Studio et de l'enregistrer). Et en plus de cela, lorsque vous exécutez le plan à partir de PE, des informations supplémentaires capturées peuvent être utiles.
Commençons par la démo que j'ai utilisée dans mon récent article, Comment les mises à jour automatiques des statistiques peuvent affecter les performances des requêtes. J'ai commencé avec la base de données AdventureWorks2012 et j'ai créé une copie de la table SalesOrderHeader avec plus de 200 millions de lignes. La table a un index clusterisé sur SalesOrderID et un index non clusterisé sur CustomerID, OrderDate, SubTotal. [Encore une fois :si vous allez faire des tests répétés, effectuez une sauvegarde de cette base de données à ce stade pour gagner du temps.] J'ai d'abord vérifié le nombre actuel de lignes dans la table et le nombre de lignes qui devraient changer pour invoquer une mise à jour automatique :
SELECT OBJECT_NAME([p].[object_id]) [TableName], [si].[name] [IndexName], [au].[type_desc] [Type], [p].[rows] [RowCount], ([p].[rows]*.20) + 500 [UpdateThreshold], [au].total_pages [PageCount], (([au].[total_pages]*8)/1024)/1024 [TotalGB] FROM [sys].[partitions] [p] JOIN [sys].[allocation_units] [au] ON [p].[partition_id] = [au].[container_id] JOIN [sys].[indexes] [si] on [p].[object_id] = [si].object_id and [p].[index_id] = [si].[index_id] WHERE [p].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Informations Big_SalesOrderHeader CIX et NCI
J'ai également vérifié l'en-tête des statistiques actuelles de l'index :
DBCC SHOW_STATISTICS ('Sales.Big_SalesOrderHeader',[IX_Big_SalesOrderHeader_CustomerID_OrderDate_SubTotal]);

Statistiques NCI :Au début
La procédure stockée que j'utilise pour les tests a déjà été créée, mais pour être complet, le code est répertorié ci-dessous :
CREATE PROCEDURE Sales.usp_GetCustomerStats
@CustomerID INT,
@StartDate DATETIME,
@EndDate DATETIME
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate), COUNT([SalesOrderID]) as Computed
FROM [Sales].[Big_SalesOrderHeader]
WHERE CustomerID = @CustomerID
AND OrderDate BETWEEN @StartDate and @EndDate
GROUP BY CustomerID, DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate)
ORDER BY DATEPART(YEAR, OrderDate), DATEPART(MONTH, OrderDate);
END Auparavant, je démarrais une session de suivi ou d'événements étendus, ou je configurais ma méthode pour créer un instantané de sys.dm_db_stats_properties dans une table. Pour cet exemple, j'ai exécuté plusieurs fois la procédure stockée ci-dessus :
EXEC Sales.usp_GetCustomerStats 11331, '2012-08-01 00:00:00.000', '2012-08-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11330, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11506, '2012-11-01 00:00:00.000', '2012-11-30 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 17061, '2013-01-01 00:00:00.000', '2013-01-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 11711, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15131, '2013-02-01 00:00:00.000', '2013-02-28 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 29837, '2012-10-01 00:00:00.000', '2012-10-31 23:59:59.997' GO EXEC Sales.usp_GetCustomerStats 15750, '2013-03-01 00:00:00.000', '2013-03-31 23:59:59.997' GO
J'ai ensuite vérifié le cache de la procédure pour vérifier le nombre d'exécutions, et également vérifié le plan qui était en cache :
SELECT OBJECT_NAME([st].[objectid]), [st].[text], [qs].[execution_count], [qs].[creation_time], [qs].[last_execution_time], [qs].[min_worker_time], [qs].[max_worker_time], [qs].[min_logical_reads], [qs].[max_logical_reads], [qs].[min_elapsed_time], [qs].[max_elapsed_time], [qp].[query_plan] FROM [sys].[dm_exec_query_stats] [qs] CROSS APPLY [sys].[dm_exec_sql_text]([qs].plan_handle) [st] CROSS APPLY [sys].[dm_exec_query_plan]([qs].plan_handle) [qp] WHERE [st].[text] LIKE '%usp_GetCustomerStats%' AND OBJECT_NAME([st].[objectid]) IS NOT NULL;

Planifier les informations de cache pour le SP :au démarrage
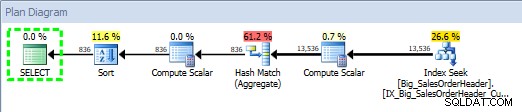
Plan de requête pour procédure stockée, à l'aide de SQL Sentry Plan Explorer
Le plan a été créé le 2014-09-29 23:23.01.
Ensuite, j'ai ajouté 61 millions de lignes à la table pour invalider les statistiques actuelles, et une fois l'insertion terminée, j'ai vérifié le nombre de lignes :

Big_SalesOrderHeader Informations CIX et NCI :après insertion de 61 millions lignes
Avant d'exécuter à nouveau la procédure stockée, j'ai vérifié que le nombre d'exécutions n'avait pas changé, que le creation_time était toujours 2014-09-29 23:23.01 pour le plan et que les statistiques n'avaient pas été mises à jour :
Planifier les informations de cache pour le SP :immédiatement après l'insertion

Statistiques NCI :après insertion
Maintenant, dans le précédent article de blog, j'ai exécuté la déclaration dans Management Studio, mais cette fois, j'ai exécuté la requête directement à partir de Plan Explorer et capturé le plan réel via PE (option entourée en rouge dans l'image ci-dessous).
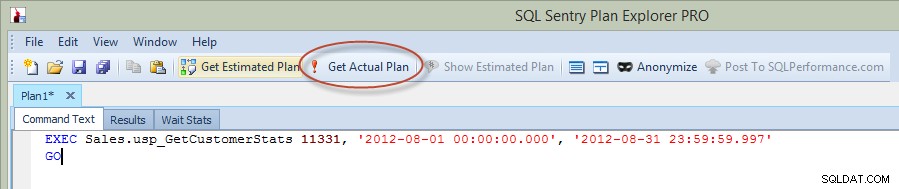
Exécuter la procédure stockée à partir de Plan Explorer
Lorsque vous exécutez une instruction à partir de PE, vous devez entrer l'instance et la base de données auxquelles vous souhaitez vous connecter, puis vous êtes averti que la requête s'exécutera et que le plan réel sera renvoyé, mais les résultats ne seront pas renvoyés. Notez que ceci est différent de Management Studio, où vous voyez les résultats.
Après avoir exécuté la procédure stockée, dans la sortie, non seulement j'obtiens le plan, mais je vois quelles instructions ont été exécutées :
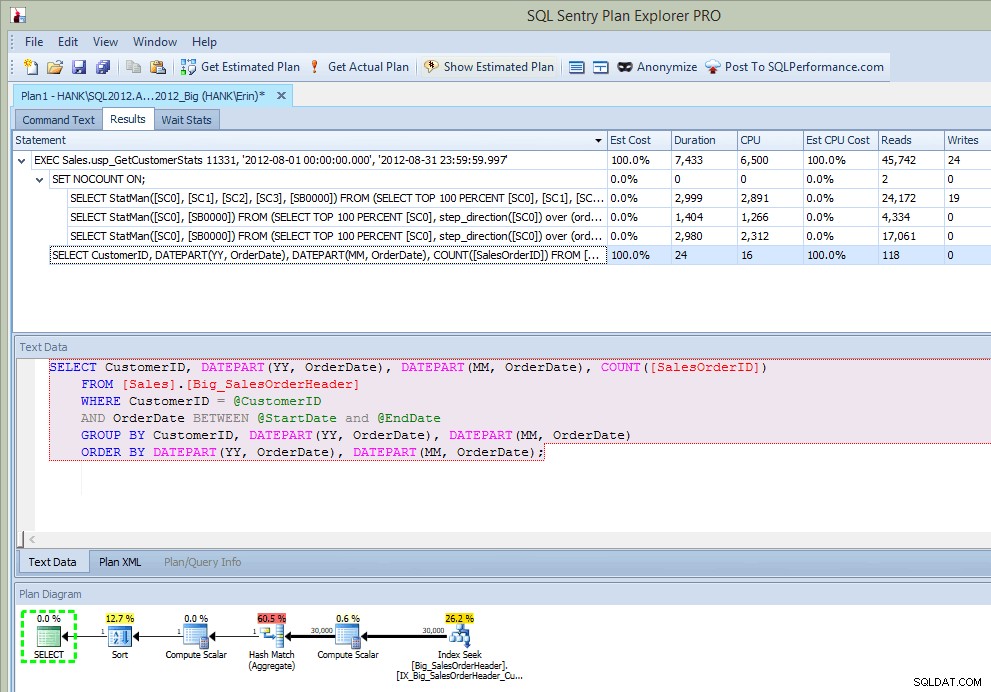
Sortie de Plan Explorer après exécution SP (après insertion)
C'est plutôt cool… en plus de voir l'instruction exécutée dans la procédure stockée, je vois également les mises à jour des statistiques, tout comme je l'ai fait lorsque j'ai capturé les mises à jour à l'aide d'événements étendus ou de SQL Trace. Parallèlement à l'exécution de l'instruction, nous pouvons également voir les informations sur le processeur, la durée et les E/S. Maintenant - la mise en garde ici est que je peux voir cette information si J'exécute l'instruction qui appelle la mise à jour des statistiques à partir de Plan Explorer. Cela n'arrivera probablement pas souvent dans votre environnement de production, mais vous pouvez le voir lorsque vous effectuez des tests (car, espérons-le, vos tests n'impliquent pas seulement l'exécution de requêtes SELECT, mais impliquent également des requêtes INSERT/UPDATE/DELETE comme vous le feriez voir dans une charge de travail normale). Cependant, si vous surveillez votre environnement avec un outil tel que SQL Sentry, vous pouvez voir ces mises à jour dans Top SQL tant qu'elles dépassent le seuil de collecte Top SQL. SQL Sentry a des seuils par défaut que les requêtes doivent dépasser avant d'être capturées en tant que Top SQL (par exemple, la durée doit dépasser cinq (5) secondes), mais vous pouvez les modifier et ajouter d'autres seuils tels que les lectures. Dans cet exemple, à des fins de test uniquement , j'ai changé mon seuil de durée minimum Top SQL à 10 millisecondes et mon seuil de lecture à 500, et SQL Sentry a pu capturer certaines des mises à jour de statistiques :
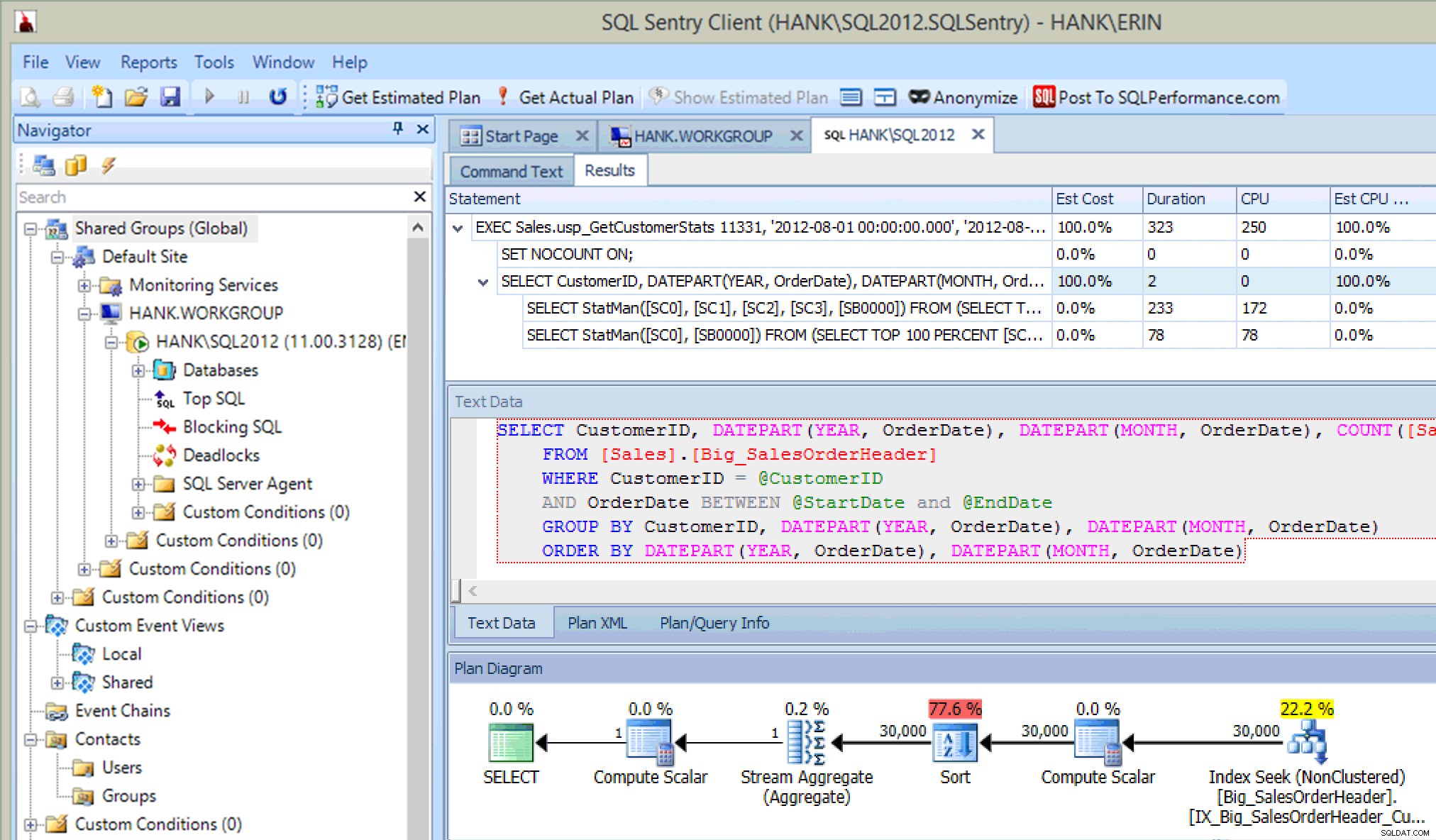
Mises à jour des statistiques capturées par SQL Sentry
Cela dit, la capacité de la surveillance à capturer ces événements dépendra en fin de compte des ressources système et de la quantité de données à lire pour mettre à jour la statistique. Vos mises à jour de statistiques ne peuvent pas dépasser ces seuils, vous devrez donc peut-être effectuer des recherches plus proactives pour les trouver.
Résumé
J'encourage toujours les administrateurs de base de données à gérer les statistiques de manière proactive, ce qui signifie qu'un travail est en place pour mettre à jour les statistiques de manière régulière. Cependant, même si ce travail s'exécute toutes les nuits (ce que je ne recommande pas nécessairement), il est tout à fait possible que les mises à jour des statistiques se produisent automatiquement tout au long de la journée, car certaines tables sont plus volatiles que d'autres et ont un nombre élevé de modifications. Ce n'est pas anormal, et selon la taille de la table et le nombre de modifications, les mises à jour automatiques peuvent ne pas interférer de manière significative avec les requêtes des utilisateurs. Mais la seule façon de savoir est de surveiller ces mises à jour – que vous utilisiez des outils natifs ou des outils tiers – afin que vous puissiez garder une longueur d'avance sur les problèmes potentiels et les résoudre avant qu'ils ne s'aggravent.