En tant qu'administrateurs de base de données SQL Server, nous avons entendu dire que les structures d'index peuvent considérablement améliorer les performances d'une requête donnée (ou d'un ensemble de requêtes). Pourtant, il y a certains détails que de nombreux administrateurs de base de données négligent, comme les suivants :
- Les structures d'index peuvent se fragmenter, ce qui peut entraîner des problèmes de dégradation des performances.
- Une fois qu'une structure d'index a été déployée pour une table de base de données, SQL Server la met à jour chaque fois que des opérations d'écriture ont lieu pour cette table. Cela se produit si les colonnes conformes à l'index sont affectées.
- Il existe des métadonnées dans SQL Server qui peuvent être utilisées pour savoir quand les statistiques d'une structure d'index particulière ont été mises à jour (le cas échéant) pour la dernière fois. Des statistiques insuffisantes ou obsolètes peuvent avoir un impact sur les performances de certaines requêtes.
- Il existe des métadonnées dans SQL Server qui peuvent être utilisées pour savoir combien une structure d'index a été soit consommée par des opérations de lecture, soit mise à jour par des opérations d'écriture par SQL Server lui-même. Cette information peut être utile pour savoir s'il existe des index dont le volume d'écriture dépasse largement celui de lecture. Il peut potentiellement s'agir d'une structure d'index qu'il n'est pas très utile de conserver.*
*Il est très important de garder à l'esprit que la vue système qui contient ces métadonnées particulières est effacée à chaque redémarrage de l'instance SQL Server, il ne s'agira donc pas d'informations dès sa conception.
En raison de l'importance de ces détails, j'ai créé une procédure stockée pour garder une trace des informations concernant les structures d'index dans son environnement, afin d'agir de la manière la plus proactive possible.
Considérations initiales
- Assurez-vous que le compte exécutant cette procédure stockée dispose de suffisamment de privilèges. Vous pourriez probablement commencer par ceux de l'administrateur système, puis aller aussi précisément que possible pour vous assurer que l'utilisateur dispose du minimum de privilèges requis pour que le SP fonctionne correctement.
- Les objets de la base de données (table de base de données et procédure stockée) seront créés dans la base de données sélectionnée au moment de l'exécution du script, choisissez donc avec soin.
- Le script est conçu de manière à pouvoir être exécuté plusieurs fois sans générer d'erreur. Pour la procédure stockée, j'ai utilisé l'instruction CREATE OR ALTER PROCEDURE, disponible depuis SQL Server 2016 SP1.
- N'hésitez pas à modifier le nom des objets de base de données créés si vous souhaitez utiliser une convention de dénomination différente.
- Lorsque vous choisissez de conserver les données renvoyées par la procédure stockée, la table cible sera d'abord tronquée afin que seul le jeu de résultats le plus récent soit stocké. Vous pouvez faire les ajustements nécessaires si vous voulez que cela se comporte différemment, pour quelque raison que ce soit (pour conserver des informations historiques peut-être ?).
Comment utiliser la procédure stockée ?
- Copiez et collez le code T-SQL (disponible dans cet article).
- Le SP attend 2 paramètres :
- @persistData :"O" si le DBA souhaite enregistrer la sortie dans une table cible, et "N" si le DBA souhaite uniquement voir la sortie directement.
- @db :'all' pour obtenir les informations de toutes les bases de données (système et utilisateur), 'user' pour cibler les bases de données utilisateur, 'system' pour cibler uniquement les bases de données système (hors tempdb), et enfin le nom réel de une base de données particulière.
Champs présentés et leur signification
- dbName : le nom de la base de données où réside l'objet index.
- schemaName : le nom du schéma où réside l'objet d'index.
- tableName : le nom de la table où réside l'objet d'index.
- nom de l'index : le nom de la structure d'index.
- tapez : le type d'index (par exemple, clusterisé, non clusterisé).
- allocation_unit_type : spécifie le type de données auquel il fait référence (par exemple, données en ligne, données de lob).
- fragmentation : le degré de fragmentation (en %) dont dispose actuellement la structure de l'index.
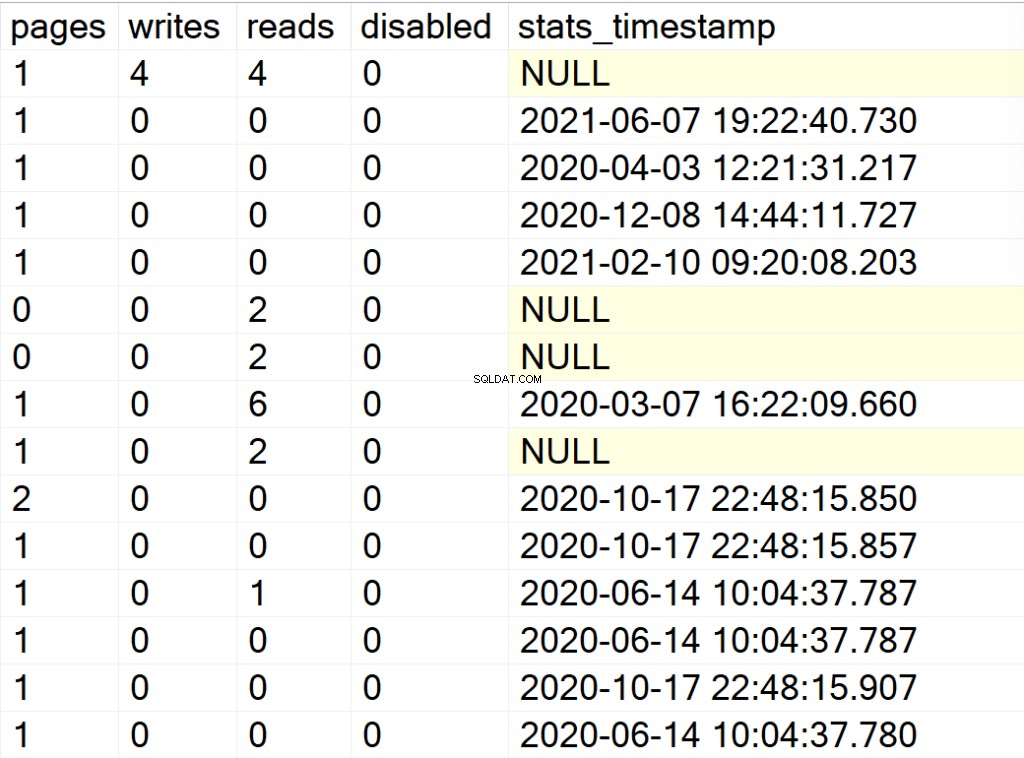
- pages : le nombre de pages de 8 Ko qui forment la structure de l'index.
- écrit : le nombre d'écritures que la structure d'index a subies depuis le dernier redémarrage de l'instance SQL Server.
- lit : le nombre de lectures que la structure d'index a subies depuis le dernier redémarrage de l'instance SQL Server.
- désactivé : 1 si la structure d'index est actuellement désactivée ou 0 si la structure est activée.
- stats_timestamp : la valeur d'horodatage de la dernière mise à jour des statistiques pour la structure d'index particulière (NULL si jamais).
- data_collection_timestamp : visible uniquement si 'Y' est passé au paramètre @persistData, et il est utilisé pour savoir quand le SP a été exécuté et les informations ont été enregistrées avec succès dans la table DBA_Indexes.
Tests d'exécution
Je vais vous montrer quelques exécutions de la procédure stockée afin que vous puissiez vous faire une idée de ce que vous pouvez en attendre :
*Vous pouvez trouver le code T-SQL complet du script dans la fin de cet article, alors assurez-vous de l'exécuter avant de passer à la section suivante.
*L'ensemble de résultats sera trop large pour tenir correctement dans 1 capture d'écran, je vais donc partager toutes les captures d'écran nécessaires pour présenter les informations complètes.
/* Affiche toutes les informations d'index pour toutes les bases de données système et utilisateur */
EXEC GetIndexData @persistData = 'N',@db = 'all'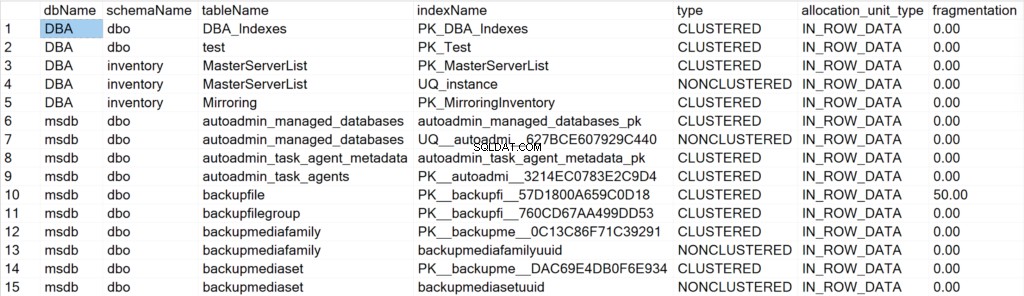
/* Affiche toutes les informations d'index pour toutes les bases de données du système */
EXEC GetIndexData @persistData = 'N',@db = 'system'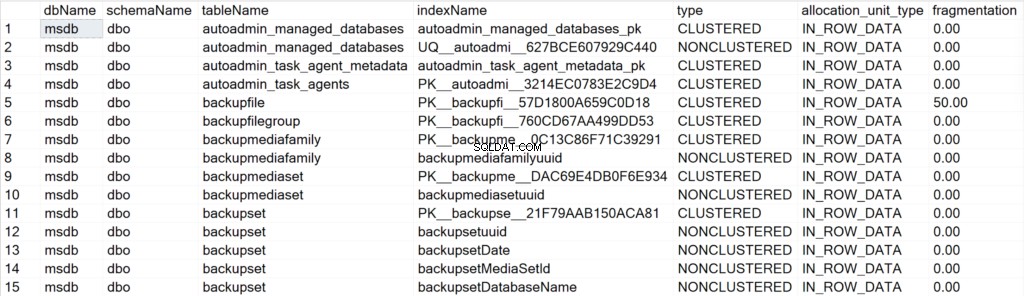
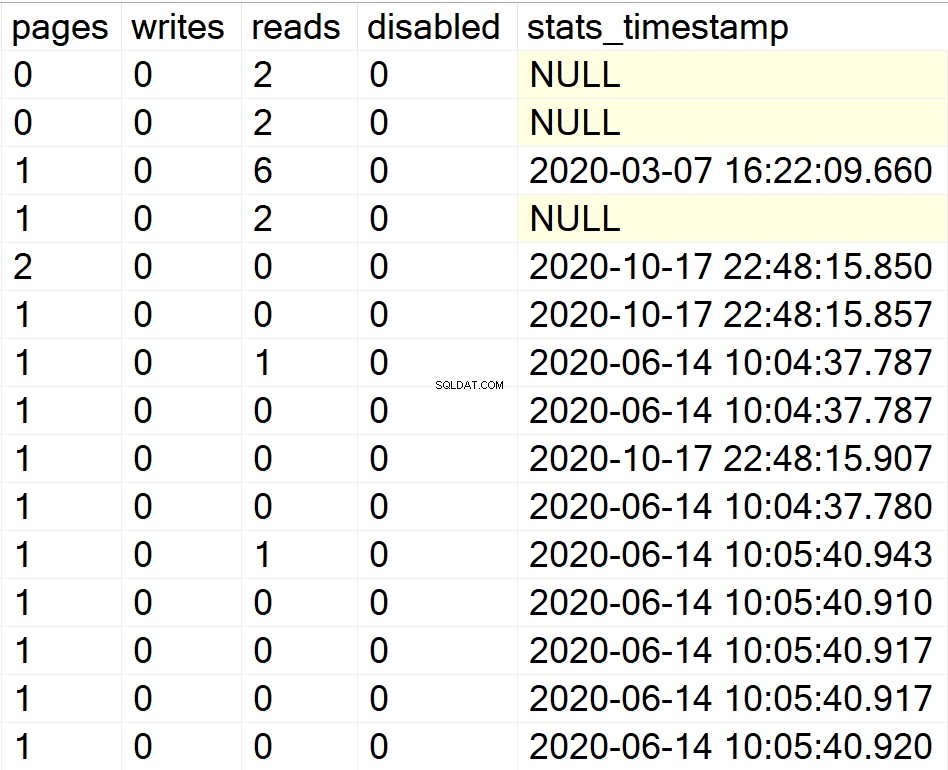
/* Affiche toutes les informations d'index pour toutes les bases de données utilisateur */
EXEC GetIndexData @persistData = 'N',@db = 'user'
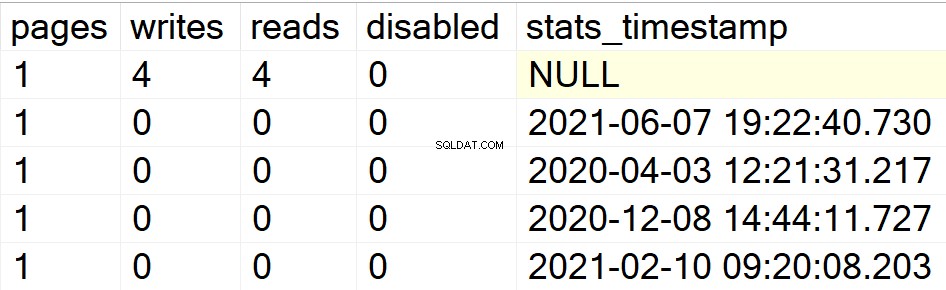
/* Affiche toutes les informations d'index pour des bases de données utilisateur spécifiques */
Dans mes exemples précédents, seule la base de données DBA apparaissait comme ma seule base de données utilisateur contenant des index. Par conséquent, permettez-moi de créer une structure d'index dans une autre base de données que j'ai dans la même instance afin que vous puissiez voir si le SP fait son travail ou non.
EXEC GetIndexData @persistData = 'N',@db = 'db2'
Tous les exemples présentés jusqu'à présent illustrent la sortie que vous obtenez lorsque vous ne souhaitez pas conserver les données, pour les différentes combinaisons d'options pour le paramètre @db. La sortie est vide lorsque vous spécifiez une option qui n'est pas valide ou que la base de données cible n'existe pas. Mais qu'en est-il lorsque le DBA souhaite conserver des données dans une table de base de données ? Découvrons.
*Je vais exécuter le SP pour un seul cas car le reste des options pour le paramètre @db a été à peu près présenté ci-dessus et le résultat est le même mais persiste dans une table de base de données.
EXEC GetIndexData @persistData = 'Y',@db = 'user'
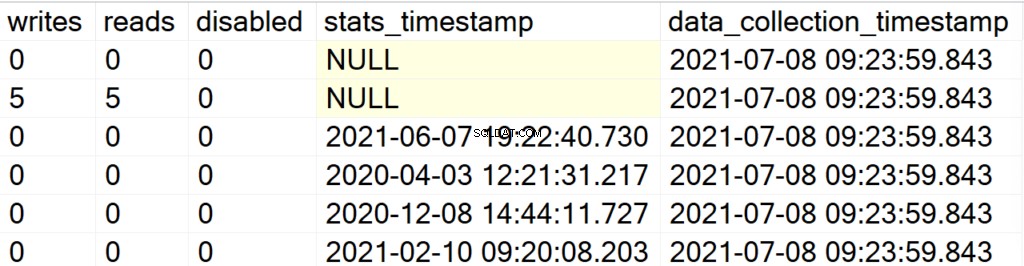
Maintenant, après avoir exécuté la procédure stockée, vous n'obtiendrez aucune sortie. Pour interroger le jeu de résultats, vous devez émettre une instruction SELECT sur la table DBA_Indexes. L'attraction principale ici est que vous pouvez interroger l'ensemble de résultats obtenu, pour la post-analyse, et l'ajout du champ data_collection_timestamp qui vous permettra de savoir à quel point les données que vous consultez sont récentes/anciennes.
Requêtes annexes
Maintenant, pour offrir plus de valeur au DBA, j'ai préparé quelques requêtes qui peuvent vous aider à obtenir des informations utiles à partir des données conservées dans la table.
* Requête pour trouver des index très fragmentés dans l'ensemble.
*Choisissez le nombre de % que vous considérez comme approprié.
*Les 1500 pages sont basées sur un article que j'ai lu, basé sur la recommandation de Microsoft.
SELECT * FROM DBA_Indexes WHERE fragmentation >= 85 AND pages >= 1500;*Requête pour trouver des index désactivés dans votre environnement.
SELECT * FROM DBA_Indexes WHERE disabled = 1;* Requête pour trouver des index (pour la plupart non clusterisés) qui ne sont pas très utilisés par les requêtes, du moins pas depuis le dernier redémarrage de l'instance SQL Server.
SELECT * FROM DBA_Indexes WHERE writes > reads AND type <> 'CLUSTERED';* Requête pour trouver des statistiques qui n'ont jamais été mises à jour ou qui sont anciennes.
*Vous déterminez ce qui est ancien dans votre environnement, alors assurez-vous d'ajuster le nombre de jours en conséquence.
SELECT * FROM DBA_Indexes WHERE stats_timestamp IS NULL OR DATEDIFF(DAY, stats_timestamp, GETDATE()) > 60;Voici le code complet de la procédure stockée :
*Au tout début du script, vous verrez la valeur par défaut que la procédure stockée assume si aucune valeur n'est transmise pour chaque paramètre.
IF NOT EXISTS (SELECT * FROM dbo.sysobjects where id = object_id(N'DBA_Indexes') and OBJECTPROPERTY(id, N'IsTable') = 1)
BEGIN
CREATE TABLE DBA_Indexes(
[dbName] VARCHAR(128) NOT NULL,
[schemaName] VARCHAR(128) NOT NULL,
[tableName] VARCHAR(128) NOT NULL,
[indexName] VARCHAR(128) NOT NULL,
[type] VARCHAR(128) NOT NULL,
[allocation_unit_type] VARCHAR(128) NOT NULL,
[fragmentation] DECIMAL(10,2) NOT NULL,
[pages] INT NOT NULL,
[writes] INT NOT NULL,
[reads] INT NOT NULL,
[disabled] TINYINT NOT NULL,
[stats_timestamp] DATETIME NULL,
[data_collection_timestamp] DATETIME NOT NULL
CONSTRAINT PK_DBA_Indexes PRIMARY KEY CLUSTERED ([dbName],[schemaName],[tableName],[indexName],[type],[allocation_unit_type],[data_collection_timestamp])
) ON [PRIMARY]
END
GO
DECLARE @sqlCommand NVARCHAR(MAX)
SET @sqlCommand = '
CREATE OR ALTER PROCEDURE GetIndexData
@persistData CHAR(1) = ''N'',
@db NVARCHAR(64)
AS
BEGIN
SET NOCOUNT ON
DECLARE @query NVARCHAR(MAX)
DECLARE @tmp_IndexInfo TABLE(
[dbName] VARCHAR(128),
[schemaName] VARCHAR(128),
[tableName] VARCHAR(128),
[indexName] VARCHAR(128),
[type] VARCHAR(128),
[allocation_unit_type] VARCHAR(128),
[fragmentation] DECIMAL(10,2),
[pages] INT,
[writes] INT,
[reads] INT,
[disabled] TINYINT,
[stats_timestamp] DATETIME)
SET @query = ''
USE [?]
''
IF(@db = ''all'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') != 2
''
IF(@db = ''system'')
SET @query += ''
IF DB_ID(''''?'''') > 0 AND DB_ID(''''?'''') < 5 AND DB_ID(''''?'''') != 2
''
IF(@db = ''user'')
SET @query += ''
IF DB_ID(''''?'''') > 4
''
IF(@db != ''user'' AND @db != ''all'' AND @db != ''system'')
SET @query += ''
IF DB_NAME() = ''+CHAR(39)example@sqldat.com+CHAR(39)+''
''
SET @query += ''
BEGIN
DECLARE @DB_ID INT;
SET @DB_ID = DB_ID();
SELECT
db_name(@DB_ID) AS db_name,
s.name,
t.name,
i.name,
i.type_desc,
ips.alloc_unit_type_desc,
CONVERT(DECIMAL(10,2),ips.avg_fragmentation_in_percent),
ips.page_count,
ISNULL(ius.user_updates,0),
ISNULL(ius.user_seeks + ius.user_scans + ius.user_lookups,0),
i.is_disabled,
STATS_DATE(st.object_id, st.stats_id)
FROM sys.indexes i
JOIN sys.tables t ON i.object_id = t.object_id
JOIN sys.schemas s ON s.schema_id = t.schema_id
JOIN sys.dm_db_index_physical_stats (@DB_ID, NULL, NULL, NULL, NULL) ips ON ips.database_id = @DB_ID AND ips.object_id = t.object_id AND ips.index_id = i.index_id
LEFT JOIN sys.dm_db_index_usage_stats ius ON ius.database_id = @DB_ID AND ius.object_id = t.object_id AND ius.index_id = i.index_id
JOIN sys.stats st ON st.object_id = t.object_id AND st.name = i.name
WHERE i.index_id > 0
END''
INSERT INTO @tmp_IndexInfo
EXEC sp_MSForEachDB @query
IF @persistData = ''N''
SELECT * FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
ELSE
BEGIN
TRUNCATE TABLE DBA_Indexes
INSERT INTO DBA_Indexes
SELECT *,GETDATE() FROM @tmp_IndexInfo ORDER BY [dbName],[schemaName],[tableName]
END
END
'
EXEC (@sqlCommand)
GOConclusion
- Vous pouvez déployer ce SP dans chaque instance SQL Server prise en charge et implémenter un mécanisme d'alerte sur l'ensemble de votre pile d'instances prises en charge.
- Si vous implémentez une tâche d'agent qui interroge ces informations relativement fréquemment, vous pouvez rester au top du jeu pour vous occuper des structures d'index dans votre ou vos environnements pris en charge.
- Assurez-vous de tester correctement ce mécanisme dans un environnement sandbox et, lorsque vous planifiez un déploiement en production, veillez à choisir des périodes de faible activité.
Les problèmes de fragmentation d'index peuvent être délicats et stressants. Pour les trouver et les corriger, vous pouvez utiliser différents outils, comme dbForge Index Manager qui peut être téléchargé ici.