Le partitionnement de table dans SQL Server est essentiellement un moyen de faire en sorte que plusieurs tables physiques (ensembles de lignes) ressemblent à une table unique. Cette abstraction est entièrement réalisée par le processeur de requêtes, une conception qui simplifie les choses pour les utilisateurs, mais qui impose des exigences complexes à l'optimiseur de requêtes. Cet article examine deux exemples qui dépassent les capacités de l'optimiseur dans SQL Server 2008 et versions ultérieures.
Rejoindre les questions d'ordre de colonne
Ce premier exemple montre comment l'ordre textuel de ON les conditions de clause peuvent affecter le plan de requête produit lors de la jointure de tables partitionnées. Pour commencer, nous avons besoin d'un schéma de partitionnement, d'une fonction de partitionnement et de deux tables :
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Ensuite, nous chargeons les deux tables avec 150 000 lignes. Les données n'ont pas beaucoup d'importance; cet exemple utilise une table Numbers standard contenant toutes les valeurs entières de 1 à 150 000 comme source de données. Les deux tables sont chargées avec les mêmes données.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Notre requête de test effectue une simple jointure interne de ces deux tables. Encore une fois, la requête n'est pas importante ou destinée à être particulièrement réaliste, elle est utilisée pour démontrer un effet étrange lors de la jointure de tables partitionnées. La première forme de la requête utilise un ON clause écrite dans l'ordre des colonnes c3, c2, c1 :
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Le plan d'exécution produit pour cette requête (sur SQL Server 2008 et versions ultérieures) comporte une jointure de hachage parallèle, avec un coût estimé à 2,6953 :
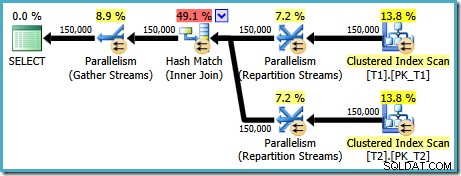
C'est un peu inattendu. Les deux tables ont un index clusterisé dans l'ordre (c1, c2, c3), partitionné par c1, nous nous attendons donc à une jointure de fusion, tirant parti de l'ordre de l'index. Essayons d'écrire le ON clause dans l'ordre (c1, c2, c3) :
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Le plan d'exécution utilise désormais la jointure de fusion attendue, avec un coût estimé de 1,64119 (en baisse de 2,6953 ). L'optimiseur décide également qu'il ne vaut pas la peine d'utiliser l'exécution parallèle :
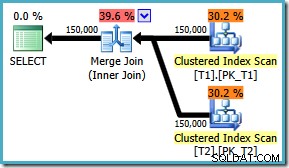
Notant que le plan de jointure par fusion est clairement plus efficace, nous pouvons tenter de forcer une jointure par fusion pour le ON d'origine ordre des clauses à l'aide d'un indicateur de requête :
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Le plan résultant utilise une jointure de fusion comme demandé, mais il comporte également des tris sur les deux entrées et revient à l'utilisation du parallélisme. Le coût estimé de ce plan est un énorme 8,71063 :
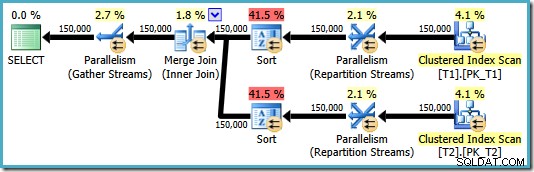
Les deux opérateurs de tri ont les mêmes propriétés :
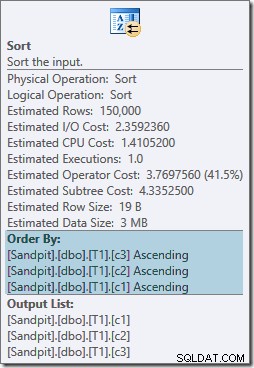
L'optimiseur pense que la jointure de fusion a besoin de ses entrées triées dans l'ordre écrit strict du ON clause, introduisant des tris explicites en conséquence. L'optimiseur sait qu'une jointure par fusion nécessite que ses entrées soient triées de la même manière, mais il sait également que l'ordre des colonnes n'a pas d'importance. La jointure de fusion sur (c1, c2, c3) est aussi satisfaisante avec les entrées triées sur (c3, c2, c1) qu'avec les entrées triées sur (c2, c1, c3) ou toute autre combinaison.
Malheureusement, ce raisonnement est rompu dans l'optimiseur de requête lorsque le partitionnement est impliqué. Il s'agit d'un bogue de l'optimiseur qui a été corrigé dans SQL Server 2008 R2 et versions ultérieures, bien que l'indicateur de trace 4199 est nécessaire pour activer le correctif :
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Vous devez normalement activer cet indicateur de trace à l'aide de DBCC TRACEON ou comme option de démarrage, car le QUERYTRACEON l'indice n'est pas documenté pour une utilisation avec 4199. L'indicateur de trace est requis dans SQL Server 2008 R2, SQL Server 2012 et SQL Server 2014 CTP1.
Quoi qu'il en soit, quelle que soit la manière dont l'indicateur est activé, la requête produit désormais la jointure de fusion optimale quel que soit le ON ordre des clauses :
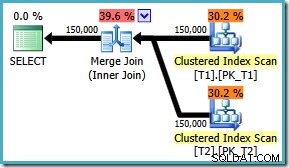
Il n'y a pas de correctif pour SQL Server 2008 , la solution consiste à écrire le ON clause dans le "bon" ordre ! Si vous rencontrez une requête comme celle-ci sur SQL Server 2008, essayez de forcer une jointure par fusion et examinez les tris pour déterminer la manière "correcte" d'écrire le ON de votre requête. clause.
Ce problème ne se pose pas dans SQL Server 2005 car cette version a implémenté des requêtes partitionnées à l'aide de APPLY modèle :

Le plan de requête SQL Server 2005 joint une partition de chaque table à la fois, en utilisant une table en mémoire (l'analyse constante) contenant les numéros de partition à traiter. Chaque partition est fusionnée séparément du côté interne de la jointure, et l'optimiseur 2005 est assez intelligent pour voir que le ON l'ordre des colonnes de clause n'a pas d'importance.
Ce dernier plan est un exemple de jointure de fusion colocalisée , une fonctionnalité qui a été perdue lors du passage de SQL Server 2005 à la nouvelle implémentation de partitionnement dans SQL Server 2008. Une suggestion sur Connecter pour rétablir les jointures de fusion colocalisées a été fermée car ne sera pas corrigée.
Regrouper par ordre les questions
La deuxième particularité que je veux examiner suit un thème similaire, mais concerne l'ordre des colonnes dans un GROUP BY clause plutôt que le ON clause d'une jointure interne. Nous aurons besoin d'un nouveau tableau pour démontrer :
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; La table a un index non cluster aligné, où "aligné" signifie simplement qu'il est partitionné de la même manière que l'index cluster (ou tas) :
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Notre requête de test regroupe les données dans les trois colonnes d'index non clusterisées et renvoie un nombre pour chaque groupe :
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Le plan de requête analyse l'index non clusterisé et utilise un agrégat de correspondance de hachage pour compter les lignes dans chaque groupe :
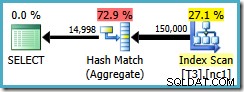
Il y a deux problèmes avec Hash Aggregate :
- C'est un opérateur bloquant. Aucune ligne n'est renvoyée au client tant que toutes les lignes n'ont pas été agrégées.
- Il nécessite une allocation de mémoire pour contenir la table de hachage.
Dans de nombreux scénarios réels, nous préférerions ici un Stream Aggregate car cet opérateur ne bloque que par groupe et ne nécessite pas d'allocation de mémoire. En utilisant cette option, l'application cliente commencerait à recevoir des données plus tôt, n'aurait pas à attendre que la mémoire soit accordée et le serveur SQL peut utiliser la mémoire à d'autres fins.
Nous pouvons exiger que l'optimiseur de requête utilise un Stream Aggregate pour cette requête en ajoutant une OPTION (ORDER GROUP) indice de requête. Cela se traduit par le plan d'exécution suivant :

L'opérateur de tri est entièrement bloquant et nécessite également une allocation de mémoire, donc ce plan semble être pire que la simple utilisation d'un agrégat de hachage. Mais pourquoi le tri est-il nécessaire ? Les propriétés montrent que les lignes sont triées dans l'ordre spécifié par notre GROUP BY clause :
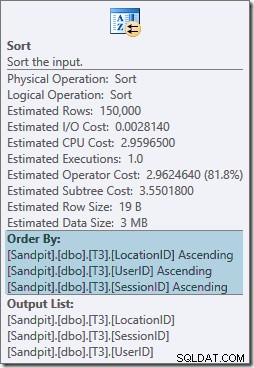
Ce tri est attendu car l'alignement de partition de l'index (dans SQL Server 2008 et versions ultérieures) signifie que le numéro de partition est ajouté en tant que colonne principale de l'index. En effet, les clés d'index non clusterisées sont (partition, utilisateur, session, emplacement) dues au partitionnement. Les lignes de l'index sont toujours triées par utilisateur, session et emplacement, mais uniquement dans chaque partition.
Si nous restreignons la requête à une seule partition, l'optimiseur devrait pouvoir utiliser l'index pour alimenter un Stream Aggregate sans effectuer de tri. Au cas où cela nécessiterait des explications, la spécification d'une seule partition signifie que le plan de requête peut éliminer toutes les autres partitions de l'analyse de l'index non clusterisé, ce qui donne un flux de lignes triées par (utilisateur, session, emplacement).
Nous pouvons réaliser cette élimination de partition explicitement en utilisant le $PARTITION fonction :
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Malheureusement, cette requête utilise toujours un agrégat de hachage, avec un coût de plan estimé à 0,287878 :
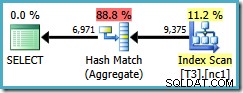
L'analyse porte maintenant sur une seule partition, mais l'ordre (utilisateur, session, emplacement) n'a pas aidé l'optimiseur à utiliser un Stream Aggregate. Vous pouvez objecter que l'ordre (utilisateur, session, emplacement) n'est pas utile car le GROUP BY la clause est (emplacement, utilisateur, session), mais l'ordre des clés n'a pas d'importance pour une opération de regroupement.
Ajoutons un ORDER BY clause dans l'ordre des clés d'index pour prouver le point :
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Notez que le ORDER BY la clause correspond à l'ordre des clés d'index non clusterisées, bien que le GROUP BY clause ne le fait pas. Le plan d'exécution de cette requête est :
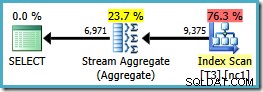
Nous avons maintenant le Stream Aggregate que nous recherchions, avec un coût de plan estimé à 0,0423925 (par rapport à 0,287878 pour le plan Hash Aggregate - presque 7 fois plus).
L'autre façon d'obtenir un Stream Aggregate ici est de réorganiser le GROUP BY colonnes pour correspondre aux clés d'index non cluster :
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Cette requête produit le même plan Stream Aggregate indiqué ci-dessus, avec exactement le même coût. Cette sensibilité à GROUP BY l'ordre des colonnes est spécifique aux requêtes de table partitionnée dans SQL Server 2008 et versions ultérieures.
Vous pouvez reconnaître que la cause principale du problème ici est similaire au cas précédent impliquant une jointure par fusion. Merge Join et Stream Aggregate nécessitent des entrées triées sur les clés de jointure ou d'agrégation, mais aucun ne se soucie de l'ordre de ces clés. Une jointure de fusion sur (x, y, z) est tout aussi heureuse de recevoir des lignes classées par (y, z, x) ou (z, y, x) et il en va de même pour Stream Aggregate.
Cette limitation de l'optimiseur s'applique également à DISTINCT dans les mêmes circonstances. La requête suivante aboutit à un plan Hash Aggregate avec un coût estimé de 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
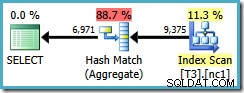
Si nous écrivons le DISTINCT colonnes dans l'ordre des clés d'index non clusterisées…
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
… nous sommes récompensés par un plan Stream Aggregate avec un coût de 0,041455 :

Pour résumer, il s'agit d'une limitation de l'optimiseur de requête dans SQL Server 2008 et versions ultérieures (y compris SQL Server 2014 CTP 1) qui n'est pas résolue en utilisant l'indicateur de trace 4199 comme c'était le cas pour l'exemple Merge Join. Le problème se produit uniquement avec les tables partitionnées avec un GROUP BY ou DISTINCT sur trois colonnes ou plus à l'aide d'un index partitionné aligné, où une seule partition est traitée.
Comme dans l'exemple Merge Join, cela représente un pas en arrière par rapport au comportement de SQL Server 2005. SQL Server 2005 n'a pas ajouté de clé de début implicite aux index partitionnés, en utilisant un APPLY technique à la place. Dans SQL Server 2005, toutes les requêtes présentées ici utilisent $PARTITION pour spécifier un seul résultat de partition dans les plans de requête qui effectuent l'élimination des partitions et utilisent les agrégats de flux sans réorganiser le texte de la requête.
Les modifications apportées au traitement des tables partitionnées dans SQL Server 2008 ont amélioré les performances dans plusieurs domaines importants, principalement liés au traitement parallèle efficace des partitions. Malheureusement, ces changements ont eu des effets secondaires qui n'ont pas tous été résolus dans les versions ultérieures.