SQL Server 2005 a ajouté la possibilité d'inclure des colonnes non clés dans un index non clusterisé. Dans SQL Server 2000 et les versions antérieures, pour un index non clusterisé, toutes les colonnes définies pour un index étaient des colonnes clés, ce qui signifiait qu'elles faisaient partie de chaque niveau de l'index, de la racine au niveau feuille. Lorsqu'une colonne est définie comme une colonne incluse, elle fait partie du niveau feuille uniquement. La documentation en ligne note les avantages suivants des colonnes incluses :
- Il peut s'agir de types de données non autorisés en tant que colonnes de clé d'index.
- Ils ne sont pas pris en compte par le moteur de base de données lors du calcul du nombre de colonnes de clé d'index ou de la taille de la clé d'index.
Par exemple, une colonne varchar(max) ne peut pas faire partie d'une clé d'index, mais il peut s'agir d'une colonne incluse. De plus, cette colonne varchar(max) ne compte pas dans la limite de 900 octets (ou 16 colonnes) imposée pour la clé d'index.
La documentation note également l'avantage de performances suivant :
Un index avec des colonnes non-clés peut améliorer considérablement les performances des requêtes lorsque toutes les colonnes de la requête sont incluses dans l'index en tant que colonnes clés ou non-clés. Des gains de performances sont obtenus car l'optimiseur de requête peut localiser toutes les valeurs de colonne dans l'index; les données de la table ou de l'index clusterisé ne sont pas accessibles, ce qui réduit le nombre d'opérations d'E/S sur le disque.Nous pouvons en déduire que, que les colonnes d'index soient des colonnes clés ou des colonnes non clés, nous obtenons une amélioration des performances par rapport au moment où toutes les colonnes ne font pas partie de l'index. Mais y a-t-il une différence de performances entre les deux variantes ?
La configuration
J'ai installé une copie de la base de données AdventuresWork2012 et vérifié les index de la table Sales.SalesOrderHeader à l'aide de la version de sp_helpindex de Kimberly Tripp :
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Index par défaut pour Sales.SalesOrderHeader
Nous allons commencer par une requête simple pour les tests qui récupère les données de plusieurs colonnes :
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Si nous exécutons cela sur la base de données AdventureWorks2012 à l'aide de SQL Sentry Plan Explorer et vérifions le plan et la sortie d'E/S de la table, nous constatons que nous obtenons une analyse d'index clusterisée avec 689 lectures logiques :
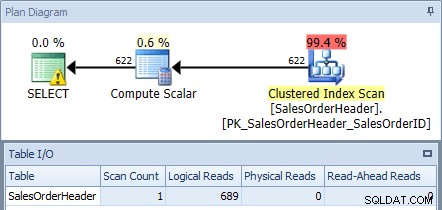
Plan d'exécution à partir de la requête d'origine
(Dans Management Studio, vous pouviez voir les métriques d'E/S en utilisant SET STATISTICS IO ON; .)
Le SELECT a une icône d'avertissement, car l'optimiseur recommande un index pour cette requête :
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Essai 1
Nous allons d'abord créer l'index recommandé par l'optimiseur (nommé NCI1_included), ainsi que la variation avec toutes les colonnes comme colonnes clés (nommée NCI1) :
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Si nous réexécutons la requête d'origine, une fois avec NCI1 et une fois avec NCI1_included, nous voyons un plan similaire à l'original, mais cette fois, il y a une recherche d'index de chaque index non clusterisé, avec des valeurs équivalentes pour le tableau I/ O, et coûts similaires (tous deux d'environ 0,006) :
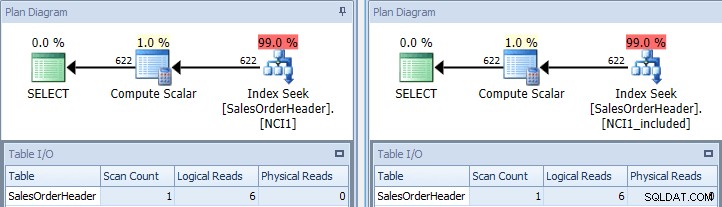
Requête originale avec recherche d'index - clé à gauche, inclure sur le droit
(Le nombre de balayages est toujours de 1 car la recherche d'index est en fait un balayage de plage déguisé.)
Maintenant, la base de données AdventureWorks2012 n'est pas représentative d'une base de données de production en termes de taille, et si nous regardons le nombre de pages dans chaque index, nous voyons qu'elles sont exactement les mêmes :
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
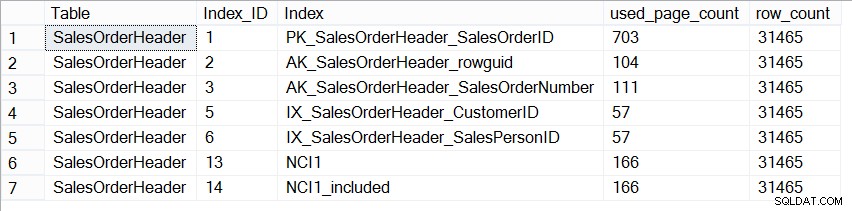
Taille des index sur Sales.SalesOrderHeader
Si nous examinons les performances, il est idéal (et plus amusant) de tester avec un ensemble de données plus important.
Essai 2
J'ai une copie de la base de données AdventureWorks2012 qui a une table SalesOrderHeader avec plus de 200 millions de lignes (script ICI), alors créons les mêmes index non clusterisés dans cette base de données et réexécutons les requêtes :
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
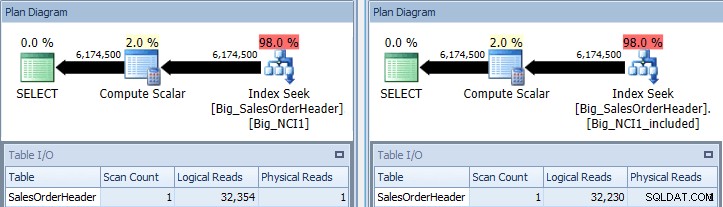
Requête originale avec recherche d'index sur Big_NCI1 (l) et Big_NCI1_Included ( r)
Maintenant, nous obtenons des données. La requête renvoie plus de 6 millions de lignes et la recherche de chaque index nécessite un peu plus de 32 000 lectures, et le coût estimé est le même pour les deux requêtes (31,233). Aucune différence de performances pour le moment, et si nous vérifions la taille des index, nous constatons que l'index avec les colonnes incluses a 5 578 pages de moins :
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Taille des index sur Sales.Big_SalesOrderHeader
Si nous creusons davantage et vérifions dm_dm_index_physical_stats, nous pouvons voir qu'il existe une différence dans les niveaux intermédiaires de l'index :
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
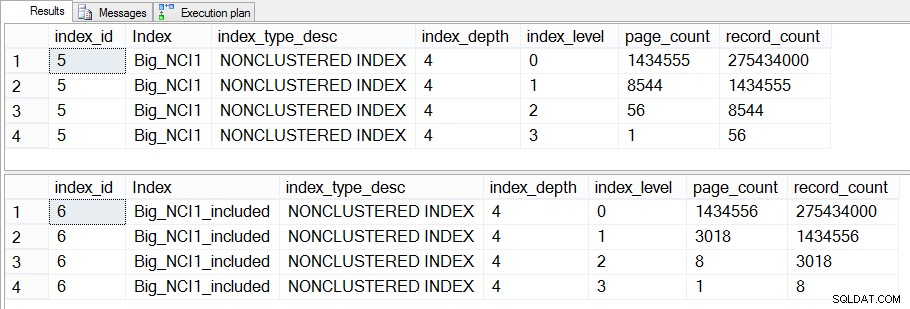
Taille des index (spécifique au niveau) sur Sales.Big_SalesOrderHeader
La différence entre les niveaux intermédiaires des deux index est de 43 Mo, ce qui n'est peut-être pas significatif, mais je serais probablement toujours enclin à créer l'index avec des colonnes incluses pour économiser de l'espace - à la fois sur le disque et en mémoire. Du point de vue des requêtes, nous ne voyons toujours pas de grand changement dans les performances entre l'index avec toutes les colonnes dans la clé et l'index avec les colonnes incluses.
Essai 3
Pour ce test, changeons la requête et ajoutons un filtre pour [SubTotal] >= 100 à la clause WHERE :
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
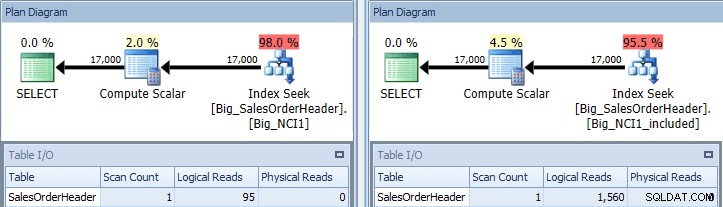
Plan d'exécution de la requête avec le prédicat SubTotal sur les deux index
Maintenant, nous voyons une différence dans les E/S (95 lectures contre 1 560), le coût (0,848 contre 1,55) et une différence subtile mais notable dans le plan de requête. Lorsque vous utilisez l'index avec toutes les colonnes de la clé, le prédicat de recherche est le CustomerID et le SubTotal :
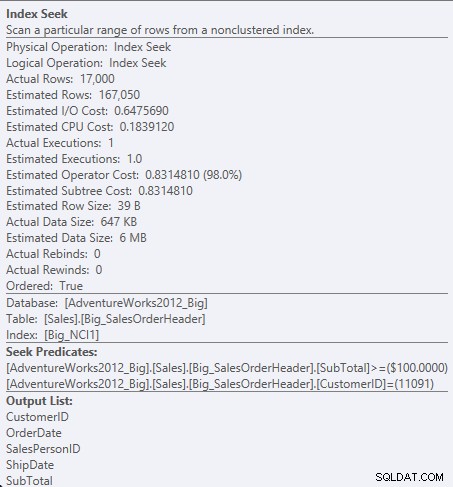
Rechercher le prédicat contre NCI1
Étant donné que SubTotal est la deuxième colonne de la clé d'index, les données sont triées et le SubTotal existe dans les niveaux intermédiaires de l'index. Le moteur est capable de rechercher directement le premier enregistrement avec un CustomerID de 11091 et un sous-total supérieur ou égal à 100, puis de lire l'index jusqu'à ce qu'il n'existe plus d'enregistrements pour le CustomerID 11091.
Pour l'index avec les colonnes incluses, le sous-total n'existe qu'au niveau feuille de l'index, donc CustomerID est le prédicat de recherche et SubTotal est un prédicat résiduel (juste répertorié comme prédicat dans la capture d'écran) :
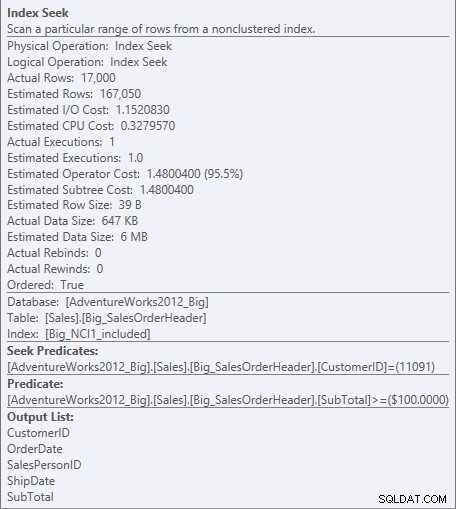
Rechercher le prédicat et le prédicat résiduel contre NCI1_included
Le moteur peut rechercher directement le premier enregistrement où CustomerID est 11091, mais il doit ensuite examiner chaque enregistrement pour CustomerID 11091 pour voir si le sous-total est égal ou supérieur à 100, car les données sont triées par CustomerID et SalesOrderID (clé de clustering).
Essai 4
Nous allons essayer une autre variante de notre requête, et cette fois nous ajouterons un ORDER BY :
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
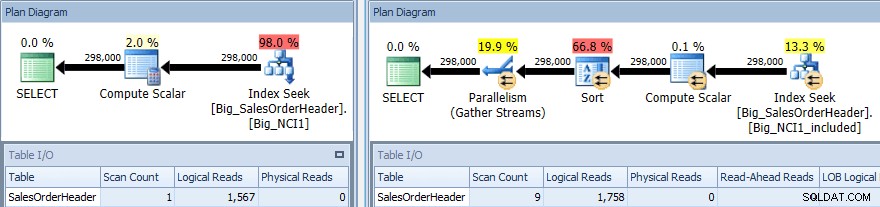
Plan d'exécution de la requête avec SORT sur les deux index
Encore une fois, nous avons un changement d'E/S (bien que très léger), un changement de coût (1,5 contre 9,3) et un changement beaucoup plus important dans la forme du plan ; nous voyons également un plus grand nombre de scans (1 contre 9). La requête nécessite que les données soient triées par sous-total ; lorsque SubTotal fait partie de la clé d'index, il est trié. Ainsi, lorsque les enregistrements pour CustomerID 11091 sont récupérés, ils sont déjà dans l'ordre demandé.
Lorsque SubTotal existe en tant que colonne incluse, les enregistrements pour CustomerID 11091 doivent être triés avant de pouvoir être renvoyés à l'utilisateur. Par conséquent, l'optimiseur injecte un opérateur de tri dans la requête. Par conséquent, la requête qui utilise l'index Big_NCI1_included demande également (et reçoit) une allocation de mémoire de 29 312 Ko, ce qui est notable (et trouvé dans les propriétés du plan).
Résumé
La question initiale à laquelle nous voulions répondre était de savoir si nous verrions une différence de performances lorsqu'une requête utilisait l'index avec toutes les colonnes de la clé, par rapport à l'index avec la plupart des colonnes incluses au niveau feuille. Dans notre première série de tests, il n'y avait aucune différence, mais dans nos troisième et quatrième tests, il y en avait. Cela dépend finalement de la requête. Nous n'avons examiné que deux variantes - l'une avait un prédicat supplémentaire, l'autre avait un ORDER BY - il en existe bien d'autres.
Ce que les développeurs et les administrateurs de base de données doivent comprendre, c'est qu'il existe de grands avantages à inclure des colonnes dans un index, mais qu'elles ne fonctionneront pas toujours de la même manière que les index qui ont toutes les colonnes dans la clé. Il peut être tentant de déplacer les colonnes qui ne font pas partie des prédicats et des jointures hors de la clé, et de les inclure simplement, afin de réduire la taille globale de l'index. Cependant, dans certains cas, cela nécessite plus de ressources pour l'exécution de la requête et peut dégrader les performances. La dégradation peut être insignifiante; ce n'est peut-être pas le cas… vous ne le saurez pas tant que vous n'aurez pas testé. Par conséquent, lors de la conception d'un index, il est important de penser aux colonnes après la première - et de comprendre si elles doivent faire partie de la clé (par exemple, parce que garder les données ordonnées apportera des avantages) ou si elles peuvent servir leur objectif comme inclus Colonnes.
Comme c'est généralement le cas avec l'indexation dans SQL Server, vous devez tester vos requêtes avec vos index pour déterminer la meilleure stratégie. Cela reste un art et une science - essayer de trouver le nombre minimum d'index pour satisfaire autant de requêtes que possible.



