Le sérialisable le niveau d'isolement fournit une protection complète des effets de concurrence qui peuvent menacer l'intégrité des données et conduire à des résultats de requête incorrects. L'utilisation de l'isolement sérialisable signifie que si une transaction peut produire des résultats corrects sans activité simultanée, elle continuera à fonctionner correctement lorsqu'elle est en concurrence avec n'importe quelle combinaison de transactions simultanées.
C'est une garantie très puissante , et qui correspond probablement aux attentes intuitives d'isolation des transactions de nombreux programmeurs T-SQL (bien qu'en vérité, relativement peu d'entre eux utiliseront systématiquement l'isolation sérialisable en production).
La norme SQL définit trois niveaux d'isolation supplémentaires qui offrent un ACID beaucoup plus faible garanties d'isolation que sérialisables, en échange d'une simultanéité potentiellement plus élevée et de moins d'effets secondaires potentiels tels que le blocage, le blocage et les abandons au moment de la validation.
Contrairement à l'isolement sérialisable, les autres niveaux d'isolement sont définis uniquement en termes de certains phénomènes de concurrence pouvant être observés. Le deuxième plus fort des niveaux d'isolation standard après sérialisable est nommé lecture répétable . La norme SQL spécifie que les transactions à ce niveau autorisent un phénomène de concurrence unique appelé fantôme .
Tout comme nous avons déjà vu des différences importantes entre la signification intuitive commune des propriétés de transaction ACID et la réalité, le phénomène fantôme englobe un éventail de comportements plus large qu'on ne l'apprécie souvent.
Cet article de la série examine les garanties réelles fournies par la lecture répétable niveau d'isolement et montre certains des comportements liés au fantôme qui peuvent être rencontrés. Pour illustrer certains points, nous nous référerons à l'exemple de requête simple suivant, où la tâche simple consiste à compter le nombre total de lignes dans une table :
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Lecture répétable
Une chose étrange à propos du niveau d'isolement de lecture répétable est qu'il ne le fait pas garantissent en fait que les lectures sont répétables , du moins dans un sens courant. Ceci est un autre exemple où le sens intuitif seul peut être trompeur. Exécuter deux fois la même requête dans la même transaction de lecture répétable peut en effet renvoyer des résultats différents.
En plus de cela, l'implémentation SQL Server de la lecture répétable signifie qu'une seule lecture d'un ensemble de données peut manquer certaines lignes qui devrait logiquement être pris en compte dans le résultat de la requête. Bien qu'indéniablement spécifique à l'implémentation, ce comportement est entièrement conforme à la définition de lecture répétable contenue dans la norme SQL.
La dernière chose que je veux noter rapidement avant d'entrer dans les détails, c'est que la lecture répétable dans SQL Server ne le fait pas fournir une vue ponctuelle des données.
Lectures non répétables
Le niveau d'isolement de lecture reproductible garantit que les données ne changeront pas pour la durée de vie de la transaction une fois qu'elle a été lue pour la première fois.
Il y a quelques subtilités contenues dans cette définition. Tout d'abord, cela permet aux données de changer après la transaction commence mais avant que les données ne soient premières accédé. Deuxièmement, il n'y a aucune garantie que la transaction rencontrera réellement toutes les données qui se qualifient logiquement. Nous verrons des exemples des deux sous peu.
Il y a un autre préliminaire dont nous devons nous débarrasser rapidement, qui a à voir avec l'exemple de requête que nous allons utiliser. En toute honnêteté, la sémantique de cette requête est un peu floue. Au risque de paraître un peu philosophique, qu'est-ce que cela signifie ? compter le nombre de lignes dans le tableau ? Le résultat doit-il refléter l'état de la table tel qu'il était à un moment donné ? Ce moment doit-il être le début ou la fin de la transaction, ou autre chose ?
Cela peut sembler un peu pointilleux, mais la question est valable dans n'importe quelle base de données qui prend en charge les lectures et modifications de données simultanées. L'exécution de notre exemple de requête peut prendre un temps arbitrairement long (étant donné une table suffisamment grande ou des contraintes de ressources, par exemple), de sorte que des modifications simultanées ne sont pas seulement possibles, elles peuvent être inévitables .
Le problème fondamental ici est le potentiel du phénomène de concurrence appelé fantôme dans la norme SQL. Pendant que nous comptons les lignes dans le tableau, une autre transaction simultanée peut insérer de nouvelles lignes dans un endroit que nous avons déjà vérifié, ou modifier une ligne que nous n'avons pas encore vérifiée de telle manière qu'elle se déplace vers un endroit que nous avons déjà regardé. Les gens pensent souvent que les fantômes sont des rangées qui peuvent apparaître comme par magie lorsqu'elles sont lues une deuxième fois, dans une déclaration séparée, mais les effets peuvent être beaucoup plus subtils que cela.
Exemple d'insertion simultanée
Ce premier exemple montre comment des insertions simultanées peuvent produire un non répétable lire et/ou entraîner le saut de lignes. Imaginez que notre table de test contienne initialement cinq lignes avec les valeurs indiquées ci-dessous :

Nous définissons maintenant le niveau d'isolement sur lecture répétable, démarrons une transaction et exécutons notre requête de comptage. Comme vous vous en doutez, le résultat est cinq . Pas de grand mystère jusqu'à présent.
Toujours en cours d'exécution dans la même transaction de lecture reproductible , nous exécutons à nouveau la requête de comptage, mais cette fois pendant qu'une deuxième transaction simultanée insère de nouvelles lignes dans la même table. Le diagramme ci-dessous montre la séquence des événements, la deuxième transaction ajoutant des lignes avec les valeurs 2 et 6 (vous avez peut-être remarqué que ces valeurs brillaient par leur absence juste au-dessus) :
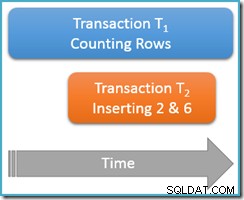
Si notre requête de comptage s'exécutait au sérialisable niveau d'isolement, il serait garanti de compter soit cinq ou sept rangées (voir l'article précédent de cette série si vous avez besoin d'un rappel sur pourquoi c'est le cas). Comment fonctionne la course chez les moins isolés le niveau de lecture répétable affecte-t-il les choses ?
Eh bien, lecture répétable isolation garantit que la deuxième exécution de la requête de comptage verra toutes les lignes précédemment lues et qu'elles seront dans le même état qu'auparavant. Le hic, c'est que l'isolation de lecture reproductible ne dit rien sur la façon dont la transaction doit traiter les nouvelles lignes (les fantômes).
Imaginez que notre transaction de comptage de lignes (T1 ) a une stratégie d'exécution physique où les lignes sont recherchées dans un ordre d'index croissant. C'est un cas courant, par exemple lorsqu'un balayage d'index b-tree ordonné vers l'avant est utilisé par le moteur d'exécution. Maintenant, juste après la transaction T1 compte les lignes 1 et 3 dans l'ordre croissant, transaction T2 pourrait se faufiler, insérer de nouvelles lignes 2 et 6, puis valider sa transaction.
Bien que nous pensions principalement aux comportements logiques à ce stade, je dois mentionner qu'il n'y a rien dans l'implémentation de verrouillage SQL Server de lecture répétable pour empêcher opération T2 de faire ça. Verrous partagés pris par la transaction T1 sur les lignes lues précédemment empêchent ces lignes d'être modifiées, mais elles n'empêchent pas les nouvelles lignes d'être inséré dans la plage de valeurs testée par notre requête de comptage (contrairement aux verrous de plage de clés dans le verrouillage de l'isolement sérialisable).
Quoi qu'il en soit, avec les deux nouvelles lignes validées, la transaction T1 continue sa recherche par ordre croissant, rencontrant finalement les lignes 4, 5, 6 et 7. Notez que T1 voit la nouvelle ligne 6 dans ce scénario, mais pas nouvelle ligne 2 (en raison de la recherche ordonnée et de sa position au moment de l'insertion).
Le résultat est que la lecture répétable la requête de comptage signale que le tableau contient six lignes (valeurs 1, 3, 4, 5, 6 et 7). Ce résultat est incohérent avec le résultat précédent de cinq lignes obtenu dans la même transaction . La deuxième lecture a compté la ligne fantôme 6 mais a raté la ligne fantôme 2. Voilà pour la signification intuitive d'une lecture répétable !
Exemple de mise à jour simultanée
Une situation similaire peut se produire avec une mise à jour simultanée au lieu d'un insert. Imaginez que notre table de test soit réinitialisée pour contenir les cinq mêmes lignes qu'avant :

Cette fois, nous n'exécuterons notre requête de comptage qu'une fois à la lecture répétable niveau d'isolement, tandis qu'une deuxième transaction simultanée met à jour la ligne avec la valeur 5 pour avoir une valeur de 2 :
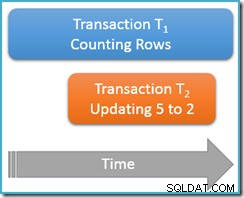
Transaction T1 recommence à compter les lignes, (dans l'ordre croissant) en rencontrant les lignes 1 et 3 en premier. Maintenant, la transaction T2 se glisse, change la valeur de la ligne 5 en 2 et valide :

J'ai montré la ligne mise à jour dans la même position qu'avant pour rendre le changement clair, mais l'index b-tree que nous scannons maintient les données dans un ordre logique, donc l'image réelle est plus proche de ceci :

Le fait est que la transaction T1 scanne simultanément cette même structure dans l'ordre vers l'avant, étant actuellement positionné juste après l'entrée pour la valeur 3. La requête de comptage continue à parcourir vers l'avant à partir de ce point, trouvant les lignes 4 et 7 (mais pas la ligne 5 bien sûr).
Pour résumer, la requête de comptage a vu les lignes 1, 3, 4 et 7 dans ce scénario. Il signale un nombre de quatre lignes – ce qui est étrange, car le tableau semble avoir contenu cinq lignes tout au long !
Une deuxième exécution de la requête de comptage dans la même transaction de lecture répétable rapporterait cinq rangées, pour les mêmes raisons que précédemment. Enfin, au cas où vous vous poseriez la question, les suppressions simultanées n'offrent pas la possibilité d'une anomalie basée sur un fantôme sous un isolement de lecture reproductible.
Réflexions finales
Les exemples précédents utilisaient tous deux des analyses par ordre croissant d'une structure d'index pour présenter une vue simple du type d'effets que les fantômes peuvent avoir sur une lecture répétable requête. Il est important de comprendre que ces illustrations ne dépendent pas de manière importante de la direction de balayage ou du fait qu'un index b-tree a été utilisé. Veuillez ne pas forment l'opinion que les scans commandés sont en quelque sorte responsables et donc à éviter !
Les mêmes effets de concurrence peuvent être observés avec une analyse par ordre décroissant d'une structure d'index, ou dans une variété d'autres scénarios d'accès aux données physiques. Le point général est que les phénomènes fantômes sont spécifiquement autorisés (mais pas obligatoires) par la norme SQL pour les transactions au niveau d'isolation de lecture répétable.
Toutes les transactions ne nécessitent pas la garantie d'isolation complète fournie par l'isolation sérialisable, et peu de systèmes pourraient tolérer les effets secondaires s'ils le faisaient. Néanmoins, il est utile d'avoir une bonne compréhension des garanties fournies par les différents niveaux d'isolement.
La prochaine fois
La partie suivante de cette série examine les garanties d'isolement encore plus faibles offertes par le niveau d'isolement par défaut de SQL Server, read commited .
[ Voir l'index pour toute la série ]