La stratégie d'indexation des tables est l'une des clés de réglage et d'optimisation des performances les plus importantes. Dans SQL Server, les index (index clusterisés et non clusterisés) sont créés à l'aide d'une structure B-tree, dans laquelle chaque page agit comme un nœud de liste à double liaison, contenant des informations sur les pages précédentes et suivantes. Cette structure B-tree, appelée Forward Scan, facilite la lecture des lignes de l'index en parcourant ou en recherchant ses pages du début à la fin. Bien que l'analyse en avant soit la méthode d'analyse d'index par défaut et largement connue, SQL Server nous offre la possibilité d'analyser les lignes d'index dans la structure B-tree de la fin au début. Cette capacité s'appelle le balayage arrière. Dans cet article, nous verrons comment cela se produit et quels sont les avantages et les inconvénients de la méthode d'analyse en arrière.
SQL Server nous offre la possibilité de lire les données de l'index de la table en parcourant les nœuds de la structure arborescente B de l'index du début à la fin à l'aide de la méthode Forward Scan, ou en lisant les nœuds de la structure arborescente B de la fin au début à l'aide de la méthode Méthode de balayage arrière. Comme son nom l'indique, l'analyse vers l'arrière est effectuée lors de la lecture opposée à l'ordre de la colonne incluse dans l'index, qui est effectuée avec l'option DESC dans l'instruction de tri ORDER BY T-SQL, qui spécifie la direction de l'opération d'analyse.
Dans des situations spécifiques, SQL Server Engine constate que la lecture des données d'index de la fin au début avec la méthode d'analyse vers l'arrière est plus rapide que la lecture dans son ordre normal avec la méthode d'analyse vers l'avant, qui peut nécessiter un processus de tri coûteux par le SQL. Moteur. Ces cas incluent l'utilisation de la fonction d'agrégation MAX() et les situations où le tri du résultat de la requête est opposé à l'ordre de l'index. Le principal inconvénient de la méthode d'analyse en arrière est que l'optimiseur de requête SQL Server choisira toujours de l'exécuter en utilisant l'exécution de plans en série, sans pouvoir tirer parti des plans d'exécution parallèles.
Supposons que nous ayons le tableau suivant qui contiendra des informations sur les employés de l'entreprise. La table peut être créée à l'aide de l'instruction CREATE TABLE T-SQL ci-dessous :
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Après avoir créé la table, nous la remplirons avec 10 000 enregistrements factices, à l'aide de l'instruction INSERT ci-dessous :
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Si nous exécutons l'instruction SELECT ci-dessous pour récupérer les données de la table précédemment créée, les lignes seront triées en fonction des valeurs de la colonne ID dans l'ordre croissant, c'est-à-dire le même que l'ordre de l'index cluster :
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
Ensuite, en vérifiant le plan d'exécution pour cette requête, une analyse sera effectuée sur l'index clusterisé pour obtenir les données triées de l'index, comme indiqué dans le plan d'exécution ci-dessous :
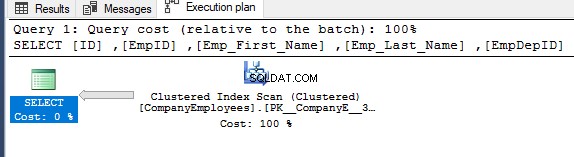
Pour obtenir la direction de l'analyse effectuée sur l'index clusterisé, cliquez avec le bouton droit sur le nœud d'analyse d'index pour parcourir les propriétés du nœud. À partir des propriétés du nœud Clustered Index Scan, la propriété Scan Direction affiche la direction de l'analyse effectuée sur l'index dans cette requête, qui est Forward Scan, comme indiqué dans l'instantané ci-dessous :

La direction d'analyse de l'index peut également être récupérée à partir du plan d'exécution XML à partir de la propriété ScanDirection sous le nœud IndexScan, comme indiqué ci-dessous :
Supposons que nous devions récupérer la valeur d'ID maximale de la table CompanyEmployees créée précédemment, à l'aide de la requête T-SQL ci-dessous :
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Passez ensuite en revue le plan d'exécution généré à partir de l'exécution de cette requête. Vous verrez qu'une analyse sera effectuée sur l'index clusterisé comme indiqué dans le plan d'exécution ci-dessous :
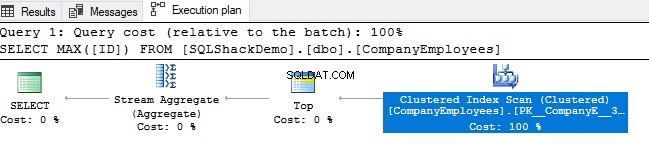
Pour vérifier le sens du parcours d'index, nous allons parcourir les propriétés du noeud Clustered Index Scan. Le résultat nous montrera que, le moteur SQL Server préfère parcourir l'index clusterisé de la fin au début, ce qui sera plus rapide dans ce cas, afin d'obtenir la valeur maximale de la colonne ID, du fait que le index est déjà trié en fonction de la colonne ID, comme indiqué ci-dessous :
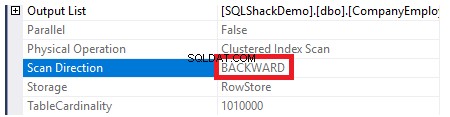
De plus, si nous essayons de récupérer les données de table précédemment créées à l'aide de l'instruction SELECT suivante, les enregistrements seront triés en fonction des valeurs de la colonne ID, mais cette fois, à l'opposé de l'ordre de l'index groupé, en spécifiant l'option de tri DESC dans ORDER Clause BY illustrée ci-dessous :
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
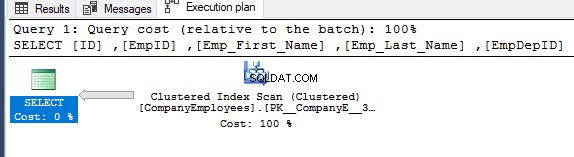
Si vous vérifiez le plan d'exécution généré après l'exécution de la requête SELECT précédente, vous verrez qu'un parcours sera effectué sur l'index clusterisé afin d'obtenir les enregistrements demandés de la table, comme indiqué ci-dessous :
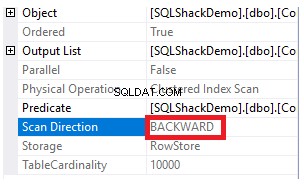
Les propriétés du nœud Clustered Index Scan indiqueront que la direction de l'analyse que le moteur SQL Server préfère prendre est la direction Backward Scan, qui est plus rapide dans ce cas, en raison du tri des données opposé au tri réel de l'index clusterisé, en tenant compte du fait que l'index est déjà trié par ordre croissant selon la colonne ID, comme indiqué ci-dessous :
Comparaison des performances
Supposons que nous ayons les instructions SELECT ci-dessous qui récupèrent des informations sur tous les employés qui ont été embauchés à partir de 2010, deux fois ; la première fois, le jeu de résultats renvoyé sera trié dans l'ordre croissant en fonction des valeurs de la colonne ID, et la deuxième fois, le jeu de résultats renvoyé sera trié dans l'ordre décroissant en fonction des valeurs de la colonne ID à l'aide des instructions T-SQL ci-dessous :
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
En vérifiant les plans d'exécution qui sont générés en exécutant les deux requêtes SELECT, le résultat montrera qu'un scan sera effectué sur l'index clusterisé dans les deux requêtes pour récupérer les données, mais la direction du scan dans la première requête sera Forward Scan en raison du tri des données ASC et Backward Scan dans la deuxième requête en raison de l'utilisation du tri des données DESC, pour remplacer la nécessité de réorganiser les données à nouveau, comme indiqué ci-dessous :
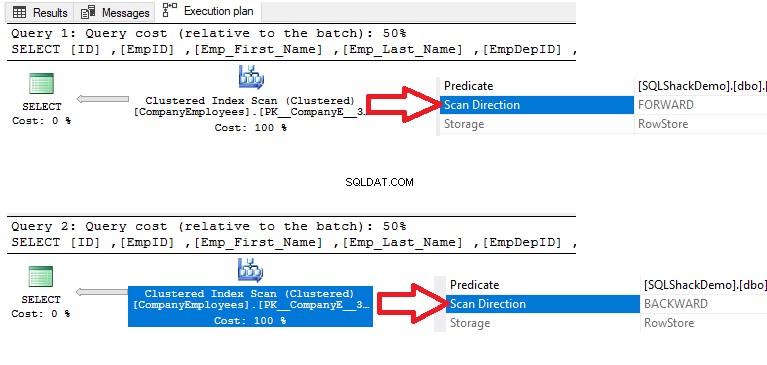
De plus, si nous vérifions les statistiques d'exécution IO et TIME des deux requêtes, nous verrons que les deux requêtes effectuent les mêmes opérations IO et consomment des valeurs proches de l'exécution et du temps CPU.
Ces valeurs nous montrent à quel point le moteur SQL Server est intelligent lorsqu'il s'agit de choisir la direction d'analyse d'index la plus appropriée et la plus rapide pour récupérer les données pour l'utilisateur, qui est l'analyse avant dans le premier cas et l'analyse arrière dans le second cas, comme le montrent les statistiques ci-dessous. :

Reprenons l'exemple MAX précédent. Supposons que nous devions récupérer l'ID maximum des employés qui ont été embauchés en 2010 et après. Pour cela, nous utiliserons les instructions SELECT suivantes qui trieront les données lues en fonction de la valeur de la colonne ID avec le tri ASC dans la première requête et avec le tri DESC dans la deuxième requête :
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Vous verrez à partir des plans d'exécution générés à partir de l'exécution des deux instructions SELECT, que les deux requêtes effectueront une opération d'analyse sur l'index clusterisé pour récupérer la valeur d'ID maximale, mais dans des directions d'analyse différentes ; Forward Scan dans la première requête et Backward Scan dans la deuxième requête, en raison des options de tri ASC et DESC, comme indiqué ci-dessous :
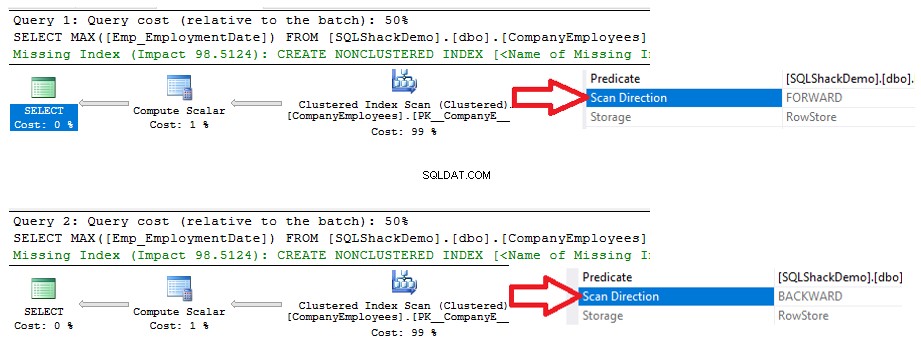
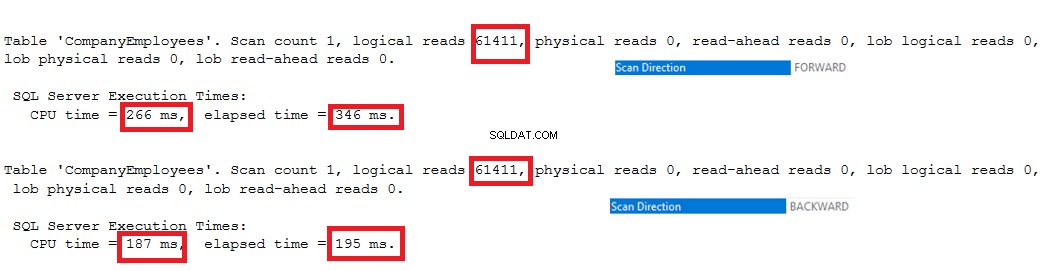
Les statistiques d'E/S générées par les deux requêtes ne montreront aucune différence entre les deux directions de balayage. Mais les statistiques TIME montrent une grande différence entre le calcul de l'ID maximum des lignes lorsque ces lignes sont analysées du début à la fin à l'aide de la méthode Forward Scan et l'analyse de la fin au début à l'aide de la méthode Backward Scan. Il ressort clairement du résultat ci-dessous que la méthode d'analyse en arrière est la méthode d'analyse optimale pour obtenir la valeur d'identification maximale :
Optimisation des performances
Comme je l'ai mentionné au début de cet article, l'indexation des requêtes est la clé la plus importante du processus de réglage et d'optimisation des performances. Dans la requête précédente, si nous organisons l'ajout d'un index non clusterisé sur la colonne EmploymentDate de la table CompanyEmployees, en utilisant l'instruction CREATE INDEX T-SQL ci-dessous :
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
En vérifiant les plans d'exécution générés après l'exécution des deux requêtes, vous verrez qu'une recherche sera effectuée sur l'index non cluster nouvellement créé, et les deux requêtes scanneront l'index du début à la fin en utilisant la méthode Forward Scan, sans la nécessité d'effectuer une analyse en arrière pour accélérer la récupération des données, bien que nous ayons utilisé l'option de tri DESC dans la deuxième requête. Cela s'est produit en raison de la recherche directe de l'index sans qu'il soit nécessaire d'effectuer une analyse complète de l'index, comme indiqué dans la comparaison des plans d'exécution ci-dessous :
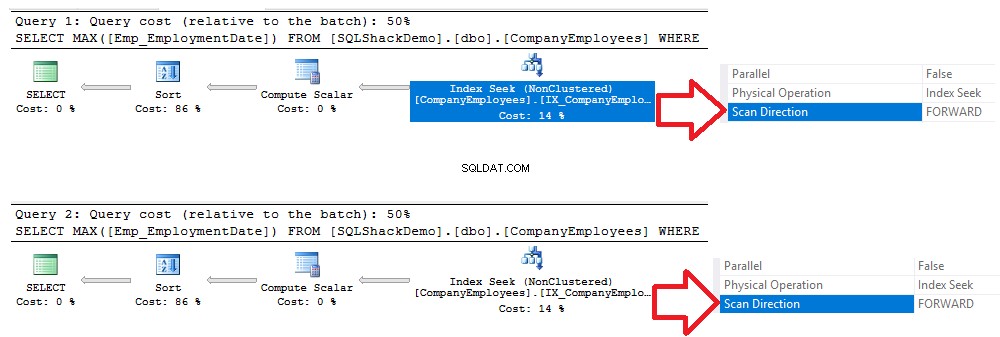
Le même résultat peut être dérivé des statistiques IO et TIME générées à partir des deux requêtes précédentes, où les deux requêtes consommeront la même quantité de temps d'exécution, d'opérations CPU et IO, avec une très petite différence, comme indiqué dans l'instantané des statistiques ci-dessous. :

Outil utile :
dbForge Index Manager - complément SSMS pratique pour analyser l'état des index SQL et résoudre les problèmes de fragmentation d'index.