La réplication est l'un des moyens les plus courants d'obtenir une haute disponibilité pour MySQL et MariaDB. Il est devenu beaucoup plus robuste avec l'ajout de GTID et est testé de manière approfondie par des milliers et des milliers d'utilisateurs. La réplication MySQL n'est pas une propriété "définir et oublier", elle doit être surveillée pour détecter les problèmes potentiels et entretenue afin qu'elle reste en bon état. Dans cet article de blog, nous aimerions partager quelques trucs et astuces sur la façon de maintenir, de dépanner et de résoudre les problèmes de réplication MySQL.
Comment déterminer si la réplication MySQL est en bon état ?
C'est sans conteste la compétence la plus importante que doit posséder toute personne prenant en charge une configuration de réplication MySQL. Voyons où chercher des informations sur l'état de la réplication. Il existe une légère différence entre MySQL et MariaDB et nous en discuterons également.
AFFICHER LE STATUT ESCLAVE
C'est sans conteste la méthode la plus courante pour vérifier l'état de la réplication sur un hôte esclave - c'est avec nous depuis toujours et c'est généralement le premier endroit où nous allons si nous pensons qu'il y a un problème avec la réplication.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Certains détails peuvent différer entre MySQL et MariaDB, mais la majorité du contenu sera identique. Les modifications seront visibles dans la section GTID car MySQL et MariaDB le font d'une manière différente. À partir de SHOW SLAVE STATUS, vous pouvez déduire certaines informations - quel maître est utilisé, quel utilisateur et quel port est utilisé pour se connecter au maître. Nous avons des données sur la position actuelle du journal binaire (ce n'est plus si important car nous pouvons utiliser GTID et oublier les binlogs) et l'état des threads de réplication SQL et I/O. Ensuite, vous pouvez voir si et comment le filtrage est configuré. Vous pouvez également trouver des informations sur les erreurs, le décalage de réplication, les paramètres SSL et le GTID. L'exemple ci-dessus provient d'un esclave MySQL 5.7 qui est dans un état sain. Examinons un exemple où la réplication est interrompue.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Cet exemple est tiré de MariaDB 10.1, vous pouvez voir les changements au bas de la sortie pour le faire fonctionner avec MariaDB GTID. Ce qui est important pour nous, c'est l'erreur - vous pouvez voir que quelque chose ne va pas dans le fil SQL :
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Nous discuterons de ce problème particulier plus tard, pour l'instant il suffit que vous voyiez comment vous pouvez vérifier s'il y a des erreurs dans la réplication en utilisant SHOW SLAVE STATUS.
Une autre information importante qui vient de SHOW SLAVE STATUS est - à quel point notre esclave est en retard. Vous pouvez le vérifier dans la colonne "Seconds_Behind_Master". Cette métrique est particulièrement importante à suivre si vous savez que votre application est sensible aux lectures obsolètes.
Dans ClusterControl, vous pouvez suivre ces données dans la section "Aperçu" :
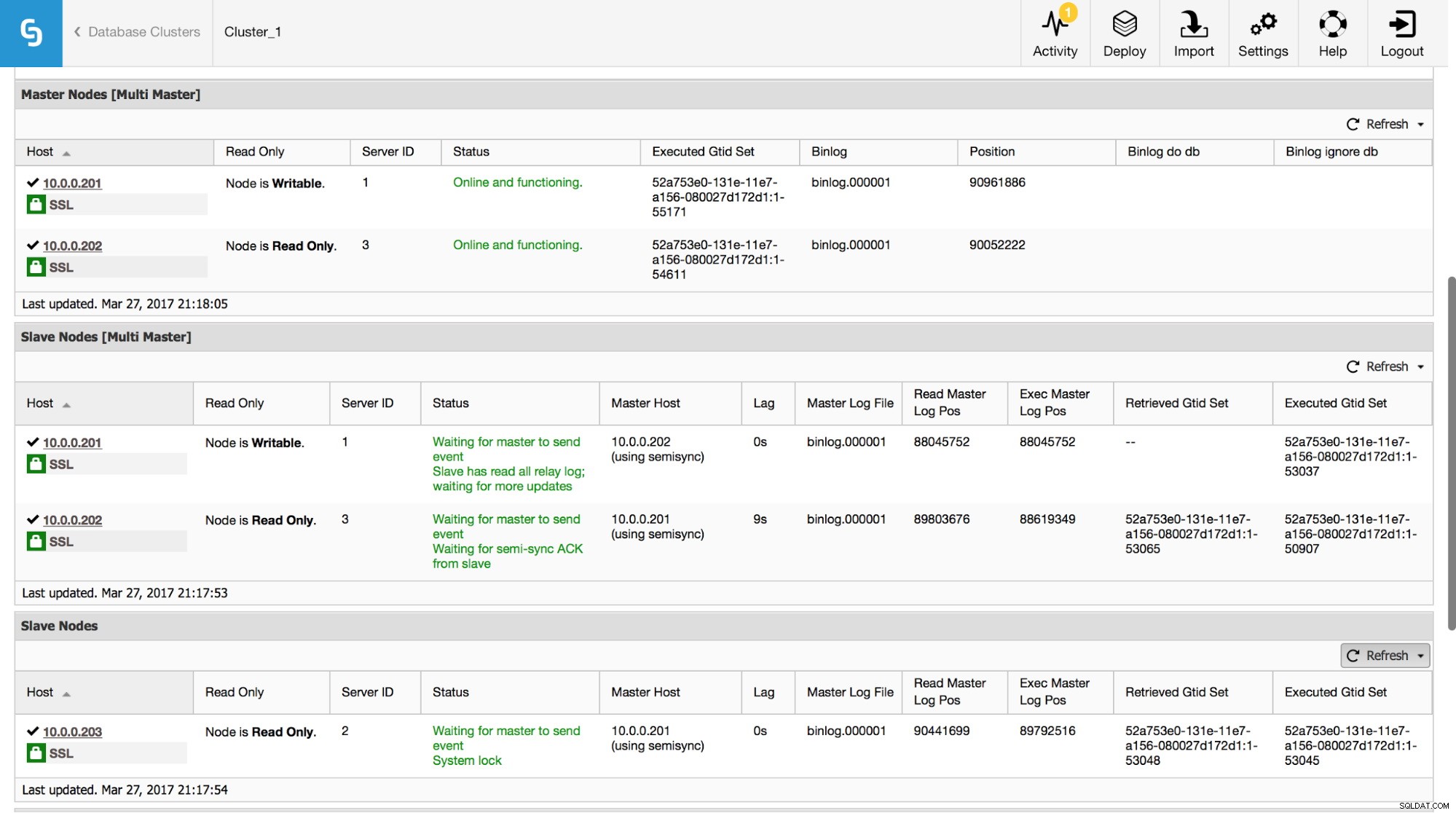
Nous avons rendu visibles toutes les informations les plus importantes de la commande SHOW SLAVE STATUS. Vous pouvez vérifier l'état de la réplication, qui est le maître, s'il y a un retard de réplication ou non, les positions du journal binaire. Vous pouvez également trouver les GTID récupérés et exécutés.
Schéma de performances
Un autre endroit où vous pouvez rechercher des informations sur la réplication est le performance_schema. Cela s'applique uniquement à MySQL 5.7 d'Oracle - les versions antérieures et MariaDB ne collectent pas ces données.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Vous trouverez ci-dessous quelques exemples de données disponibles dans certains de ces tableaux.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Comme vous pouvez le voir, nous pouvons vérifier l'état de la réplication, la dernière erreur, le jeu de transactions reçu et quelques autres données. Ce qui est important - si vous avez activé la réplication multithread, dans la table replication_applier_status_by_worker, vous verrez l'état de chaque travailleur - cela vous aide à comprendre l'état de la réplication pour chacun des threads de travail.
Délai de réplication
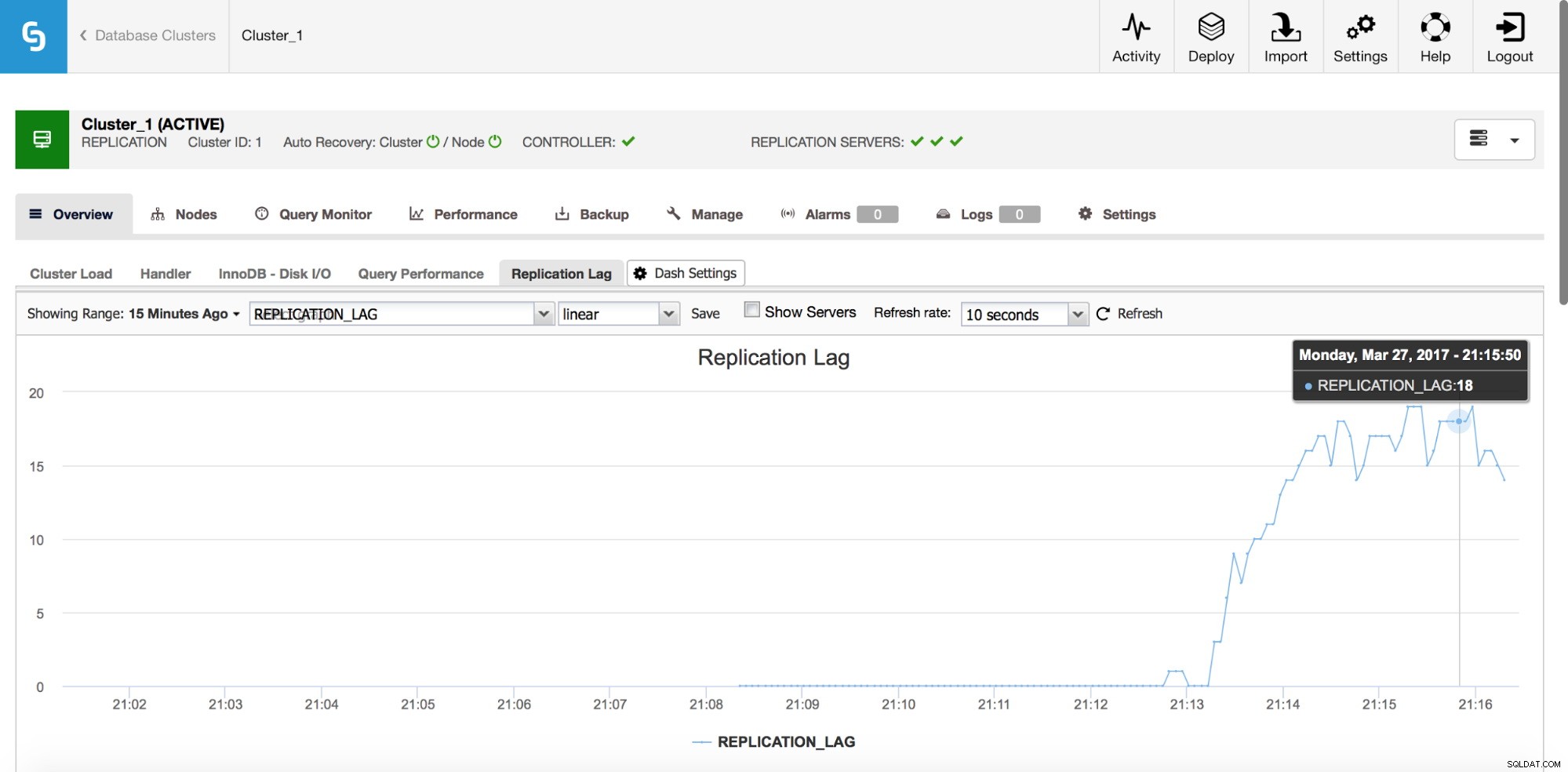
Le décalage est certainement l'un des problèmes les plus courants auxquels vous serez confronté lorsque vous travaillerez avec la réplication MySQL. Le retard de réplication apparaît lorsque l'un des esclaves est incapable de suivre le nombre d'opérations d'écriture effectuées par le maître. Les raisons peuvent être différentes - configuration matérielle différente, charge plus lourde sur l'esclave, degré élevé de parallélisation des écritures sur le maître qui doit être sérialisé (lorsque vous utilisez un seul thread pour la réplication) ou les écritures ne peuvent pas être parallélisées dans la même mesure qu'il a été sur le maître (lorsque vous utilisez la réplication multithread).
Comment le détecter ?
Il existe plusieurs méthodes pour détecter le retard de réplication. Tout d'abord, vous pouvez vérifier "Seconds_Behind_Master" dans la sortie SHOW SLAVE STATUS - il vous dira si l'esclave est en retard ou non. Cela fonctionne bien dans la plupart des cas, mais dans des topologies plus complexes, lorsque vous utilisez des maîtres intermédiaires, sur des hôtes quelque part en bas de la chaîne de réplication, cela peut ne pas être précis. Une autre solution, meilleure, consiste à s'appuyer sur des outils externes comme pt-heartbeat. L'idée est simple - un tableau est créé avec, entre autres, une colonne d'horodatage. Cette colonne est mise à jour sur le maître à intervalles réguliers. Sur un esclave, vous pouvez alors comparer l'horodatage de cette colonne avec l'heure actuelle - il vous dira à quelle distance se trouve l'esclave.
Quelle que soit la façon dont vous calculez le décalage, assurez-vous que vos hôtes sont synchronisés dans le temps. Utilisez ntpd ou d'autres moyens de synchronisation temporelle - s'il y a une dérive temporelle, vous verrez un "faux" décalage sur vos esclaves.
Comment réduire le décalage ?
Ce n'est pas une question facile à répondre. En bref, cela dépend de ce qui cause le décalage et de ce qui est devenu un goulot d'étranglement. Il existe deux modèles typiques - l'esclave est lié aux E/S, ce qui signifie que son sous-système d'E/S ne peut pas gérer la quantité d'opérations d'écriture et de lecture. Deuxièmement - l'esclave est lié au CPU, ce qui signifie que le thread de réplication utilise tout le CPU qu'il peut (un thread ne peut utiliser qu'un seul cœur de CPU) et ce n'est toujours pas suffisant pour gérer toutes les opérations d'écriture.
Lorsque le processeur est un goulot d'étranglement, la solution peut être aussi simple que d'utiliser la réplication multithread. Augmentez le nombre de threads de travail pour permettre une parallélisation plus élevée. Ce n'est pas toujours possible cependant - dans ce cas, vous voudrez peut-être jouer un peu avec les variables de commit de groupe (pour MySQL et MariaDB) pour retarder les commits pendant une légère période de temps (nous parlons ici de millisecondes) et, de cette façon , augmentez la parallélisation des commits.
Si le problème se situe dans les E/S, le problème est un peu plus difficile à résoudre. Bien sûr, vous devriez revoir vos paramètres d'E/S InnoDB - il y a peut-être de la place pour des améliorations. Si le réglage my.cnf ne vous aide pas, vous n'avez pas trop d'options :améliorez vos requêtes (dans la mesure du possible) ou mettez à niveau votre sous-système d'E/S vers quelque chose de plus performant.
La plupart des proxys (par exemple, tous les proxys pouvant être déployés à partir de ClusterControl :ProxySQL, HAProxy et MaxScale) vous offrent la possibilité de supprimer un esclave de la rotation si le délai de réplication dépasse un seuil prédéfini. Ce n'est en aucun cas une méthode pour réduire le décalage, mais cela peut être utile pour éviter les lectures obsolètes et, comme effet secondaire, pour réduire la charge sur un esclave, ce qui devrait l'aider à rattraper son retard.
Bien sûr, le réglage des requêtes peut être une solution dans les deux cas :il est toujours bon d'améliorer les requêtes qui sont gourmandes en CPU ou en E/S.
Transactions erronées
Les transactions errantes sont des transactions qui ont été exécutées sur un esclave uniquement, pas sur le maître. Bref, ils font un esclave incompatible avec le maître. Lors de l'utilisation de la réplication basée sur GTID, cela peut entraîner de graves problèmes si l'esclave est promu au rang de maître. Nous avons un article détaillé sur ce sujet et nous vous encourageons à l'examiner et à vous familiariser avec la façon de détecter et de résoudre les problèmes liés aux transactions errantes. Nous y avons également inclus des informations sur la façon dont ClusterControl détecte et gère les transactions errantes.
Pas de fichier Binlog sur le maître
Comment identifier le problème ?
Dans certaines circonstances, il peut arriver qu'un esclave se connecte à un maître et demande un fichier journal binaire inexistant. Une raison à cela pourrait être la transaction errante - à un moment donné, une transaction a été exécutée sur un esclave et plus tard cet esclave devient un maître. D'autres hôtes, qui sont configurés pour asservir ce maître, demanderont cette transaction manquante. S'il a été exécuté il y a longtemps, il est possible que les fichiers journaux binaires aient déjà été purgés.
Autre exemple, plus typique :vous souhaitez provisionner un esclave à l'aide de xtrabackup. Vous copiez la sauvegarde sur un hôte, appliquez le journal, modifiez le propriétaire du répertoire de données MySQL - opérations typiques que vous effectuez pour restaurer une sauvegarde. Vous exécutez
SET GLOBAL gtid_purged=basé sur les données de xtrabackup_binlog_info et vous exécutez CHANGE MASTER TO … MASTER_AUTO_POSITION=1 (c'est dans MySQL, MariaDB a un processus légèrement différent), démarrez l'esclave et vous vous retrouvez avec une erreur comme :
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'dans MySQL ou :
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'dans MariaDB.
Cela signifie essentiellement que le maître ne dispose pas de tous les journaux binaires nécessaires pour exécuter toutes les transactions manquantes. Très probablement, la sauvegarde est trop ancienne et le maître a déjà purgé certains des journaux binaires créés entre le moment où la sauvegarde a été créée et le moment où l'esclave a été provisionné.
Comment résoudre ce problème ?
Malheureusement, vous ne pouvez pas faire grand-chose dans ce cas particulier. Si vous avez des hôtes MySQL qui stockent les journaux binaires plus longtemps que le maître, vous pouvez essayer d'utiliser ces journaux pour rejouer les transactions manquantes sur l'esclave. Voyons comment cela peut être fait.
Tout d'abord, examinons le plus ancien GTID dans les journaux binaires du maître :
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)Ainsi, 'binlog.000021' est le dernier (et le seul) fichier. Vérifions quelle est la première entrée GTID dans ce fichier :
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Comme nous pouvons le voir, la plus ancienne entrée de journal binaire disponible est :5d1e2227-07c6-11e7-8123-080027495a77:1106669
Nous devons également vérifier quel est le dernier GTID couvert par la sauvegarde :
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Il s'agit de :5d1e2227-07c6-11e7-8123-080027495a77:1-1106666, il nous manque donc deux événements :
5d1e2227-07c6-11e7-8123-080027495a77:1106667-1106668
Voyons si nous pouvons trouver ces transactions sur d'autres esclaves.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Il semble que 'binlog.000003' soit le dernier journal binaire. Nous devons vérifier si nos GTID manquants s'y trouvent :
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;N'oubliez pas que vous souhaiterez peut-être copier les fichiers binlog en dehors du serveur de production, car leur traitement peut ajouter de la charge. Comme nous avons vérifié que ces GTID existent, nous pouvons les extraire :
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlAprès un scp rapide, nous pouvons appliquer ces événements sur l'esclave
slave1:~# mysql -ppass < to_apply_on_slave1.sqlUne fois cela fait, nous pouvons vérifier si ces GTID ont été appliqués en examinant la sortie de SHOW SLAVE STATUS :
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set semble bon, nous pouvons donc démarrer des threads esclaves :
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Vérifions si cela a bien fonctionné. Nous utiliserons à nouveau la sortie SHOW SLAVE STATUS :
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Ça a l'air bien, c'est opérationnel !
Une autre méthode pour résoudre ce problème consistera à effectuer une sauvegarde une fois de plus et à approvisionner à nouveau l'esclave, en utilisant de nouvelles données. Ce sera très probablement plus rapide et certainement plus fiable. Ce n'est pas souvent que vous avez des politiques de purge binlog différentes sur le maître et sur les esclaves)
Nous continuerons à discuter d'autres types de problèmes de réplication dans le prochain article de blog.