Une grande partie du code T-SQL de production est écrit avec l'hypothèse implicite que les données sous-jacentes ne changeront pas pendant l'exécution. Comme nous l'avons vu dans l'article précédent de cette série, il s'agit d'une hypothèse peu sûre car les données et les entrées d'index peuvent se déplacer sous nous, même pendant l'exécution d'une seule instruction.
Lorsque le programmeur T-SQL est conscient des types de problèmes d'exactitude et d'intégrité des données qui peuvent survenir en raison de modifications de données simultanées par d'autres processus, la solution la plus couramment proposée consiste à encapsuler les instructions vulnérables dans une transaction. Il n'est pas clair comment le même type de raisonnement serait appliqué au cas d'instruction unique, qui est déjà enveloppé dans une transaction de validation automatique par défaut.
Laissant cela de côté une seconde, l'idée de protéger une zone importante du code T-SQL avec une transaction semble être basée sur une mauvaise compréhension des protections offertes par les propriétés de transaction ACID. L'élément important de cet acronyme pour la présente discussion est l'isolement biens. L'idée est que l'utilisation d'une transaction fournit automatiquement une isolation complète des effets d'autres activités simultanées.
La vérité est que les transactions inférieures à SERIALIZABLE fournir uniquement un diplôme d'isolation, qui dépend du niveau d'isolation de transaction actuellement effectif. Pour comprendre ce que tout cela signifie pour notre quotidien T Pratiques de codage SQL, nous allons d'abord examiner en détail le niveau d'isolement sérialisable.
Isolation sérialisable
Serializable est le plus isolé des niveaux d'isolement de transaction standard. C'est aussi la valeur par défaut niveau d'isolement spécifié par la norme SQL, bien que SQL Server (comme la plupart des systèmes de bases de données commerciaux) diffère de la norme à cet égard. Le niveau d'isolement par défaut dans SQL Server est la lecture validée, un niveau d'isolement inférieur que nous explorerons plus tard dans la série.
La définition du niveau d'isolement sérialisable dans la norme SQL-92 contient le texte suivant (c'est moi qui souligne) :
Une exécution sérialisable est définie comme une exécution des opérations d'exécution simultanée de transactions SQL qui produit le même effet qu'une exécution en série de ces mêmes transactions SQL. Une exécution en série est une exécution dans laquelle chaque transaction SQL s'exécute jusqu'à la fin avant que la prochaine transaction SQL ne commence.
Il y a une distinction importante à faire ici entre vraiment sérialisé exécution (où chaque transaction s'exécute en fait exclusivement jusqu'à la fin avant que la suivante ne démarre) et sérialisable l'isolement, où les transactions doivent seulement avoir les mêmes effets comme si ils ont été exécutés en série (dans un ordre non spécifié).
En d'autres termes, un véritable système de base de données est autorisé à se chevaucher physiquement l'exécution de transactions sérialisables dans le temps (augmentant ainsi la simultanéité) tant que les effets de ces transactions correspondent toujours à un ordre possible d'exécution en série. En d'autres termes, les transactions sérialisables sont potentiellement sérialisables plutôt que d'être réellement sérialisé .
Transactions logiquement sérialisables
Laissez de côté toutes les considérations physiques (comme le verrouillage) pour un moment et ne pensez qu'au traitement logique de deux transactions sérialisables simultanées.
Considérez une table qui contient un grand nombre de lignes, dont cinq satisfont un prédicat de requête intéressant. Une transaction sérialisable T1 commence à compter le nombre de lignes de la table qui correspondent à ce prédicat. Quelque temps après T1 commence, mais avant de s'engager, une seconde transaction sérialisable T2 départs. Opération T2 ajoute quatre nouvelles lignes qui satisfont également le prédicat de requête à la table, et valide. Le diagramme ci-dessous montre la séquence temporelle des événements :

La question est, combien de lignes la requête doit-elle avoir dans la transaction sérialisable T1 compte ? N'oubliez pas que nous pensons ici uniquement aux exigences logiques, évitez donc de penser aux verrous qui pourraient être pris, etc.
Les deux transactions se chevauchent physiquement dans le temps, ce qui est bien. L'isolation sérialisable nécessite seulement que les résultats de ces deux transactions correspondent à une éventuelle exécution en série. Il existe clairement deux possibilités pour un calendrier logique en série des transactions T1 et T2 :
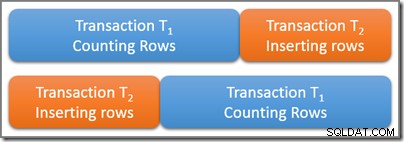
Utilisation du premier programme de série possible (T1 puis T2 ) le T1 la requête de comptage verrait cinq lignes , car la deuxième transaction ne démarre pas tant que la première n'est pas terminée. En utilisant le deuxième horaire logique possible, le T1 la requête compterait neuf lignes , car l'insertion de quatre lignes s'est terminée logiquement avant le début de la transaction de comptage.
Les deux réponses sont logiquement correctes sous isolement sérialisable. De plus, aucune autre réponse n'est possible (donc la transaction T1 ne pouvait pas compter sept lignes, par exemple). Lequel des deux résultats possibles est réellement observé dépend d'un timing précis et d'un certain nombre de détails de mise en œuvre spécifiques au moteur de base de données utilisé.
Notez que nous ne concluons pas que les transactions sont en fait réorganisées dans le temps. L'exécution physique est libre de se chevaucher comme indiqué dans le premier diagramme, tant que le moteur de base de données garantit que les résultats reflètent ce qui se serait passé s'ils avaient été exécutés dans l'une des deux séquences en série possibles.
Sérialisable et les phénomènes de concurrence
En plus de la sérialisation logique, la norme SQL mentionne également qu'une transaction fonctionnant au niveau d'isolement sérialisable ne doit pas subir certains phénomènes de concurrence. Il ne doit pas lire de données non validées (pas de lectures erronées ); et une fois que les données ont été lues, une répétition de la même opération doit renvoyer exactement le même ensemble de données (lectures répétables sans fantômes ).
La norme tient à dire que ces phénomènes de concurrence sont exclus au niveau de l'isolement sérialisable en tant que conséquence directe d'exiger que la transaction soit logiquement sérialisable. En d'autres termes, l'exigence de sérialisabilité est suffisante à elle seule pour éviter les phénomènes de lecture sale, de lecture non répétable et de simultanéité fantôme. En revanche, éviter à lui seul les trois phénomènes de concurrence n'est pas suffisant pour garantir la sérialisabilité, comme nous le verrons bientôt.
Intuitivement, les transactions sérialisables évitent tous les phénomènes liés à la concurrence car elles doivent agir comme si elles s'étaient exécutées de manière totalement isolée. En ce sens, le niveau d'isolement des transactions sérialisables correspond assez étroitement aux attentes courantes des programmeurs T-SQL.
Implémentations sérialisables
Il se trouve que SQL Server utilise une implémentation de verrouillage du niveau d'isolement sérialisable, où les verrous physiques sont acquis et conservés à la fin de la transaction (d'où l'indicateur de table obsolète HOLDLOCK comme synonyme de SERIALIZABLE ).
Cette stratégie n'est pas tout à fait suffisante pour fournir une garantie technique de sérialisabilité totale, car des données nouvelles ou modifiées peuvent apparaître dans une plage de lignes précédemment traitées par la transaction. Ce phénomène de simultanéité est connu sous le nom de fantôme et peut entraîner des effets qui n'auraient pu se produire dans aucun programme en série.
Pour assurer la protection contre le phénomène de concurrence fantôme, les verrous pris par SQL Server au niveau d'isolation sérialisable peuvent également incorporer le verrouillage de plage de clés pour empêcher l'apparition de lignes nouvelles ou modifiées entre les valeurs de clé d'index précédemment examinées. Les verrous de plage ne sont pas toujours acquis sous le niveau d'isolement sérialisable ; tout ce que nous pouvons dire en général, c'est que SQL Server acquiert toujours suffisamment de verrous pour répondre aux exigences logiques du niveau d'isolement sérialisable. En fait, les implémentations de verrouillage acquièrent assez souvent des verrous plus nombreux et plus stricts que ce qui est réellement nécessaire pour garantir la sérialisabilité, mais je m'éloigne du sujet.
Le verrouillage n'est qu'une des implémentations physiques possibles du niveau d'isolement sérialisable. Nous devons veiller à séparer mentalement les comportements spécifiques de l'implémentation du verrouillage SQL Server de la définition logique de sérialisable.
À titre d'exemple de stratégie physique alternative, consultez l'implémentation PostgreSQL de l'isolement d'instantané sérialisable, bien qu'il ne s'agisse que d'une alternative. Chaque implémentation physique différente a bien sûr ses propres forces et faiblesses. En passant, notez qu'Oracle ne fournit toujours pas d'implémentation entièrement conforme du niveau d'isolement sérialisable. Il a un niveau d'isolement nommé sérialisable, mais cela ne garantit pas vraiment que les transactions s'exécuteront selon un calendrier en série possible. Oracle fournit à la place l'isolation des instantanés lorsque sérialisable est demandé, de la même manière que PostgreSQL l'a fait avant l'isolement d'instantané sérialisable (SSI ) a été implémenté.
L'isolement d'instantané n'empêche pas les anomalies de concurrence telles que le décalage d'écriture, ce qui n'est pas possible dans le cadre d'un isolement véritablement sérialisable. Si vous êtes intéressé, vous pouvez trouver des exemples de décalage d'écriture et d'autres effets de simultanéité autorisés par l'isolement d'instantané sur le lien SSI ci-dessus. Nous discuterons également de l'implémentation SQL Server du niveau d'isolement d'instantané plus tard dans la série.
Une vue ponctuelle ?
L'une des raisons pour lesquelles j'ai passé du temps à parler des différences entre la sérialisabilité logique et l'exécution physiquement sérialisée est qu'il est autrement facile de déduire des garanties qui pourraient ne pas exister réellement. Par exemple, si vous considérez les transactions sérialisables comme en fait s'exécutant l'une après l'autre, vous pourriez en déduire qu'une transaction sérialisable verra nécessairement la base de données telle qu'elle existait au début de la transaction, fournissant une vue ponctuelle.
En fait, il s'agit d'un détail spécifique à l'implémentation. Rappelez-vous l'exemple précédent, où la transaction sérialisable T1 pouvait légitimement compter cinq ou neuf rangées. Si un nombre de neuf est renvoyé, la première transaction voit clairement les lignes qui n'existaient pas au moment où la transaction a commencé. Ce résultat est possible dans SQL Server mais pas dans PostgreSQL SSI, bien que les deux implémentations respectent les comportements logiques spécifiés pour le niveau d'isolement sérialisable.
Dans SQL Server, les transactions sérialisables ne voient pas nécessairement les données telles qu'elles existaient au début de la transaction. Au contraire, les détails de l'implémentation de SQL Server signifient qu'une transaction sérialisable voit les dernières données validées, à partir du moment où les données ont été verrouillées pour l'accès. De plus, l'ensemble des dernières données validées finalement lues est garanti de ne pas changer d'appartenance avant la fin de la transaction.
La prochaine fois
La partie suivante de cette série examine le niveau d'isolation de lecture reproductible, qui fournit des garanties d'isolation de transaction plus faibles que sérialisable.
[ Voir l'index pour toute la série ]