Lorsque les utilisateurs demandent des données à un système, ils aiment généralement les voir dans un ordre spécifique… même lorsqu'ils renvoient des milliers de lignes. Comme de nombreux administrateurs de base de données et développeurs le savent, ORDER BY peut introduire des ravages dans un plan de requête, car il nécessite le tri des données. Cela peut parfois nécessiter un opérateur SORT dans le cadre de l'exécution de la requête, ce qui peut être une opération coûteuse, en particulier si les estimations sont erronées et qu'elles se répandent sur le disque. Dans un monde idéal, les données sont déjà triées grâce à un index (les index et les tris sont très complémentaires). Nous parlons souvent de créer un index de couverture pour satisfaire une requête, afin que l'optimiseur n'ait pas à revenir à la table de base ou à l'index clusterisé pour obtenir des colonnes supplémentaires. Et vous avez peut-être entendu des gens dire que l'ordre des colonnes dans l'index est important. Avez-vous déjà réfléchi à la façon dont cela affecte vos opérations SORT ?
Examiner ORDER BY et les tris
Nous allons commencer avec une nouvelle copie de la base de données AdventureWorks2014 sur une instance SQL Server 2014 (version 12.0.2000). Si nous exécutons une simple requête SELECT sur Sales.SalesOrderHeader sans ORDER BY, nous voyons une simple analyse d'index clusterisée (à l'aide de SQL Sentry Plan Explorer) :
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Requête sans ORDER BY, analyse d'index cluster
Requête sans ORDER BY, analyse d'index cluster
Ajoutons maintenant un ORDER BY pour voir comment le plan change :
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
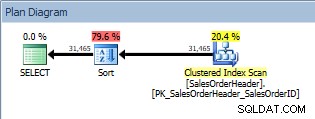 Requête avec un ORDER BY, un parcours d'index clusterisé et un tri
Requête avec un ORDER BY, un parcours d'index clusterisé et un tri
En plus du Clustered Index Scan, nous avons maintenant un Sort introduit par l'optimiseur, et son coût estimé est significativement plus élevé que celui du scan. Maintenant, le coût estimé est juste estimé, et nous ne pouvons pas dire avec une certitude absolue ici que le tri a pris 79,6 % du coût de la requête. Pour vraiment comprendre à quel point le tri est coûteux, nous devrions également examiner les STATISTIQUES IO, ce qui dépasse l'objectif d'aujourd'hui.
Maintenant, s'il s'agissait d'une requête fréquemment exécutée dans votre environnement, vous envisageriez probablement d'ajouter un index pour la prendre en charge. Dans ce cas, il n'y a pas de clause WHERE, nous récupérons simplement quatre colonnes et les classons par l'une d'entre elles. Une première tentative logique d'indexation serait :
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Nous allons réexécuter notre requête après avoir ajouté l'index qui contient toutes les colonnes souhaitées, et rappelez-vous que l'index a fait le travail pour trier les données. Nous voyons maintenant une analyse d'index par rapport à notre nouvel index non cluster :
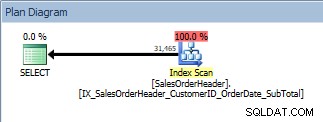 Requête avec ORDER BY, le nouvel index non clusterisé est analysé
Requête avec ORDER BY, le nouvel index non clusterisé est analysé
C'est une bonne nouvelle. Mais que se passe-t-il si quelqu'un modifie cette requête, soit parce que les utilisateurs peuvent spécifier les colonnes qu'ils souhaitent trier, soit parce qu'un changement a été demandé à un développeur ? Par exemple, les utilisateurs souhaitent peut-être voir les CustomerIDs et SalesOrderIDs dans l'ordre décroissant :
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
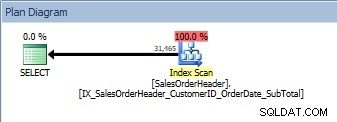 Requête avec deux colonnes dans ORDER BY, le nouvel index non clusterisé est analysé
Requête avec deux colonnes dans ORDER BY, le nouvel index non clusterisé est analysé
Nous avons le même plan; aucun opérateur de tri n'a été ajouté. Si nous examinons l'index à l'aide du sp_helpindex de Kimberly Tripp (certaines colonnes se sont réduites pour économiser de l'espace), nous pouvons comprendre pourquoi le plan n'a pas changé :
 Sortie de sp_helpindex
Sortie de sp_helpindex
La colonne clé de l'index est CustomerID, mais puisque SalesOrderID est la colonne clé de l'index clusterisé, elle fait également partie de la clé d'index, ainsi les données sont triées par CustomerID, puis SalesOrderID. La requête demandait les données triées par ces deux colonnes, par ordre décroissant. L'index a été créé avec les deux colonnes ascendantes, mais comme il s'agit d'une liste à double liaison, l'index peut être lu à l'envers. Vous pouvez le voir dans le volet Propriétés de Management Studio pour l'opérateur d'analyse d'index non cluster :
 Volet Propriétés de l'analyse de l'index non clusterisé, indiquant qu'il était inversé
Volet Propriétés de l'analyse de l'index non clusterisé, indiquant qu'il était inversé
Génial, aucun problème avec cette requête... mais qu'en est-il de celle-ci :
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
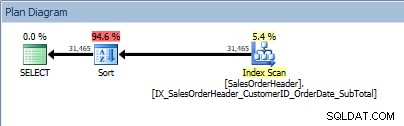 Requête avec deux colonnes dans ORDER BY, et un tri est ajouté
Requête avec deux colonnes dans ORDER BY, et un tri est ajouté
Notre opérateur SORT réapparaît, car les données issues de l'index ne sont pas triées dans l'ordre demandé. Nous verrons le même comportement si nous trions sur l'une des colonnes incluses :
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
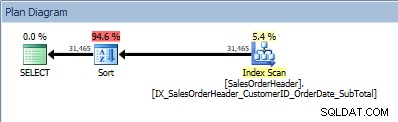 Requête avec deux colonnes dans ORDER BY, et un tri est ajouté
Requête avec deux colonnes dans ORDER BY, et un tri est ajouté
Que se passe-t-il si nous ajoutons (enfin) un prédicat et modifions légèrement ORDER BY ?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
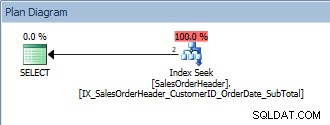 Requête avec un seul prédicat et un ORDER BY
Requête avec un seul prédicat et un ORDER BY
Cette requête est correcte car encore une fois, SalesOrderID fait partie de la clé d'index. Pour ce CustomerID, les données sont déjà triées par SalesOrderID. Que se passe-t-il si nous recherchons une plage de CustomerIDs, triés par SalesOrderID ?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
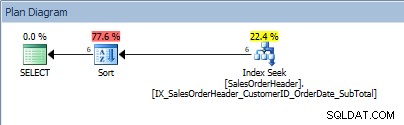 Requête avec une plage de valeurs dans le prédicat et un ORDER BY
Requête avec une plage de valeurs dans le prédicat et un ORDER BY
Rats, notre SORT est de retour. Le fait que les données soient triées par CustomerID aide uniquement à rechercher l'index pour trouver cette plage de valeurs ; pour le ORDER BY SalesOrderID, l'optimiseur doit insérer le Sort pour mettre les données dans l'ordre demandé.
Maintenant, à ce stade, vous vous demandez peut-être pourquoi je suis obsédé par l'opérateur de tri apparaissant dans les plans de requête. C'est parce que c'est cher. Cela peut être coûteux en termes de ressources (mémoire, IO) et/ou de durée.
La durée de la requête peut être affectée par un tri, car il s'agit d'une opération discontinue. L'ensemble des données doit être trié avant que l'opération suivante du plan puisse se produire. Si seules quelques lignes de données doivent être ordonnées, ce n'est pas si grave. S'il s'agit de milliers ou de millions de lignes ? Maintenant, nous attendons.
En plus de la durée globale des requêtes, nous devons également penser à l'utilisation des ressources. Prenons les 31 465 lignes avec lesquelles nous avons travaillé et poussons-les dans une variable de table, puis exécutons cette requête initiale avec ORDER BY sur CustomerID :
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
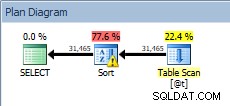 Requête sur la variable table, avec le tri
Requête sur la variable table, avec le tri
Notre SORT est de retour, et cette fois il a un avertissement (notez le triangle jaune avec le point d'exclamation). Les avertissements ne sont pas bons. Si nous regardons les propriétés du tri, nous pouvons voir l'avertissement "L'opérateur a utilisé tempdb pour répandre les données lors de l'exécution avec le niveau de déversement 1":
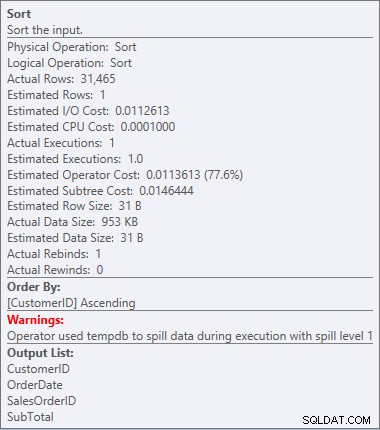 Avertissement de tri
Avertissement de tri
Ce n'est pas quelque chose que je veux voir dans un plan. L'optimiseur a fait une estimation de l'espace mémoire dont il aurait besoin pour trier les données, et il a demandé cette mémoire. Mais lorsqu'il a eu toutes les données et qu'il est allé les trier, le moteur s'est rendu compte qu'il n'y avait pas assez de mémoire (l'optimiseur en demandait trop peu !), alors l'opération de tri a débordé. Dans certains cas, cela peut se répandre sur le disque, ce qui signifie des lectures et des écritures - qui sont lentes. Non seulement nous attendons juste pour mettre les données en ordre, mais c'est encore plus lent car nous ne pouvons pas tout faire en mémoire. Pourquoi l'optimiseur n'a-t-il pas demandé suffisamment de mémoire ? Il avait une mauvaise estimation des données à trier :
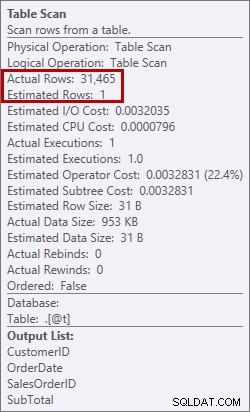 Estimation de 1 ligne contre 31 465 lignes réelles
Estimation de 1 ligne contre 31 465 lignes réelles
Dans ce cas, j'ai forcé une mauvaise estimation en utilisant une variable de table. Il existe des problèmes connus avec les estimations de statistiques et les variables de table (Aaron Bertrand a un excellent article sur les options pour essayer de résoudre ce problème), et ici, l'optimiseur pensait qu'une seule ligne allait être renvoyée à partir de l'analyse de la table, et non 31 465.
Options
Alors, que pouvez-vous faire, en tant que DBA ou développeur, pour éviter les SORT dans vos plans de requête ? La réponse rapide est :« Ne commandez pas vos données. Mais ce n'est pas toujours réaliste. Dans certains cas, vous pouvez décharger ce tri sur le client ou sur une couche d'application - mais les utilisateurs doivent encore attendre pour trier les données à ce couche. Dans les situations où vous ne pouvez pas modifier le fonctionnement de l'application, vous pouvez commencer par consulter vos index.
Si vous prenez en charge une application qui permet aux utilisateurs d'exécuter des requêtes ad hoc, ou de modifier l'ordre de tri afin qu'ils puissent voir les données triées comme ils le souhaitent... vous allez avoir le plus de mal (mais ce n'est pas une cause perdue donc n'arrêtez pas encore de lire !). Vous ne pouvez pas indexer pour chaque option. C'est inefficace et vous créerez plus de problèmes que vous n'en résoudrez. Votre meilleur pari ici est de parler aux utilisateurs (je sais, parfois c'est effrayant de quitter votre coin de bois, mais essayez-le). Pour les requêtes que les utilisateurs exécutent le plus souvent, découvrez comment ils aiment généralement voir les données. Oui, vous pouvez également l'obtenir à partir du cache du plan - vous pouvez récupérer des requêtes et des plans jusqu'à ce que vous en ayez envie pour voir ce qu'ils font. Mais c'est plus rapide de parler aux utilisateurs. L'avantage supplémentaire est que vous pouvez expliquer pourquoi vous demandez, et pourquoi cette idée de "trier sur toutes les colonnes parce que je peux" n'est pas si bonne. Savoir est la moitié de la bataille. Si vous pouvez passer du temps à éduquer vos utilisateurs expérimentés et les utilisateurs qui forment de nouvelles personnes, vous pourrez peut-être faire du bien.
Si vous prenez en charge une application avec des options ORDER BY limitées, vous pouvez effectuer une véritable analyse. Passez en revue les variantes ORDER BY existantes, déterminez les combinaisons qui sont exécutées le plus souvent et indexez pour prendre en charge ces requêtes. Vous ne toucherez probablement pas tout le monde, mais vous pouvez toujours avoir un impact. Vous pouvez aller plus loin en discutant avec vos développeurs et en les renseignant sur le problème et sur la manière de le résoudre.
Enfin, lorsque vous examinez des plans de requête avec des opérations SORT, ne vous concentrez pas uniquement sur la suppression du tri. Regardez où le tri se produit dans le plan. Si cela se produit bien à gauche du plan, et est généralement quelques lignes, il peut y avoir d'autres domaines avec un facteur d'amélioration plus important sur lesquels se concentrer. Le tri à gauche est le modèle sur lequel nous nous sommes concentrés aujourd'hui, mais un tri ne se produit pas toujours à cause d'un ORDER BY. Si vous voyez un tri à l'extrême droite du plan et que de nombreuses lignes se déplacent dans cette partie du plan, vous savez que vous avez trouvé un bon endroit pour commencer le réglage.