Mysqldump est l'outil de sauvegarde logique le plus populaire pour MySQL. Il est inclus dans la distribution MySQL, il est donc prêt à être utilisé sur toutes les instances MySQL.
Les sauvegardes logiques ne sont cependant pas le moyen le plus rapide ni le plus économe en espace pour sauvegarder les bases de données MySQL, mais elles présentent un énorme avantage par rapport aux sauvegardes physiques.
Les sauvegardes physiques sont généralement des sauvegardes de type tout ou rien. Bien qu'il soit possible de créer une sauvegarde partielle avec Xtrabackup (nous l'avons décrit dans l'un de nos précédents articles de blog), la restauration d'une telle sauvegarde est délicate et prend du temps.
En gros, si nous voulons restaurer une seule table, nous devons arrêter toute la chaîne de réplication et effectuer la restauration sur tous les nœuds à la fois. C'est un problème majeur - de nos jours, vous pouvez rarement vous permettre d'arrêter toutes les bases de données.
Un autre problème est que le niveau de la table est le niveau de granularité le plus bas que vous pouvez atteindre avec Xtrabackup :vous pouvez restaurer une seule table mais vous ne pouvez pas en restaurer une partie. La sauvegarde logique, cependant, peut être restaurée en exécutant des instructions SQL, donc elle peut facilement être effectuée sur un cluster en cours d'exécution et vous pouvez (nous ne l'appellerions pas facilement, mais quand même) choisir les instructions SQL à exécuter afin que vous puissiez faire une restauration partielle d'une table.
Voyons comment cela peut être fait dans le monde réel.
Restauration d'une seule table MySQL à l'aide de mysqldump
Au début, veuillez garder à l'esprit que les sauvegardes partielles ne fournissent pas une vue cohérente des données. Lorsque vous effectuez des sauvegardes de tables distinctes, vous ne pouvez pas restaurer une telle sauvegarde à une position connue dans le temps (par exemple, pour provisionner l'esclave de réplication) même si vous restaurez toutes les données à partir de la sauvegarde. Ayant ceci derrière nous, continuons.
Nous avons un maître et un esclave :
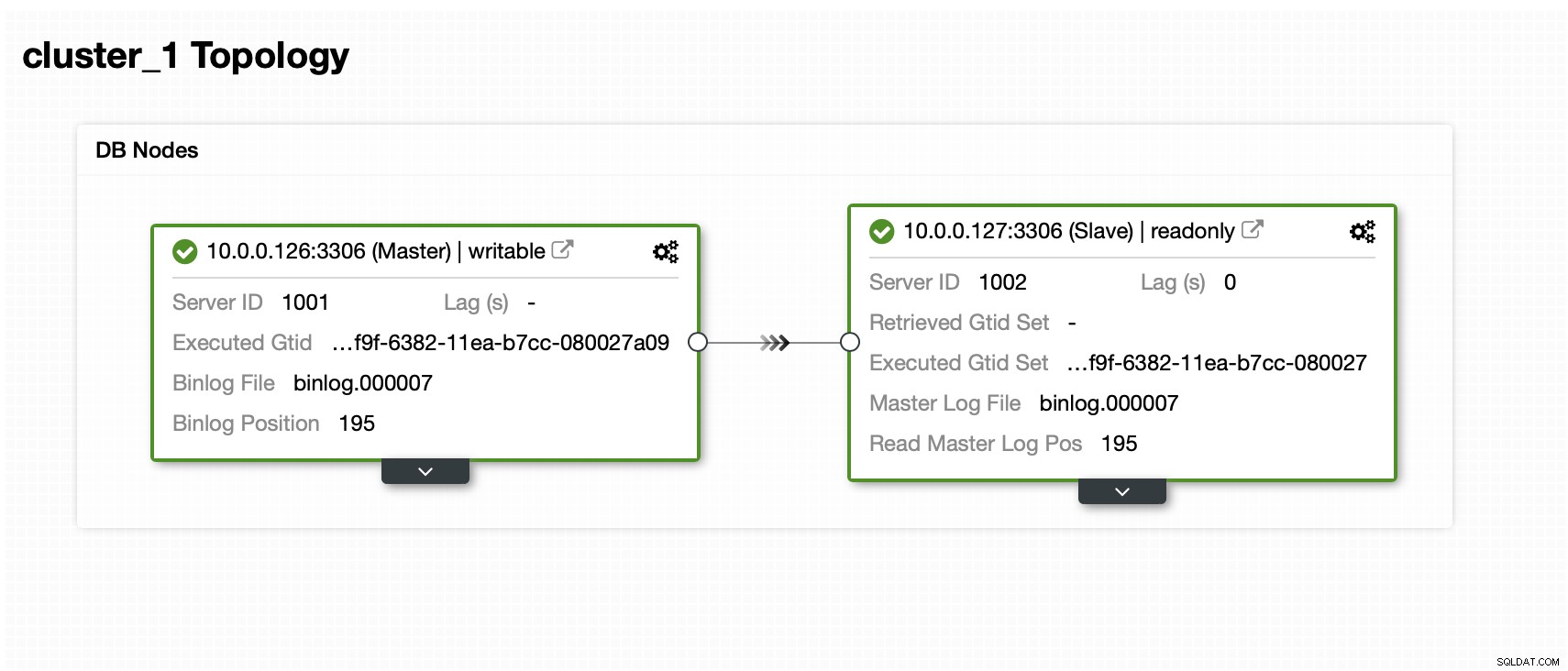
L'ensemble de données contient un schéma et plusieurs tables :
mysql> SHOW SCHEMAS;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sbtest |
| sys |
+--------------------+
5 rows in set (0.01 sec)
mysql> SHOW TABLES FROM sbtest;
+------------------+
| Tables_in_sbtest |
+------------------+
| sbtest1 |
| sbtest10 |
| sbtest11 |
| sbtest12 |
| sbtest13 |
| sbtest14 |
| sbtest15 |
| sbtest16 |
| sbtest17 |
| sbtest18 |
| sbtest19 |
| sbtest2 |
| sbtest20 |
| sbtest21 |
| sbtest22 |
| sbtest23 |
| sbtest24 |
| sbtest25 |
| sbtest26 |
| sbtest27 |
| sbtest28 |
| sbtest29 |
| sbtest3 |
| sbtest30 |
| sbtest31 |
| sbtest32 |
| sbtest4 |
| sbtest5 |
| sbtest6 |
| sbtest7 |
| sbtest8 |
| sbtest9 |
+------------------+
32 rows in set (0.00 sec)Maintenant, nous devons faire une sauvegarde. Il existe plusieurs façons d'aborder cette question. Nous pouvons simplement effectuer une sauvegarde cohérente de l'ensemble de données, mais cela générera un grand fichier unique avec toutes les données. Pour restaurer la table unique, nous devrions extraire les données de la table à partir de ce fichier. C'est bien sûr possible, mais cela prend beaucoup de temps et c'est à peu près une opération manuelle qui peut être scriptée, mais si vous n'avez pas de scripts appropriés en place, écrire du code ad hoc lorsque votre base de données est en panne et que vous êtes sous forte pression est pas nécessairement l'idée la plus sûre.
Au lieu de cela, nous pouvons préparer la sauvegarde de manière à ce que chaque table soit stockée dans un fichier séparé :
example@sqldat.com:~/backup# d=$(date +%Y%m%d) ; db='sbtest'; for tab in $(mysql -uroot -ppass -h127.0.0.1 -e "SHOW TABLES FROM ${db}" | grep -v Tables_in_${db}) ; do mysqldump --set-gtid-purged=OFF --routines --events --triggers ${db} ${tab} > ${d}_${db}.${tab}.sql ; doneVeuillez noter que nous définissons --set-gtid-purged=OFF. Nous en avons besoin si nous chargeons ces données plus tard dans la base de données. Sinon, MySQL tentera de définir @@GLOBAL.GTID_PURGED, ce qui échouera très probablement. MySQL définirait également SET @@SESSION.SQL_LOG_BIN=0 ; ce qui n'est certainement pas ce que nous voulons. Ces paramètres sont nécessaires si nous souhaitons effectuer une sauvegarde cohérente de l'ensemble des données et que nous souhaitons l'utiliser pour provisionner un nouveau nœud. Dans notre cas, nous savons qu'il ne s'agit pas d'une sauvegarde cohérente et qu'il est impossible de reconstruire quoi que ce soit à partir de celle-ci. Tout ce que nous voulons, c'est générer un vidage que nous pouvons charger sur le maître et le laisser répliquer sur les esclaves.
Cette commande a généré une belle liste de fichiers sql pouvant être chargés sur le cluster de production :
example@sqldat.com:~/backup# ls -alh
total 605M
drwxr-xr-x 2 root root 4.0K Mar 18 14:10 .
drwx------ 9 root root 4.0K Mar 18 14:08 ..
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest10.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest11.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest12.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest13.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest14.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest15.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest16.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest17.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest18.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest19.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest1.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest20.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest21.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest22.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest23.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest24.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest25.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest26.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest27.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest28.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest29.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest2.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest30.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest31.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest32.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest3.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest4.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest5.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest6.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest7.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest8.sql
-rw-r--r-- 1 root root 19M Mar 18 14:10 20200318_sbtest.sbtest9.sqlLorsque vous souhaitez restaurer les données, il vous suffit de charger le fichier SQL dans le nœud maître :
example@sqldat.com:~/backup# mysql -uroot -ppass sbtest < 20200318_sbtest.sbtest11.sqlLes données seront chargées dans la base de données et répliquées sur tous les esclaves.
Comment restaurer une seule table MySQL à l'aide de ClusterControl ?
Actuellement, ClusterControl ne fournit pas un moyen facile de restaurer une seule table, mais il est toujours possible de le faire avec seulement quelques actions manuelles. Vous pouvez utiliser deux options. Tout d'abord, adapté à un petit nombre de tables, vous pouvez essentiellement créer une planification dans laquelle vous effectuez des sauvegardes partielles d'une table distincte une par une :
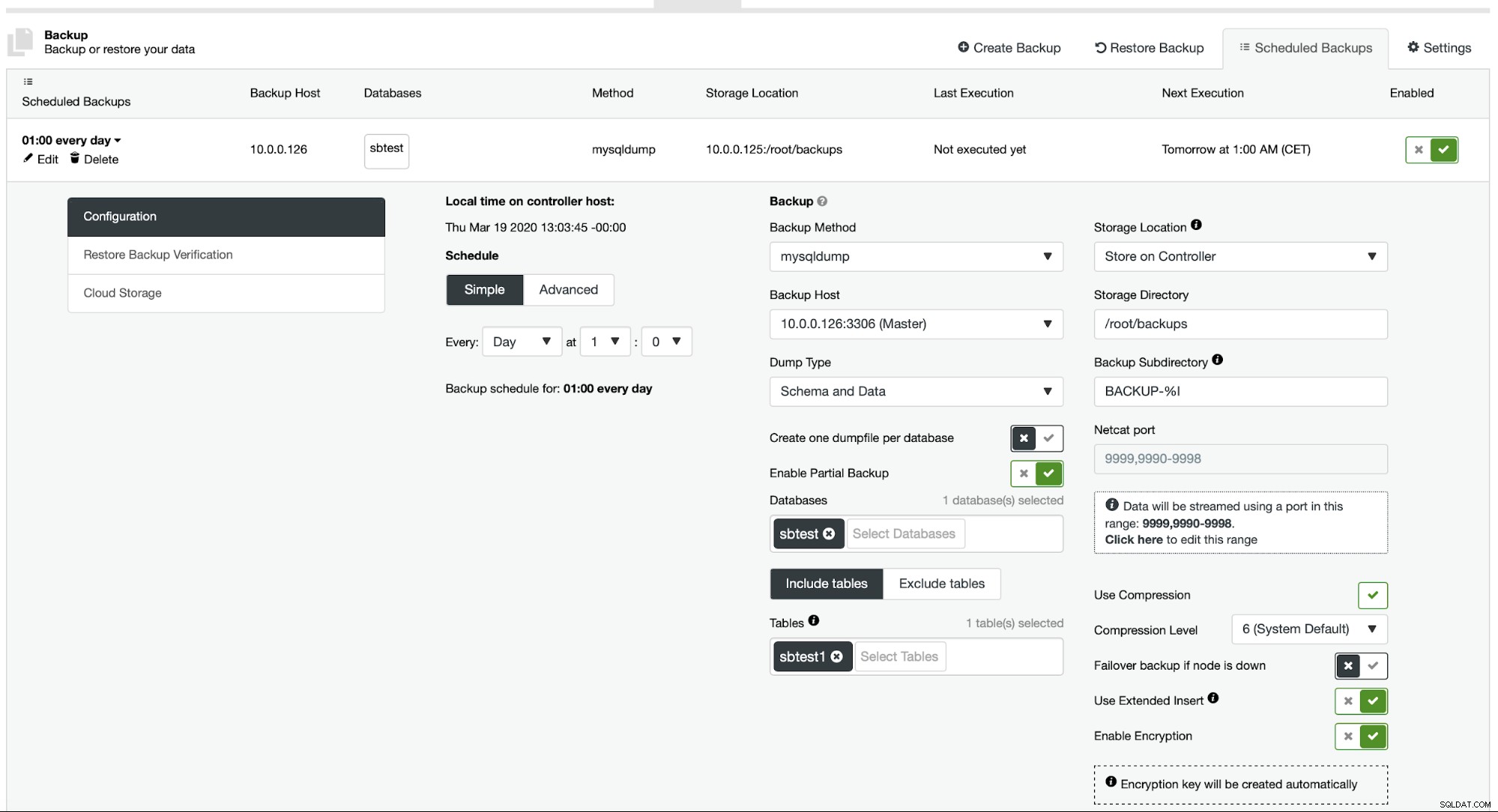
Ici, nous effectuons une sauvegarde de la table sbtest.sbtest1. Nous pouvons facilement programmer une autre sauvegarde pour la table sbtest2 :
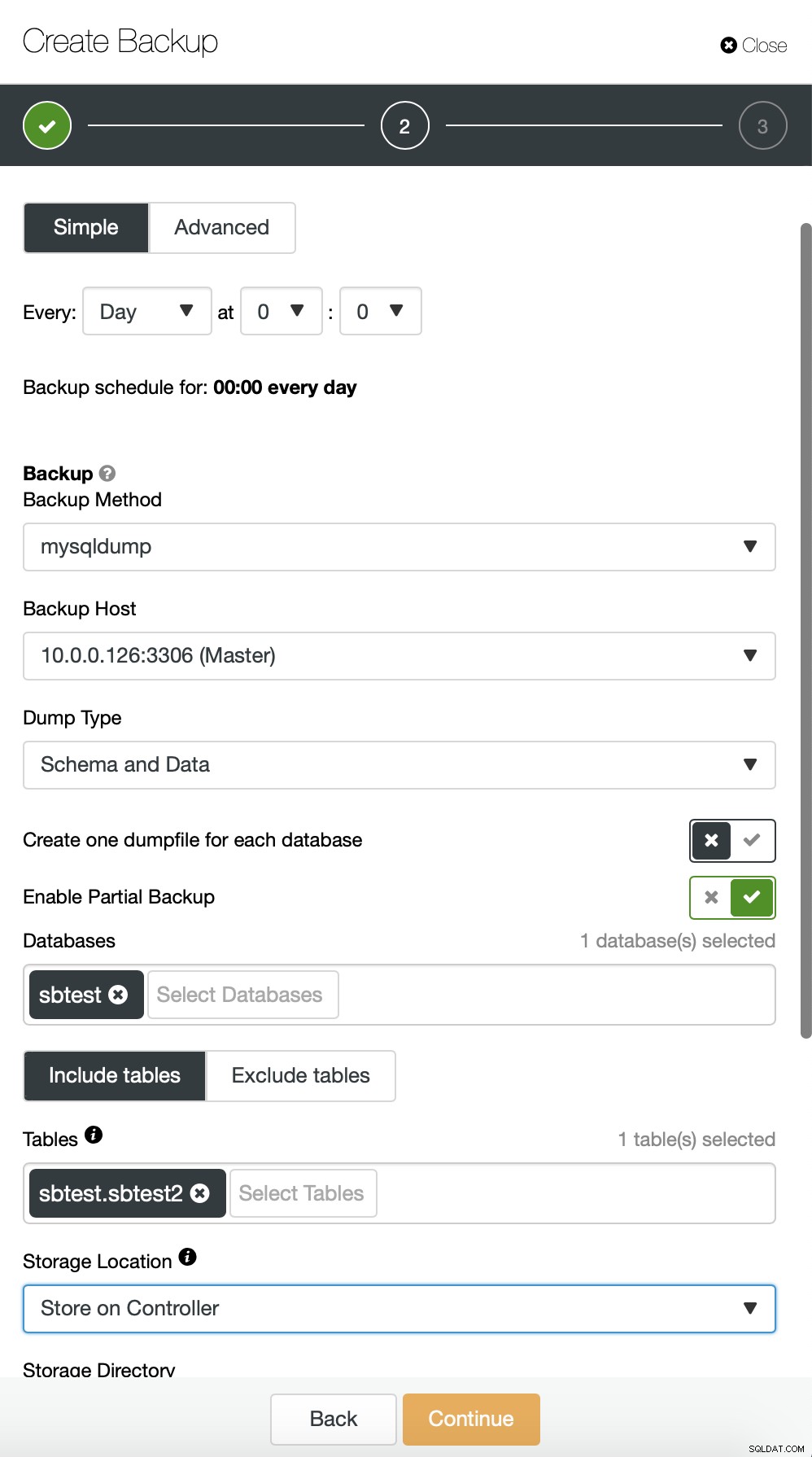
Vous pouvez également effectuer une sauvegarde et placer les données d'un seul schéma dans un fichier séparé :
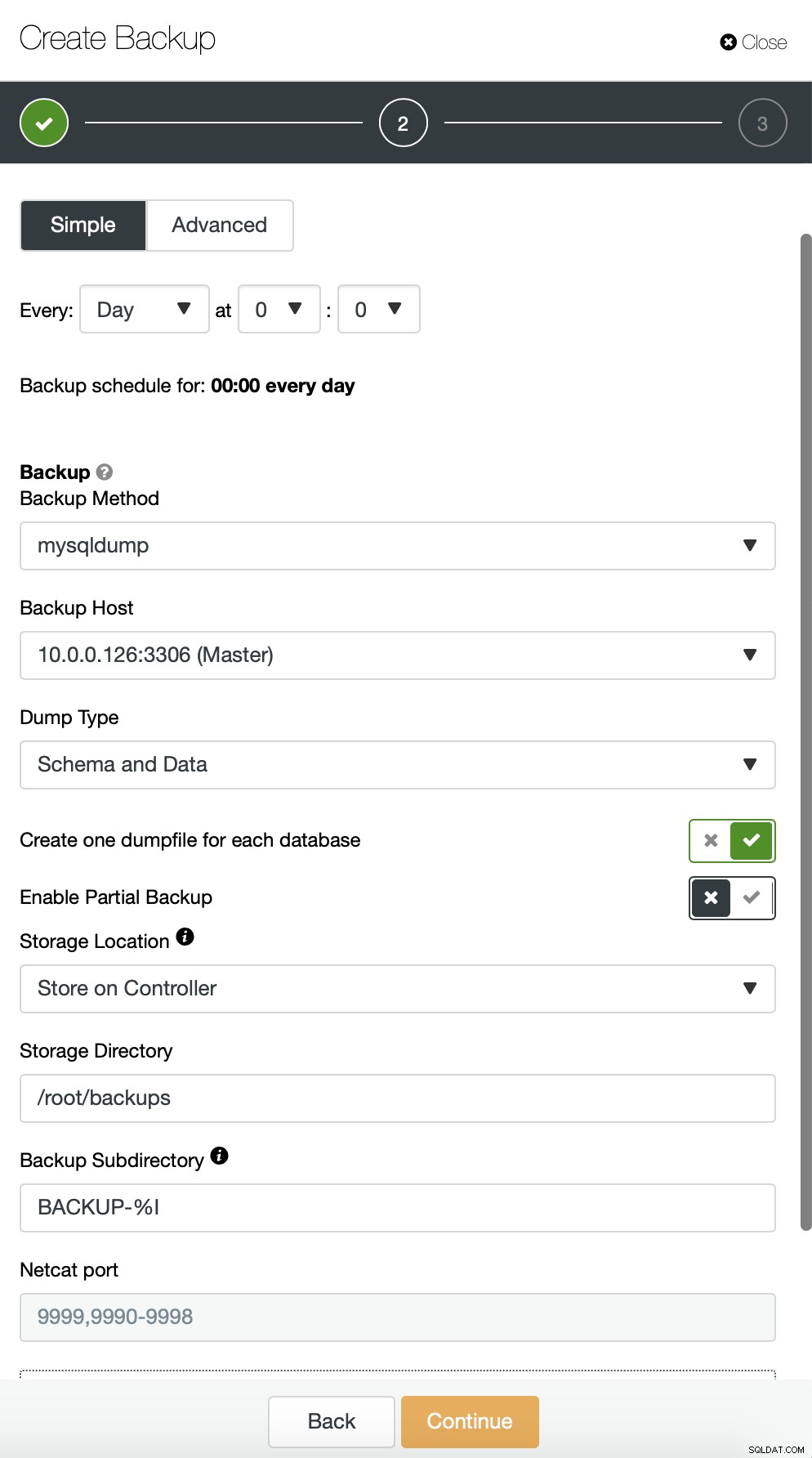
Maintenant, vous pouvez soit trouver les données manquantes à la main dans le fichier, restaurer cette sauvegarde sur un serveur séparé ou laissez ClusterControl le faire :
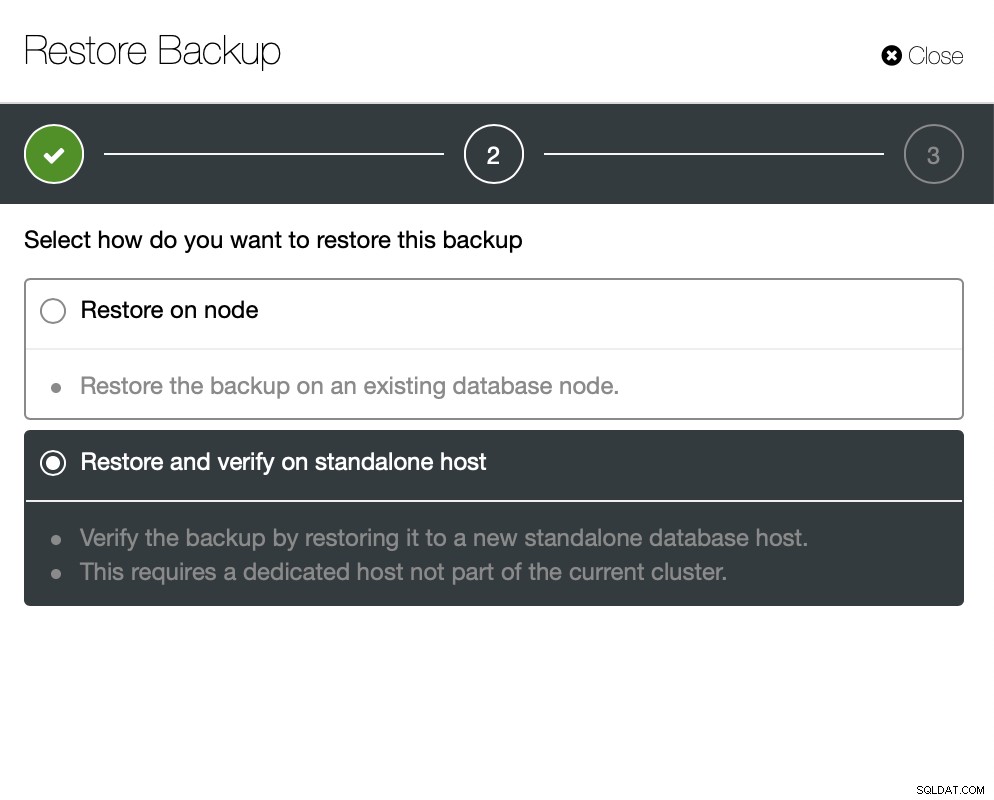
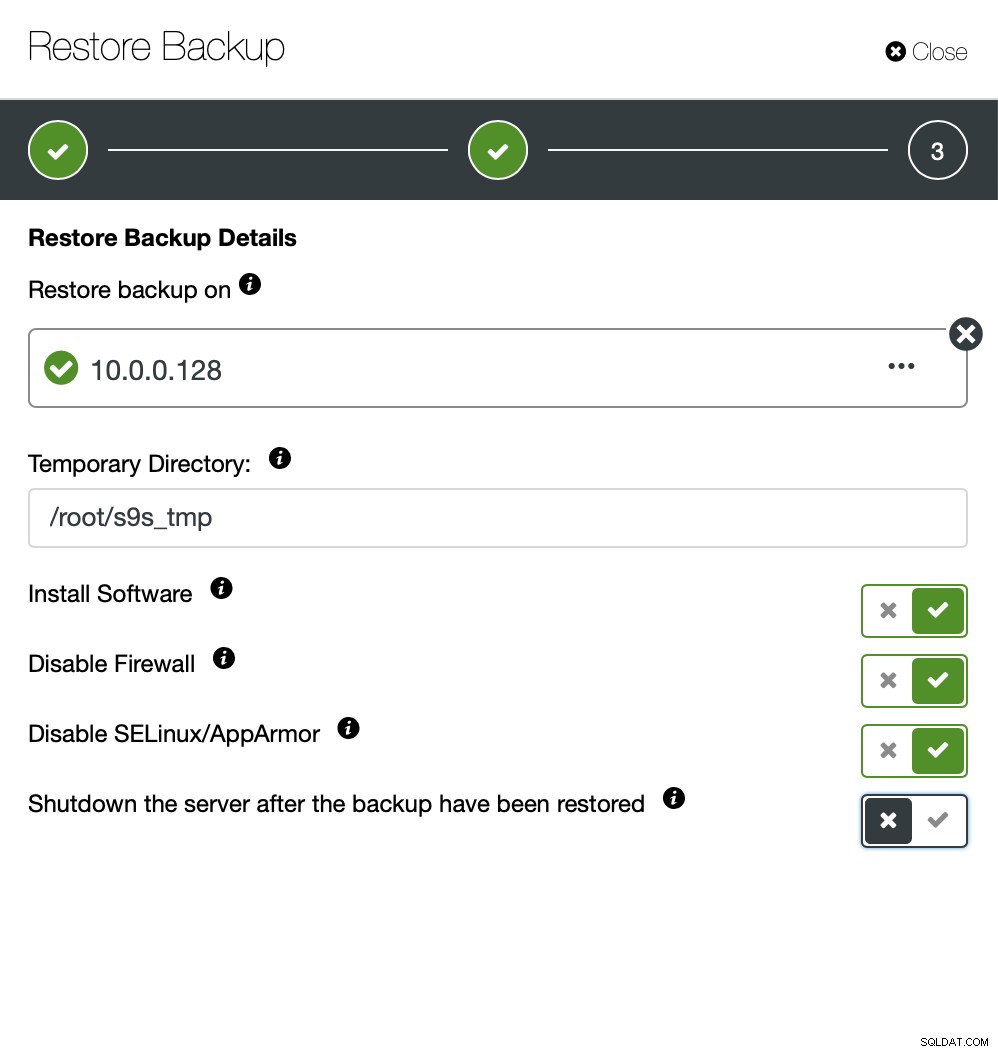
Vous maintenez le serveur opérationnel et vous pouvez extraire les données que vous voulait restaurer en utilisant mysqldump ou SELECT … INTO OUTFILE. Ces données extraites seront prêtes à être appliquées sur le cluster de production.