Il est très facile de prouver que les deux expressions suivantes donnent exactement le même résultat :le premier jour du mois en cours.
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE())); Et ils prennent à peu près le même temps de calcul :
SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); GO 1000000 GO SELECT SYSDATETIME(); GO DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()); GO 1000000 SELECT SYSDATETIME();
Sur mon système, les deux lots ont pris environ 175 secondes.
Alors, pourquoi préférez-vous une méthode plutôt qu'une autre ? Lorsque l'un d'entre eux se trompe vraiment avec les estimations de cardinalité .
Pour commencer, comparons ces deux valeurs :
SELECT DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), -- today: 2013-09-01
DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0); -- today: 1786-05-01
--------------------------------------^^^^^^^^^^^^ notice how these are swapped
(Notez que les valeurs réelles représentées ici changeront, selon le moment où vous lisez ce message - "aujourd'hui" référencé dans le commentaire est le 5 septembre 2013, le jour où ce message a été écrit. En octobre 2013, par exemple, la sortie sera être 2013-10-01 et 1786-04-01 .)
Cela dit, laissez-moi vous montrer ce que je veux dire…
Une reproduction
Créons une table très simple, avec seulement un cluster DATE colonne et chargez 15 000 lignes avec la valeur 1786-05-01 et 50 lignes avec la valeur 2013-09-01 :
CREATE TABLE dbo.DateTest ( CreateDate DATE ); CREATE CLUSTERED INDEX x ON dbo.DateTest(CreateDate); INSERT dbo.DateTest(CreateDate) SELECT TOP (15000) DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 UNION ALL SELECT TOP (50) DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0) FROM sys.all_objects;
Et regardons ensuite les plans réels pour ces deux requêtes :
SELECT /* Query 1 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT /* Query 2 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
Les plans graphiques semblent corrects :
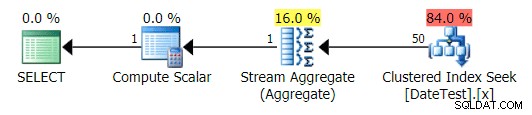
Plan graphique pour DATEDIFF(MONTH, 0, GETDATE()) requête
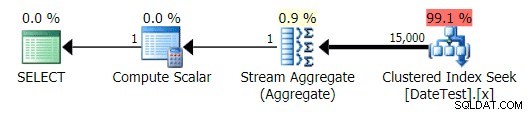
Plan graphique pour DATEDIFF(MONTH, GETDATE(), 0) requête
Mais les coûts estimés sont aberrants. Notez à quel point les coûts estimés sont plus élevés pour la première requête, qui ne renvoie que 50 lignes, par rapport à la deuxième requête, qui renvoie 15 000 lignes !

Grille de déclaration indiquant les coûts estimés
Et l'onglet Top Operations montre que la première requête (recherche de 2013-09-01 ) a estimé qu'il trouverait 15 000 lignes, alors qu'en réalité il n'en a trouvé que 50 ; la deuxième requête montre le contraire :elle s'attendait à trouver 50 lignes correspondant à 1786-05-01 , mais en a trouvé 15 000. Sur la base d'estimations de cardinalité incorrectes comme celle-ci, je suis sûr que vous pouvez imaginer le type d'effet drastique que cela pourrait avoir sur des requêtes plus complexes sur des ensembles de données beaucoup plus volumineux.
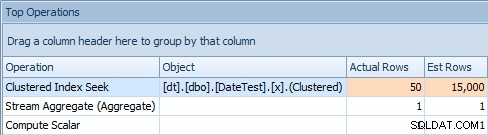
Onglet Top Operations pour la première requête [DATEDIFF(MONTH, 0, GETDATE())]
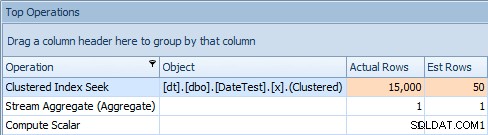
Onglet Top Operations pour la deuxième requête [DATEDIFF(MONTH, 0, GETDATE())]
Une variante légèrement différente de la requête, utilisant une expression différente pour calculer le début du mois (évoquée au début de l'article), ne présente pas ce symptôme :
SELECT /* Query 3 */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
Le plan est très similaire à la requête 1 ci-dessus, et si vous ne regardiez pas de plus près, vous penseriez que ces plans sont équivalents :
Plan graphique pour requête non-DATEDIFF
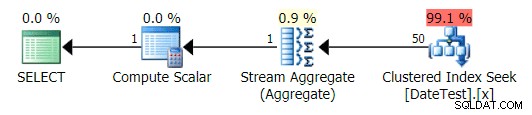
Cependant, lorsque vous regardez l'onglet Principales opérations ici, vous voyez que l'estimation est parfaite :
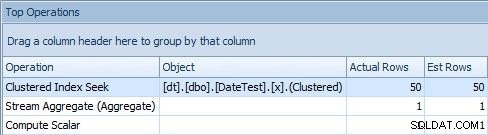
Onglet Top Operations affichant des estimations précises
Sur cette taille de données et cette requête particulières, l'impact net sur les performances (notamment la durée et les lectures) est largement non pertinent. Et il est important de noter que les requêtes elles-mêmes renvoient toujours des données correctes ; c'est juste que les estimations sont fausses (et pourraient conduire à un plan pire que celui que j'ai démontré ici). Cela dit, si vous dérivez des constantes à l'aide de DATEDIFF dans vos requêtes de cette façon, vous devriez vraiment tester cet impact dans votre environnement.
Alors, pourquoi cela arrive-t-il ?
Pour le dire simplement, SQL Server a un DATEDIFF bogue où il échange les deuxième et troisième arguments lors de l'évaluation de l'expression pour l'estimation de la cardinalité. Cela semble impliquer un pliage constant, au moins périphériquement; il y a beaucoup plus de détails sur le pliage constant dans cet article de Books Online mais, malheureusement, l'article ne révèle aucune information sur ce bogue particulier.
Il existe un correctif - ou existe-t-il ?
Il existe un article de la base de connaissances (KB #2481274) qui prétend résoudre le problème, mais il a quelques problèmes qui lui sont propres :
- L'article de la base de connaissances affirme que le problème a été résolu dans divers service packs ou mises à jour cumulatives pour SQL Server 2005, 2008 et 2008 R2. Cependant, le symptôme est toujours présent dans les branches qui n'y sont pas explicitement mentionnées, même si elles ont vu de nombreuses UC supplémentaires depuis la publication de l'article. Je peux toujours reproduire ce problème sur SQL Server 2008 SP3 CU #8 (10.0.5828) et SQL Server 2012 SP1 CU #5 (11.0.3373).
- Il oublie de mentionner que, pour bénéficier du correctif, vous devez activer l'indicateur de trace 4199 (et "bénéficier" de toutes les autres façons dont l'indicateur de trace spécifique peut affecter l'optimiseur). Le fait que cet indicateur de trace soit requis pour le correctif est mentionné dans un élément Connect associé, # 630583, mais cette information n'a pas été renvoyée à l'article de la base de connaissances. Ni l'article de la base de connaissances ni l'élément Connect ne donnent un aperçu de la cause (que les arguments de
DATEDIFFont été échangés pendant l'évaluation). Du côté positif, exécuter les requêtes ci-dessus avec l'indicateur de trace activé (en utilisantOPTION (QUERYTRACEON 4199)) génère des plans qui n'ont pas le problème d'estimation incorrecte.
- Il vous suggère d'utiliser SQL dynamique pour contourner le problème. Dans mes tests, en utilisant une expression différente (comme celle ci-dessus qui n'utilise pas
DATEDIFF) a surmonté le problème dans les versions modernes de SQL Server 2008 et SQL Server 2012. Recommander SQL dynamique ici est inutilement complexe et probablement exagéré, étant donné qu'une expression différente pourrait résoudre le problème. Mais si vous deviez utiliser SQL dynamique, je le ferais de cette façon au lieu de la manière recommandée dans l'article de la base de connaissances, surtout pour minimiser les risques d'injection SQL :DECLARE @date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0), @sql NVARCHAR(MAX) = N'SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @date;'; EXEC sp_executesql @sql, N'@date DATE', @date;(Et vous pouvez ajouter
OPTION (RECOMPILE)là, selon la façon dont vous voulez que SQL Server gère le reniflage des paramètres.)Cela conduit au même plan que la requête précédente qui n'utilise pas
DATEDIFF, avec des estimations appropriées et 99,1 % du coût dans la recherche d'index clusterisé.Une autre approche qui pourrait vous tenter (et par vous, je veux dire moi, quand j'ai commencé à enquêter) consiste à utiliser une variable pour calculer la valeur au préalable :
DECLARE @d DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0); SELECT COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
Le problème avec cette approche est qu'avec une variable, vous allez vous retrouver avec un plan stable, mais la cardinalité va être basée sur une supposition (et le type de supposition dépendra de la présence ou de l'absence de statistiques) . Dans ce cas, voici l'estimation par rapport à la réalité :
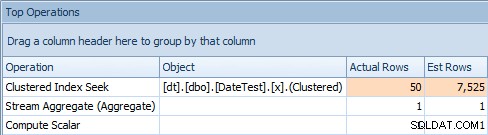
Onglet Top Operations pour une requête qui utilise une variableCe n'est clairement pas juste; il semble que SQL Server ait deviné que la variable correspondrait à 50 % des lignes de la table.
SQL Server 2014
J'ai trouvé un problème légèrement différent dans SQL Server 2014. Les deux premières requêtes sont corrigées (par des modifications de l'estimateur de cardinalité ou d'autres correctifs), ce qui signifie que le DATEDIFF les arguments ne sont plus commutés. Yay!
Cependant, une régression semble avoir été introduite dans la solution de contournement consistant à utiliser une expression différente - elle souffre maintenant d'une estimation inexacte (basée sur la même estimation de 50 % que l'utilisation d'une variable). Voici les requêtes que j'ai exécutées :
SELECT /* 0, GETDATE() (2013) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0);
SELECT /* GETDATE(), 0 (1786) */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = DATEADD(MONTH, DATEDIFF(MONTH, GETDATE(), 0), 0);
SELECT /* Non-DATEDIFF */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = CONVERT(DATE, DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE()));
DECLARE @d DATE = DATEADD(DAY, 1 - DAY(GETDATE()), GETDATE());
SELECT /* Variable */ COUNT(*) FROM dbo.DateTest WHERE CreateDate = @d;
DECLARE
@date DATE = DATEADD(MONTH, DATEDIFF(MONTH, 0, GETDATE()), 0),
@sql NVARCHAR(MAX) = N'SELECT /* Dynamic SQL */ COUNT(*) FROM dbo.DateTest
WHERE CreateDate = @date;';
EXEC sp_executesql @sql, N'@date DATE', @date; Voici la grille d'instructions comparant les coûts estimés et les métriques d'exécution réelles :
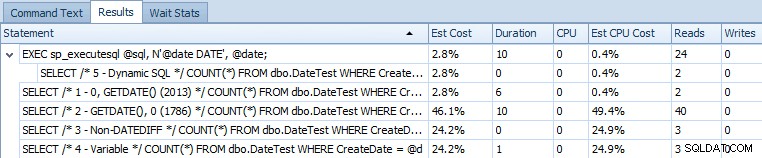
Coûts estimés pour les 5 requêtes de spécimen sur SQL Server 2014
Et voici leurs nombres de lignes estimés et réels (assemblés à l'aide de Photoshop) :

Nombre de lignes estimé et réel pour les 5 requêtes sur SQL Server 2014
Il ressort clairement de cette sortie que l'expression qui résolvait auparavant le problème en a maintenant introduit un autre. Je ne sais pas s'il s'agit d'un symptôme d'exécution dans un CTP (par exemple, quelque chose qui sera corrigé) ou s'il s'agit vraiment d'une régression.
Dans ce cas, l'indicateur de trace 4199 (seul) n'a aucun effet; le nouvel estimateur de cardinalité fait des suppositions et n'est tout simplement pas correct. Que cela conduise à un problème de performances réel dépend beaucoup de nombreux autres facteurs au-delà de la portée de cet article.
Si vous rencontrez ce problème, vous pouvez - au moins dans les CTP actuels - restaurer l'ancien comportement en utilisant OPTION (QUERYTRACEON 9481, QUERYTRACEON 4199) . L'indicateur de trace 9481 désactive le nouvel estimateur de cardinalité, comme décrit dans ces notes de version (qui disparaîtra certainement ou au moins se déplacera à un moment donné). Cela restaure à son tour les estimations correctes pour le non-DATEDIFF version de la requête, mais malheureusement ne résout toujours pas le problème où une estimation est faite sur la base d'une variable (et l'utilisation de TF9481 seul, sans TF4199, force les deux premières requêtes à régresser vers l'ancien comportement d'échange d'arguments).
Conclusion
J'avoue que cela a été une énorme surprise pour moi. Félicitations à Martin Smith et t-clausen.dk pour avoir persévéré et m'avoir convaincu qu'il s'agissait d'un problème réel et non imaginaire. Un grand merci également à Paul White (@SQL_Kiwi) qui m'a aidé à garder ma santé mentale et m'a rappelé les choses que je ne devrais pas dire. :-)
N'étant pas au courant de ce bogue, j'étais catégorique sur le fait que le meilleur plan de requête était généré simplement en modifiant le texte de la requête, et non en raison du changement spécifique. Il s'avère qu'il arrive parfois qu'une modification d'une requête que vous supposez ne fera aucune différence, le fera réellement. Je vous recommande donc, si vous avez des modèles de requête similaires dans votre environnement, de les tester et de vous assurer que les estimations de cardinalité sont correctes. Et prenez note de les tester à nouveau lors de la mise à niveau.