[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]
Dans la première partie de cette série, nous avons vu comment le problème d'Halloween s'applique à UPDATE requêtes. Pour résumer brièvement, le problème était qu'un index utilisé pour localiser les enregistrements à mettre à jour avait ses clés modifiées par l'opération de mise à jour elle-même (une autre bonne raison d'utiliser des colonnes incluses dans un index plutôt que d'étendre les clés). L'optimiseur de requête a introduit un opérateur Eager Table Spool pour séparer les côtés lecture et écriture du plan d'exécution afin d'éviter le problème. Dans cet article, nous verrons comment le même problème sous-jacent peut affecter INSERT et DELETE déclarations.
Insérer des déclarations
Maintenant que nous connaissons un peu les conditions qui nécessitent une protection Halloween, il est assez facile de créer un INSERT exemple qui implique la lecture et l'écriture dans les clés de la même structure d'index. L'exemple le plus simple est la duplication de lignes dans une table (où l'ajout de nouvelles lignes modifie inévitablement les clés de l'index clusterisé) :
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
INSERT dbo.Demo
SELECT SomeKey FROM dbo.Demo; Le problème est que les lignes nouvellement insérées peuvent être rencontrées par le côté lecture du plan d'exécution, ce qui peut entraîner une boucle qui ajoute des lignes pour toujours (ou du moins jusqu'à ce qu'une certaine limite de ressources soit atteinte). L'optimiseur de requête reconnaît ce risque et ajoute un spool de table Eager pour fournir la séparation de phases nécessaire :
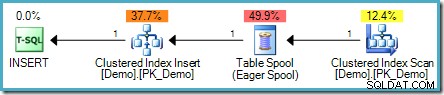
Un exemple plus réaliste
Vous n'écrivez probablement pas souvent des requêtes pour dupliquer chaque ligne d'une table, mais vous écrivez probablement des requêtes où la table cible pour un INSERT apparaît également quelque part dans le SELECT clause. Un exemple consiste à ajouter des lignes à partir d'une table intermédiaire qui n'existent pas déjà dans la destination :
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
-- Test query
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
); Le plan d'exécution est :
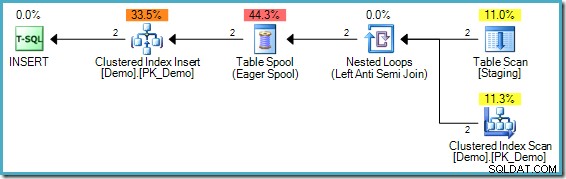
Le problème dans ce cas est subtilement différent, bien qu'il s'agisse toujours d'un exemple du même problème de base. Il n'y a pas de valeur '1234' dans la table Demo cible, mais la table Staging contient deux entrées de ce type. Sans séparation de phase, la première valeur « 1234 » rencontrée serait insérée avec succès, mais la deuxième vérification trouverait que la valeur « 1234 » existe maintenant et ne tenterait pas de l'insérer à nouveau. L'instruction dans son ensemble se terminerait avec succès.
Cela pourrait produire un résultat souhaitable dans ce cas particulier (et pourrait même sembler intuitivement correct) mais ce n'est pas une implémentation correcte. La norme SQL exige que les requêtes de modification de données s'exécutent comme si les trois phases de lecture, d'écriture et de vérification des contraintes se produisaient complètement séparément (voir première partie).
En recherchant toutes les lignes à insérer en une seule opération, nous devons sélectionner les deux lignes "1234" dans la table Staging, car cette valeur n'existe pas encore dans la cible. Le plan d'exécution doit donc essayer d'insérer les deux "1234" lignes de la table Staging, entraînant une violation de clé primaire :
Msg 2627, Niveau 14, État 1, Ligne 1Violation de la contrainte PRIMARY KEY 'PK_Demo'.
Impossible d'insérer la clé en double dans l'objet 'dbo.Demo'.
La valeur de la clé en double est ( 1234).
La déclaration a été terminée.
La séparation de phase fournie par le spool de table garantit que toutes les vérifications d'existence sont terminées avant que toute modification ne soit apportée à la table cible. Si vous exécutez la requête dans SQL Server avec les exemples de données ci-dessus, vous recevrez le message d'erreur (correct).
La protection Halloween est requise pour les instructions INSERT où la table cible est également référencée dans la clause SELECT.
Supprimer les déclarations
Nous pourrions nous attendre à ce que le problème d'Halloween ne s'applique pas à DELETE instructions, car cela ne devrait pas vraiment avoir d'importance si nous essayons de supprimer une ligne plusieurs fois. Nous pouvons modifier notre exemple de table intermédiaire pour supprimer lignes de la table Demo qui n'existent pas dans Staging :
TRUNCATE TABLE dbo.Demo;
TRUNCATE TABLE dbo.Staging;
INSERT dbo.Demo (SomeKey) VALUES (1234);
DELETE dbo.Demo
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Staging AS s
WHERE s.SomeKey = dbo.Demo.SomeKey
); Ce test semble valider notre intuition car il n'y a pas de Table Spool dans le plan d'exécution :
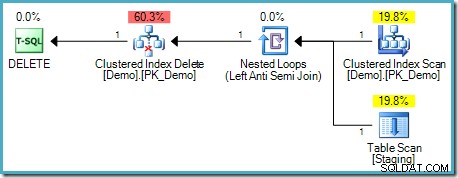
Ce type de DELETE ne nécessite pas de séparation de phases, car chaque ligne possède un identifiant unique (un RID si la table est un tas, une ou plusieurs clés d'index en cluster et éventuellement un unificateur dans le cas contraire). Ce localisateur de ligne unique est une clé stable - il n'y a aucun mécanisme par lequel il peut changer pendant l'exécution de ce plan, donc le problème d'Halloween ne se pose pas.
SUPPRIMER la protection d'Halloween
Néanmoins, il existe au moins un cas où un DELETE requiert la protection Halloween :lorsque le plan fait référence à une ligne de la table autre que celle qui est en cours de suppression. Cela nécessite une auto-jointure, que l'on trouve couramment lorsque des relations hiérarchiques sont modélisées. Un exemple simplifié est présenté ci-dessous :
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', 'A'),
('C', 'B'),
('D', 'C');
Il devrait vraiment y avoir une référence de clé étrangère de même table définie ici, mais ignorons cet échec de conception pour un moment - la structure et les données sont néanmoins valides (et il est malheureusement assez courant de trouver des clés étrangères omises dans le monde réel). Quoi qu'il en soit, la tâche à accomplir consiste à supprimer toute ligne où la ref la colonne pointe vers un pk inexistant valeur. Le DELETE naturel la requête correspondant à cette exigence est :
DELETE dbo.Test
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t2
WHERE t2.pk = dbo.Test.ref
); Le plan de requête est :
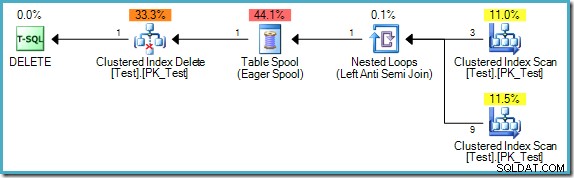
Notez que ce plan comprend désormais une bobine de table Eager coûteuse. La séparation des phases est requise ici, car sinon les résultats pourraient dépendre de l'ordre dans lequel les lignes sont traitées :
Si le moteur d'exécution commence par la ligne où pk =B, il ne trouverait aucune ligne correspondante (ref =A et il n'y a pas de ligne où pk =A). Si l'exécution passe alors à la ligne où pk =C, il serait également supprimé car nous venons de supprimer la ligne B pointée par sa ref colonne. Le résultat final serait que le traitement itératif dans cet ordre supprimerait toutes les lignes de la table, ce qui est clairement incorrect.
En revanche, si le moteur d'exécution a traité la ligne avec pk =D d'abord, il trouverait une ligne correspondante (ref =C). En supposant que l'exécution continue en sens inverse pk commande, la seule ligne supprimée de la table serait celle où pk =B. Il s'agit du résultat correct (rappelez-vous que la requête doit s'exécuter comme si les phases de lecture, d'écriture et de validation s'étaient déroulées de manière séquentielle et sans chevauchement).
Séparation des phases pour la validation des contraintes
En aparté, nous pouvons voir un autre exemple de séparation de phase si nous ajoutons une contrainte de clé étrangère de même table à l'exemple précédent :
DROP TABLE dbo.Test;
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk),
CONSTRAINT FK_ref_pk
FOREIGN KEY (ref)
REFERENCES dbo.Test (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', NULL),
('C', 'B'),
('D', 'C'); Le plan d'exécution pour l'INSERT est :
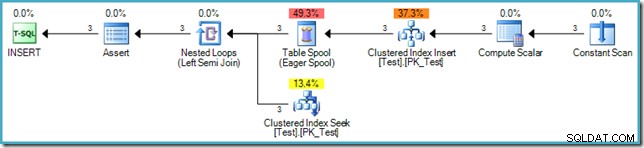
L'insertion elle-même ne nécessite pas de protection Halloween car le plan ne lit pas à partir de la même table (la source de données est une table virtuelle en mémoire représentée par l'opérateur Constant Scan). La norme SQL exige cependant que la phase 3 (vérification des contraintes) se produise une fois la phase d'écriture terminée. Pour cette raison, une séparation de phase Eager Table Spool est ajoutée au plan après l'index de l'index clusterisé, et juste avant que chaque ligne ne soit vérifiée pour s'assurer que la contrainte de clé étrangère reste valide.
Si vous commencez à penser que la traduction d'une requête de modification SQL déclarative basée sur un ensemble en un plan d'exécution physique itératif robuste est une tâche délicate, vous commencez à comprendre pourquoi le traitement des mises à jour (dont Halloween Protection n'est qu'une très petite partie) est le partie la plus complexe du processeur de requêtes.
Les instructions DELETE nécessitent la protection Halloween lorsqu'une auto-jointure de la table cible est présente.
Résumé
La protection d'Halloween peut être une fonctionnalité coûteuse (mais nécessaire) dans les plans d'exécution qui modifient les données (où la « modification » inclut toute la syntaxe SQL qui ajoute, modifie ou supprime des lignes). La protection Halloween est requise pour UPDATE plans où les clés d'une structure d'index commune sont à la fois lues et modifiées, pour INSERT plans où la table cible est référencée côté lecture du plan, et pour DELETE plans où une jointure réflexive sur la table cible est effectuée.
La prochaine partie de cette série couvrira certaines optimisations spéciales du problème d'Halloween qui s'appliquent uniquement à MERGE déclarations.
[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]



