Ce blog est une brève présentation de Jenkins et vous montre comment utiliser cet outil pour vous aider dans certaines de vos tâches quotidiennes d'administration et de gestion de PostgreSQL.
À propos de Jenkins
Jenkins est un logiciel open source pour l'automatisation. Il est développé en Java et est l'un des outils les plus populaires pour l'intégration continue (CI) et la livraison continue (CD).
En 2010, après le rachat de Sun Microsystems par Oracle, le logiciel "Hudson" était en conflit avec sa communauté open source. Ce différend est devenu la base du lancement du projet Jenkins.
De nos jours, "Hudson" (licence publique Eclipse) et "Jenkins" (licence MIT) sont deux projets actifs et indépendants avec un objectif très similaire.
Jenkins propose des milliers de plug-ins que vous pouvez utiliser pour accélérer la phase de développement grâce à l'automatisation de l'ensemble du cycle de vie du développement ; construire, documenter, tester, empaqueter, mettre en scène et déployer.
Que fait Jenkins ?
Bien que l'utilisation principale de Jenkins puisse être l'intégration continue (CI) et la livraison continue (CD), cet open source possède un ensemble de fonctionnalités et peut être utilisé sans aucun engagement ou dépendance de CI ou de CD, ainsi Jenkins présente quelques fonctionnalités intéressantes pour explorer :
- Planification des tâches périodiques (au lieu d'utiliser le traditionnel crontab )
- Surveillance des travaux, de ses journaux et de ses activités par une vue propre (car ils ont une option de regroupement)
- La maintenance des travaux pourrait être effectuée facilement ; en supposant que Jenkins dispose d'un ensemble d'options pour cela
- Configuration et planification de l'installation du logiciel (à l'aide de Puppet) sur le même hôte ou sur un autre.
- Publication de rapports et envoi de notifications par e-mail
Exécuter des tâches PostgreSQL dans Jenkins
Il y a trois tâches courantes qu'un développeur PostgreSQL ou un administrateur de base de données doit effectuer quotidiennement :
- Planification et exécution de scripts PostgreSQL
- Exécuter un processus PostgreSQL composé de trois scripts ou plus
- Intégration continue (CI) pour les développements PL/pgSQL
Pour l'exécution de ces exemples, il est supposé que les serveurs Jenkins et PostgreSQL (au moins la version 9.5) sont installés et fonctionnent correctement.
Planification et exécution d'un script PostgreSQL
Dans la plupart des cas la mise en place de scripts PostgreSQL quotidiens (ou périodiques) pour l'exécution d'une tâche usuelle telle que...
- Génération des sauvegardes
- Tester la restauration d'une sauvegarde
- Exécution d'une requête à des fins de création de rapports
- Nettoyer et archiver les fichiers journaux
- Appeler une procédure PL/pgSQL pour purger les tables
t est défini sur crontab :
0 5,17 * * * /filesystem/scripts/archive_logs.sh
0 2 * * * /db/scripts/db_backup.sh
0 6 * * * /db/data/scripts/backup_client_tables.sh
0 4 * * * /db/scripts/Test_db_restore.sh
*/10 * * * * /db/scripts/monitor.sh
0 4 * * * /db/data/scripts/queries.sh
0 4 * * * /db/scripts/data_extraction.sh
0 5 * * * /db/scripts/data_import.sh
0 */4 * * * /db/data/scripts/report.shEn tant que crontab n'est pas le meilleur outil convivial pour gérer ce type de planification, cela peut être fait sur Jenkins avec les avantages suivants...
- Interface très conviviale pour suivre leur progression et leur statut actuel
- Les journaux sont immédiatement disponibles et ne nécessitent aucune subvention spéciale pour y accéder
- Le travail pourrait être exécuté manuellement sur Jenkins au lieu d'avoir une planification
- Pour certains types de travaux, il n'est pas nécessaire de définir les utilisateurs et les mots de passe dans des fichiers en texte brut car Jenkins le fait de manière sécurisée
- Les tâches peuvent être définies comme une exécution d'API
Ainsi, cela pourrait être une bonne solution de migrer les travaux liés aux tâches PostgreSQL vers Jenkins au lieu de crontab.
D'autre part, la plupart des administrateurs et développeurs de bases de données ont de solides compétences en langages de script et il leur serait facile de développer de petites interfaces pour traiter ces scripts afin de mettre en œuvre les processus automatisés dans le but d'améliorer leurs tâches. Mais rappelez-vous, Jenkins a très probablement déjà un ensemble de fonctions pour le faire et ces fonctionnalités peuvent faciliter la vie des développeurs qui choisissent de les utiliser.
Ainsi, pour définir l'exécution du script, il est nécessaire de créer un nouveau travail en sélectionnant l'option "Nouvel élément".
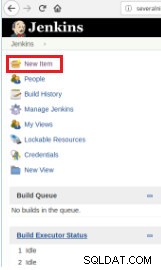 Figure 1 – "Nouvel élément" afin de définir une tâche pour exécuter un script PostgreSQL
Figure 1 – "Nouvel élément" afin de définir une tâche pour exécuter un script PostgreSQL Ensuite, après l'avoir nommé, choisissez le type "Projets FreeStyle" et cliquez sur OK.
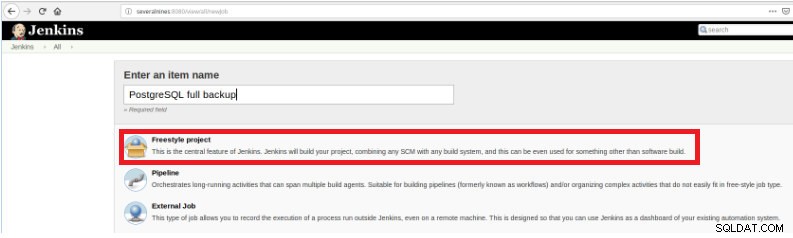 Figure 2 – Sélection du type de travail (élément)
Figure 2 – Sélection du type de travail (élément) Pour terminer la création de ce nouveau travail, dans la section "Build" doit être sélectionné l'option "Execute script" et dans la boîte de ligne de commande le chemin et le paramétrage du script qui sera exécuté :
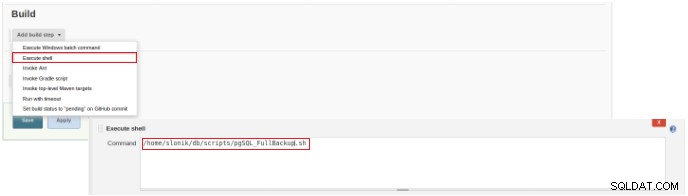 Figure 3 – Spécification de la commande à exécuter
Figure 3 – Spécification de la commande à exécuter Pour ce type de travail, il est conseillé de vérifier les autorisations de script, car au moins l'exécution pour le groupe auquel appartient le fichier et pour tout le monde doit être définie.
Dans cet exemple, le script query.sh a des autorisations de lecture et d'exécution pour tout le monde, des autorisations de lecture et d'exécution pour le groupe et des autorisations de lecture, d'écriture et d'exécution pour l'utilisateur :
example@sqldat.com:~/db/scripts$ ls -l query.sh
-rwxr-xr-x 1 slonik slonik 365 May 11 20:01 query.sh
example@sqldat.com:~/db/scripts$ Ce script a un ensemble d'instructions très simple, essentiellement des appels à l'utilitaire psql afin d'exécuter des requêtes :
#!/bin/bash
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl" > /home/slonik/db/scripts/appl.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_users" > /home/slonik/db/scripts/appl_user.dat
/usr/lib/postgresql/10/bin/psql -U report -d db_deploy -c "select * from appl_rights" > /home/slonik/db/scripts/appl_rights.datExécuter un processus PostgreSQL composé de trois scripts ou plus
Dans cet exemple, je vais décrire ce dont vous avez besoin pour exécuter trois scripts différents afin de masquer des données sensibles et pour cela, nous suivrons les étapes ci-dessous...
- Importer des données à partir de fichiers
- Préparer les données à masquer
- Sauvegarde de la base de données avec des données masquées
Ainsi, pour définir ce nouveau travail, il est nécessaire de sélectionner l'option "New Item" dans la page principale de Jenkins, puis, après avoir attribué un nom, l'option "Pipeline" doit être choisie :
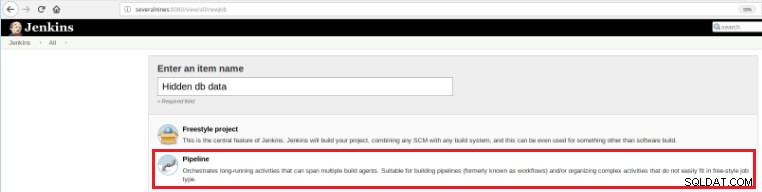 Figure 5 - Élément de pipeline dans Jenkins
Figure 5 - Élément de pipeline dans Jenkins Une fois le travail enregistré dans la section « Pipeline », dans l'onglet « Options avancées du projet », le champ « Définition » doit être défini sur « Script de pipeline », comme indiqué ci-dessous :
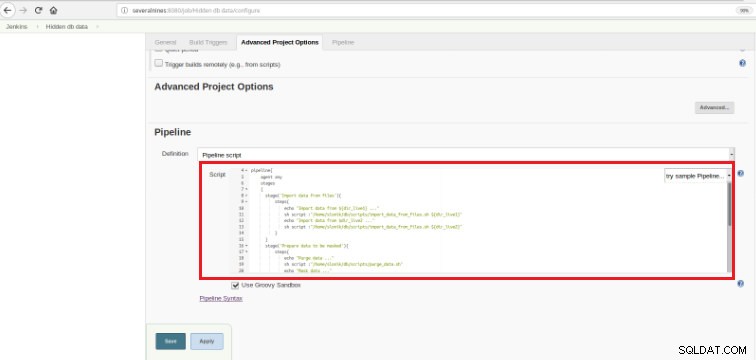 Figure 6 - Script Groovy dans la section pipeline
Figure 6 - Script Groovy dans la section pipeline Comme je l'ai mentionné au début du chapitre, le script Groovy utilisé est composé de trois étapes, cela signifie trois parties distinctes (étapes), comme présenté dans le script suivant :
def dir_live1='/data/ftp/server1'
def dir_live2='/data/ftp/server2'
pipeline{
agent any
stages
{
stage('Import data from files'){
steps{
echo "Import data from ${dir_live1} ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live1}"
echo "Import data from $dir_live2 ..."
sh script :"/home/slonik/db/scripts/import_data_from_files.sh ${dir_live2}"
}
}
stage('Prepare data to be masked'){
steps{
echo "Purge data ..."
sh script :"/home/slonik/db/scripts/purge_data.sh"
echo "Mask data ..."
sh script :"/home/slonik/db/scripts/mask_data.sh"
}
}
stage('Backup of database with data masked'){
steps{
echo "Backup database after masking ..."
sh script :"/home/slonik/db/scripts/backup_db.sh"
}
}
}
}Groovy est un langage de programmation orienté objet compatible avec la syntaxe Java pour la plate-forme Java. C'est à la fois un langage statique et dynamique avec des fonctionnalités similaires à celles de Python, Ruby, Perl et Smalltalk.
C'est facile à comprendre puisque ce genre de script se base sur quelques énoncés…
Étape
Signifie les 3 processus qui seront exécutés :"Importer des données à partir de fichiers", "Préparer les données à masquer"
et "Sauvegarde de la base de données avec des données masquées".
Étape
Une « étape » (souvent appelée « étape de construction ») est une tâche unique qui fait partie d'une séquence. Chaque étape peut être composée de plusieurs étapes. Dans cet exemple, la première étape comporte deux étapes.
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server1'
sh script :"/home/slonik/db/scripts/import_data_from_files.sh '/data/ftp/server2'Les données sont importées de deux sources distinctes.
Dans l'exemple précédent, il est important de noter qu'il y a deux variables définies au début et avec une portée globale :
dir_live1
dir_live2Les scripts utilisés dans ces trois étapes appellent le psql , pg_restore et pg_dump utilitaires.
Une fois le job défini, il est temps de l'exécuter et pour cela, il suffit de cliquer sur l'option « Build Now » :
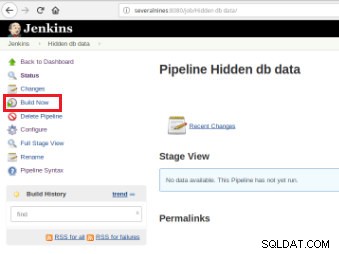 Figure 7 – Tâche d'exécution
Figure 7 – Tâche d'exécution Après le démarrage de la construction, il est possible de vérifier sa progression.
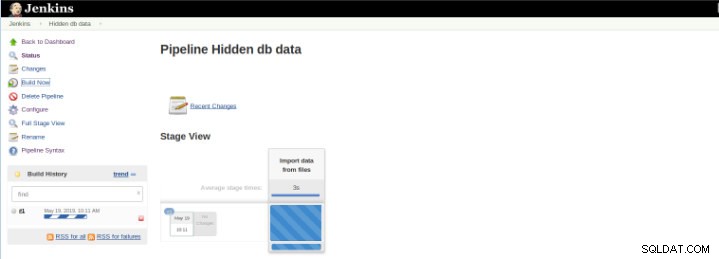 Figure 8 – Démarrage de « Build »
Figure 8 – Démarrage de « Build » Le plug-in Pipeline Stage View inclut une visualisation étendue de l'historique de construction de Pipeline sur la page d'index d'un projet de flux sous Stage View. Cette vue est construite dès que les tâches sont terminées et chaque tâche est représentée par une colonne de gauche à droite et il est possible de visualiser et de comparer le temps écoulé pour les exécutions de serval (connu sous le nom de Build dans Jenkins).
Une fois l'exécution (également appelée Build) terminée, il est possible d'obtenir des détails supplémentaires en cliquant sur le fil terminé (boîte rouge).
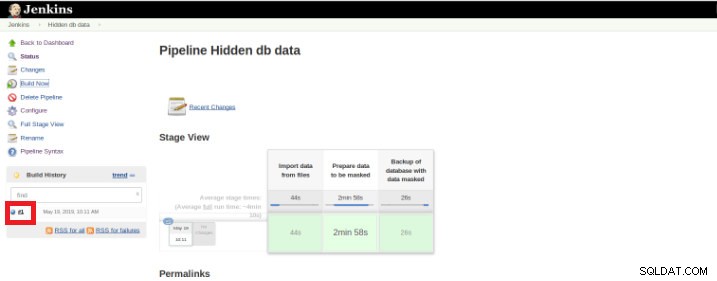 Figure 9 – Démarrage de « Build »
Figure 9 – Démarrage de « Build » puis dans l'option "Sortie de la console".
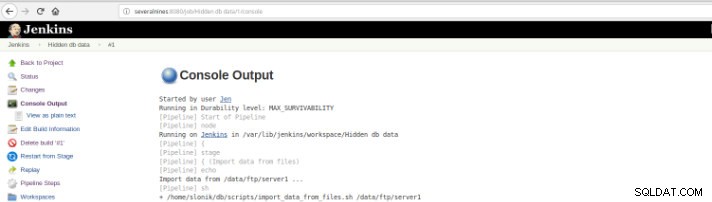 Figure 10 – Sortie de la console
Figure 10 – Sortie de la console Les vues précédentes sont d'une extrême utilité puisqu'elles permettent d'avoir une perception du temps d'exécution nécessaire à chaque étape.
Pipelines, également connu sous le nom de workflow, c'est un plugin qui permet la définition du cycle de vie de l'application et c'est une fonctionnalité utilisée dans Jenkins pour la livraison continue (CD).vCe plugin a été construit avec des exigences pour une capacité de workflow de CD flexible, extensible et basée sur des scripts à l'esprit.
Cet exemple consiste à masquer des données sensibles, mais il existe bien sûr de nombreux autres exemples quotidiens d'administrateur de base de données PostgreSQL pouvant être exécutés sur un travail de pipeline.
Pipeline est disponible sur Jenkins depuis la version 2.0 et c'est une solution incroyable !

Intégration continue (CI) pour les développements PL/pgSQL
L'intégration continue pour le développement de la base de données n'est pas aussi simple que dans d'autres langages de programmation en raison des données qui peuvent être perdues, il n'est donc pas facile de garder la base de données sous contrôle de source et de la déployer sur un serveur dédié, en particulier une fois qu'il y a des scripts qui contiennent des instructions DDL (Data Definition Language) et DML (Data Manipulation Language). En effet, ces types d'instructions modifient l'état actuel de la base de données et, contrairement à d'autres langages de programmation, il n'y a pas de code source à compiler.
D'autre part, il existe un ensemble d'instructions de base de données pour lesquelles il est possible l'intégration continue comme pour d'autres langages de programmation.
Cet exemple est basé uniquement sur le développement de procédures et il illustrera le déclenchement d'un ensemble de tests (écrits en Python) par Jenkins une fois que les scripts PostgreSQL, sur lesquels sont stockés le code des fonctions suivantes, sont validés dans un dépôt de code.
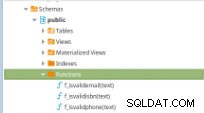 Figure 11 – Fonctions PLpg/SQL
Figure 11 – Fonctions PLpg/SQL Ces fonctions sont simples et son contenu n'a que peu de logique ou une requête en PLpg/SQL ou plperlu langue comme la fonction f_IsValidEmail :
CREATE OR REPLACE FUNCTION f_IsValidEmail(email text) RETURNS bool
LANGUAGE plperlu
AS $$
use Email::Address;
my @addresses = Email::Address->parse($_[0]);
return scalar(@addresses) > 0 ? 1 : 0;
$$;Toutes les fonctions présentées ici ne dépendent pas les unes des autres, et puis il n'y a pas de précédent ni dans son développement ni dans son déploiement. De plus, comme cela sera vérifié à l'avance, il n'y a aucune dépendance à leurs validations.
Ainsi, afin d'exécuter un ensemble de scripts de validation une fois qu'un commit est effectué dans un référentiel de code, il est nécessaire de créer une tâche de build (nouvel élément) dans Jenkins :
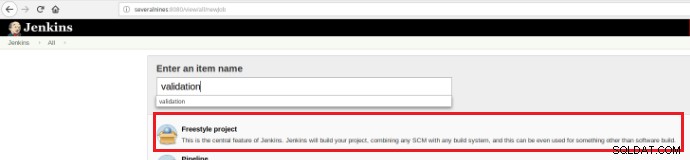 Figure 12 – Projet "Freestyle" pour l'Intégration Continue
Figure 12 – Projet "Freestyle" pour l'Intégration Continue Ce nouveau travail de build doit être créé en tant que projet « Freestyle » et dans la section « Référentiel du code source » doit être défini l'URL du référentiel et ses informations d'identification (case orange) :
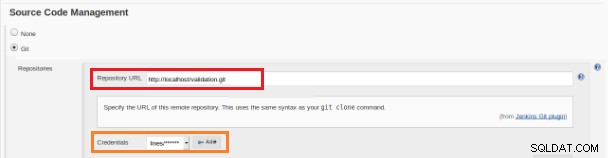 Figure 13 – Référentiel de code source
Figure 13 – Référentiel de code source Dans la section "Build Triggers" l'option "GitHub hook trigger for GITScm polling" doit être cochée :
 Figure 14 – Section « Générer des déclencheurs »
Figure 14 – Section « Générer des déclencheurs » Enfin, dans la section "Build", l'option "Execute Shell" doit être sélectionnée et dans la boîte de commande les scripts qui feront la validation des fonctions développées :
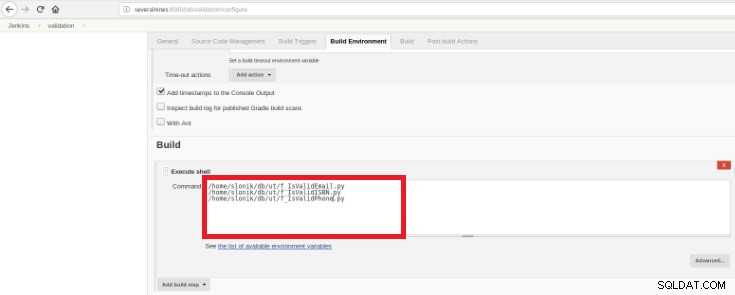 Figure 15 – Section « Environnement de construction »
Figure 15 – Section « Environnement de construction » Le but est d'avoir un script de validation pour chaque fonction développée.
Ce script Python a un ensemble simple d'instructions qui appelleront ces procédures à partir d'une base de données avec des résultats attendus prédéfinis :
#!/usr/bin/python
import psycopg2
con = psycopg2.connect(database="db_deploy", user="postgres", password="postgres10", host="localhost", port="5432")
cur = con.cursor()
email_list = { 'example@sqldat.com' : True,
'tintinmail.com' : False,
'example@sqldat.com' : False,
'director#mail.com': False,
'example@sqldat.com' : True
}
result_msg= "f_IsValidEmail -> OK"
for key in email_list:
cur.callproc('f_IsValidEmail', (key,))
row = cur.fetchone()
if email_list[key]!=row[0]:
result_msg= "f_IsValidEmail -> Nok"
print result_msg
cur.close()
con.close()Ce script testera le PLpg/SQL présenté ou plperlu fonctions et il sera exécuté après chaque commit dans le dépôt de code afin d'éviter les régressions sur les développements.
Une fois cette construction de tâche exécutée, les exécutions du journal peuvent être vérifiées.
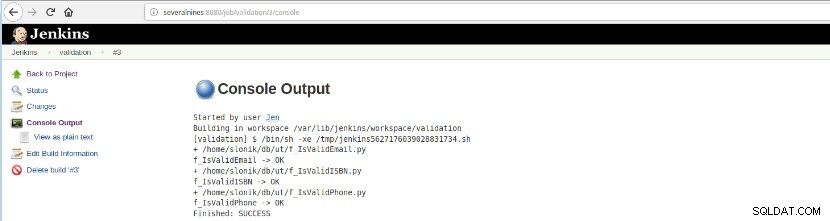 Figure 16 – "Sortie de la console"
Figure 16 – "Sortie de la console" Cette option présente le statut final :SUCCESS ou FAILURE, l'espace de travail, les fichiers/script exécutés, les fichiers temporaires créés et les messages d'erreur (pour ceux en échec) !
Conclusion
En résumé, Jenkins est connu comme un excellent outil pour l'intégration continue (CI) et la livraison continue (CD), cependant, il peut être utilisé pour diverses fonctionnalités telles que,
- Planification des tâches
- Exécution de scripts
- Processus de surveillance
À toutes ces fins, à chaque exécution (construire sur le vocabulaire Jenkins), il peut être analysé les journaux et le temps écoulé.
En raison d'un grand nombre de plugins disponibles, cela pourrait éviter certains développements dans un but précis, il existe probablement un plugin qui fait exactement ce que vous recherchez, il suffit de rechercher dans le centre de mise à jour ou Gérer Jenkins>> Gérer les plugins à l'intérieur l'application Web.