De nombreuses personnes utilisent les statistiques d'attente dans le cadre de leur méthodologie de dépannage des performances globales, tout comme moi, donc la question que je voulais explorer dans cet article concerne les types d'attente associés à la surcharge de l'observateur. Par surcharge d'observateur, j'entends l'impact sur le débit de la charge de travail SQL Server causé par SQL Profiler, les traces côté serveur ou les sessions d'événements étendus. Pour en savoir plus sur le sujet des frais généraux des observateurs, consultez les deux articles suivants de mon collègue Jonathan Kehayias :
- Mesure de la « surcharge de l'observateur » de SQL Trace par rapport aux événements étendus
- Impact de l'événement étendu query_post_execution_showplan dans SQL Server 2012
Donc, dans cet article, je voudrais passer en revue quelques variations de surcharge d'observateur et voir si nous pouvons trouver des types d'attente cohérents associés à la dégradation mesurée. Les utilisateurs de SQL Server implémentent le traçage dans leurs environnements de production de différentes manières. Vos résultats peuvent donc varier, mais je voulais couvrir quelques grandes catégories et rendre compte de ce que j'ai trouvé :
- Utilisation de la session du générateur de profils SQL
- Utilisation de la trace côté serveur
- Utilisation de la trace côté serveur, écriture sur un chemin d'E/S lent
- Utilisation d'événements étendus avec une cible de tampon en anneau
- Utilisation des événements étendus avec une cible de fichier
- Utilisation des événements étendus avec une cible de fichier sur un chemin d'E/S lent
- Utilisation d'événements étendus avec une cible de fichier sur un chemin d'E/S lent sans perte d'événement
Vous pouvez probablement imaginer d'autres variations sur le thème et je vous invite à partager toute découverte intéressante concernant les frais généraux des observateurs et les statistiques d'attente sous forme de commentaire dans cet article.
Référence
Pour le test, j'ai utilisé une machine virtuelle VMware avec quatre vCPU et 4 Go de RAM. Mon invité de machine virtuelle était sur des SSD OCZ Vertex. Le système d'exploitation était Windows Server 2008 R2 Enterprise et la version de SQL Server est 2012, SP1 CU4.
En ce qui concerne la "charge de travail", j'utilise une requête en lecture seule dans une boucle par rapport à l'exemple de base de données de crédit 2008, défini sur GO 10 000 000 fois.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 J'exécute également cette requête via 16 sessions simultanées. Le résultat final sur mon système de test est une utilisation de 100 % du processeur sur tous les vCPU de l'invité virtuel et une moyenne de 14 492 requêtes par lot par seconde sur une période de 2 minutes.
En ce qui concerne le traçage des événements, dans chaque test, j'ai utilisé Showplan XML Statistics Profile pour les tests de suivi SQL Profiler et côté serveur – et query_post_execution_showplan pour les sessions d'événements prolongés. Les événements du plan d'exécution sont très cher, c'est précisément pourquoi je les ai choisis afin que je puisse voir si dans des circonstances extrêmes je pouvais ou non dériver des thèmes de type attente.
Pour tester l'accumulation de type d'attente sur une période de test, j'ai utilisé la requête suivante. Rien d'extraordinaire :il suffit d'effacer les statistiques, d'attendre 2 minutes, puis de collecter les 10 accumulations d'attente les plus importantes pour l'instance SQL Server au cours de la période de test de dégradation :
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Remarquez que je ne suis pas filtrer les types d'attente en arrière-plan qui sont généralement filtrés, et c'est parce que je ne voulais pas éliminer quelque chose qui est normalement bénin - mais dans cette circonstance indique en fait un domaine réel à approfondir.
Session du profileur SQL
Le tableau suivant montre les requêtes par lot avant et après par seconde lors de l'activation d'un suivi de trace SQL Profiler local Showplan XML Statistics Profile (s'exécutant sur la même machine virtuelle que l'instance SQL Server) :
| Requêtes par lot de base par seconde (moyenne de 2 minutes) | Requêtes par lot de session du profileur SQL par seconde (moyenne de 2 minutes) |
|---|---|
| 14 492 | 1 416 |
Vous pouvez voir que la trace du SQL Profiler provoque une baisse significative du débit.
En ce qui concerne le temps d'attente accumulé au cours de cette même période, les principaux types d'attente étaient les suivants (comme pour le reste des tests de cet article, j'ai effectué quelques tests et le résultat était généralement cohérent) :
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| TRACEWRITE | 67 142 | 1 149 824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 313 | 180 449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 086 |
| LAZYWRITER_SLEEP | 120 | 120 059 |
| DIRTY_PAGE_POLL | 1 198 | 120 038 |
| HADR_WORK_QUEUE | 12 | 120 015 |
| LOGMGR_QUEUE | 937 | 120 011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 006 |
Le type d'attente qui me saute aux yeux est TRACEWRITE - qui est défini par la documentation en ligne comme un type d'attente qui "se produit lorsque le fournisseur de trace d'ensemble de lignes SQL Trace attend soit un tampon libre, soit un tampon avec des événements à traiter". Les autres types d'attente ressemblent à des types d'attente d'arrière-plan standard que l'on filtre généralement de votre ensemble de résultats. De plus, j'ai parlé d'un problème similaire avec le sur-traçage dans un article de 2011 intitulé Observer overhead - les périls d'un trop grand traçage - donc je connaissais ce type d'attente parfois pointant correctement les problèmes de surcharge des observateurs. Maintenant, dans ce cas particulier sur lequel j'ai blogué, ce n'était pas SQL Profiler, mais une autre application utilisant le fournisseur de trace d'ensemble de lignes (de manière inefficace).
Traçage côté serveur
C'était pour SQL Profiler, mais qu'en est-il de la surcharge de trace côté serveur ? Le tableau suivant montre les requêtes par lot avant et après par seconde lors de l'activation d'une trace locale côté serveur en écrivant dans un fichier :
| Requêtes par lot de base par seconde (moyenne de 2 minutes) | Requêtes par lot du profileur SQL par seconde (moyenne de 2 minutes) |
|---|---|
| 14 492 | 4 015 |
Les principaux types d'attente étaient les suivants (j'ai effectué quelques tests et le résultat était cohérent) :
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 015 |
| SLEEP_TASK | 253 | 180 871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 046 |
| HADR_WORK_QUEUE | 12 | 120 042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 021 |
| XE_DISPATCHER_WAIT | 3 | 120 006 |
| ATTENDRE | 1 | 120 000 |
| LOGMGR_QUEUE | 931 | 119 993 |
| DIRTY_PAGE_POLL | 1 193 | 119 958 |
| XE_TIMER_EVENT | 55 | 119 954 |
Cette fois, nous ne voyons pas TRACEWRITE (nous utilisons maintenant un fournisseur de fichiers) et l'autre type d'attente lié à la trace, le SQLTRACE_INCREMENTAL_FLUSH_SLEEP non documenté a grimpé - mais par rapport au premier test, a un temps d'attente accumulé très similaire (120 046 contre 120 006) - et ma collègue Erin Stellato (@erinstellato) a parlé de ce type d'attente particulier dans son article Déterminer quand les statistiques d'attente ont été effacées pour la dernière fois . Donc, en regardant les autres types d'attente, aucun n'apparaît comme un signal d'alarme fiable.
Écriture de la trace côté serveur sur un chemin d'E/S lent
Et si nous mettions le fichier de trace côté serveur sur un disque lent ? Le tableau suivant montre les requêtes par lot avant et après par seconde lors de l'activation d'une trace locale côté serveur qui écrit dans un fichier sur une clé USB :
| Requêtes par lot de base par seconde (moyenne de 2 minutes) | Requêtes par lot du profileur SQL par seconde (moyenne de 2 minutes) |
|---|---|
| 14 492 | 260 |
Comme nous pouvons le voir - les performances sont considérablement dégradées - même par rapport au test précédent.
Les principaux types d'attente étaient les suivants :
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351 174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2 273 | 299 995 |
| SLEEP_TASK | 240 | 194 264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181 458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125 007 |
| LAZYWRITER_SLEEP | 63 | 124 437 |
| LOGMGR_QUEUE | 941 | 120 559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120 516 |
| ATTENDRE | 1 | 120 515 |
| DIRTY_PAGE_POLL | 1 204 | 120 513 |
Un type d'attente qui saute pour ce test est le SQLTRACE_FILE_BUFFER non documenté . Pas beaucoup de documentation sur celui-ci, mais sur la base du nom, nous pouvons faire une supposition éclairée (surtout compte tenu de la configuration de ce test particulier).
Événements étendus à la cible du tampon en anneau
Passons maintenant en revue les résultats pour les équivalents de session d'événement prolongé. J'ai utilisé la définition de session suivante :
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
Le tableau suivant montre les requêtes par lot avant et après par seconde lors de l'activation d'une session XE avec une cible de tampon en anneau (capturant le query_post_execution_showplan événement):
| Requêtes par lot de base par seconde (moyenne de 2 minutes) | Requêtes par lot du profileur SQL par seconde (moyenne de 2 minutes) |
|---|---|
| 14 492 | 4 737 |
Les principaux types d'attente étaient les suivants :
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299 992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 006 |
| SLEEP_TASK | 240 | 181 739 |
| LAZYWRITER_SLEEP | 120 | 120 219 |
| HADR_WORK_QUEUE | 12 | 120 038 |
| DIRTY_PAGE_POLL | 1 198 | 120 035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 011 |
| LOGMGR_QUEUE | 936 | 120 008 |
| ATTENDRE | 1 | 120 001 |
Rien n'a sauté comme lié à XE, seulement le "bruit" de tâche en arrière-plan.
Événements étendus à un fichier cible
Qu'en est-il de la modification de la session pour utiliser une cible de fichier au lieu d'une cible de tampon en anneau ? Le tableau suivant montre les requêtes par lot avant et après par seconde lors de l'activation d'une session XE avec une cible de fichier au lieu d'une cible de tampon en anneau :
| Requêtes par lot de base par seconde (moyenne de 2 minutes) | Requêtes par lot du profileur SQL par seconde (moyenne de 2 minutes) |
|---|---|
| 14 492 | 4 299 |
Les principaux types d'attente étaient les suivants :
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2 103 | 299 996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 253 | 180 663 |
| LAZYWRITER_SLEEP | 120 | 120 187 |
| HADR_WORK_QUEUE | 12 | 120 029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| ATTENDRE | 1 | 120 001 |
| XE_TIMER_EVENT | 59 | 119 966 |
| LOGMGR_QUEUE | 935 | 119 957 |
Rien, à l'exception de XE_TIMER_EVENT , a sauté comme lié à XE. Le référentiel de types d'attente de Bob Ward désigne celui-ci comme sûr à ignorer à moins qu'il n'y ait quelque chose de mal possible - mais de manière réaliste, remarqueriez-vous ce type d'attente généralement bénin s'il était en 9 place sur votre système lors d'une dégradation des performances ? Et si vous le filtrez déjà en raison de sa nature normalement bénigne ?
Événements étendus vers une cible de fichier de chemin d'E/S lente
Et maintenant, que se passe-t-il si je mets le fichier sur un chemin d'E/S lent ? Le tableau suivant montre les requêtes par lot avant et après par seconde lors de l'activation d'une session XE avec une cible de fichier sur une clé USB :
| Requêtes par lot de base par seconde (moyenne de 2 minutes) | Requêtes par lot du profileur SQL par seconde (moyenne de 2 minutes) |
|---|---|
| 14 492 | 4 386 |
Les principaux types d'attente étaient les suivants :
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 046 |
| SLEEP_TASK | 253 | 180 719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120 427 |
| LAZYWRITER_SLEEP | 120 | 120 190 |
| HADR_WORK_QUEUE | 12 | 120 025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 011 |
| ATTENDRE | 1 | 120 002 |
| DIRTY_PAGE_POLL | 1 197 | 119 977 |
| XE_TIMER_EVENT | 59 | 119 949 |
Encore une fois, rien de lié à XE ne saute à l'exception du XE_TIMER_EVENT .
Événements étendus vers une cible de fichier de chemin d'E/S lente, aucune perte d'événement
Le tableau suivant montre les requêtes par lot avant et après par seconde lors de l'activation d'une session XE avec une cible de fichier sur une clé USB, mais cette fois sans autoriser la perte d'événements (EVENT_RETENTION_MODE=NO_EVENT_LOSS) - ce qui n'est pas recommandé et vous verrez dans les résultats pourquoi cela pourrait être :
| Requêtes par lot de base par seconde (moyenne de 2 minutes) | Requêtes par lot du profileur SQL par seconde (moyenne de 2 minutes) |
|---|---|
| 14 492 | 539 |
Les principaux types d'attente étaient les suivants :
| wait_type | waiting_tasks_count | wait_time_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8 773 | 1 707 845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237 003 |
| SLEEP_TASK | 337 | 180 446 |
| LAZYWRITER_SLEEP | 120 | 120 032 |
| DIRTY_PAGE_POLL | 1 198 | 120 026 |
| HADR_WORK_QUEUE | 12 | 120 009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120 007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120 006 |
| ATTENDRE | 1 | 120 000 |
| XE_TIMER_EVENT | 59 | 119 944 |
Avec la réduction extrême du débit, nous voyons XE_BUFFERMGR_FREEBUF_EVENT passer au premier rang de nos résultats cumulés sur les temps d'attente. Celui-ci est documenté dans la documentation en ligne, et Microsoft nous indique que cet événement est associé à des sessions XE configurées pour aucune perte d'événement, et où tous les tampons de la session sont pleins.
Impact des observateurs
Mis à part les types d'attente, il était intéressant de noter l'impact de chaque méthode d'observation sur la capacité de notre charge de travail à traiter les requêtes par lots :
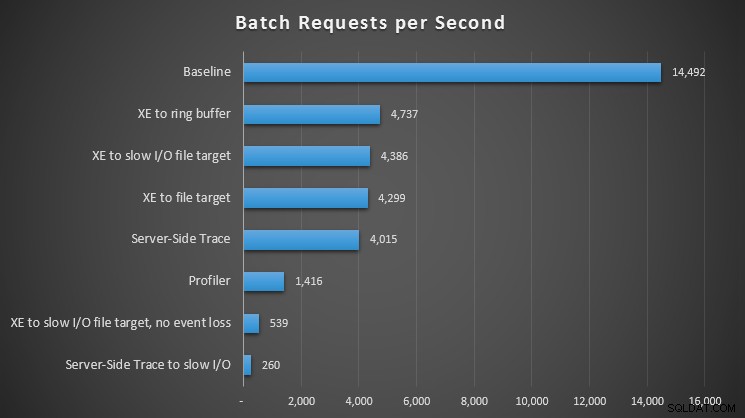
Impact des différentes méthodes d'observation sur les requêtes par seconde
Pour toutes les approches, il y a eu un impact significatif - mais pas choquant - par rapport à notre référence (aucune observation) ; le plus de douleur, cependant, a été ressenti lors de l'utilisation de Profiler, lors de l'utilisation de la trace côté serveur vers un chemin d'E/S lent, ou d'événements étendus vers une cible de fichier sur un chemin d'E/S lent, mais uniquement lorsqu'il est configuré pour aucune perte d'événement. Avec la perte d'événements, cette configuration a en fait fonctionné de la même manière qu'une cible de fichier vers un chemin d'E/S rapide, probablement parce qu'elle a pu supprimer beaucoup plus d'événements.
Résumé
Je n'ai pas testé tous les scénarios possibles et il existe certainement d'autres combinaisons intéressantes (sans parler des différents comportements basés sur la version de SQL Server), mais la principale conclusion que je retiens de cette exploration est que vous ne pouvez pas toujours compter sur une accumulation évidente de type d'attente pointeur face à un scénario de surcharge d'observateur. Sur la base des tests de cet article, seuls trois scénarios sur sept ont manifesté un type d'attente spécifique qui pourrait potentiellement vous aider à vous orienter dans la bonne direction. Même alors - ces tests étaient sur un système contrôlé - et souvent les gens filtrent les types d'attente susmentionnés en tant que types d'antécédents bénins - de sorte que vous ne les voyez peut-être pas du tout.
Compte tenu de cela, que pouvez-vous faire? Pour une dégradation des performances sans symptômes clairs ou évidents, je recommande d'élargir la portée pour poser des questions sur les traces et les sessions XE (en aparté - je recommande également d'élargir votre portée si le système est virtualisé ou peut avoir des options d'alimentation incorrectes). Par exemple, dans le cadre du dépannage d'un système, vérifiez sys.[traces] et sys.[dm_xe_sessions] pour voir si quelque chose est en cours d'exécution sur le système qui est inattendu. Il s'agit d'une couche supplémentaire par rapport à ce dont vous devez vous soucier, mais effectuer quelques validations rapides peut vous faire gagner beaucoup de temps.