Un événement récurrent, par définition, est un événement qui se répète à un intervalle; on l'appelle aussi un événement périodique. Il existe de nombreuses applications qui permettent à leurs utilisateurs de configurer des événements récurrents. Comment un système de base de données gère-t-il les événements récurrents ? Dans cet article, nous allons explorer une manière de les gérer.
La récurrence n'est pas facile à gérer pour les applications. Cela peut devenir une tâche ardue, en particulier lorsqu'il s'agit de couvrir tous les scénarios récurrents possibles, y compris la création d'événements bihebdomadaires ou trimestriels ou la possibilité de reprogrammer toutes les instances d'événements futurs.
Deux façons de gérer les événements récurrents
Je peux penser à au moins deux façons de gérer les tâches périodiques dans un modèle de données. Avant d'en discuter, passons rapidement en revue les exigences de cette tâche. En bref, une gestion efficace signifie :
- Les utilisateurs sont autorisés à créer des événements réguliers et récurrents.
- Des événements quotidiens, hebdomadaires, bihebdomadaires, mensuels, trimestriels, biannuels et annuels peuvent être créés sans restriction de date de fin.
- Les utilisateurs peuvent reprogrammer ou annuler une instance d'un événement ou toutes les instances futures d'un événement.
Compte tenu de ces paramètres, deux façons de gérer les événements récurrents dans le modèle de données viennent à l'esprit. Nous les appellerons la voie naïve et la voie experte.
La méthode naïve : Stockage de toutes les instances récurrentes possibles d'un événement sous forme de lignes distinctes dans une table. Dans cette solution, nous n'avons besoin que d'une seule table, à savoir event . Ce tableau contient des colonnes telles que event_title , start_date , end_date , is_full_day_event , etc. La start_date et end_date les colonnes sont des types de données d'horodatage ; de cette façon, ils peuvent accueillir des événements qui ne durent pas toute la journée.
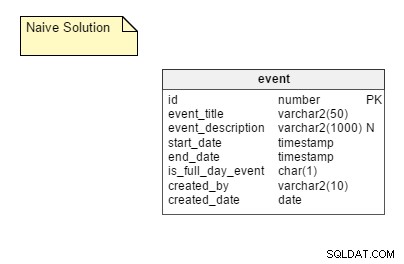
Les avantages : C'est une approche assez simple et la plus simple à mettre en œuvre.
Les inconvénients : La méthode naïve présente des inconvénients importants, notamment :
- La nécessité de stocker toutes les instances possibles d'un événement. Si vous tenez compte des besoins d'une large base d'utilisateurs, une grande partie de l'espace est nécessaire. Cependant, l'espace est assez bon marché, donc ce point n'a pas d'impact majeur.
- Un processus de mise à jour très compliqué. Supposons qu'un événement soit reprogrammé. Dans ce cas, quelqu'un doit mettre à jour toutes les instances de celui-ci. Un grand nombre d'opérations DML doivent être effectuées lors de la replanification, ce qui a un impact négatif sur les performances de l'application.
- Gestion des exceptions. Toutes les exceptions doivent être gérées avec élégance, surtout si vous devez revenir en arrière et modifier le rendez-vous d'origine après avoir fait une exception. Par exemple, supposons que vous avanciez d'un jour la troisième instance d'un événement récurrent. Que se passe-t-il si vous modifiez ultérieurement l'heure de l'événement d'origine ? Réinsérez-vous un autre événement le jour d'origine et laissez-vous celui que vous avez avancé ? Dissocier l'exception ? Essayez de le modifier de manière appropriée ?
Event_id– Cette colonne est référencée depuis leeventtable, et il agit comme la clé primaire dans cette table. Il montre la relation d'identification entreeventetrecurring_patternles tables. Cette colonne garantira également qu'il existe au maximum un modèle récurrent pour chaque événement.Recurring_type_id– Cette colonne indique le type de récurrence, qu'elle soit quotidienne, hebdomadaire, mensuelle ou annuelle.Max_num_of_occurrances– Il y a des moments où nous ne connaissons pas la date de fin exacte d'un événement mais nous savons combien d'occurrences (réunions) sont nécessaires pour le terminer. Cette colonne stocke un nombre arbitraire qui définit la fin logique d'un événement.Separation_count– Vous vous demandez peut-être comment un événement bihebdomadaire ou biannuel peut être configuré s'il n'y a que quatre valeurs de type de récurrence possibles (quotidienne, hebdomadaire, mensuelle, annuelle). La réponse est leseparation_countcolonne. Cette colonne indique l'intervalle (en jours, semaines ou mois) avant que la prochaine instance d'événement ne soit autorisée. Par exemple, si un événement doit être configuré toutes les deux semaines, alors separation_count ="1" pour répondre à cette exigence. La valeur par défaut de cette colonne est "0".- Le
recurring_type_idserait "hebdomadaire". - Le
separation_countserait "1". - Le
day_of_weekserait "2". Week_of_month- Cette colonne est pour les événements qui sont programmés pour une certaine semaine du mois - c'est-à-dire le premier, l'avant-dernier, le dernier, l'avant-dernier, etc. Nous pouvons stocker ces valeurs sous la forme 1,2,3, 4,.. (à partir de début du mois) ou -1,-2,-3,... (à compter de la fin du mois).Day_of_month– Il y a des cas où un événement est programmé un jour particulier du mois, disons le 25. Cette colonne répond à cette exigence. Commeweek_of_month, il peut être rempli avec des nombres positifs ("7" pour le 7ème jour à partir du début du mois) ou des nombres négatifs ("-7" pour le septième jour à partir de la fin du mois).- Le
recurring_type_idserait "mensuel". - Le
separation_countserait "2". - Le
day_of_monthserait "11". - Toutes les colonnes restantes seraient nulles.
- Événements qui se produisent pendant les vacances. Lorsqu'une instance particulière d'un événement se produit un jour férié, doit-elle être automatiquement déplacée vers le jour ouvrable suivant immédiatement le jour férié ? Ou devrait-il être automatiquement annulé ? Dans quelles circonstances l'une ou l'autre de ces conditions s'appliquerait-elle ?
- Conflits entre événements. Que se passe-t-il si certains événements (qui s'excluent mutuellement) se produisent le même jour ?
La méthode experte : Stocker un modèle récurrent et générer des instances d'événements passés et futurs par programmation. Cette solution résout les inconvénients de la solution naïve. Nous expliquerons la solution experte en détail dans cet article.
Le modèle proposé
Créer des événements
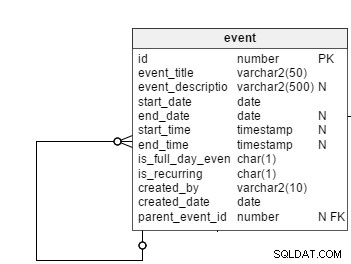
Tous les événements programmés, qu'ils soient réguliers ou récurrents, sont enregistrés dans le event table. Tous les événements ne sont pas des événements récurrents, nous aurons donc besoin d'une colonne d'indicateur, is_recurring , dans ce tableau pour spécifier explicitement les événements récurrents. Le event_title et event_description les colonnes stockent le sujet et un bref résumé des événements. Les descriptions d'événements sont facultatives, c'est pourquoi cette colonne est nullable.
Comme leur nom l'indique, la start_date et end_date les colonnes conservent les dates de début et de fin des événements. Dans le cas d'événements réguliers, ces colonnes stockent les dates de début et de fin réelles. Cependant, ils stockent également les dates des premières et dernières occurrences d'événements périodiques. Nous conserverons la end_date colonne comme nullable, puisque les utilisateurs peuvent configurer des événements récurrents sans date de fin. Dans ce cas, les occurrences futures jusqu'à une date de fin hypothétique (disons pendant un an) seraient affichées dans l'interface utilisateur.
Le is_full_date_event la colonne indique si un événement est un événement d'une journée entière. Dans le cas d'un événement d'une journée complète, le start_time et end_time les colonnes seraient nulles ; c'est la raison de garder ces deux colonnes nullables.
Le created_by et created_date les colonnes stockent quel utilisateur a créé un événement et la date à laquelle cet événement a été créé.
Ensuite, il y a le parent_event_id colonne. Cela joue un rôle majeur dans notre modèle de données. J'expliquerai sa signification plus tard.
Gérer les récurrences
Nous arrivons maintenant directement à l'énoncé principal du problème :que se passe-t-il si un événement récurrent est créé dans l'event table - c'est-à-dire le is_recurring drapeau pour l'événement est "Y" ?
Comme expliqué précédemment, nous allons stocker un modèle récurrent pour les événements afin de pouvoir construire toutes ses occurrences futures. Commençons par créer le recurring_pattern table. Ce tableau comporte les colonnes suivantes :
Considérons l'importance des colonnes restantes en termes de différents types de récurrences.
Récurrence quotidienne
Avons-nous vraiment besoin de capturer un modèle pour un événement récurrent quotidien ? Non, car tous les détails requis pour générer un modèle de récurrence quotidien sont déjà enregistrés dans l'événement event tableau.
Le seul scénario qui nécessite un modèle est lorsque les événements sont planifiés pour des jours alternés ou tous les X jours. Dans ce cas, le separation_count nous aidera à comprendre le modèle de récurrence et à dériver d'autres instances.
Récurrence hebdomadaire
Nous avons besoin d'une seule colonne supplémentaire, day_of_week , pour mémoriser quel jour de la semaine cet événement aura lieu. En supposant que lundi est le premier jour de la semaine et que dimanche est le dernier, les valeurs possibles seraient 1, 2, 3, 4, 5, 6 et 7. Des modifications appropriées dans le code qui génère des occurrences d'événements individuels doivent être apportées si nécessaire. Toutes les colonnes restantes seraient nulles pour les événements hebdomadaires.
Prenons un type classique d'événement hebdomadaire :l'occurrence bihebdomadaire. Dans ce cas, nous dirons que cela se produit une semaine sur deux un mardi, le deuxième jour de la semaine. Donc :

Récurrence mensuelle
Outre day_of_week , nous avons besoin de deux colonnes supplémentaires pour répondre à tout scénario de récurrence mensuelle. En bref, ces colonnes sont :
Considérons maintenant un exemple plus compliqué - un événement trimestriel. Supposons qu'une entreprise planifie un événement de projection de résultats trimestriels pour le 11e jour du premier mois de chaque trimestre (généralement janvier, avril, juillet et octobre). Donc dans ce cas :
Dans l'exemple ci-dessus, nous supposons que l'utilisateur crée la projection des résultats trimestriels en janvier. Veuillez noter que cette logique de séparation commencera à compter à partir du mois, de la semaine ou du jour où l'événement est créé.
Sur des lignes similaires, les événements semestriels peuvent être enregistrés comme des événements mensuels avec un
La récurrence annuelle est assez simple. Nous avons des colonnes pour des jours particuliers de la semaine et du mois, nous n'avons donc besoin que d'une colonne supplémentaire pour le mois de l'année. Nous avons nommé cette colonne
Venons-en maintenant aux exceptions. Que se passe-t-il si une instance particulière d'un événement récurrent est annulée ou reprogrammée ? Toutes ces instances sont enregistrées séparément dans le
Examinons deux colonnes,
Hormis ces deux colonnes, toutes les colonnes restantes agissent de la même manière que dans le
Il existe des applications qui permettent aux utilisateurs de reprogrammer toutes les instances futures d'un événement récurrent. Dans de tels cas, nous avons deux options. Nous pouvons stocker toutes les instances futures dans
Avec cette solution, nous pouvons obtenir toutes les occurrences passées d'un événement, même lorsque son modèle de récurrence a été modifié.
Il existe des domaines plus complexes autour des événements récurrents dont nous n'avons pas discuté. En voici deux :
Quels changements devons-nous apporter pour intégrer ces capacités ? Veuillez nous faire part de votre point de vue dans la section des commentaires.separation_count de "5".
Récurrence annuelle
month_of_year .
Gérer les exceptions d'événements récurrents
event_instance_exception table. Is_rescheduled et is_cancelled . Ces colonnes indiquent si cette instance est reprogrammée à une date/heure ultérieure ou annulée complètement. Pourquoi ai-je deux colonnes distinctes pour cela ? Eh bien, pensez aux événements qui ont d'abord été reprogrammés puis complètement annulés. Cela se produit, et nous avons un moyen de l'enregistrer avec ces colonnes. event tableau.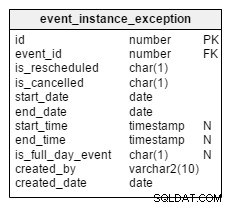
Pourquoi lier deux événements au moyen de
parent_event_id ?event_instance_exception (indice :pas une solution acceptable). Ou nous pouvons créer un nouvel événement avec de nouveaux paramètres de date/heure dans le event table et liez-la à son événement précédent (l'événement parent) au moyen du id_parent_event colonne. Comment améliorer la gestion des événements récurrents ?



