Dans mon dernier article, nous avons vu comment une requête comportant un agrégat scalaire pouvait être transformée par l'optimiseur en une forme plus efficace. Pour rappel, voici à nouveau le schéma :
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Choix de plans
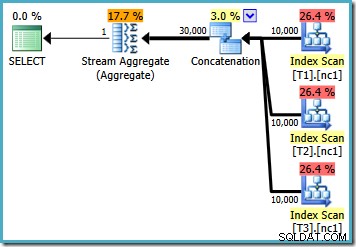
Avec 10 000 lignes dans chacune des tables de base, l'optimiseur propose un plan simple qui calcule le maximum en lisant les 30 000 lignes dans un agrégat :
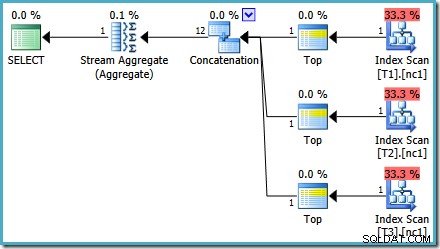
Avec 50 000 lignes dans chaque table, l'optimiseur passe un peu plus de temps sur le problème et trouve un plan plus intelligent. Il lit uniquement la ligne du haut (par ordre décroissant) de chaque index, puis calcule le maximum à partir de ces 3 lignes uniquement :
Un bogue de l'optimiseur
Vous remarquerez peut-être quelque chose d'un peu étrange à propos de cette estimation plan. L'opérateur de concaténation lit une ligne à partir de trois tables et produit en quelque sorte douze lignes ! Il s'agit d'une erreur causée par un bogue dans l'estimation de la cardinalité que j'ai signalé en mai 2011. Il n'est toujours pas corrigé à partir de SQL Server 2014 CTP 1 (même si le nouvel estimateur de cardinalité est utilisé) mais j'espère qu'il sera résolu pour le version finale.
Pour voir comment l'erreur se produit, rappelez-vous que l'une des alternatives de plan envisagées par l'optimiseur pour le cas de 50 000 lignes comporte des agrégats partiels sous l'opérateur de concaténation :
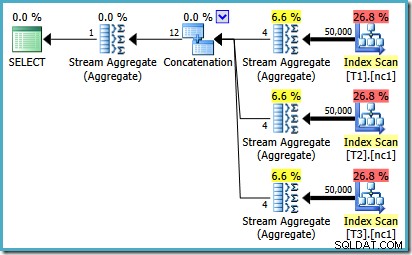
C'est l'estimation de cardinalité pour ces MAX partiels agrégats qui est en faute. Ils estiment quatre lignes où le résultat est garanti d'être une ligne. Vous pouvez voir un nombre autre que quatre - cela dépend du nombre de processeurs logiques disponibles pour l'optimiseur au moment de la compilation du plan (voir le lien du bogue ci-dessus pour plus de détails).
L'optimiseur remplace ensuite les agrégats partiels par des opérateurs Top (1), qui recalculent correctement l'estimation de cardinalité. Malheureusement, l'opérateur de concaténation reflète toujours les estimations des agrégats partiels remplacés (3 * 4 =12). En conséquence, nous nous retrouvons avec une concaténation qui lit 3 lignes et en produit 12.
Utiliser TOP au lieu de MAX
En regardant à nouveau le plan de 50 000 lignes, il semble que la plus grande amélioration trouvée par l'optimiseur consiste à utiliser les opérateurs Top (1) au lieu de lire toutes les lignes et de calculer la valeur maximale en utilisant la force brute. Que se passe-t-il si nous essayons quelque chose de similaire et réécrivons explicitement la requête en utilisant Top ?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Le plan d'exécution de la nouvelle requête est :
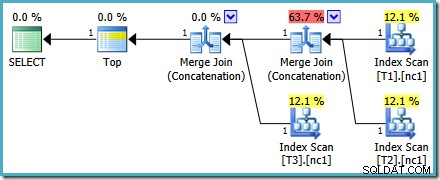
Ce plan est assez différent de celui choisi par l'optimiseur pour le MAX requête. Il comporte trois parcours d'index ordonnés, deux jointures par fusion fonctionnant en mode concaténation et un seul opérateur supérieur. Ce nouveau plan de requête comporte des fonctionnalités intéressantes qui méritent d'être examinées en détail.
Analyse du plan
La première ligne (dans l'ordre décroissant de l'index) est lue à partir de l'index non cluster de chaque table, et une jointure par fusion fonctionnant en mode concaténation est utilisée. Bien que l'opérateur Merge Join n'effectue pas une jointure au sens normal du terme, l'algorithme de traitement de cet opérateur est facilement adapté pour concaténer ses entrées au lieu d'appliquer des critères de jointure.
L'avantage d'utiliser cet opérateur dans le nouveau plan est que la concaténation de fusion préserve l'ordre de tri dans ses entrées. En revanche, un opérateur de concaténation régulier lit ses entrées en séquence. Le schéma ci-dessous illustre la différence (cliquez pour agrandir) :
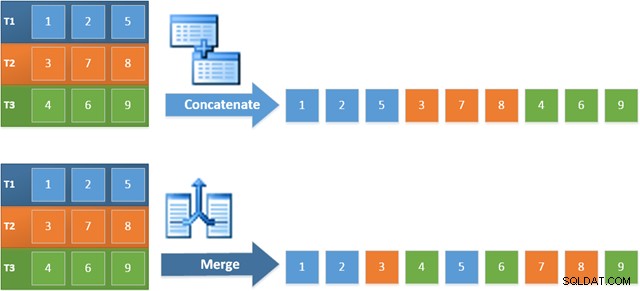
Le comportement de préservation de l'ordre de la concaténation de fusion signifie que la première ligne produite par l'opérateur de fusion le plus à gauche dans le nouveau plan est garantie d'être la ligne avec la valeur la plus élevée dans la colonne c1 dans les trois tables. Plus précisément, le plan fonctionne comme suit :
- Une ligne est lu à partir de chaque table (dans l'ordre décroissant de l'index) ; et
- Chaque fusion effectue un test pour voir laquelle de ses lignes d'entrée a la valeur la plus élevée
Cela semble être une stratégie très efficace, il peut donc sembler étrange que le MAX de l'optimiseur plan a un coût estimé à moins de la moitié du nouveau plan. Dans une large mesure, la raison en est que la concaténation de fusion préservant l'ordre est supposée être plus coûteuse qu'une simple concaténation. L'optimiseur ne se rend pas compte que chaque fusion ne peut voir qu'un maximum d'une ligne et surestime son coût en conséquence.
Autres problèmes de coût
Strictement parlant, nous ne comparons pas ici des pommes avec des pommes, car les deux plans concernent des requêtes différentes. Comparer des coûts comme celui-ci n'est généralement pas une chose valable à faire, bien que SSMS fasse exactement cela en affichant des pourcentages de coût pour différentes déclarations dans un lot. Mais je m'égare.
Si vous regardez le nouveau plan dans SSMS au lieu de SQL Sentry Plan Explorer, vous verrez quelque chose comme ceci :
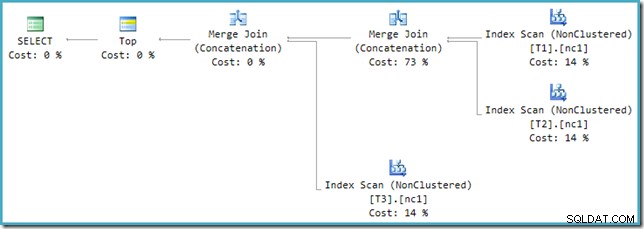
L'un des opérateurs Merge Join Concatenation a un coût estimé à 73 % tandis que le second (opérant sur exactement le même nombre de lignes) est présenté comme ne coûtant rien du tout. Un autre signe que quelque chose ne va pas ici est que les pourcentages de coût de l'opérateur dans ce plan ne totalisent pas 100 %.
Optimiseur contre moteur d'exécution
Le problème réside dans une incompatibilité entre l'optimiseur et le moteur d'exécution. Dans l'optimiseur, Union et Union All peuvent avoir 2 entrées ou plus. Dans le moteur d'exécution, seul l'opérateur Concaténation est capable d'accepter 2 ou plus contributions; La jointure par fusion nécessite exactement deux entrées, même lorsqu'elles sont configurées pour effectuer une concaténation plutôt qu'une jointure.
Pour résoudre cette incompatibilité, une réécriture post-optimisation est appliquée pour traduire l'arborescence de sortie de l'optimiseur dans une forme que le moteur d'exécution peut gérer. Lorsqu'une Union ou Union All avec plus de deux entrées est implémentée à l'aide de Merge, une chaîne d'opérateurs est nécessaire. Avec trois entrées dans l'Union All dans le cas présent, deux Unions de fusion sont nécessaires :
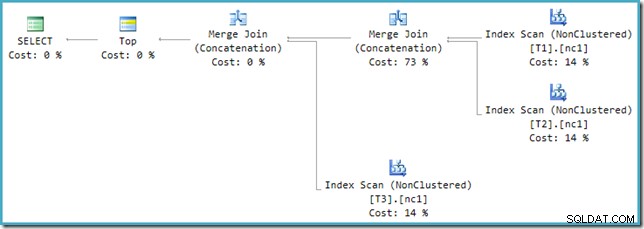
Nous pouvons voir l'arbre de sortie de l'optimiseur (avec trois entrées vers une union de fusion physique) en utilisant l'indicateur de trace 8607 :
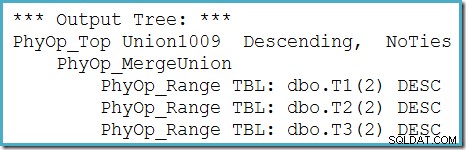
Un correctif incomplet
Malheureusement, la réécriture post-optimisation n'est pas parfaitement implémentée. Cela fait un peu désordre dans les chiffres des coûts. Mis à part les problèmes d'arrondi, les coûts du plan s'élèvent à 114 %, les 14 % supplémentaires provenant de l'entrée de la concaténation supplémentaire de fusion et de jointure générée par la réécriture :
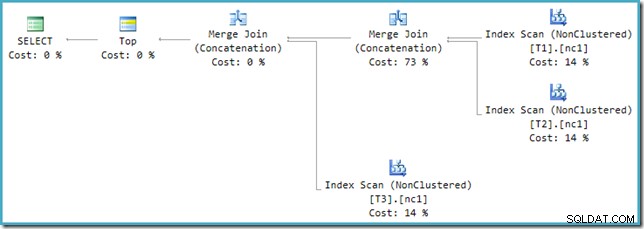
La fusion la plus à droite dans ce plan est l'opérateur d'origine dans l'arborescence de sortie de l'optimiseur. L'intégralité du coût de l'opération Union All lui est affectée. L'autre fusion est ajoutée par la réécriture et reçoit un coût nul.
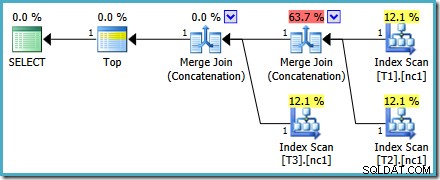
Quelle que soit la façon dont nous choisissons de le regarder (et il y a différents problèmes qui affectent la concaténation régulière), les nombres semblent étranges. Plan Explorer fait de son mieux pour contourner les informations erronées dans le plan XML en s'assurant au moins que les chiffres totalisent 100 % :
Ce problème de coût particulier est résolu dans SQL Server 2014 CTP 1 :
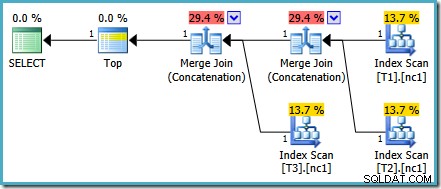
Les coûts de la concaténation de fusion sont désormais répartis équitablement entre les deux opérateurs, et les pourcentages totalisent 100 %. Étant donné que le XML sous-jacent a été corrigé, SSMS parvient également à afficher les mêmes chiffres.
Quel forfait est le meilleur ?
Si nous écrivons la requête en utilisant MAX , nous devons compter sur l'optimiseur qui choisit d'effectuer le travail supplémentaire nécessaire pour trouver un plan efficace. Si l'optimiseur trouve tôt un plan apparemment assez bon, il peut produire un plan relativement inefficace qui lit chaque ligne de chacune des tables de base :
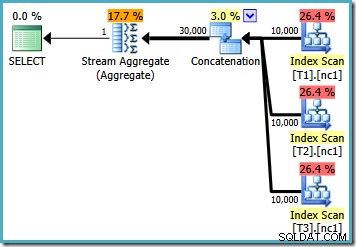
Si vous exécutez SQL Server 2008 ou SQL Server 2008 R2, l'optimiseur choisira toujours un plan inefficace quel que soit le nombre de lignes dans les tables de base. Le plan suivant a été produit sur SQL Server 2008 R2 avec 50 000 lignes :
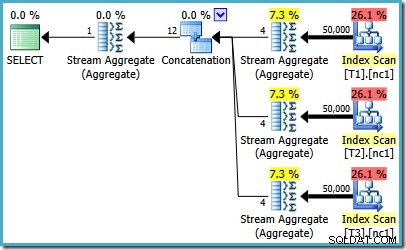
Même avec 50 millions de lignes dans chaque table, l'optimiseur 2008 et 2008 R2 ajoute juste du parallélisme, il n'introduit pas les opérateurs Top :
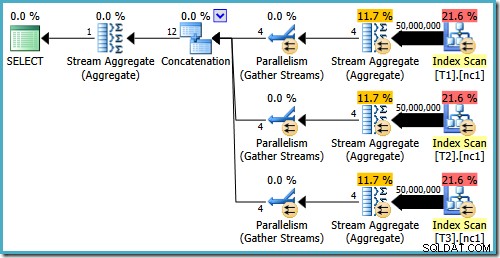
Comme mentionné dans mon article précédent, l'indicateur de trace 4199 est requis pour que SQL Server 2008 et 2008 R2 produise le plan avec les opérateurs Top. SQL Server 2005 et 2012 et versions ultérieures ne nécessitent pas l'indicateur de trace :
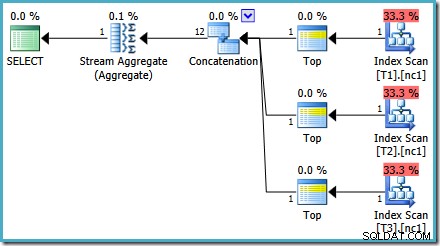
TOP avec ORDRE PAR
Une fois que nous comprenons ce qui se passe dans les plans d'exécution précédents, nous pouvons faire le choix conscient (et informé) de réécrire la requête en utilisant un TOP explicite avec ORDER BY :
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
Le plan d'exécution résultant peut avoir des pourcentages de coût qui semblent étranges dans certaines versions de SQL Server, mais le plan sous-jacent est solide. La réécriture post-optimisation qui rend les nombres impairs est appliquée une fois l'optimisation de la requête terminée, nous pouvons donc être sûrs que la sélection du plan de l'optimiseur n'a pas été affectée par ce problème.
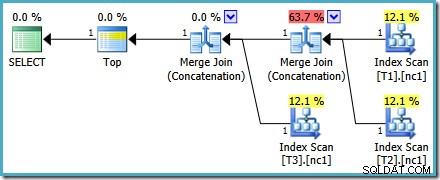
Ce plan ne change pas en fonction du nombre de lignes dans la table de base et ne nécessite la génération d'aucun indicateur de trace. Petit avantage supplémentaire, ce plan est trouvé par l'optimiseur lors de la première phase d'optimisation basée sur les coûts (recherche 0) :
Le meilleur plan sélectionné par l'optimiseur pour le MAX requête requise exécutant deux étapes d'optimisation basée sur les coûts (recherche 0 et recherche 1).
Il y a une petite différence sémantique entre le TOP requête et le MAX d'origine forme que je devrais mentionner. Si aucune des tables ne contient de ligne, la requête d'origine produirait un seul NULL résultat. Le remplacement TOP (1) la requête ne produit aucune sortie dans les mêmes circonstances. Cette différence n'est pas souvent importante dans les requêtes du monde réel, mais c'est quelque chose dont il faut être conscient. Nous pouvons répliquer le comportement de TOP en utilisant MAX dans SQL Server 2008 et versions ultérieures en ajoutant un ensemble vide GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Ce changement n'affecte pas les plans d'exécution générés pour le MAX requête d'une manière visible pour les utilisateurs finaux.
MAX avec concaténation de fusion
Vu le succès de Merge Join Concatenation dans le TOP (1) plan d'exécution, il est naturel de se demander si le même plan optimal pourrait être généré pour le MAX d'origine demander si nous forçons l'optimiseur à utiliser la concaténation de fusion au lieu de la concaténation normale pour UNION ALL opération.
Il existe un indice de requête à cet effet - MERGE UNION - mais malheureusement, cela ne fonctionne correctement qu'à partir de SQL Server 2012. Dans les versions précédentes, le UNION l'indice n'affecte que UNION requêtes, pas UNION ALL . À partir de SQL Server 2012, nous pouvons essayer ceci :
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Nous sommes récompensés par un plan qui comprend la concaténation de fusion. Malheureusement, ce n'est pas tout à fait tout ce que nous aurions pu espérer :
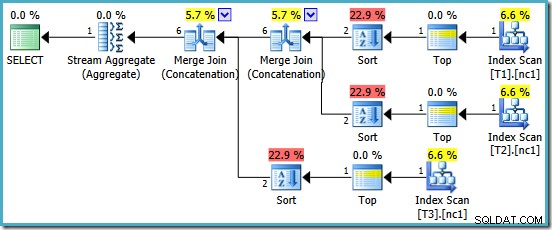
Les opérateurs intéressants dans ce plan sont les sortes. Notez l'estimation de cardinalité d'entrée à 1 ligne et l'estimation à 4 lignes sur la sortie. La cause devrait maintenant vous être familière :il s'agit de la même erreur d'estimation de cardinalité agrégée partielle dont nous avons parlé plus tôt.
La présence des tris révèle un autre problème avec les agrégats partiels. Non seulement ils produisent une estimation de cardinalité incorrecte, mais ils ne parviennent pas non plus à préserver l'ordre d'index qui rendrait le tri inutile (la concaténation de fusion nécessite des entrées triées). Les agrégats partiels sont scalaires MAX agrégats, garantis pour produire une ligne, donc la question de la commande devrait être sans objet de toute façon (il n'y a qu'une seule façon de trier une ligne !)
C'est dommage, car sans les sortes, ce serait un plan d'exécution décent. Si les agrégats partiels ont été implémentés correctement, et que le MAX écrit avec un GROUP BY () clause, on pourrait même espérer que l'optimiseur puisse repérer que les trois Tops et le Stream Aggregate final pourraient être remplacés par un seul opérateur Top final, donnant exactement le même plan que le TOP (1) explicite requête. L'optimiseur ne contient pas cette transformation aujourd'hui, et je suppose qu'elle ne serait pas assez souvent utile pour que son inclusion en vaille la peine à l'avenir.
Derniers mots
Utilisation de TOP ne sera pas toujours préférable à MIN ou MAX . Dans certains cas, cela produira un plan nettement moins optimal. Le but de cet article est que la compréhension des transformations appliquées par l'optimiseur peut suggérer des façons de réécrire la requête d'origine qui peuvent s'avérer utiles.