De nos jours, les bases de données couvrant plusieurs clouds sont assez courantes. Ils promettent une haute disponibilité et la possibilité de mettre en œuvre facilement des procédures de reprise après sinistre. Ils constituent également une méthode pour éviter la dépendance vis-à-vis d'un fournisseur :si vous concevez votre environnement de base de données de manière à ce qu'il puisse fonctionner sur plusieurs fournisseurs de cloud, vous n'êtes probablement pas lié à des fonctionnalités et à des implémentations spécifiques à un fournisseur particulier. Cela vous permet d'ajouter plus facilement un autre fournisseur d'infrastructure à votre environnement, qu'il s'agisse d'un autre cloud ou d'une configuration sur site. Une telle flexibilité est très importante étant donné qu'il existe une concurrence féroce entre les fournisseurs de cloud et la migration de l'un à l'autre pourrait être tout à fait réalisable si elle s'accompagnait d'une réduction des dépenses.
Étendre votre infrastructure sur plusieurs centres de données (du même fournisseur ou non, cela n'a pas vraiment d'importance) pose de sérieux problèmes à résoudre. Comment concevoir l'ensemble de l'infrastructure de manière à ce que les données soient sécurisées ? Comment faire face aux défis auxquels vous devez faire face lorsque vous travaillez dans un environnement multi-cloud ? Dans ce blog, nous en examinerons un, mais sans doute le plus sérieux - le potentiel d'un cerveau divisé. Qu'est-ce que ça veut dire? Découvrons un peu ce qu'est le cerveau divisé.
Qu'est-ce que "Split-Brain" ?
Split-brain est une condition dans laquelle un environnement composé de plusieurs nœuds subit un partitionnement du réseau et a été divisé en plusieurs segments qui n'ont pas de contact les uns avec les autres. Le cas le plus simple ressemblera à ceci :
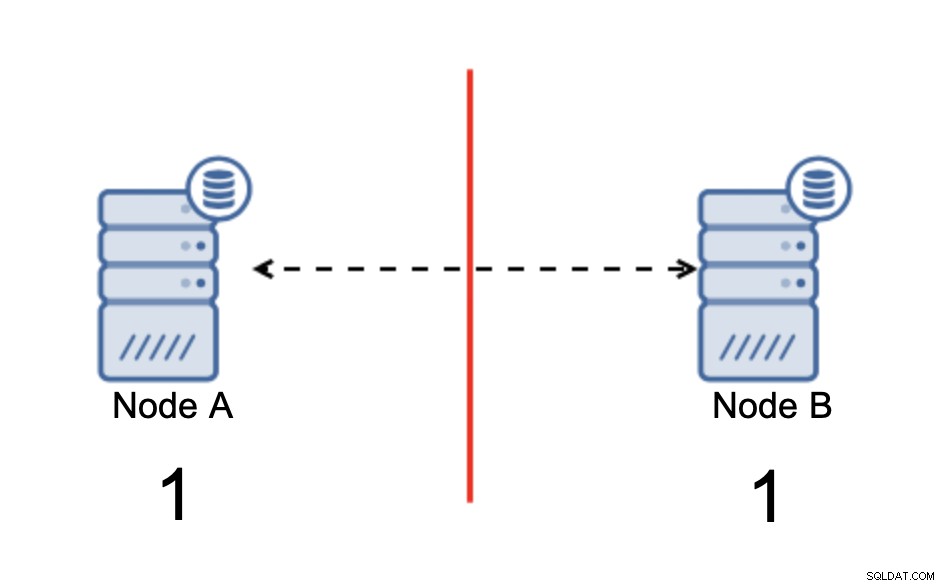
Nous avons deux nœuds, A et B, connectés sur un réseau utilisant bi -réplication asynchrone directionnelle. Ensuite, la connexion réseau est coupée entre ces nœuds. Par conséquent, les deux nœuds ne peuvent pas se connecter et les modifications exécutées sur le nœud A ne peuvent pas être transmises au nœud B et vice versa. Les deux nœuds, A et B, sont actifs et acceptent les connexions, ils ne peuvent tout simplement pas échanger de données. Cela peut entraîner de graves problèmes car l'application peut apporter des modifications sur les deux nœuds en s'attendant à voir l'état complet de la base de données alors qu'en fait, elle ne fonctionne que sur un état de données partiellement connu. En conséquence, des actions incorrectes peuvent être prises par l'application, des résultats incorrects peuvent être présentés à l'utilisateur, etc. Nous pensons qu'il est clair que le cerveau divisé est potentiellement une condition très dangereuse et l'une des priorités serait de s'en occuper dans une certaine mesure. Que peut-on y faire ?
Comment éviter le Split-Brain
En bref, cela dépend. Le principal problème à résoudre est le fait que les nœuds sont opérationnels mais n'ont pas de connectivité entre eux, ils ne sont donc pas conscients de l'état de l'autre nœud. En général, la réplication asynchrone MySQL ne dispose d'aucune sorte de mécanisme qui résoudrait en interne le problème du split-brain. Vous pouvez essayer de mettre en œuvre des solutions qui vous aident à éviter le split-brain, mais elles comportent des limites ou ne résolvent toujours pas complètement le problème.
Lorsque nous nous aventurons loin de la réplication asynchrone, les choses se présentent différemment. MySQL Group Replication et MySQL Galera Cluster sont des technologies qui bénéficient de la prise en compte des clusters build-it. Ces deux solutions maintiennent la communication entre les nœuds et garantissent que le cluster est au courant de l'état des nœuds. Ils implémentent un mécanisme de quorum qui régit si les clusters peuvent être opérationnels ou non.
Discutons plus en détail de ces deux solutions (réplication asynchrone et clusters basés sur un quorum).
Clusterisation basée sur un quorum
Nous n'allons pas discuter des différences d'implémentation entre MySQL Galera Cluster et MySQL Group Replication, nous nous concentrerons sur l'idée de base derrière l'approche basée sur le quorum et comment elle est conçue pour résoudre le problème de la split-brain dans votre cluster.
L'essentiel est que :le cluster, pour fonctionner, nécessite que la majorité de ses nœuds soient disponibles. Avec cette exigence, nous pouvons être sûrs que la minorité ne pourra jamais vraiment affecter le reste du cluster car la minorité ne devrait pas être en mesure d'effectuer des actions. Cela signifie également que, pour pouvoir gérer une défaillance d'un nœud, un cluster doit avoir au moins trois nœuds. Si vous n'avez que deux nœuds :
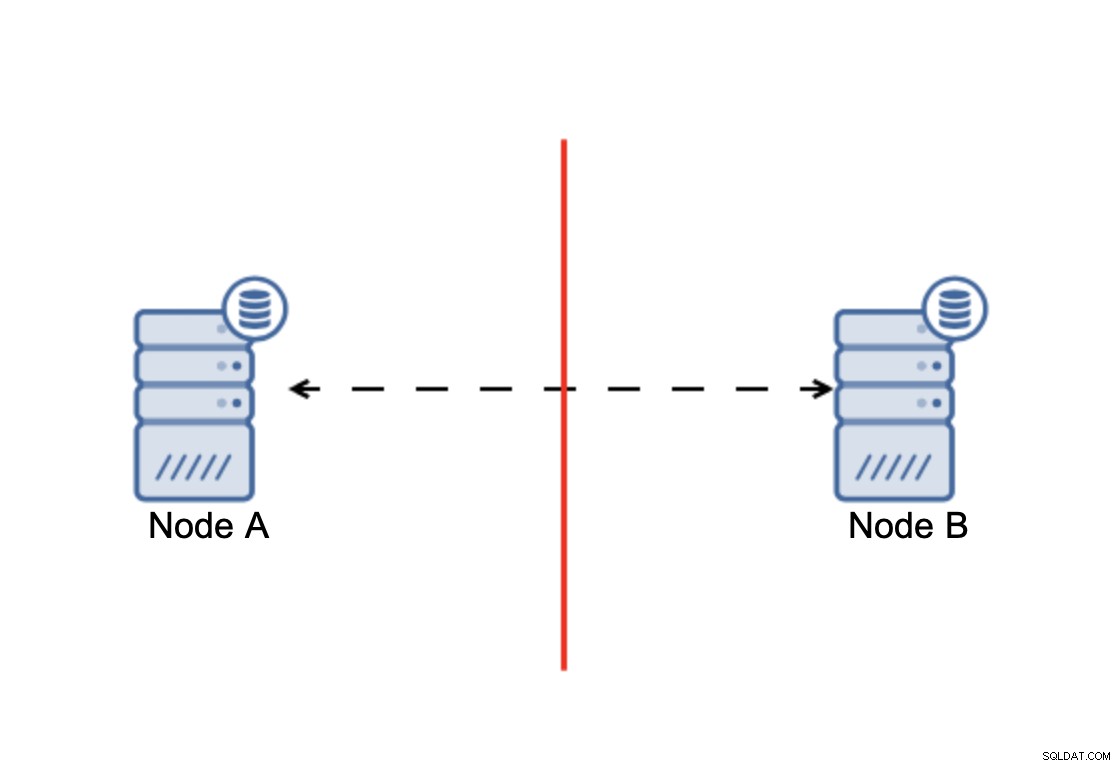
Lorsqu'il y a une division du réseau, vous vous retrouvez avec deux parties du cluster, chacun composé d'exactement 50 % du nombre total de nœuds dans le cluster. Aucune de ces parties n'a la majorité. Si vous avez trois nœuds, cependant, les choses sont différentes :
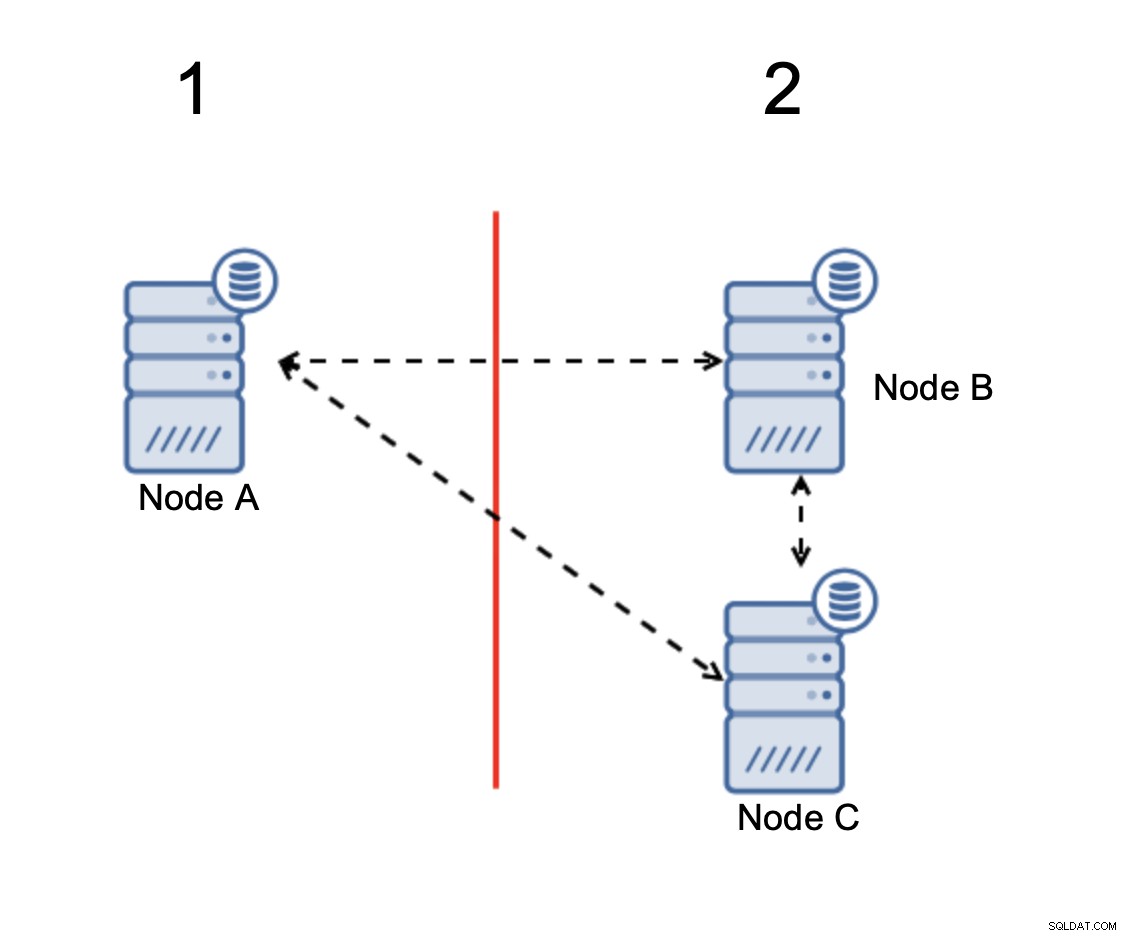
Les nœuds B et C ont la majorité :cette partie est constituée de deux nœuds de trois donc il peut continuer à fonctionner. D'autre part, le nœud A ne représente que 33 % des nœuds du cluster, il n'a donc pas la majorité et il cessera de gérer le trafic pour éviter le split brain.
Avec une telle implémentation, il est très peu probable que le split-brain se produise (il devrait être introduit via des états de réseau étranges et inattendus, des conditions de concurrence ou simplement des bogues dans le code de clustering. Bien qu'il ne soit pas impossible de rencontrer de telles conditions, l'utilisation de l'une des solutions basées sur le quorum est la meilleure option pour éviter le split-brain qui existe en ce moment.
Réplication asynchrone
Bien qu'il ne s'agisse pas du choix idéal lorsqu'il s'agit de gérer le cerveau divisé, la réplication asynchrone reste une option viable. Vous devez prendre en compte plusieurs éléments avant de mettre en œuvre une base de données multicloud avec réplication asynchrone.
Tout d'abord, le basculement. La réplication asynchrone est livrée avec un seul écrivain - seul le maître doit être accessible en écriture et les autres nœuds ne doivent servir que le trafic en lecture seule. Le défi est de savoir comment gérer la panne du maître ?
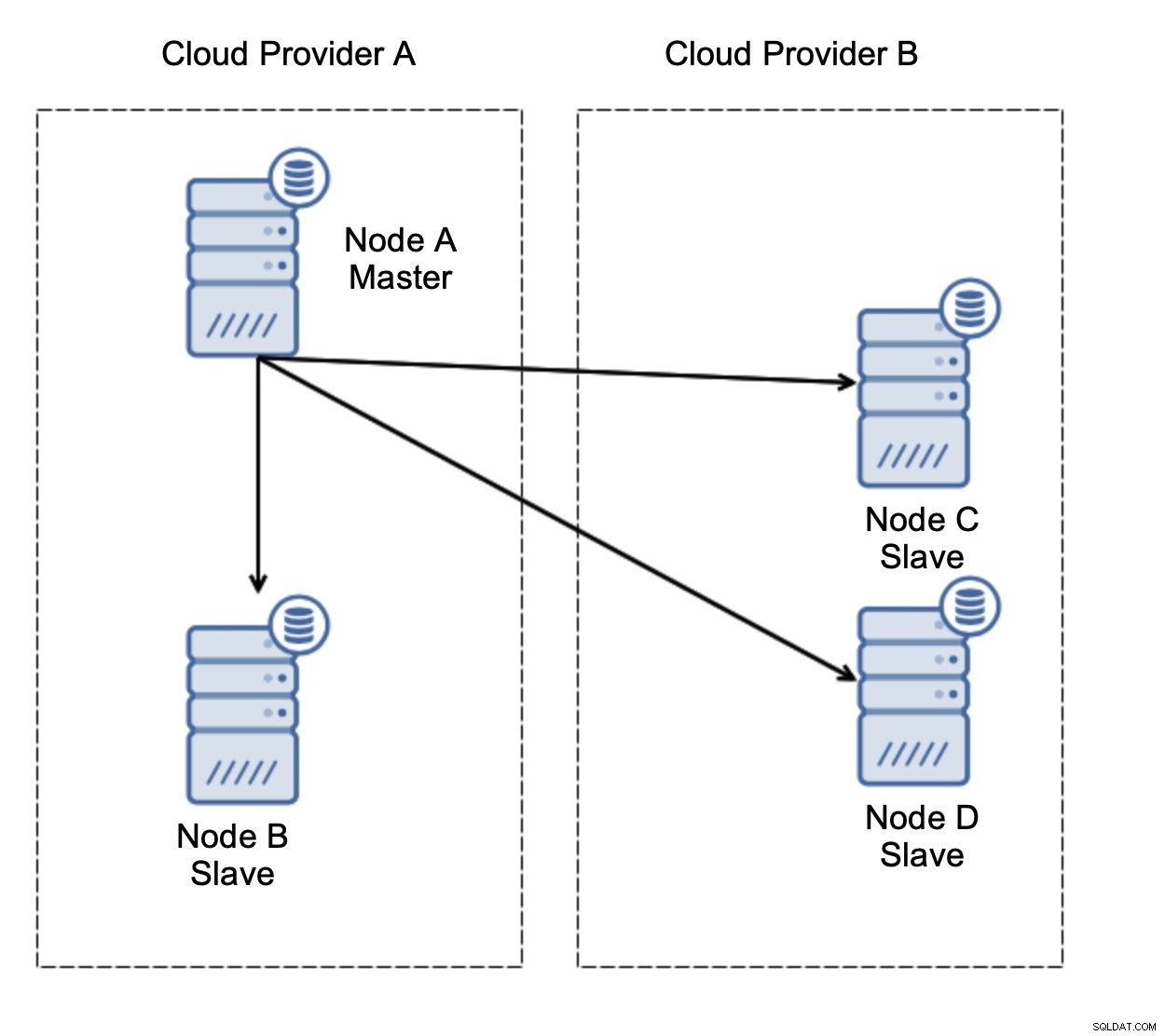
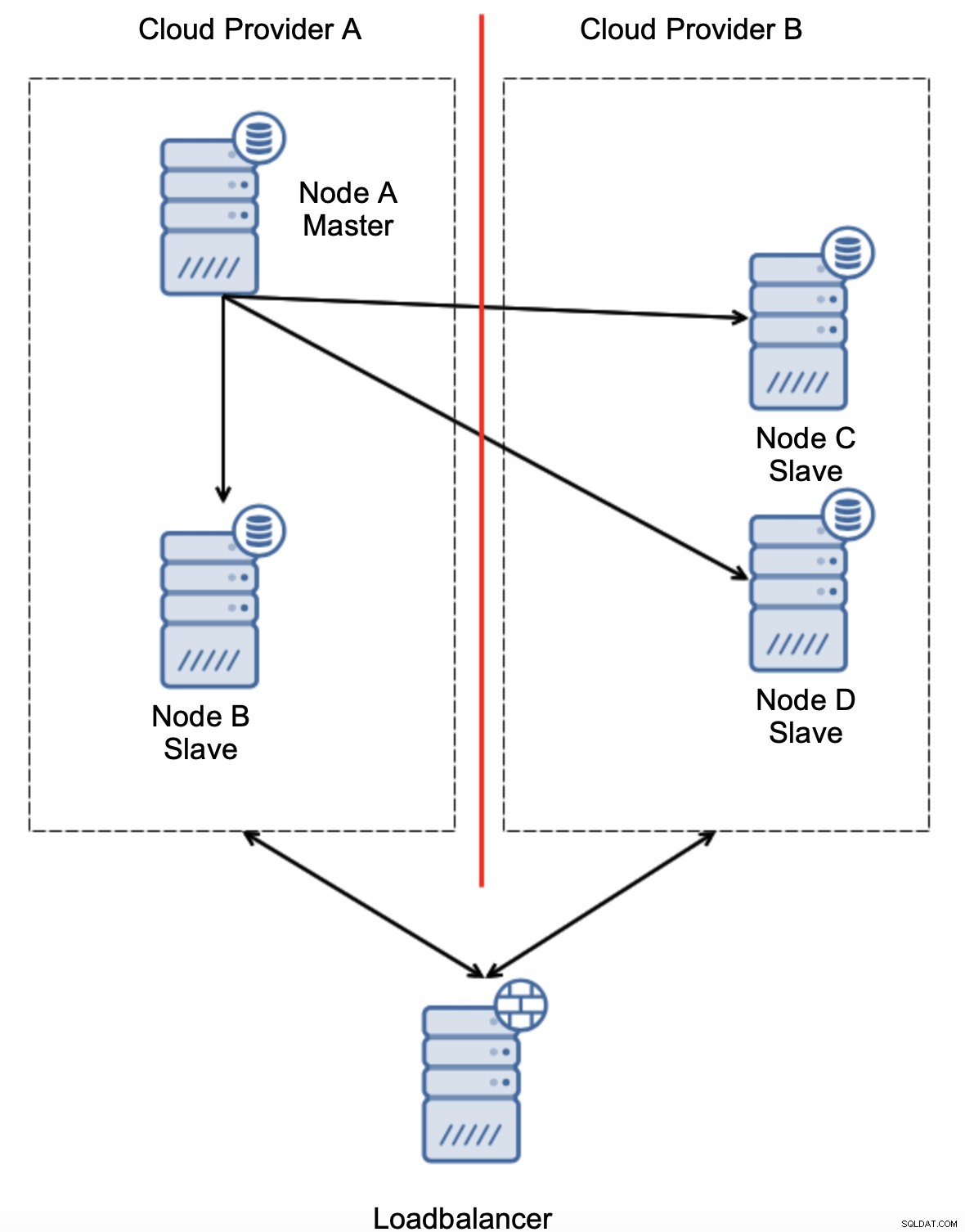
Considérons la configuration comme sur le schéma ci-dessus. Nous avons deux fournisseurs de cloud, deux nœuds chacun. Le fournisseur A héberge également le maître. Que doit-il se passer si le maître tombe en panne ? L'un des esclaves doit être promu pour s'assurer que la base de données continuera à être opérationnelle. Idéalement, il devrait s'agir d'un processus automatisé pour réduire le temps nécessaire pour amener la base de données à l'état opérationnel. Que se passerait-il, cependant, s'il y avait un partitionnement du réseau ? Comment sommes-nous censés vérifier l'état du cluster ?
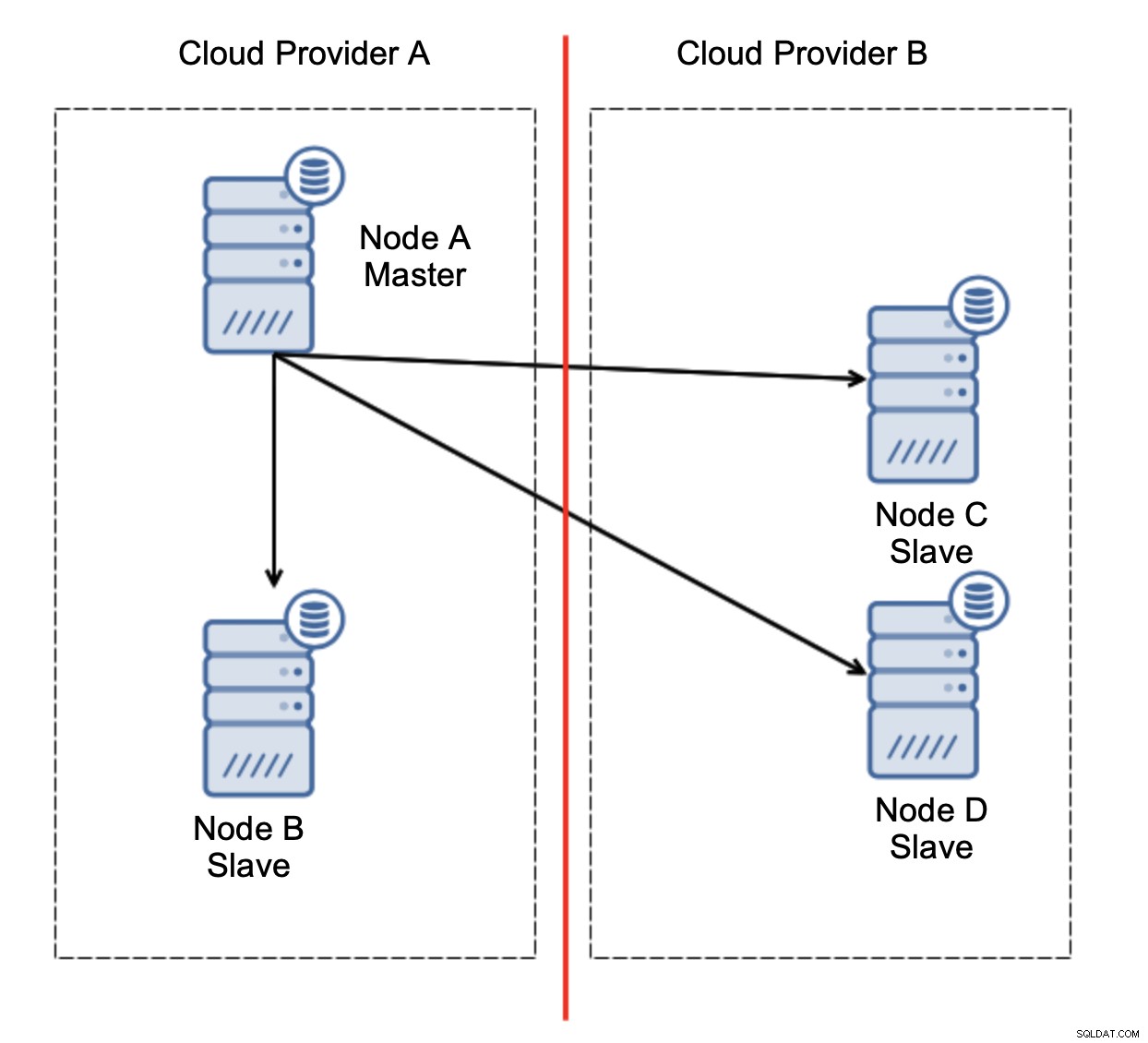
Voici le défi. La connectivité réseau est perdue entre deux fournisseurs de cloud. Du point de vue des nœuds C et D, le nœud B et le maître, le nœud A sont hors ligne. Le nœud C ou D doit-il être promu pour devenir maître ? Mais l'ancien maître est toujours actif - il ne s'est pas écrasé, il n'est tout simplement pas accessible sur le réseau. Si nous promouvons l'un des nœuds situés chez le fournisseur B, nous nous retrouverons avec deux maîtres inscriptibles, deux ensembles de données et un cerveau divisé :
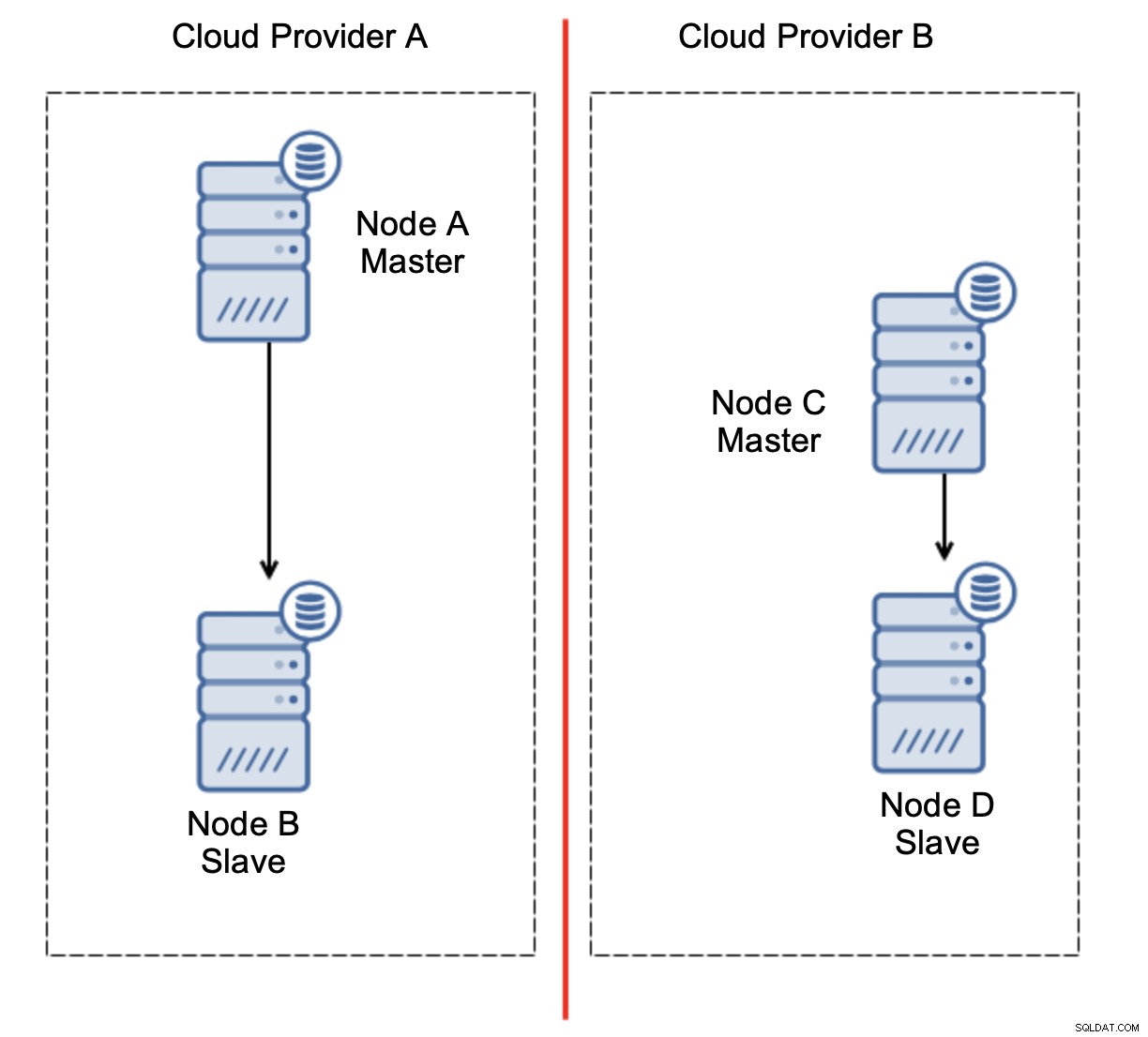
Ce n'est certainement pas quelque chose que nous voulons. Il y a quelques options ici. Tout d'abord, nous pouvons définir des règles de basculement de manière à ce que le basculement ne se produise que dans l'un des segments du réseau, où se trouve le maître. Dans notre cas, cela signifierait que seul le nœud B pourrait être automatiquement promu pour devenir un maître. De cette façon, nous pouvons nous assurer que le basculement automatisé se produira si le nœud A est en panne, mais aucune action ne sera entreprise s'il y a un partitionnement du réseau. Certains des outils qui peuvent vous aider à gérer les basculements automatisés (comme ClusterControl) prennent en charge les listes blanches et noires, permettant aux utilisateurs de définir quels nœuds peuvent être considérés comme candidats au basculement et lesquels ne doivent jamais être utilisés comme maîtres.
Une autre option consisterait à implémenter une sorte de solution de « conscience de la topologie ». Par exemple, on pourrait essayer de vérifier l'état du maître en utilisant des services externes comme des équilibreurs de charge.
Si l'automatisation du basculement peut vérifier l'état de la topologie tel qu'il est vu par le équilibreur de charge, il se peut que l'équilibreur de charge, situé dans un troisième emplacement, puisse réellement atteindre les deux centres de données et indiquer clairement que les nœuds du fournisseur de cloud A ne sont pas en panne, ils ne peuvent tout simplement pas être atteints depuis le fournisseur de cloud B. Tel une couche supplémentaire de contrôles est implémentée dans ClusterControl.
Enfin, quel que soit l'outil que vous utilisez pour implémenter le basculement automatisé, il peut également être conçu de manière à tenir compte du quorum. Ensuite, avec trois nœuds répartis sur trois sites, vous pouvez facilement déterminer quelle partie de l'infrastructure doit être maintenue en vie et laquelle ne doit pas l'être.
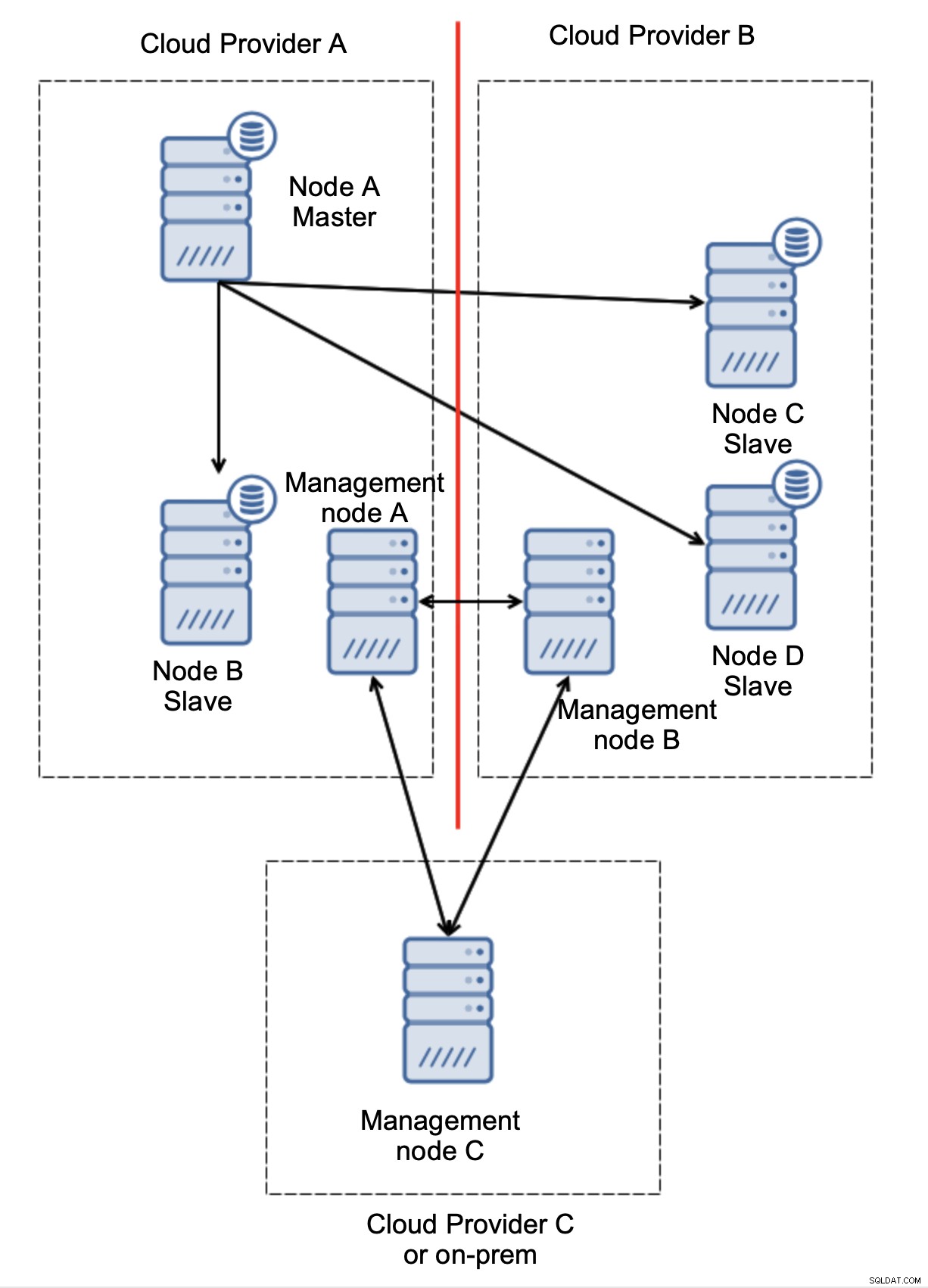
Ici, nous pouvons clairement voir que le problème est uniquement lié à la connectivité entre les fournisseurs A et B. Le nœud de gestion C agira comme un relais et, par conséquent, aucun basculement ne doit être lancé. En revanche, si un datacenter est totalement coupé :

Ce qui s'est passé est également assez clair. Le nœud de gestion A signalera qu'il ne peut pas atteindre la majorité du cluster tandis que les nœuds de gestion B et C formeront la majorité. Il est possible de s'appuyer sur cela et, par exemple, d'écrire des scripts qui géreront la topologie en fonction de l'état du nœud de gestion. Cela pourrait signifier que les scripts exécutés dans le fournisseur de cloud A détecteraient que le nœud de gestion A ne constitue pas la majorité et qu'ils arrêteraient tous les nœuds de base de données pour s'assurer qu'aucune écriture ne se produirait dans le fournisseur de cloud partitionné.
ClusterControl, lorsqu'il est déployé en mode haute disponibilité, peut être traité comme les nœuds de gestion que nous avons utilisés dans nos exemples. Trois nœuds ClusterControl, en plus du protocole RAFT, peuvent vous aider à déterminer si un segment de réseau donné est partitionné ou non.
Conclusion
Nous espérons que cet article de blog vous donnera une idée des scénarios de split-brain qui peuvent se produire pour les déploiements MySQL couvrant plusieurs plates-formes cloud.