Les bases de données qui servent les applications métier doivent souvent prendre en charge les données temporelles. Par exemple, supposons qu'un contrat avec un fournisseur n'est valide que pour une durée limitée. Il peut être valide à partir d'un point précis dans le temps, ou il peut être valide pour un intervalle de temps spécifique, d'un point de départ à un point de fin. En outre, vous devez souvent auditer toutes les modifications apportées à une ou plusieurs tables. Vous devrez peut-être également être en mesure d'afficher l'état à un moment précis ou toutes les modifications apportées à une table au cours d'une période donnée. Du point de vue de l'intégrité des données, vous devrez peut-être implémenter de nombreuses contraintes spécifiques temporelles supplémentaires.
Présentation des données temporelles
Dans une table avec support temporel, l'en-tête représente un prédicat avec un paramètre au moins unique qui représente l'intervalle lorsque le reste du prédicat est valide, le prédicat complet est donc un prédicat horodaté. Les lignes représentent des propositions horodatées et la période de validité de la ligne est généralement exprimée avec deux attributs :de et à , ou commencer et fin .
Types de tables temporelles
Vous avez peut-être remarqué lors de la partie introduction qu'il existe deux types de problèmes temporels. Le premier est le temps de validité de la proposition - à quelle période la proposition qu'une ligne horodatée dans une table représente était en fait vraie. Par exemple, un contrat avec un fournisseur n'était valide que du point 1 au point 2. Ce type de durée de validité est significatif pour les personnes, significatif pour l'entreprise. Le temps de validité est aussi appelé temps d'application ou temps humain . Nous pouvons avoir plusieurs périodes valides pour la même entité. Par exemple, le contrat susmentionné qui était valide du point 1 au point 2 pourrait également être valide du point 7 au point 9.
Le deuxième problème temporel est le temps de transaction . Une ligne pour le contrat mentionné ci-dessus a été insérée au point 1 et était la seule version de la vérité connue de la base de données jusqu'à ce que quelqu'un la modifie, ou même jusqu'à la fin des temps. Lorsque la ligne est mise à jour au point 2, la ligne d'origine était connue comme étant fidèle à la base de données du point 1 au point 2. Une nouvelle ligne pour la même proposition est insérée avec l'heure valide pour la base de données du point 2 au point temporel. la fin des temps. L'heure de la transaction est également appelée heure système ou heure de la base de données .
Bien sûr, vous pouvez également implémenter des tables versionnées d'application et de système. De telles tables sont dites bitemporelles tableaux.
Dans SQL Server 2016, vous bénéficiez d'une prise en charge de l'heure système prête à l'emploi avec les tables temporelles versionnées du système . Si vous devez implémenter le temps d'application, vous devez développer une solution par vous-même.
Opérateurs d'intervalle d'Allen
La théorie des données temporelles dans un modèle relationnel a commencé à évoluer il y a plus de trente ans. Je vais présenter quelques opérateurs booléens utiles et quelques opérateurs qui fonctionnent sur des intervalles et renvoient un intervalle. Ces opérateurs sont connus sous le nom d'opérateurs d'Allen, du nom de J. F. Allen, qui en a défini un certain nombre dans un article de recherche de 1983 sur les intervalles temporels. Tous sont toujours acceptés comme valides et nécessaires. Un système de gestion de base de données pourrait vous aider à gérer les délais d'application en mettant en œuvre ces opérateurs prêts à l'emploi.
Permettez-moi d'abord d'introduire la notation que j'utiliserai. Je vais travailler sur deux intervalles, notés i1 et i2 . Le point de départ du premier intervalle est b1 , et la fin est e1 ; le point de début du deuxième intervalle est b2 et la fin est e2 . Les opérateurs booléens d'Allen sont définis dans le tableau suivant.
[table id=2 /]
En plus des opérateurs booléens, il existe trois opérateurs d'Allen qui acceptent des intervalles comme paramètres d'entrée et renvoient un intervalle. Ces opérateurs constituent une algèbre d'intervalle simple . Notez que ces opérateurs portent le même nom que les opérateurs relationnels que vous connaissez probablement déjà :Union, Intersect et Minus. Cependant, ils ne se comportent pas exactement comme leurs homologues relationnels. En général, en utilisant l'un des trois opérateurs d'intervalle, si l'opération aboutit à un ensemble vide de points temporels ou à un ensemble qui ne peut pas être décrit par un intervalle, alors l'opérateur doit renvoyer NULL. Une union de deux intervalles n'a de sens que si les intervalles se rencontrent ou se chevauchent. Une intersection n'a de sens que si les intervalles se chevauchent. L'opérateur Intervalle moins n'a de sens que dans certains cas. Par exemple, (3:10) Moins (5:7) renvoie NULL car le résultat ne peut pas être décrit par un intervalle. Le tableau suivant résume la définition des opérateurs de l'algèbre d'intervalle.
[identifiant de table=3 /]
Problème de performance des requêtes qui se chevauchentL'un des opérateurs les plus complexes à implémenter est le chevauchement opérateur. Les requêtes qui doivent trouver des intervalles qui se chevauchent ne sont pas simples à optimiser. Cependant, de telles requêtes sont assez fréquentes sur les tables temporelles. Dans cet article et les deux suivants, je vais vous montrer quelques façons d'optimiser ces requêtes. Mais avant de présenter les solutions, permettez-moi de vous présenter le problème.
Afin d'expliquer le problème, j'ai besoin de quelques données. Le code suivant montre un exemple comment créer une table avec des intervalles de validité exprimés avec le b et e colonnes, où le début et la fin d'un intervalle sont représentés sous forme d'entiers. La table est remplie avec des données de démonstration de la table WideWorldImporters.Sales.OrderLines. Veuillez noter qu'il existe plusieurs versions de WideWorldImporters base de données, vous pourriez donc obtenir des résultats légèrement différents. J'ai utilisé le fichier de sauvegarde WideWorldImporters-Standard.bak de https://github.com/Microsoft/sql-server-samples/releases/tag/wide-world-importers-v1.0 pour restaurer cette base de données de démonstration sur mon instance SQL Server .
Création des données de démonstration
J'ai créé une table de démonstration dbo.Intervals dans le tempd base de données avec le code suivant.
USE tempdb; GO SELECT OrderLineID AS id, StockItemID * (OrderLineID % 5 + 1) AS b, LastEditedBy + StockItemID * (OrderLineID % 5 + 1) AS e INTO dbo.Intervals FROM WideWorldImporters.Sales.OrderLines; -- 231412 rows GO ALTER TABLE dbo.Intervals ADD CONSTRAINT PK_Intervals PRIMARY KEY(id); CREATE INDEX idx_b ON dbo.Intervals(b) INCLUDE(e); CREATE INDEX idx_e ON dbo.Intervals(e) INCLUDE(b); GO
Veuillez également noter les index créé. Les deux index sont optimaux pour les recherches sur le début d'un intervalle ou sur la fin d'un intervalle. Vous pouvez vérifier le début minimal et la fin maximale de tous les intervalles avec le code suivant.
SELECT MIN(b), MAX(e) FROM dbo.Intervals;
Vous pouvez voir dans les résultats que le point de temps de début minimal est 1 et le point de temps de fin maximal est 1155.
Donner le contexte aux données
Vous remarquerez peut-être que je représente les points temporels de début et de fin sous forme d'entiers. Maintenant, je dois donner aux intervalles un contexte temporel. Dans ce cas, un seul point dans le temps représente un jour . Le code suivant crée une table de recherche de dates et le peuple. Notez que la date de début est le 1er juillet 2014.
CREATE TABLE dbo.DateNums (n INT NOT NULL PRIMARY KEY, d DATE NOT NULL); GO DECLARE @i AS INT = 1, @d AS DATE = '20140701'; WHILE @i <= 1200 BEGIN INSERT INTO dbo.DateNums (n, d) SELECT @i, @d; SET @i += 1; SET @d = DATEADD(day,1,@d); END; GO
Maintenant, vous pouvez joindre deux fois la table dbo.Intervals à la table dbo.DateNums, pour donner le contexte aux entiers qui représentent le début et la fin des intervalles.
SELECT i.id, i.b, d1.d AS dateB, i.e, d2.d AS dateE FROM dbo.Intervals AS i INNER JOIN dbo.DateNums AS d1 ON i.b = d1.n INNER JOIN dbo.DateNums AS d2 ON i.e = d2.n ORDER BY i.id;
Présentation du problème de performances
Le problème avec les requêtes temporelles est que lors de la lecture d'une table, SQL Server ne peut utiliser qu'un seul index et éliminer avec succès les lignes qui ne sont pas candidates au résultat d'un seul côté, puis analyse le reste des données. Par exemple, vous devez trouver tous les intervalles du tableau qui chevauchent un intervalle donné. Rappelons que deux intervalles se chevauchent lorsque le début du premier est inférieur ou égal à la fin du second et le début du second est inférieur ou égal à la fin du premier, ou mathématiquement lorsque (b1 ≤ e2) ET (b2 ≤ e1).
La requête suivante a recherché tous les intervalles qui chevauchent l'intervalle (10, 30). Notez que la deuxième condition (b2 ≤ e1) est inversée en (e1 ≥ b2) pour une lecture plus simple (le début et la fin des intervalles du tableau sont toujours à gauche de la condition). L'intervalle donné ou recherché se trouve au début de la chronologie pour tous les intervalles du tableau.
SET STATISTICS IO ON; DECLARE @b AS INT = 10, @e AS INT = 30; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
La requête a utilisé 36 lectures logiques. Si vous vérifiez le plan d'exécution, vous pouvez voir que la requête a utilisé la recherche d'index dans l'index idx_b avec le prédicat de recherche [tempdb].[dbo].[Intervals].b <=Scalar Operator((30)) and then scan les lignes et sélectionnez les lignes résultantes à l'aide du prédicat résiduel [tempdb].[dbo].[Intervals].[e]>=(10). Étant donné que l'intervalle recherché se trouve au début de la chronologie, le prédicat de recherche a réussi à éliminer la majorité des lignes ; seuls quelques intervalles du tableau ont un point de départ inférieur ou égal à 30.
Vous obtiendrez une requête tout aussi efficace si l'intervalle recherché se trouvait à la fin de la chronologie, juste que SQL Server utiliserait l'index idx_e pour la recherche. Cependant, que se passe-t-il si l'intervalle recherché se situe au milieu de la chronologie, comme le montre la requête suivante ?
DECLARE @b AS INT = 570, @e AS INT = 590; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND e >= @b OPTION (RECOMPILE);
Cette fois, la requête a utilisé 111 lectures logiques. Avec une table plus grande, la différence avec la première requête serait encore plus grande. Si vous vérifiez le plan d'exécution, vous pouvez découvrir que SQL Server a utilisé l'index idx_e avec [tempdb].[dbo].[Intervals].e>=Scalar Operator((570)) seek predicate et [tempdb].[ dbo].[Intervalles].[b]<=(590) prédicat résiduel. Le prédicat de recherche exclut environ la moitié des lignes d'un côté, tandis que la moitié des lignes de l'autre côté est analysée et les lignes résultantes extraites avec le prédicat résiduel.
Solution T-SQL améliorée
Il existe une solution qui utiliserait cet index pour l'élimination des lignes des deux côtés de l'intervalle recherché en utilisant un seul index. La figure suivante illustre cette logique.
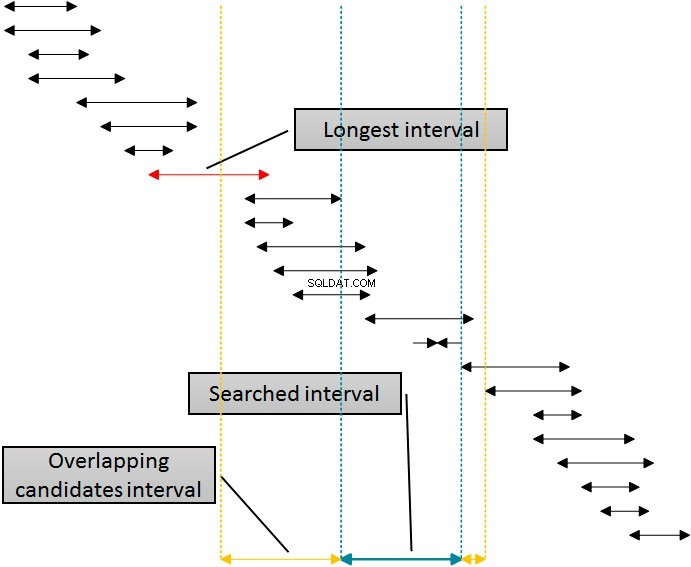
Les intervalles de la figure sont triés par la limite inférieure, représentant l'utilisation de l'index idx_b par SQL Server. L'élimination des intervalles du côté droit de l'intervalle donné (recherché) est simple :éliminez simplement tous les intervalles dont le début est supérieur d'au moins une unité (plus à droite) à la fin de l'intervalle donné. Vous pouvez voir cette limite dans la figure indiquée par la ligne pointillée la plus à droite. Cependant, l'élimination par la gauche est plus complexe. Afin d'utiliser le même index, l'index idx_b pour éliminer de la gauche, je dois utiliser le début des intervalles dans la table dans la clause WHERE de la requête. Je dois aller sur le côté gauche du début de l'intervalle donné (recherché) au moins pour la longueur de l'intervalle le plus long du tableau, qui est marqué d'une légende dans la figure. Les intervalles qui commencent avant la ligne jaune de gauche ne peuvent pas se chevaucher avec l'intervalle (bleu) donné.
Comme je sais déjà que la longueur de l'intervalle le plus long est de 20, je peux écrire une requête améliorée de manière assez simple.
DECLARE @b AS INT = 570, @e AS INT = 590; DECLARE @max AS INT = 20; SELECT id, b, e FROM dbo.Intervals WHERE b <= @e AND b >= @b - @max AND e >= @b AND e <= @e + @max OPTION (RECOMPILE);
Cette requête récupère les mêmes lignes que la précédente avec 20 lectures logiques uniquement. Si vous vérifiez le plan d'exécution, vous pouvez voir que l'idx_b a été utilisé, avec le prédicat de recherche Seek Keys[1] :Start :[tempdb].[dbo].[Intervals].b>=Scalar Operator((550)) , Fin :[tempdb].[dbo].[Intervals].b <=Scalar Operator((590)), qui a réussi à éliminer les lignes des deux côtés de la chronologie, puis le prédicat résiduel [tempdb].[dbo]. [Intervals].[e]>=(570) AND [tempdb].[dbo].[Intervals].[e]<=(610) a été utilisé pour sélectionner des lignes à partir d'un balayage partiel très limité.
Bien sûr, le chiffre pourrait être inversé pour couvrir les cas où l'index idx_e serait plus utile. Avec cet indice, l'élimination par la gauche est simple - éliminer tous les intervalles qui se terminent au moins une unité avant le début de l'intervalle donné. Cette fois, l'élimination par la droite est plus complexe - la fin des intervalles dans le tableau ne peut pas être plus à droite que la fin de l'intervalle donné plus la longueur maximale de tous les intervalles dans le tableau.
Veuillez noter que cette performance est la conséquence des données spécifiques du tableau. La longueur maximale d'un intervalle est de 20. Ainsi, SQL Server peut très efficacement éliminer les intervalles des deux côtés. Cependant, s'il n'y avait qu'un seul intervalle long dans la table, le code deviendrait beaucoup moins efficace, car SQL Server ne serait pas en mesure d'éliminer un grand nombre de lignes d'un côté, à gauche ou à droite, selon l'index qu'il utiliserait. . Quoi qu'il en soit, dans la vraie vie, la longueur de l'intervalle ne varie pas beaucoup de fois, donc cette technique d'optimisation pourrait être très utile, surtout parce qu'elle est simple.
Conclusion
Veuillez noter qu'il ne s'agit que d'une solution possible. Vous pouvez trouver une solution plus complexe, mais qui offre des performances prévisibles quelle que soit la longueur de l'intervalle le plus long dans l'article Interval Queries in SQL Server d'Itzik Ben-Gan (https://sqlmag.com/t-sql/ sql-server-intervalle-requêtes). Cependant, j'aime beaucoup le T-SQL amélioré solution que j'ai présentée dans cet article. La solution est très simple; tout ce que vous avez à faire est d'ajouter deux prédicats à la clause WHERE de vos requêtes qui se chevauchent. Cependant, ce n'est pas la fin des possibilités. Restez à l'écoute, dans les deux prochains articles, je vous montrerai plus de solutions, vous aurez donc un riche éventail de possibilités dans votre boîte à outils d'optimisation.
Outil utile :
dbForge Query Builder pour SQL Server - permet aux utilisateurs de créer rapidement et facilement des requêtes SQL complexes via une interface visuelle intuitive sans écriture manuelle de code.