Les modifications de la représentation interne des tables partitionnées entre SQL Server 2005 et SQL Server 2008 ont entraîné une amélioration des plans de requête et des performances dans la majorité des cas (en particulier lorsque l'exécution parallèle est impliquée). Malheureusement, les mêmes modifications ont fait que certaines choses qui fonctionnaient bien dans SQL Server 2005 ne fonctionnaient soudainement pas aussi bien dans SQL Server 2008 et versions ultérieures. Cet article examine un exemple où l'optimiseur de requête SQL Server 2005 a produit un plan d'exécution supérieur par rapport aux versions ultérieures.
Exemple de tableau et de données
Les exemples de cet article utilisent la table partitionnée et les données suivantes :
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Disposition des données partitionnées
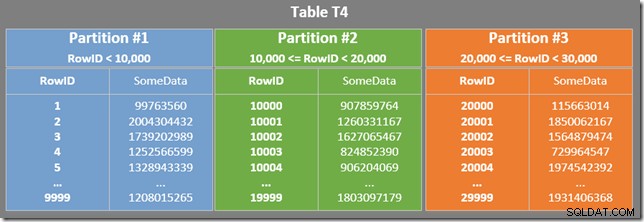
Notre table a un index clusterisé partitionné. Dans ce cas, la clé de clustering sert également de clé de partitionnement (bien que ce ne soit pas une exigence, en général). Le partitionnement se traduit par des unités de stockage physiques distinctes (ensembles de lignes) que le processeur de requêtes présente aux utilisateurs comme une seule entité.
Le schéma ci-dessous montre les trois premières partitions de notre table (cliquez pour agrandir) :
L'index non-cluster est partitionné de la même manière (il est "aligné") :

Chaque partition de l'index non cluster couvre une plage de valeurs RowID. Dans chaque partition, les données sont triées par SomeData (mais les valeurs RowID ne seront pas triées en général).
Le problème MIN/MAX
Il est raisonnablement bien connu que MIN et MAX les agrégats ne s'optimisent pas bien sur les tables partitionnées (à moins que la colonne agrégée ne soit également la colonne de partitionnement). Cette limitation (qui existe toujours dans SQL Server 2014 CTP 1) a été écrite à plusieurs reprises au fil des ans; ma couverture préférée est dans cet article d'Itzik Ben-Gan. Pour illustrer brièvement le problème, considérons la requête suivante :
SELECT MIN(SomeData) FROM dbo.T4;
Le plan d'exécution sur SQL Server 2008 ou supérieur est le suivant :

Ce plan lit les 150 000 lignes de l'index et un Stream Aggregate calcule la valeur minimale (le plan d'exécution est essentiellement le même si nous demandons la valeur maximale à la place). Le plan d'exécution de SQL Server 2005 est légèrement différent (mais pas meilleur) :
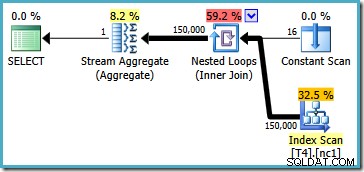
Ce plan itère sur les numéros de partition (répertoriés dans l'analyse constante) en analysant entièrement une partition à la fois. Les 150 000 lignes sont toujours lues et traitées par le Stream Aggregate.
Examinez la table partitionnée et les diagrammes d'index et réfléchissez à la manière dont la requête pourrait être traitée plus efficacement sur notre ensemble de données. L'index non clusterisé semble un bon choix pour résoudre la requête car il contient des valeurs SomeData dans un ordre qui pourrait être exploité lors du calcul de l'agrégat.
Maintenant, le fait que l'index soit partitionné complique un peu les choses :chaque partition de l'index est trié par la colonne SomeData, mais nous ne pouvons pas simplement lire la valeur la plus basse à partir de n'importe quel particular partition pour obtenir la bonne réponse à l'ensemble de la requête.
Une fois que la nature essentielle du problème est comprise, un être humain peut voir qu'une stratégie efficace serait de trouver la seule valeur la plus basse de SomeData dans chaque partition de l'index, puis prenez la valeur la plus basse des résultats par partition.
C'est essentiellement la solution de contournement qu'Itzik présente dans son article; réécrivez la requête pour calculer un agrégat par partition (en utilisant APPLY syntaxe), puis agréger à nouveau ces résultats par partition. En utilisant cette approche, le MIN réécrit query produit ce plan d'exécution (voir l'article d'Itzik pour la syntaxe exacte) :
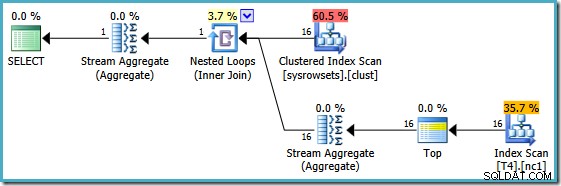
Ce plan lit les numéros de partition à partir d'une table système et récupère la valeur la plus faible de SomeData dans chaque partition. Le Stream Aggregate final calcule simplement le minimum sur les résultats par partition.
La caractéristique importante de ce plan est qu'il lit une ligne unique de chaque partition (en exploitant l'ordre de tri de l'index dans chaque partition). Il est bien plus efficace que le plan de l'optimiseur qui traitait les 150 000 lignes de la table.
MIN et MAX dans une même partition
Considérez maintenant la requête suivante pour trouver la valeur minimale dans la colonne SomeData, pour une plage de valeurs RowID contenues dans une seule partition :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Nous avons vu que l'optimiseur a du mal avec MIN et MAX sur plusieurs partitions, mais nous nous attendrions à ce que ces limitations ne s'appliquent pas à une seule requête de partition.
La partition unique est celle délimitée par les valeurs RowID 10 000 et 20 000 (reportez-vous à la définition de la fonction de partitionnement). La fonction de partitionnement a été définie comme RANGE RIGHT , de sorte que la valeur limite de 10 000 appartient à la partition n° 2 et la limite de 20 000 appartient à la partition n° 3. La plage de valeurs RowID spécifiée par notre nouvelle requête est donc contenue dans la seule partition 2.
Les plans d'exécution graphiques pour cette requête sont identiques sur toutes les versions de SQL Server à partir de 2005 :
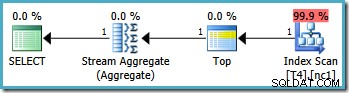
Analyse du plan
L'optimiseur a pris la plage RowID spécifiée dans WHERE clause et l'a comparée à la définition de la fonction de partition pour déterminer que seule la partition 2 de l'index non clusterisé devait être accessible. Les propriétés du plan SQL Server 2005 pour l'analyse de l'index montrent clairement l'accès à une seule partition :
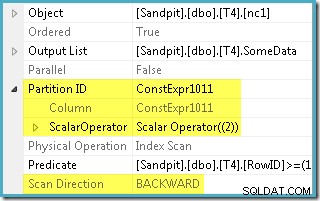
L'autre propriété en surbrillance est la direction de numérisation. L'ordre de l'analyse diffère selon que la requête recherche la valeur minimale ou maximale de SomeData. L'index non clusterisé est ordonné (par partition, rappelez-vous) sur des valeurs SomeData croissantes, de sorte que la direction d'analyse de l'index est FORWARD si la requête demande la valeur minimale, et BACKWARD si la valeur maximale est nécessaire (la capture d'écran ci-dessus a été tirée du MAX plan de requête).
Il existe également un prédicat résiduel sur l'analyse de l'index pour vérifier que les valeurs RowID analysées à partir de la partition 2 correspondent à WHERE prédicat de clause. L'optimiseur suppose que les valeurs RowID sont distribuées de manière assez aléatoire dans l'index non clusterisé, il s'attend donc à trouver la première ligne qui correspond à WHERE prédicat de clause assez rapidement. Le diagramme de disposition des données partitionnées montre que les valeurs RowID sont en effet distribuées de manière assez aléatoire dans l'index (qui est ordonné par la colonne SomeData, rappelez-vous):
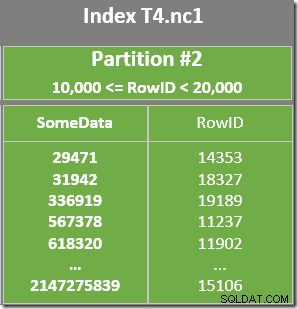
L'opérateur Top dans le plan de requête limite l'analyse de l'index à une seule ligne (à partir de l'extrémité inférieure ou supérieure de l'index en fonction de la direction d'analyse). Les parcours d'index peuvent être problématiques dans les plans de requête, mais l'opérateur Top en fait une option efficace ici :le parcours ne peut produire qu'une seule ligne, puis il s'arrête. La combinaison Top et Ordered Index Scan effectue effectivement une recherche vers la valeur la plus élevée ou la plus basse de l'index qui correspond également à WHERE prédicats de clause. Un Stream Aggregate apparaît également dans le plan pour s'assurer qu'un NULL est généré si aucune ligne n'est renvoyée par l'analyse d'index. Scalaire MIN et MAX les agrégats sont définis pour retourner un NULL lorsque l'entrée est un ensemble vide.
Dans l'ensemble, il s'agit d'une stratégie très efficace, et les plans ont un coût estimé à seulement 0,0032921 unités en conséquence. Jusqu'ici tout va bien.
Le problème de la valeur limite
L'exemple suivant modifie l'extrémité supérieure de la plage RowID :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
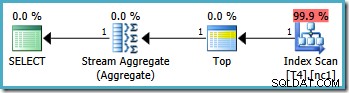
Notez que la requête exclut la valeur 20 000 en utilisant un opérateur "inférieur à". Rappelez-vous que la valeur 20 000 appartient à la partition 3 (pas à la partition 2) car la fonction de partition est définie comme RANGE RIGHT . Le serveur SQL 2005 l'optimiseur gère cette situation correctement, en produisant le plan de requête optimal sur une seule partition, avec un coût estimé à 0,0032878 :
Cependant, la même requête produit un plan différent sur SQL Server 2008 et versions ultérieures (y compris SQL Server 2014 CTP 1) :
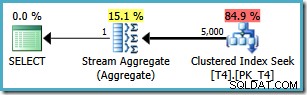
Nous avons maintenant une recherche d'index groupée (au lieu de la combinaison souhaitée de balayage d'index et d'opérateur supérieur). Toutes les 5 000 lignes correspondant à WHERE clause sont traitées via le Stream Aggregate dans ce nouveau plan d'exécution. Le coût estimé de ce plan est de 0,0199319 unités – plus de six fois le coût du plan SQL Server 2005.
Cause
Les optimiseurs SQL Server 2008 (et versions ultérieures) n'obtiennent pas tout à fait la bonne logique interne lorsqu'un intervalle fait référence, mais exclut , une valeur limite appartenant à une partition différente. L'optimiseur pense à tort que plusieurs partitions seront accessibles et conclut qu'il ne peut pas utiliser l'optimisation de partition unique pour MIN et MAX agrégats.
Solutions
Une option consiste à réécrire la requête en utilisant les opérateurs>=et <=afin de ne pas référencer une valeur limite d'une autre partition (même pour l'exclure !) :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
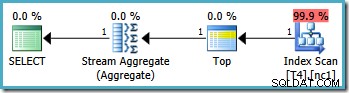
Il en résulte le plan optimal, touchant une seule partition :
Malheureusement, il n'est pas toujours possible de spécifier des valeurs limites correctes de cette manière (selon le type de la colonne de partitionnement). Un exemple de cela est avec les types de date et d'heure où il est préférable d'utiliser des intervalles semi-ouverts. Une autre objection à cette solution de contournement est plus subjective :la fonction de partitionnement exclut une limite de la plage, il semble donc plus naturel d'écrire la requête en utilisant également la syntaxe d'intervalle semi-ouvert.
Une deuxième solution consiste à spécifier explicitement le numéro de partition (et à conserver l'intervalle semi-ouvert) :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Cela produit le plan optimal, au prix d'exiger un prédicat supplémentaire et de compter sur l'utilisateur pour déterminer quel devrait être le numéro de partition.
Bien sûr, il serait préférable que les optimiseurs 2008 et ultérieurs produisent le même plan optimal que SQL Server 2005. Dans un monde parfait, une solution plus complète traiterait également le cas des partitions multiples, rendant également inutile la solution de contournement décrite par Itzik.