[ Partie 1 | Partie 2 | Partie 3 ]
Dans la partie 1, j'ai montré comment la compression de page et de columnstore pouvait réduire la taille d'une table de 1 To de 80 % ou plus. Bien que j'aie été impressionné de pouvoir réduire une table de 1 To à 50 Go, je n'étais pas très satisfait du temps que cela a pris (de 2 à 14 heures). Avec quelques conseils gracieusement empruntés à des gens comme Joe Obbish, Lonny Niederstadt, Niko Neugebauer et d'autres, dans cet article, je vais essayer d'apporter quelques modifications à ma tentative initiale d'obtenir de meilleures performances de charge. Étant donné que l'index columnstore normal n'a pas compressé mieux que la compression de page sur cet ensemble de données , et qu'il a fallu 13 heures de plus pour y parvenir, je me concentrerai uniquement sur la solution la plus avancée utilisant COLUMNSTORE_ARCHIVE compression.
Voici quelques-uns des problèmes qui, selon moi, ont affecté les performances :
- Mauvais choix de mise en page des fichiers - J'ai mis 8 fichiers dans un groupe de fichiers, avec du parallélisme mais pas de partitionnement (ou sous-optimal), pulvérisant des E/S sur plusieurs fichiers avec un abandon imprudent. Pour résoudre ce problème, je vais :
- partitionnez la table en 8 partitions (une par cœur)
- placer le fichier de données de chaque partition sur son propre groupe de fichiers
- utiliser 8 processus distincts pour établir une affinité avec chaque partition
- utiliser la compression d'archive sur toutes les partitions sauf la partition "active"
- trop de petits lots et population de groupes de lignes sous-optimale - en traitant 10 millions de lignes à la fois, je remplissais neuf groupes de lignes avec 1 048 576 lignes agréables, puis les 562 816 lignes restantes se retrouveraient dans un autre groupe de lignes plus petit. Et toute distribution inégale qui laissait un reste <102 400 lignes entraînerait des insertions dans la structure moins efficace du magasin delta. Pour répartir les lignes plus uniformément et éviter le stockage delta, je vais :
- traiter autant de données que possible en multiples exacts de 1 048 576 lignes
- répartissez-les sur 8 partitions aussi uniformément que possible
- utiliser une taille de lot plus proche de 10 x -> 100 millions de lignes
- Empilement du planificateur - même si je n'ai pas vérifié cela, il est possible qu'une partie du ralentissement ait été causée par un planificateur prenant trop de travail et un autre pas assez, en raison de la répétition alternée des planificateurs. Maintenant que je vais charger intentionnellement les données avec 8 processus maxdop 1 au lieu d'un processus maxdop 8, pour que tous les planificateurs soient également occupés, je vais :
- utiliser une procédure stockée qui tente de s'équilibrer uniformément entre les planificateurs (voir les pages 189-191 du Guide de SQLCAT sur :le moteur relationnel pour l'inspiration derrière cette idée)
- activer l'indicateur de trace global 2467 et 2469, comme indiqué dans la documentation
- tâche de compression columnstore en arrière-plan - c'était du gaspillage de laisser cela fonctionner pendant la population, puisque j'avais prévu de reconstruire à la fin de toute façon. Cette fois, je vais :
- désactiver cette tâche à l'aide de l'indicateur de trace global 634
J'ai supprimé la fonction et le schéma de partition initiaux, et j'en ai construit un nouveau basé sur une distribution plus uniforme des données. Je veux que 8 partitions correspondent au nombre de cœurs et au nombre de fichiers de données, afin de maximiser le "parallélisme du pauvre" que je prévois d'utiliser.
Tout d'abord, nous devons créer un nouvel ensemble de groupes de fichiers, chacun avec son propre fichier :
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
Ensuite, j'ai regardé le nombre de lignes dans le tableau :3 754 965 954. Pour les distribuer exactement uniformément sur 8 partitions, ce serait 469 370 744,25 lignes par partition. Pour que cela fonctionne bien, faisons en sorte que les limites de la partition s'adaptent au suivant multiple de 1 048 576 lignes. C'est 1,048,576 x 448 = 469,762,048 - qui serait le nombre de lignes que nous visons dans les 7 premières partitions, laissant 466 631 618 lignes dans la dernière partition. Pour voir l'OID réel valeurs qui serviraient de limites pour contenir le nombre optimal de lignes dans chaque partition, j'ai exécuté cette requête sur la table d'origine (puisqu'il a fallu 25 minutes pour s'exécuter, j'ai rapidement appris à vider ces résultats dans une table séparée):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
 Plus à déballer ici que vous ne le pensez. Le CTE fait tout le gros du travail, car il doit analyser l'intégralité de la table de 1,14 To et attribuer un numéro de ligne à chaque ligne . Je veux seulement retourner tous les
Plus à déballer ici que vous ne le pensez. Le CTE fait tout le gros du travail, car il doit analyser l'intégralité de la table de 1,14 To et attribuer un numéro de ligne à chaque ligne . Je veux seulement retourner tous les (1048576*112)th ligne, cependant, comme ce sont mes lignes de limite de lot, c'est donc ce que le WHERE clause le fait. Rappelez-vous que je veux diviser le travail en lots plus près de 100 millions de lignes à la fois, mais je ne veux pas non plus vraiment traiter 469 millions de lignes en une seule fois. Donc, en plus de diviser les données en 8 partitions, je souhaite diviser chacune de ces partitions en quatre lots de 117 440 512 (1,048,576*112) Lignes. Chaque ensemble adjacent de quatre lots appartient à une partition, donc le PartitionID Je dérive ajoute juste un au résultat du numéro de ligne actuel entier divisé par (1,048,576*448) , ce qui garantit que la limite est toujours dans l'ensemble "gauche". Nous ajoutons ensuite un au résultat car sinon nous ferions référence à une collection de partitions basée sur 0, et personne ne veut cela.
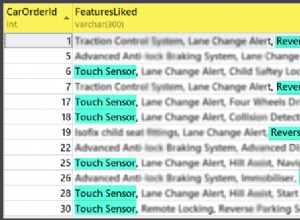
Ok, c'était beaucoup de mots. A droite se trouve une image montrant le contenu (abrégé) de l'stage tableau (cliquez pour afficher le résultat complet, en mettant en surbrillance les valeurs limites de la partition).
Nous pouvons ensuite dériver une autre requête de cette table intermédiaire qui nous montre les valeurs min et max pour chaque lot à l'intérieur de chaque partition, ainsi que le lot supplémentaire non pris en compte (les lignes de la table d'origine avec OID supérieure à la valeur limite la plus élevée) :
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
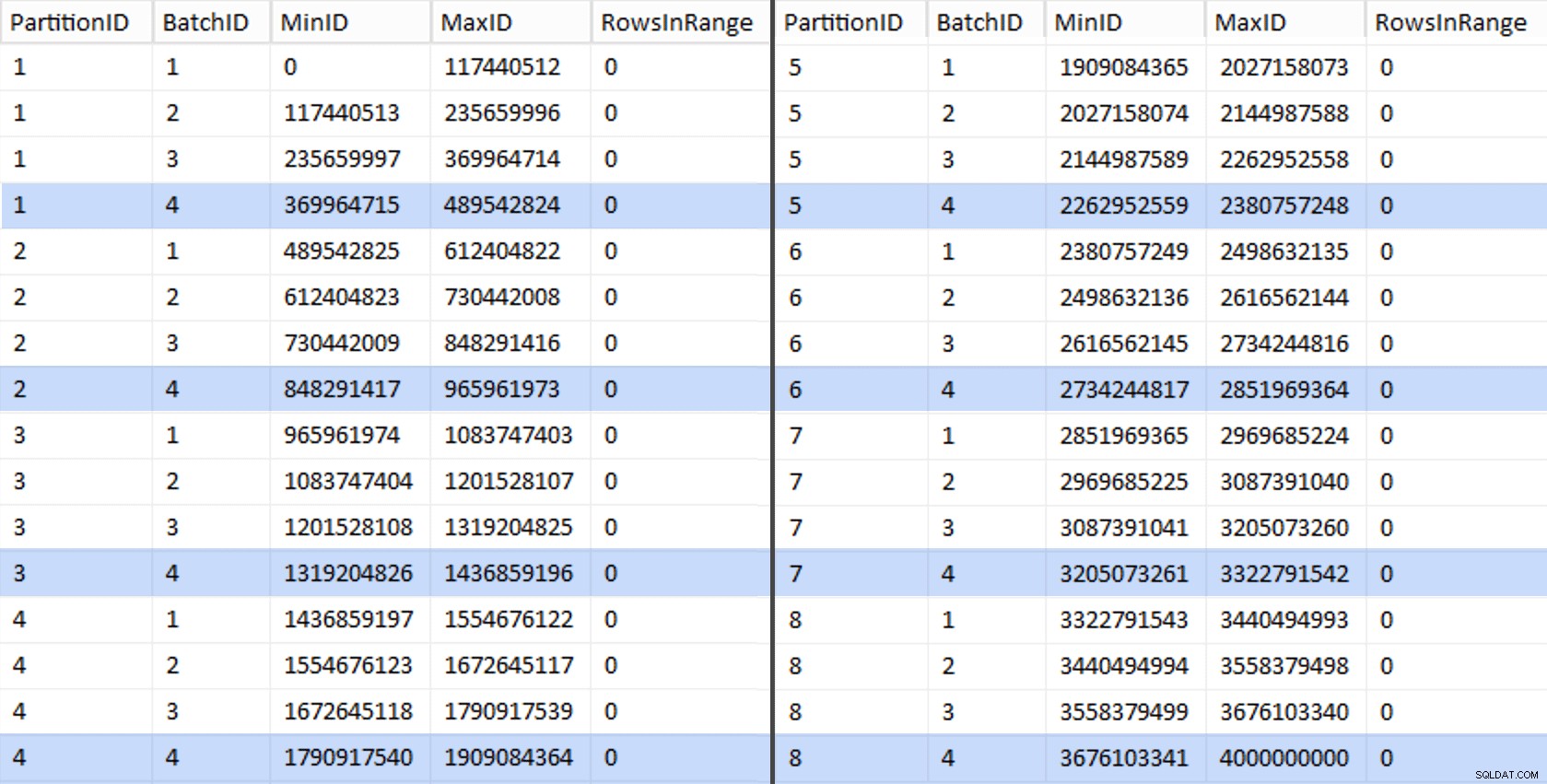
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Ces valeurs ressemblent à ceci :
Pour tester notre travail, nous pouvons en dériver un ensemble de requêtes qui mettront à jour BatchQueue avec le nombre réel de lignes de la table.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; Cela a pris environ 6 minutes sur mon système. Ensuite, vous pouvez exécuter la requête suivante pour montrer que chaque lot, à l'exception du tout dernier, est capable de remplir entièrement les groupes de lignes et de ne laisser aucun reste pour une utilisation potentielle du magasin delta :
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Le tableau ressemble maintenant à ceci :
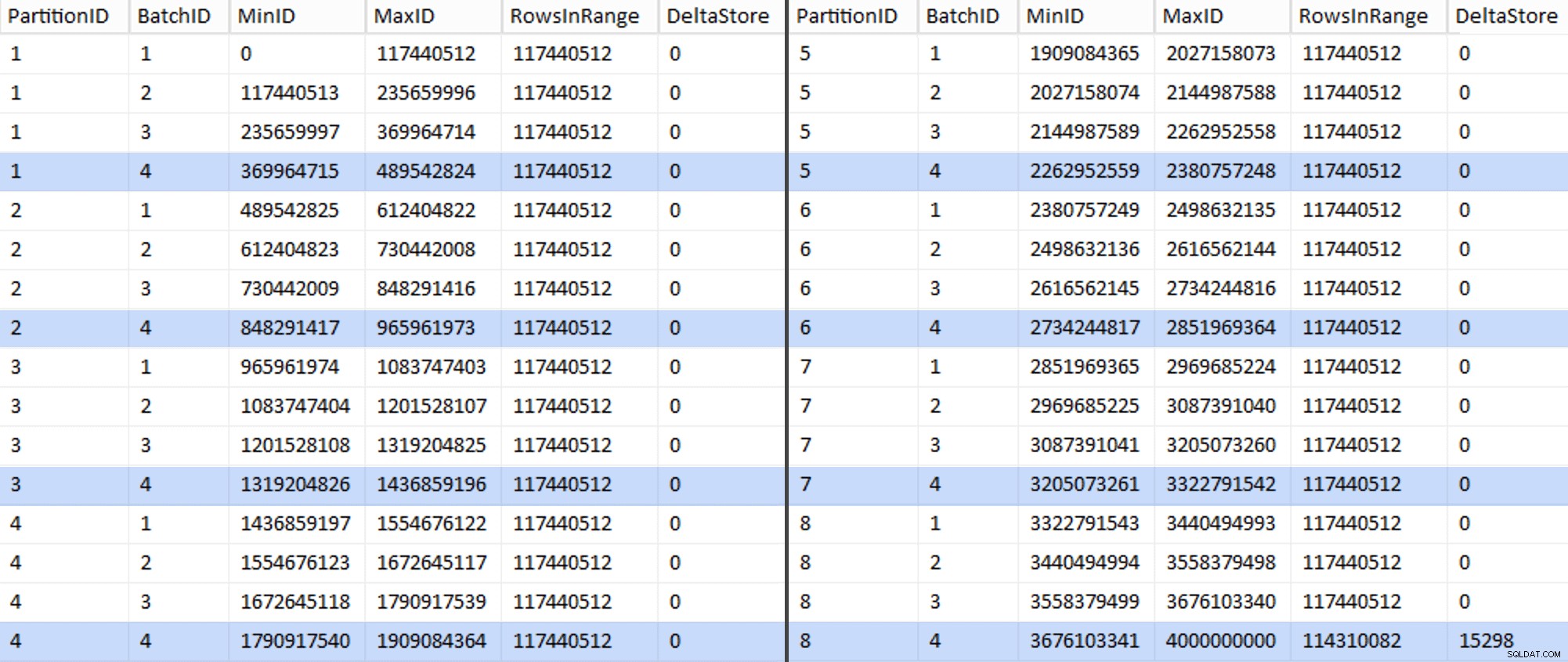
Effectivement, chaque lot contient les 117 440 512 millions de lignes calculées, à l'exception de la dernière qui contiendra, au moins idéalement, notre seul magasin delta non compressé. Nous pouvons probablement empêcher cela aussi, en modifiant légèrement la taille du lot pour cette partition de sorte que les quatre lots soient exécutés avec la même taille, ou en modifiant le nombre de lots pour s'adapter à un autre multiple de 102 400 ou 1 048 576. Puisque cela nécessiterait d'obtenir un nouveau OID valeurs de la table de base, ajoutant encore 25 minutes supplémentaires à notre effort de migration, je vais laisser glisser cette partition imparfaite, d'autant plus que nous n'en tirons pas de toute façon tous les avantages de la compression d'archivage.
La BatchQueue La table commence à montrer des signes d'utilité pour le traitement de nos lots afin de migrer les données vers notre nouvelle table columnstore partitionnée et en cluster. Que nous devons créer, maintenant que nous connaissons les limites. Il n'y a que 7 limites, donc vous pouvez certainement le faire manuellement, mais j'aime laisser SQL dynamique faire mon travail pour moi :
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Résultats :
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Une fois cela créé, nous pouvons créer notre schéma de partition et attribuer chaque partition successive à son fichier dédié :
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Nous pouvons maintenant créer la table et la préparer pour la migration :
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
Dans la partie 3, je configurerai davantage le BatchQueue table, créez une procédure pour que les processus poussent les données vers la nouvelle structure et analysez les résultats.
[ Partie 1 | Partie 2 | Partie 3 ]