[ Partie 1 | Partie 2 | Partie 3 ]
Récemment, quelqu'un au travail a demandé plus d'espace pour accueillir une table en croissance rapide. À l'époque, il comptait 3,75 milliards de lignes, présentées sur 143 millions de pages et occupant environ 1,14 To. Bien sûr, nous pouvons toujours jeter plus de disque sur une table, mais je voulais voir si nous pouvions faire évoluer cela plus efficacement que la tendance linéaire actuelle. Sonne comme un excellent travail pour la compression, non? Mais je voulais aussi essayer d'autres solutions, y compris columnstore - que les gens sont étonnamment réticents à essayer. Je ne suis pas Niko, mais je voulais faire un effort pour voir ce qu'il pouvait faire pour nous ici.
Notez que je ne me concentre pas sur les rapports de charge de travail ou d'autres performances des requêtes de lecture pour le moment. Je veux simplement voir quel impact je peux avoir sur l'empreinte de stockage (et de mémoire) de ces données.
Voici le tableau d'origine. J'ai changé les noms des tables et des colonnes pour protéger les innocents, mais tout le reste est relativement précis.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Il y a d'autres petites choses là-dedans qui sont plus larges qu'elles ne devraient l'être et/ou que la compression de ligne pourrait nettoyer, comme celles numeric(24,12) et bigint colonnes qui peuvent être prématurément surdimensionnées, mais je ne vais pas retourner voir l'équipe d'application et déterminer s'il y a peu d'efficacité là-bas, et je vais ignorer la compression des lignes pour cet exercice et me concentrer sur la page et la compression du magasin de colonnes.
Il s'agit d'une copie des données, sur un serveur inactif (8 cœurs, 64 Go de RAM), avec beaucoup d'espace disque (bien plus de 6 To). Alors d'abord, ajoutons quelques groupes de fichiers, un pour le magasin de colonnes en cluster standard et un pour une version partitionnée de la table (où toutes les partitions sauf la plus récente seront compressées avec COLUMNSTORE_ARCHIVE , puisque toutes ces données plus anciennes sont désormais "en lecture seule et rarement") :
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
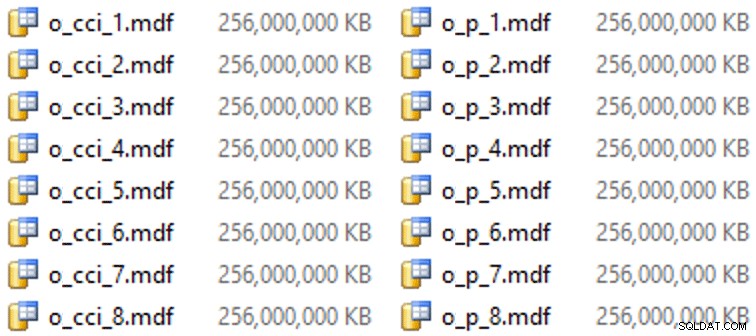
Et puis quelques fichiers pour ces groupes de fichiers (un fichier par cœur, agréable et de taille uniforme à 256 Go) :
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Sur ce matériel particulier (YMMV !), cela prenait environ 10 secondes par fichier et donnait ce qui suit :
Pour générer les partitions, j'ai naïvement divisé les données "également" - du moins le pensais-je. J'ai juste pris les 3,75 milliards de lignes et les ai partitionnées en quelque chose que je pensais être gérable :38 partitions avec 100 millions de lignes dans les 37 premières partitions, et le reste dans la dernière. (Rappelez-vous, ce n'est que la partie 1 ! Il existe une hypothèse inhérente ici sur la distribution égale des valeurs dans la table source, et également sur ce qui est optimal pour la population de groupes de lignes dans la table de destination.) La création du schéma de partition et de la fonction pour cela est aussi suit :
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
J'utilise RANGE LEFT car, comme Cathrine Wilhelmsen continue de me le rappeler, cela signifie que la valeur limite fait partie de la partition à sa gauche. En d'autres termes, les valeurs que je spécifie sont les valeurs maximales dans chaque partition (avec les dates, vous voulez généralement RANGE RIGHT ).
J'ai ensuite créé deux copies de la table, une sur chaque groupe de fichiers. Le premier avait un index cluster columnstore standard, les seules différences étant le OID la colonne n'est pas une IDENTITY et la colonne calculée est juste un varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Le second a été construit sur le schéma de partition, il fallait donc d'abord un PK nommé, qui a ensuite dû être remplacé par un index de magasin de colonnes en cluster (bien que Brent Ozar montre dans ce bref article qu'il existe une syntaxe non intuitive qui accomplira cela en moins d'étapes ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Ensuite, afin de mettre la compression d'archive sur toutes les partitions sauf la dernière, j'ai exécuté ce qui suit :
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Maintenant, j'étais prêt à remplir ces tableaux avec des données, à mesurer le temps nécessaire et la taille résultante, et à comparer. J'ai modifié un script de traitement par lots utile d'Andy Mallon et inséré les lignes dans les deux tables de manière séquentielle, avec une taille de lot de 10 millions de lignes. Il y a beaucoup plus que cela dans le vrai script (y compris la mise à jour d'une table de file d'attente avec la progression), mais en gros :
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Après avoir rempli les deux tables columnstore à partir de la source d'origine (non compressée), j'ai reconstruit à nouveau ces partitions pour nettoyer tout désordre de groupes de lignes et de dictionnaires. Enfin, j'ai appliqué la compression de page, en place, à la table source. Voici les délais et les résultats de compression de chaque type :
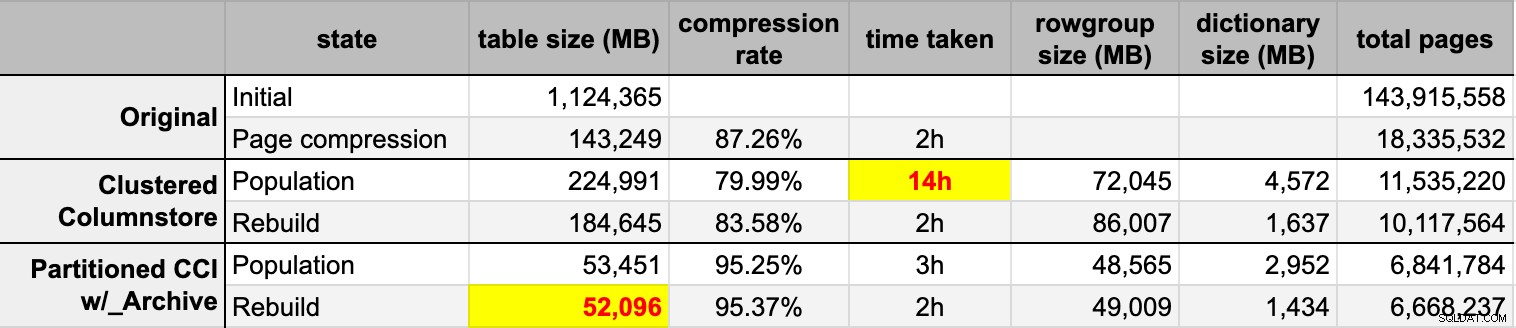
Je suis à la fois impressionné et déçu. Impressionné parce que ces données se compriment très bien - réduire l'empreinte de stockage à 5% du 1 To d'origine est assez incroyable. Déçu car :
- J'ai créé ces fichiers de données façon trop grand.
- Je ne comprends pas ce qui s'est passé avec la compression initiale du columnstore de 14 heures :
- Je n'ai observé aucune pression sur la mémoire ou le journal.
- Aucun événement de croissance de fichier n'a eu lieu.
- Malheureusement, je n'ai pas pensé à suivre les temps d'attente. Non, je ne vais pas réessayer. :-)
- La compression des pages a surpassé la compression classique du columnstore, peut-être en raison des données.
- La reconstruction des partitions d'archive columnstore a utilisé beaucoup de temps CPU pour un gain presque nul.
Dans les prochains articles, et après avoir passé en revue mes notes d'une incroyable présentation columnstore par Joe Obbish au PASS Summit (auquel je ferais un lien direct, si seulement PASS savait comment utiliser l'interface utilisateur), je parlerai un peu des changements que je vais apporter à la configuration du serveur et à mon script de population pour voir si je peux obtenir de meilleures performances de la population du columnstore.
[ Partie 1 | Partie 2 | Partie 3 ]