Problème
Dans cet article, nous allons nous concentrer sur la démonstration du partitionnement de table. L'explication la plus simple du partitionnement de table peut être appelée la division de grandes tables en petites. Cette rubrique offre évolutivité et facilité de gestion.
Qu'est-ce que le partitionnement de table dans SQL Server ?
Supposons que nous ayons une table et qu'elle grandisse de jour en jour. Dans ce cas, le tableau peut poser des problèmes qui doivent être résolus par les étapes définies ci-dessous :
- Maintenir ce tableau. Cela prendra beaucoup de temps et consommera plus de ressources (CPU, IO, etc.).
- Sauvegarder.
- Problèmes de verrouillage.
Pour les raisons mentionnées ci-dessus, nous avons besoin d'un partitionnement de table. Cette approche présente les avantages suivants :
- Capacité de gestion :si nous séparons la table, nous pouvons gérer chaque partition de la table. Par exemple, nous pouvons créer une seule partition de la table.
- Capacité d'archivage :certaines partitions de la table sont utilisées uniquement pour cette raison. Nous n'avons pas besoin de sauvegarder cette partition de la table. Nous pouvons utiliser une sauvegarde de groupe de fichiers et la sauvegarder uniquement en modifiant une partition de la table.
- Performances des requêtes :l'optimiseur de requêtes SQL Server décide d'utiliser l'élimination de partition. Cela signifie que SQL Server n'effectue aucune recherche sur la partition non liée de la table.
Partitionnement vertical et horizontal des tables dans SQL Server
Le partitionnement de table est un concept général. Il existe plusieurs types de partitionnement qui fonctionnent pour des cas particuliers. Les deux approches les plus essentielles et les plus utilisées sont :le partitionnement vertical et le partitionnement horizontal.
La spécificité de chaque type reflète l'essence d'un tableau en tant que structure composée de colonnes et de lignes :
• Le partitionnement vertical divise le tableau en colonnes.
• Le partitionnement horizontal divise le tableau en lignes.
L'exemple le plus typique de partitionnement de table verticale est une table d'employés avec leurs détails - noms, e-mails, numéros de téléphone, adresses, anniversaires, professions, salaires et toutes les autres informations qui pourraient être nécessaires. Une partie de ces données est confidentielle. De plus, dans la plupart des cas, les opérateurs n'ont besoin que de quelques données de base comme les noms et les adresses e-mail.
Le partitionnement vertical crée plusieurs tables "plus étroites" avec les données nécessaires à portée de main. Les requêtes ciblent uniquement une partie spécifique. De cette façon, les entreprises réduisent la charge, accélèrent les tâches et s'assurent que les données confidentielles ne seront pas révélées.
Le partitionnement horizontal des tables entraîne la division d'une table générale en plusieurs plus petites, où chaque table de particules a le même nombre de colonnes, mais le nombre de lignes est inférieur. Il s'agit d'une approche standard pour les tableaux excessifs avec des données chronologiques.
Par exemple, un tableau avec les données pour toute l'année peut être divisé en sections plus petites pour chaque mois ou semaine. Ensuite, la requête ne concernera qu'une seule petite table spécifique. Le partitionnement horizontal améliore l'évolutivité des volumes de données avec leur croissance. Les tables partitionnées resteront plus petites et faciles à traiter.
Tout partitionnement de table dans SQL Server doit être considéré avec soin. Parfois, vous devez demander les données de plusieurs tables partitionnées à la fois, puis vous aurez besoin de JOIN dans les requêtes. De plus, le partitionnement vertical peut toujours donner lieu à de grandes tables et vous devrez les diviser davantage. Dans votre travail, vous devez vous fier aux décisions prises pour vos objectifs commerciaux spécifiques.
Maintenant que nous avons clarifié le concept de partitionnement de table dans SQL Server, il est temps de passer à la démonstration.
Nous allons éviter tout script T-SQL et gérer toutes les étapes de partitionnement de table avec l'assistant de partitionnement SQL Server.
De quoi avez-vous besoin pour créer des partitions de base de données SQL ?
- Exemple de base de données WideWorldImporters
- SQL Server 2017 Édition Développeur
L'image ci-dessous nous montre comment concevoir une partition de table. Nous allons créer une partition de table par années et localiser différents groupes de fichiers.

A cette étape, nous allons créer deux groupes de fichiers (FG_2013, FG_2014). Cliquez avec le bouton droit sur une base de données, puis cliquez sur l'onglet Groupes de fichiers.

Maintenant, nous allons connecter les groupes de fichiers aux nouveaux fichiers pdf.

Notre structure de stockage de base de données est prête pour le partitionnement de table. Nous allons localiser la table que nous voulons partitionner et lancer l'assistant de création de partition.


Sur la capture d'écran ci-dessous, nous allons sélectionner une colonne sur laquelle nous voulons appliquer la fonction de partition. La colonne sélectionnée est "InvoiceDate".

Sur les deux écrans suivants, nous nommerons une fonction de partition et un schéma de partition.
Une fonction de partition définira comment partitionner les lignes [Sales].[Invoices] en fonction de la colonne InvoiceDate.

Un schéma de partition définira les correspondances entre les lignes Sales.Invoices et les groupes de fichiers.

Attribuez les partitions aux groupes de fichiers et définissez les limites.
Limite gauche/droite définit le côté de chaque intervalle de valeur limite qui peut être à gauche ou à droite. Nous allons définir des limites comme celle-ci et cliquer sur Estimer le stockage. Cette option nous fournit les informations sur le nombre de lignes à situer dans les limites.

Et enfin, nous sélectionnerons Exécuter immédiatement puis cliquerons sur Suivant.

Une fois l'opération réussie, cliquez sur Fermer.

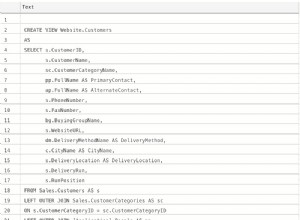
Comme vous pouvez le voir, notre table Sales.Invoices a été partitionnée. Cette requête affichera les détails de la table partitionnée.
SELECT
OBJECT_SCHEMA_NAME(pstats.object_id) AS SchemaName
,OBJECT_NAME(pstats.object_id) AS TableName
,ps.name AS PartitionSchemeName
,ds.name AS PartitionFilegroupName
,pf.name AS PartitionFunctionName
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Range Left' ELSE 'Range Right' END AS PartitionFunctionRange
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Upper Boundary' ELSE 'Lower Boundary' END AS PartitionBoundary
,prv.value AS PartitionBoundaryValue
,c.name AS PartitionKey
,CASE
WHEN pf.boundary_value_on_right = 0
THEN c.name + ' > ' + CAST(ISNULL(LAG(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' <= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100))
ELSE c.name + ' >= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' < ' + CAST(ISNULL(LEAD(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100))
END AS PartitionRange
,pstats.partition_number AS PartitionNumber
,pstats.row_count AS PartitionRowCount
,p.data_compression_desc AS DataCompression
FROM sys.dm_db_partition_stats AS pstats
INNER JOIN sys.partitions AS p ON pstats.partition_id = p.partition_id
INNER JOIN sys.destination_data_spaces AS dds ON pstats.partition_number = dds.destination_id
INNER JOIN sys.data_spaces AS ds ON dds.data_space_id = ds.data_space_id
INNER JOIN sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id
INNER JOIN sys.partition_functions AS pf ON ps.function_id = pf.function_id
INNER JOIN sys.indexes AS i ON pstats.object_id = i.object_id AND pstats.index_id = i.index_id AND dds.partition_scheme_id = i.data_space_id AND i.type <= 1 /* Heap or Clustered Index */
INNER JOIN sys.index_columns AS ic ON i.index_id = ic.index_id AND i.object_id = ic.object_id AND ic.partition_ordinal > 0
INNER JOIN sys.columns AS c ON pstats.object_id = c.object_id AND ic.column_id = c.column_id
LEFT JOIN sys.partition_range_values AS prv ON pf.function_id = prv.function_id AND pstats.partition_number = (CASE pf.boundary_value_on_right WHEN 0 THEN prv.boundary_id ELSE (prv.boundary_id+1) END)
WHERE pstats.object_id = OBJECT_ID('Sales.Invoices')
ORDER BY TableName, PartitionNumber;

MS Performances de partitionnement SQL Server
Nous allons comparer les performances des tables partitionnées et non partitionnées pour la même table. Pour ce faire, utilisez la requête ci-dessous et activez Inclure le plan d'exécution réel.
DECLARE @Dt as date = '20131231'
SELECT COUNT(InvoiceDate)
FROM [Sales].[Invoices]
where InvoiceDate < @Dt


Lorsque nous examinons le plan d'exécution, nous apprenons qu'il inclut les propriétés "Partitionné", "Nombre réel de partitions" et "Accès partitionné réel".
La propriété partitionnée indique que cette table est activée pour la partition.
Le nombre réel de partitions La propriété est le nombre total de partitions lues par le moteur SQL Server.
L'Accès partitionné réel La propriété correspond aux numéros de partition évalués par le moteur SQL Server. SQL Server élimine l'accès pour les autres partitions car cela s'appelle une élimination de partition et gagne un avantage sur les performances des requêtes.
Maintenant, regardez le plan d'exécution de la table non partitionnée.

La principale différence entre ces deux plans d'exécution est le Nombre de lignes lues car cette propriété indique le nombre de lignes lues pour cette requête. Comme vous pouvez le voir dans le tableau de compression ci-dessous, les valeurs des tables partitionnées sont trop faibles. Pour cette raison, il consommera un faible IO.

Ensuite, exécutez la requête et examinez le plan d'exécution.
DECLARE @DtBeg as date = '20140502'
DECLARE @DtEnd as date = '20140701'
SELECT COUNT(InvoiceDate)
FROM [Sales].[Invoices]
where InvoiceDate between @DtBeg and @DtEnd

Escalade des verrous au niveau de la partition
L'escalade de verrous est un mécanisme utilisé par SQL Server Lock Manager. Il s'arrange pour verrouiller un niveau d'objets. Lorsque le nombre de lignes à verrouiller augmente, le gestionnaire de verrous modifie un objet de verrouillage. Il s'agit du niveau hiérarchique d'escalade de verrous "Ligne -> Page -> Table -> Base de données". Mais, dans la table partitionnée, nous pouvons verrouiller une partition car cela augmente la simultanéité et les performances. Le niveau par défaut d'escalade de verrous est "TABLE" dans SQL Server.
Exécutez la requête à l'aide de l'instruction UPDATE ci-dessous.
BEGIN TRAN
DECLARE @Dt as date = '20131221'
UPDATE [Sales].[Invoices] SET CreditNoteReason = 'xxx' where InvoiceDate < @Dt
SP_LOCK

La case rouge définit un verrou exclusif qui garantit que plusieurs mises à jour ne peuvent pas être effectuées sur la même ressource en même temps. Il apparaît dans le tableau Factures.
Maintenant, nous allons définir le mode d'escalade pour la table Sales.Invoices pour l'automatiser et relancer la requête.
ALTER TABLE Sales.Invoices SET (LOCK_ESCALATION = AUTO)
Maintenant, la case rouge définit le verrou exclusif d'indentation qui protège les verrous exclusifs demandés ou acquis sur certaines ressources plus bas dans la hiérarchie. En peu de temps, ce niveau de verrouillage nous permet de mettre à jour ou de supprimer d'autres partitions de tables. Cela signifie que nous pouvons démarrer une autre mise à jour ou insérer une autre partition de la table.
Dans les articles précédents, nous avons également exploré le problème du basculement entre le partitionnement de table et fourni la procédure pas à pas. Ces informations peuvent vous être utiles si vous traitez ces cas. Reportez-vous à l'article pour plus d'informations.
Références
- Modes de verrouillage
- Tables et index partitionnés