T-SQL Tuesday #78 est hébergé par Wendy Pastrick, et le défi ce mois-ci est simplement "d'apprendre quelque chose de nouveau et de bloguer à ce sujet". Son texte de présentation se penche sur les nouvelles fonctionnalités de SQL Server 2016, mais depuis que j'ai blogué et présenté bon nombre d'entre elles, j'ai pensé que j'explorerais quelque chose d'autre de première main qui m'a toujours vraiment intéressé.
J'ai vu plusieurs personnes déclarer qu'un tas peut être meilleur qu'un index clusterisé pour certains scénarios. Je ne peux pas être en désaccord avec cela. L'une des raisons intéressantes que j'ai vues, cependant, est qu'une recherche RID est plus rapide qu'une recherche de clé. Je suis un grand fan des index clusterisés et pas un grand fan des tas, donc j'ai pensé que cela nécessitait des tests.
Alors, testons-le !
J'ai pensé qu'il serait bon de créer une base de données avec deux tables, identiques sauf que l'une avait une clé primaire en cluster et l'autre avait une clé primaire non en cluster. Je chronométrais le chargement de certaines lignes dans la table, la mise à jour d'un groupe de lignes dans une boucle et la sélection à partir d'un index (forçant une recherche de clé ou de RID).
Spécifications du système
Cette question revient souvent, alors pour clarifier les détails importants sur ce système, je suis sur une machine virtuelle à 8 cœurs avec 32 Go de RAM, soutenu par un stockage PCIe. La version de SQL Server est 2014 SP1 CU6, sans modification de configuration spéciale ni indicateur de trace en cours d'exécution :
Microsoft SQL Server 2014 (SP1-CU6) (KB3144524) – 12.0.4449.0 (X64)13 avril 2016 12:41:07
Copyright (c) Microsoft Corporation
Developer Edition (64- bit) sous Windows NT 6.3
La base de données
J'ai créé une base de données avec beaucoup d'espace libre à la fois dans les données et dans le fichier journal afin d'empêcher tout événement de croissance automatique d'interférer avec les tests. J'ai également défini la base de données sur une récupération simple pour minimiser l'impact sur le journal des transactions.
CREATE DATABASE HeapVsCIX ON ( name = N'HeapVsCIX_data', filename = N'C:\...\HeapCIX.mdf', size = 100MB, filegrowth = 10MB ) LOG ON ( name = N'HeapVsCIX_log', filename = 'C:\...\HeapCIX.ldf', size = 100MB, filegrowth = 10MB ); GO ALTER DATABASE HeapVsCIX SET RECOVERY SIMPLE;
Les tableaux
Comme je l'ai dit, deux tables, la seule différence étant de savoir si la clé primaire est en cluster.
CREATE TABLE dbo.ObjectHeap ( ObjectID int PRIMARY KEY NONCLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oh_name ON dbo.ObjectHeap(Name) INCLUDE(SchemaID); CREATE TABLE dbo.ObjectCIX ( ObjectID INT PRIMARY KEY CLUSTERED, Name sysname, SchemaID int, ModuleDefinition nvarchar(max) ); CREATE INDEX oc_name ON dbo.ObjectCIX(Name) INCLUDE(SchemaID);
Un tableau pour capturer le temps d'exécution
Je pourrais surveiller le processeur et tout cela, mais la curiosité tourne presque toujours autour de l'exécution. J'ai donc créé une table de journalisation pour capturer le temps d'exécution de chaque test :
CREATE TABLE dbo.Timings ( Test varchar(32) NOT NULL, StartTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME(), EndTime datetime2 );
Le test d'insertion
Alors, combien de temps faut-il pour insérer 2 000 lignes, 100 fois ? Je récupère quelques données assez basiques de sys.all_objects , et en tirant la définition de toutes les procédures, fonctions, etc. :
INSERT dbo.Timings(Test) VALUES('Inserting Heap');
GO
TRUNCATE TABLE dbo.ObjectHeap;
INSERT dbo.ObjectHeap(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
-- CIX:
INSERT dbo.Timings(Test) VALUES('Inserting CIX');
GO
TRUNCATE TABLE dbo.ObjectCIX;
INSERT dbo.ObjectCIX(ObjectID, Name, SchemaID, ModuleDefinition)
SELECT TOP (2000) [object_id], name, [schema_id], OBJECT_DEFINITION([object_id])
FROM sys.all_objects ORDER BY [object_id];
GO 100
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Le test de mise à jour
Pour le test de mise à jour, je voulais juste tester la vitesse d'écriture dans un index clusterisé par rapport à un tas d'une manière très ligne par ligne. J'ai donc vidé 200 lignes aléatoires dans une table #temp, puis j'ai construit un curseur autour de celle-ci (la table #temp garantit simplement que les mêmes 200 lignes sont mises à jour dans les deux versions de la table, ce qui est probablement exagéré).
CREATE TABLE #IdsToUpdate(ObjectID int PRIMARY KEY CLUSTERED);
INSERT #IdsToUpdate(ObjectID)
SELECT TOP (200) ObjectID
FROM dbo.ObjectCIX ORDER BY NEWID();
GO
INSERT dbo.Timings(Test) VALUES('Updating Heap');
GO
-- update speed - update 200 rows 1,000 times
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectHeap SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Updating CIX');
GO
DECLARE @id int;
DECLARE c CURSOR LOCAL FORWARD_ONLY
FOR SELECT ObjectID FROM #IdsToUpdate;
OPEN c; FETCH c INTO @id;
WHILE @@FETCH_STATUS <> -1
BEGIN
UPDATE dbo.ObjectCIX SET Name = REPLACE(Name,'s','u') WHERE ObjectID = @id;
FETCH c INTO @id;
END
CLOSE c; DEALLOCATE c;
GO 1000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Le test de sélection
Donc, ci-dessus, vous avez vu que j'ai créé un index avec Name comme colonne clé dans chaque tableau ; afin d'évaluer le coût d'exécution des recherches pour un nombre important de lignes, j'ai écrit une requête qui affecte la sortie à une variable (éliminant les E/S réseau et le temps de rendu client), mais force l'utilisation de l'index :
INSERT dbo.Timings(Test) VALUES('Forcing RID Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectHeap WITH (INDEX(oh_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL;
GO
INSERT dbo.Timings(Test) VALUES('Forcing Key Lookup');
GO
DECLARE @x nvarchar(max);
SELECT @x = ModuleDefinition FROM dbo.ObjectCIX WITH (INDEX(oc_name)) WHERE Name LIKE N'S%';
GO 10000
UPDATE dbo.Timings SET EndTime = SYSUTCDATETIME() WHERE EndTime IS NULL; Pour celui-ci, je voulais montrer quelques aspects intéressants des plans avant de rassembler les résultats des tests. Les exécuter individuellement en tête-à-tête fournit ces statistiques comparatives :

La durée est sans importance pour une seule instruction, mais regardez ces lectures. Si vous utilisez un stockage lent, c'est une grande différence que vous ne verrez pas à plus petite échelle et/ou sur votre SSD de développement local.
Et puis les plans montrant les deux recherches différentes, à l'aide de SQL Sentry Plan Explorer :

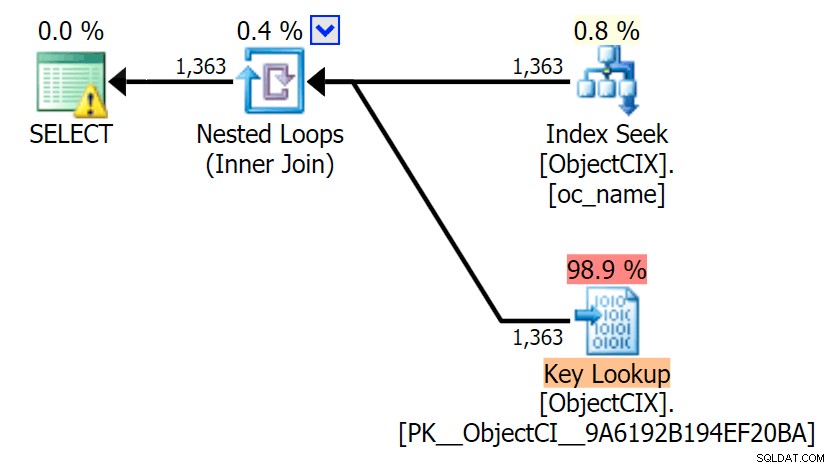
Les plans semblent presque identiques et vous ne remarquerez peut-être pas la différence de lectures dans SSMS à moins que vous ne capturiez les E/S statistiques. Même les coûts d'E/S estimés pour les deux recherches étaient similaires :1,69 pour la recherche de clé et 1,59 pour la recherche RID. (L'icône d'avertissement dans les deux plans est pour un index de couverture manquant.)
Il est intéressant de noter que si nous ne forçons pas une recherche et laissons SQL Server décider quoi faire, il choisit une analyse standard dans les deux cas - aucun avertissement d'index manquant et regardez à quel point les lectures sont proches :

L'optimiseur sait qu'une analyse sera beaucoup moins chère qu'une recherche + des recherches dans ce cas. J'ai choisi une colonne LOB pour l'affectation de variables uniquement pour l'effet, mais les résultats étaient similaires en utilisant également une colonne non LOB.
Les résultats du test
Avec la table Timings en place, j'ai pu facilement exécuter les tests plusieurs fois (j'ai exécuté une douzaine de tests), puis obtenir des moyennes pour les tests avec la requête suivante :
SELECT Test, Avg_Duration = AVG(1.0*DATEDIFF(MILLISECOND, StartTime, EndTime)) FROM dbo.Timings GROUP BY Test;
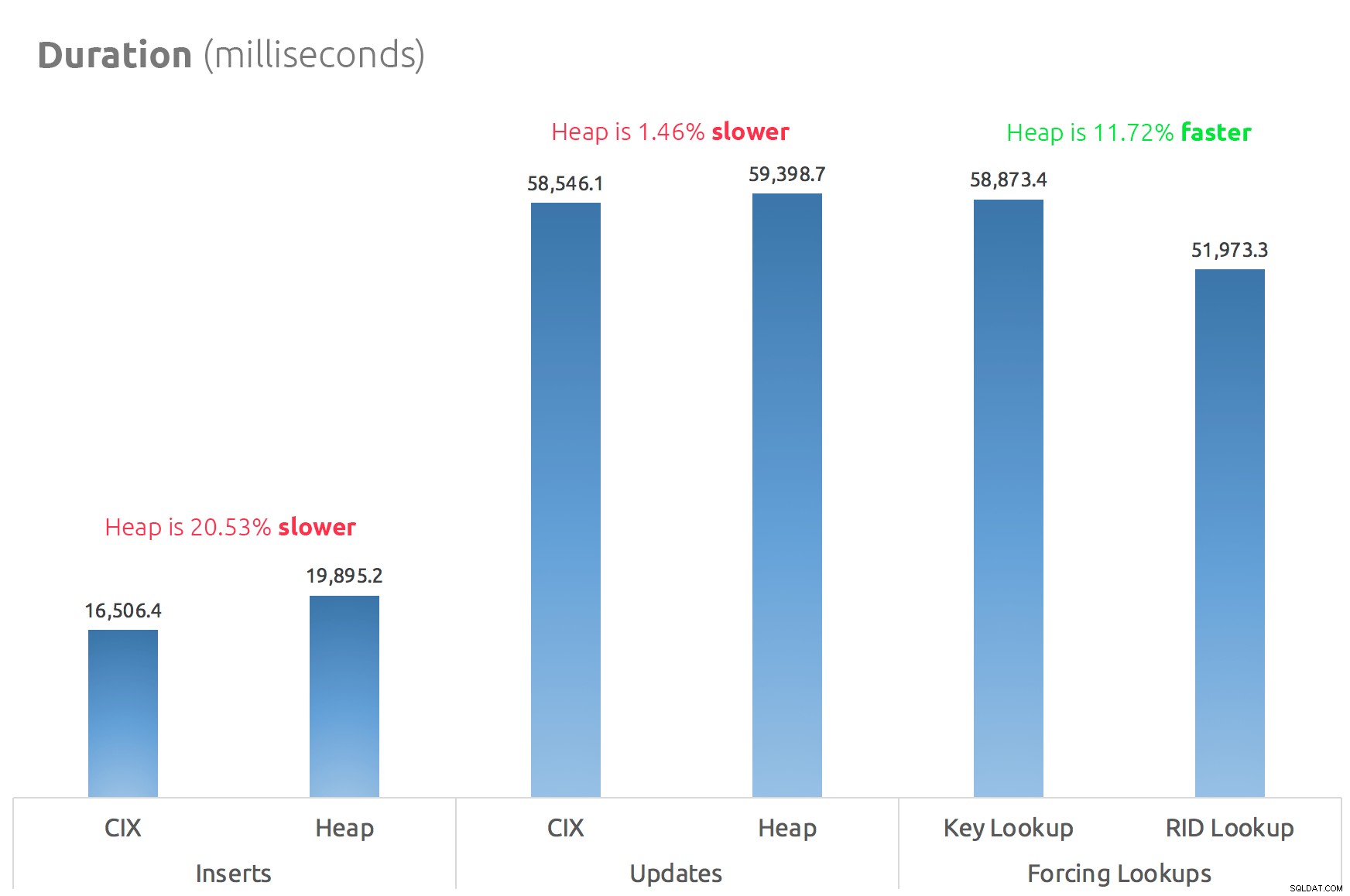
Un simple graphique à barres montre comment ils se comparent :
Conclusion
Ainsi, les rumeurs sont vraies :dans ce cas au moins, une recherche RID est nettement plus rapide qu'une recherche de clé. Aller directement à file:page:slot est évidemment plus efficace en termes d'E/S que de suivre le b-tree (et si vous n'êtes pas sur un stockage moderne, le delta pourrait être beaucoup plus visible).
Que vous souhaitiez tirer parti de cela et apporter tous les autres aspects du tas dépendra de votre charge de travail - le tas est légèrement plus cher pour les opérations d'écriture. Mais ce n'est pas définitif - cela peut varier considérablement en fonction de la structure de la table, des index et des modèles d'accès.
J'ai testé des choses très simples ici, et si vous êtes sur la clôture à ce sujet, je vous recommande fortement de tester votre charge de travail réelle sur votre propre matériel et de comparer par vous-même (et n'oubliez pas de tester la même charge de travail où les index de couverture sont présents; vous obtiendrez probablement de bien meilleures performances globales si vous pouvez simplement éliminer complètement les recherches). Assurez-vous de mesurer toutes les mesures qui sont importantes pour vous ; Ce n'est pas parce que je me concentre sur la durée que c'est celle dont vous devez le plus vous soucier. :-)