Souvent, lorsque nous écrivons une procédure stockée, nous voulons qu'elle se comporte de différentes manières en fonction de l'entrée de l'utilisateur. Prenons l'exemple suivant :
CREATE PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC; GO
Cette procédure stockée, que j'ai créée dans la base de données AdventureWorks2017, a deux paramètres :@CustomerID et @SortOrder. Le premier paramètre, @CustomerID, affecte les lignes à renvoyer. Si un ID client spécifique est transmis à la procédure stockée, elle renvoie toutes les commandes (top 10) pour ce client. Sinon, si c'est NULL, la procédure stockée renvoie toutes les commandes (top 10), quel que soit le client. Le deuxième paramètre, @SortOrder, détermine comment les données seront triées, par OrderDate ou par SalesOrderID. Notez que seules les 10 premières lignes seront renvoyées selon l'ordre de tri.
Ainsi, les utilisateurs peuvent affecter le comportement de la requête de deux manières :quelles lignes renvoyer et comment les trier. Pour être plus précis, il existe 4 comportements différents pour cette requête :
- Renvoie les 10 premières lignes pour tous les clients triés par date de commande (comportement par défaut)
- Renvoie les 10 premières lignes d'un client spécifique, triées par date de commande
- Renvoie les 10 premières lignes pour tous les clients triés par SalesOrderID
- Renvoie les 10 premières lignes d'un client spécifique triées par SalesOrderID
Testons la procédure stockée avec les 4 options et examinons le plan d'exécution et les statistiques IO.
Renvoyer les 10 premières lignes pour tous les clients triés par date de commande
Voici le code pour exécuter la procédure stockée :
EXECUTE Sales.GetOrders; GO
Voici le plan d'exécution :
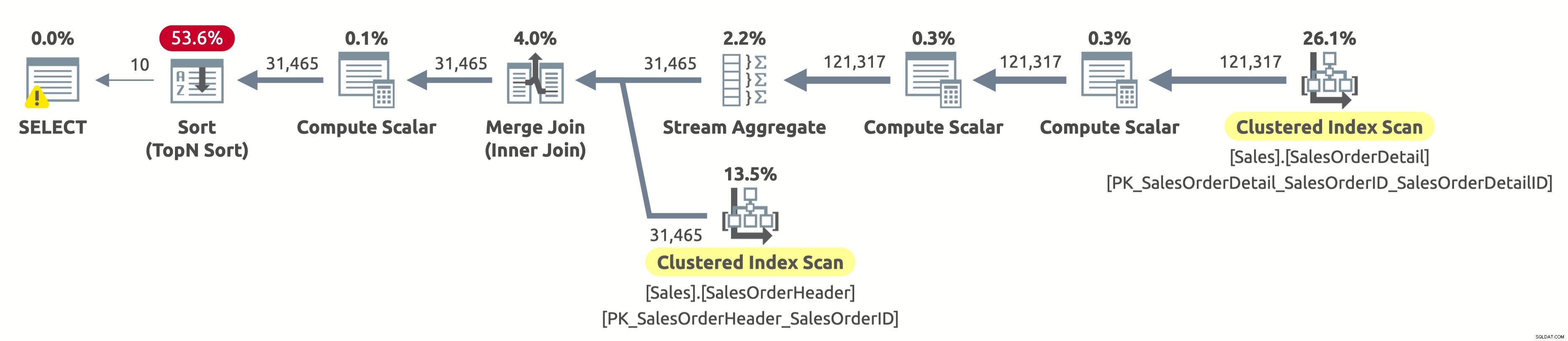
Comme nous n'avons pas filtré par client, nous devons scanner l'intégralité du tableau. L'optimiseur a choisi d'analyser les deux tables à l'aide d'index sur SalesOrderID, ce qui a permis un agrégat de flux efficace ainsi qu'une jointure de fusion efficace.
Si vous vérifiez les propriétés de l'opérateur Clustered Index Scan sur la table Sales.SalesOrderHeader, vous trouverez le prédicat suivant :[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[ @CustomerID] OU [@CustomerID] EST NULL. Le processeur de requêtes doit évaluer ce prédicat pour chaque ligne de la table, ce qui n'est pas très efficace car il sera toujours évalué à true.
Nous devons toujours trier toutes les données par OrderDate pour renvoyer les 10 premières lignes. S'il y avait un index sur OrderDate, l'optimiseur l'aurait probablement utilisé pour analyser uniquement les 10 premières lignes de Sales.SalesOrderHeader, mais il n'y a pas d'index de ce type, donc le plan semble correct compte tenu des index disponibles.
Voici le résultat des statistiques IO :
- Tableau 'SalesOrderHeader'. Scan compte 1, lectures logiques 689
- Tableau 'SalesOrderDetail'. Scan compte 1, lectures logiques 1248
Si vous demandez pourquoi il y a un avertissement sur l'opérateur SELECT, il s'agit d'un avertissement d'octroi excessif. Dans ce cas, ce n'est pas parce qu'il y a un problème dans le plan d'exécution, mais plutôt parce que le processeur de requêtes a demandé 1 024 Ko (ce qui est le minimum par défaut) et n'a utilisé que 16 Ko.
Parfois, la mise en cache des plans n'est pas une si bonne idée
Ensuite, nous voulons tester le scénario consistant à renvoyer les 10 premières lignes pour un client spécifique trié par OrderDate. Ci-dessous le code :
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
Le plan d'exécution est exactement le même qu'avant. Cette fois, le plan est très inefficace car il scanne les deux tables uniquement pour renvoyer 3 commandes. Il existe de bien meilleures façons d'exécuter cette requête.
La raison, dans ce cas, est la mise en cache du plan. Le plan d'exécution a été généré lors de la première exécution en fonction des valeurs des paramètres de cette exécution spécifique, une méthode connue sous le nom de reniflage de paramètres. Ce plan a été stocké dans le cache de plan pour être réutilisé et, à partir de maintenant, chaque appel à cette procédure stockée va réutiliser le même plan.
Ceci est un exemple où la mise en cache du plan n'est pas une si bonne idée. En raison de la nature de cette procédure stockée, qui a 4 comportements différents, nous nous attendons à obtenir un plan différent pour chaque comportement. Mais nous sommes coincés avec un seul plan, qui n'est valable que pour l'une des 4 options, en fonction de l'option utilisée lors de la première exécution.
Désactivons la mise en cache du plan pour cette procédure stockée, juste pour que nous puissions voir le meilleur plan que l'optimiseur peut proposer pour chacun des 3 autres comportements. Nous le ferons en ajoutant WITH RECOMPILE à la commande EXECUTE.
Renvoyer les 10 premières lignes d'un client spécifique triées par date de commande
Voici le code permettant de renvoyer les 10 premières lignes d'un client spécifique triées par date de commande :
EXECUTE Sales.GetOrders @CustomerID = 11006 WITH RECOMPILE; GO
Voici le plan d'exécution :
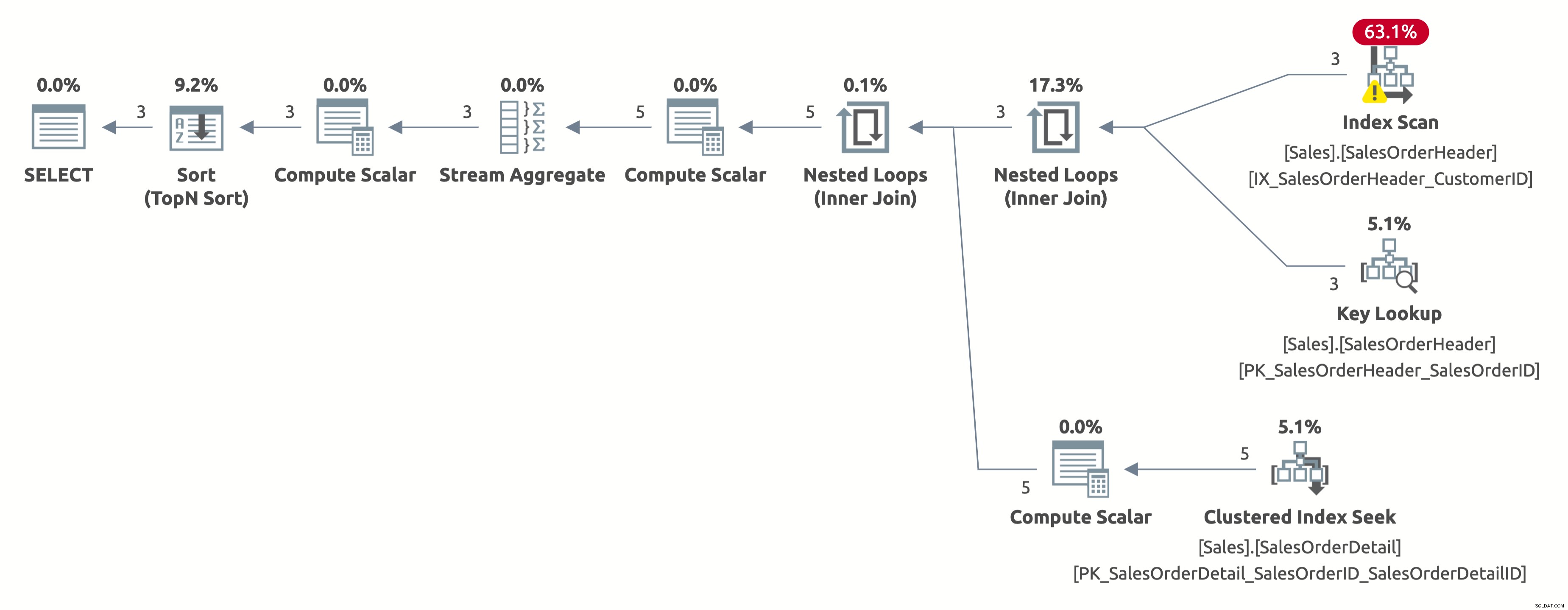
Cette fois, nous obtenons un meilleur plan, qui utilise un index sur CustomerID. L'optimiseur estime correctement 2,6 lignes pour CustomerID =11006 (le nombre réel est 3). Mais notez qu'il effectue une analyse d'index au lieu d'une recherche d'index. Il ne peut pas effectuer de recherche d'index car il doit évaluer le prédicat suivant pour chaque ligne de la table :[AdventureWorks2017].[Sales].[SalesOrderHeader].[CustomerID] as [SalesOrders].[CustomerID]=[@CustomerID ] OU [@CustomerID] EST NULL.
Voici le résultat des statistiques IO :
- Tableau 'SalesOrderDetail'. Nombre de scans 3, lectures logiques 9
- Tableau 'SalesOrderHeader'. Scan compte 1, lectures logiques 66
Renvoyer les 10 premières lignes pour tous les clients triés par SalesOrderID
Voici le code permettant de renvoyer les 10 premières lignes pour tous les clients triés par SalesOrderID :
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Voici le plan d'exécution :
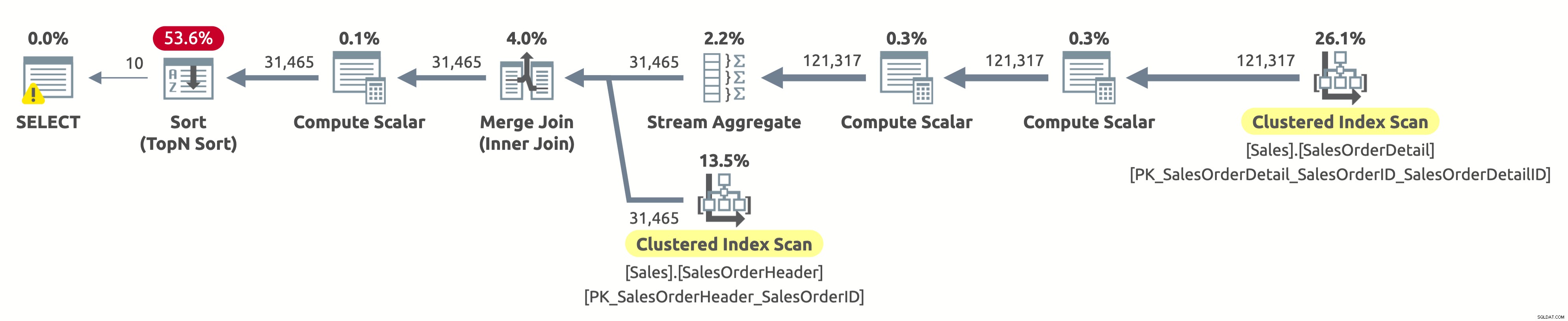
Hé, c'est le même plan d'exécution que dans la première option. Mais cette fois, quelque chose ne va pas. Nous savons déjà que les index clusterisés des deux tables sont triés par SalesOrderID. Nous savons également que le plan les analyse tous les deux dans l'ordre logique pour conserver l'ordre de tri (la propriété Ordered est définie sur True). L'opérateur Merge Join conserve également l'ordre de tri. Parce que nous demandons maintenant de trier le résultat par SalesOrderID, et qu'il est déjà trié de cette façon, alors pourquoi devons-nous payer pour un opérateur de tri coûteux ?
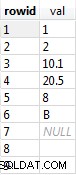
Eh bien, si vous cochez l'opérateur Sort, vous remarquerez qu'il trie les données selon Expr1004. Et, si vous cochez l'opérateur Compute Scalar à droite de l'opérateur Sort, vous découvrirez que Expr1004 est le suivant :

Ce n'est pas beau à voir, je sais. C'est l'expression que nous avons dans la clause ORDER BY de notre requête. Le problème est que l'optimiseur ne peut pas évaluer cette expression au moment de la compilation, il doit donc la calculer pour chaque ligne au moment de l'exécution, puis trier l'ensemble des enregistrements en fonction de cela.
La sortie des statistiques IO est comme lors de la première exécution :
- Tableau 'SalesOrderHeader'. Scan compte 1, lectures logiques 689
- Tableau 'SalesOrderDetail'. Scan compte 1, lectures logiques 1248
Renvoyer les 10 premières lignes pour un client spécifique triées par SalesOrderID
Voici le code permettant de renvoyer les 10 premières lignes d'un client spécifique triées par SalesOrderID :
EXECUTE Sales.GetOrders @CustomerID = 11006 , @SortOrder = N'SalesOrderID' WITH RECOMPILE; GO
Le plan d'exécution est le même que dans la deuxième option (renvoyer les 10 premières lignes pour un client spécifique triées par OrderDate). Le plan présente les deux mêmes problèmes, que nous avons déjà mentionnés. Le premier problème consiste à effectuer un parcours d'index plutôt qu'une recherche d'index en raison de l'expression dans la clause WHERE. Le deuxième problème est d'effectuer un tri coûteux en raison de l'expression dans la clause ORDER BY.
Alors, que devons-nous faire ?
Rappelons-nous d'abord à quoi nous avons affaire. Nous avons des paramètres qui déterminent la structure de la requête. Pour chaque combinaison de valeurs de paramètres, nous obtenons une structure de requête différente. Dans le cas du paramètre @CustomerID, les deux comportements différents sont NULL ou NOT NULL, et ils affectent la clause WHERE. Dans le cas du paramètre @SortOrder, il existe deux valeurs possibles, et elles affectent la clause ORDER BY. Le résultat est 4 structures de requête possibles, et nous aimerions obtenir un plan différent pour chacune.
Nous avons alors deux problèmes distincts. Le premier est la mise en cache du plan. Il n'y a qu'un seul plan pour la procédure stockée, et il sera généré en fonction des valeurs des paramètres lors de la première exécution. Le deuxième problème est que même lorsqu'un nouveau plan est généré, il n'est pas efficace car l'optimiseur ne peut pas évaluer les expressions "dynamiques" dans la clause WHERE et dans la clause ORDER BY au moment de la compilation.
Nous pouvons essayer de résoudre ces problèmes de plusieurs manières :
- Utiliser une série d'instructions IF-ELSE
- Diviser la procédure en procédures stockées distinctes
- Utiliser OPTION (RECOMPILER)
- Générer la requête dynamiquement
Utilisez une série d'instructions IF-ELSE
L'idée est simple :au lieu des expressions "dynamiques" dans la clause WHERE et dans la clause ORDER BY, nous pouvons diviser l'exécution en 4 branches à l'aide d'instructions IF-ELSE - une branche pour chaque comportement possible.
Par exemple, voici le code de la première branche :
IF @CustomerID IS NULL AND @SortOrder = N'OrderDate' BEGIN SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID GROUP BY SalesOrders.SalesOrderID, SalesOrders.OrderDate, SalesOrders.DueDate, SalesOrders.[Status], SalesOrders.CustomerID ORDER BY SalesOrders.OrderDate ASC; END;
Cette approche peut aider à générer de meilleurs plans, mais elle présente certaines limites.
Tout d'abord, la procédure stockée devient assez longue et plus difficile à écrire, à lire et à maintenir. Et c'est alors que nous n'avons que deux paramètres. Si nous avions 3 paramètres, nous aurions 8 branches. Imaginez que vous deviez ajouter une colonne à la clause SELECT. Vous auriez à ajouter la colonne dans 8 requêtes différentes. Cela devient un cauchemar de maintenance, avec un risque élevé d'erreur humaine.
Deuxièmement, nous avons toujours le problème de la mise en cache du plan et du reniflage des paramètres dans une certaine mesure. En effet, lors de la première exécution, l'optimiseur va générer un plan pour les 4 requêtes en fonction des valeurs des paramètres de cette exécution. Disons que la première exécution va utiliser les valeurs par défaut pour les paramètres. Plus précisément, la valeur de @CustomerID sera NULL. Toutes les requêtes seront optimisées en fonction de cette valeur, y compris la requête avec la clause WHERE (SalesOrders.CustomerID =@CustomerID). L'optimiseur va estimer 0 lignes pour ces requêtes. Maintenant, disons que la deuxième exécution va utiliser une valeur non nulle pour @CustomerID. Le plan mis en cache, qui estime 0 lignes, sera utilisé, même si le client peut avoir de nombreuses commandes dans le tableau.
Diviser la procédure en procédures stockées séparées
Au lieu de 4 branches au sein d'une même procédure stockée, nous pouvons créer 4 procédures stockées distinctes, chacune avec les paramètres pertinents et la requête correspondante. Ensuite, nous pouvons soit réécrire l'application pour décider quelle procédure stockée exécuter en fonction des comportements souhaités. Ou, si nous voulons qu'elle soit transparente pour l'application, nous pouvons réécrire la procédure stockée d'origine pour décider quelle procédure exécuter en fonction des valeurs des paramètres. Nous allons utiliser les mêmes instructions IF-ELSE, mais au lieu d'exécuter une requête dans chaque branche, nous exécuterons une procédure stockée distincte.
L'avantage est que nous résolvons le problème de la mise en cache du plan, car chaque procédure stockée a désormais son propre plan, et le plan de chaque procédure stockée va être généré lors de sa première exécution en fonction du reniflage des paramètres.
Mais nous avons toujours le problème de maintenance. Certaines personnes pourraient dire que maintenant c'est encore pire, car nous devons gérer plusieurs procédures stockées. Encore une fois, si nous augmentons le nombre de paramètres à 3, nous nous retrouverons avec 8 procédures stockées distinctes.
Utilisez OPTION (RECOMPILER)
OPTION (RECOMPILE) fonctionne comme par magie. Il vous suffit de dire les mots (ou de les ajouter à la requête) et la magie opère. Vraiment, il résout tellement de problèmes car il compile la requête au moment de l'exécution, et il le fait pour chaque exécution.
Mais vous devez être prudent car vous savez ce qu'ils disent :"Avec un grand pouvoir vient une grande responsabilité." Si vous utilisez OPTION (RECOMPILE) dans une requête qui est exécutée très souvent sur un système OLTP occupé, vous risquez de tuer le système car le serveur doit compiler et générer un nouveau plan à chaque exécution, en utilisant beaucoup de ressources CPU. C'est vraiment dangereux. Cependant, si la requête n'est exécutée qu'une fois de temps en temps, disons une fois toutes les quelques minutes, elle est probablement sans danger. Mais testez toujours l'impact dans votre environnement spécifique.
Dans notre cas, en supposant que nous pouvons utiliser OPTION (RECOMPILE) en toute sécurité, tout ce que nous avons à faire est d'ajouter les mots magiques à la fin de notre requête, comme indiqué ci-dessous :
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID WHERE SalesOrders.CustomerID = @CustomerID OR @CustomerID IS NULL GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY CASE @SortOrder WHEN N'OrderDate' THEN SalesOrders.OrderDate WHEN N'SalesOrderID' THEN SalesOrders.SalesOrderID END ASC OPTION (RECOMPILE); GO
Voyons maintenant la magie en action. Par exemple, voici le plan pour le second comportement :
EXECUTE Sales.GetOrders @CustomerID = 11006; GO
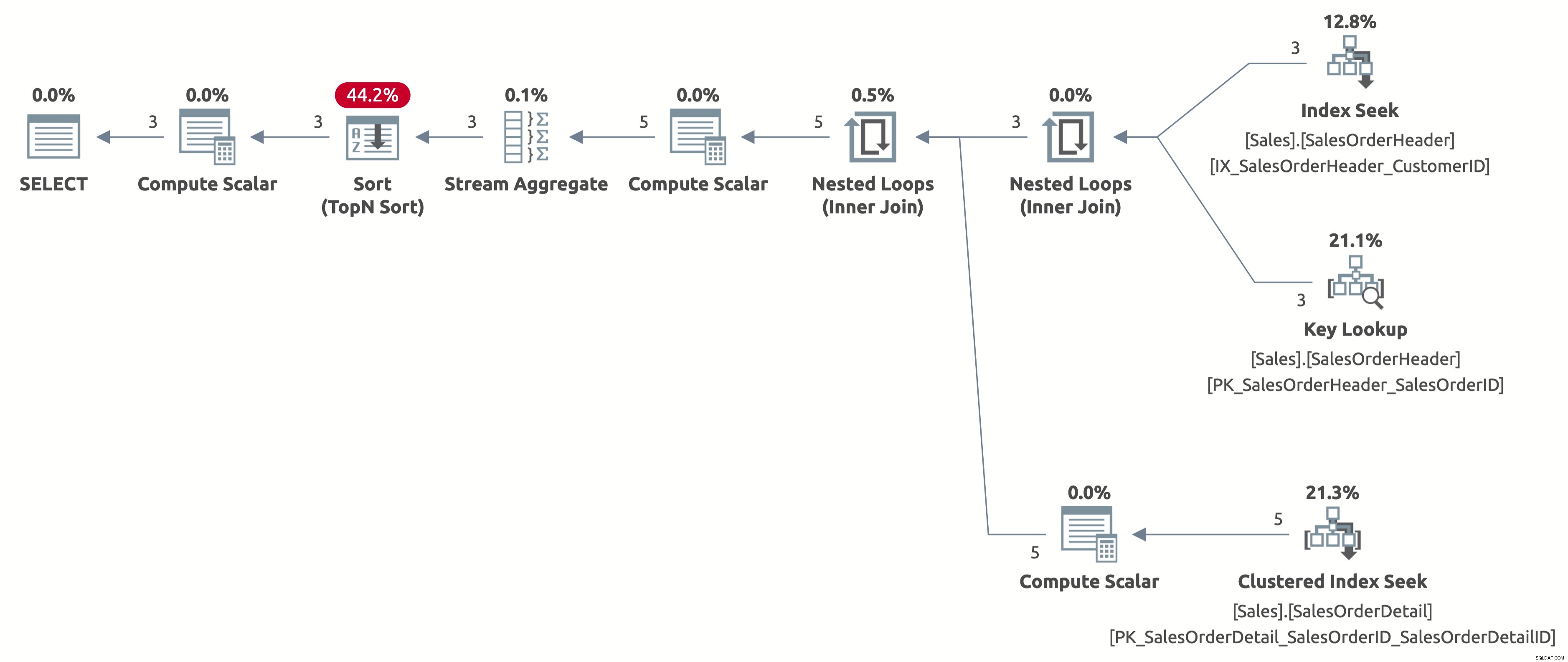
Nous obtenons maintenant une recherche d'index efficace avec une estimation correcte de 2,6 lignes. Nous devons toujours trier par OrderDate, mais maintenant le tri se fait directement par Order Date, et nous n'avons plus besoin de calculer l'expression CASE dans la clause ORDER BY. Il s'agit du meilleur plan possible pour ce comportement de requête basé sur les index disponibles.
Voici le résultat des statistiques IO :
- Tableau 'SalesOrderDetail'. Nombre de scans 3, lectures logiques 9
- Tableau 'SalesOrderHeader'. Scan compte 1, lectures logiques 11
La raison pour laquelle OPTION (RECOMPILE) est si efficace dans ce cas est qu'elle résout exactement les deux problèmes que nous avons ici. N'oubliez pas que le premier problème est la mise en cache du plan. OPTION (RECOMPILE) élimine complètement ce problème car il recompile la requête à chaque fois. Le deuxième problème est l'incapacité de l'optimiseur à évaluer l'expression complexe dans la clause WHERE et dans la clause ORDER BY au moment de la compilation. Étant donné que OPTION (RECOMPILE) se produit au moment de l'exécution, cela résout le problème. Parce qu'au moment de l'exécution, l'optimiseur dispose de beaucoup plus d'informations par rapport au temps de compilation, et cela fait toute la différence.
Voyons maintenant ce qui se passe lorsque nous essayons le troisième comportement :
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
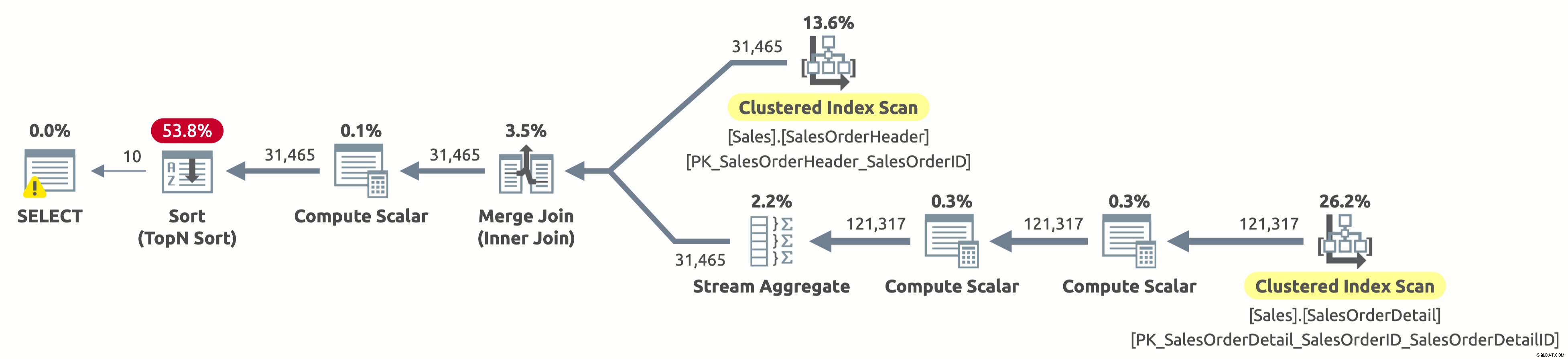
Houston nous avons un problème. Le plan analyse toujours entièrement les deux tables, puis trie tout, au lieu d'analyser uniquement les 10 premières lignes de Sales.SalesOrderHeader et d'éviter complètement le tri. Que s'est-il passé ?
Il s'agit d'un "cas" intéressant, lié à l'expression CASE dans la clause ORDER BY. L'expression CASE évalue une liste de conditions et renvoie l'une des expressions de résultat. Mais les expressions de résultat peuvent avoir des types de données différents. Alors, quel serait le type de données de l'expression CASE entière ? Eh bien, l'expression CASE renvoie toujours le type de données de priorité la plus élevée. Dans notre cas, la colonne OrderDate a le type de données DATETIME, tandis que la colonne SalesOrderID a le type de données INT. Le type de données DATETIME a une priorité plus élevée, donc l'expression CASE renvoie toujours DATETIME.
Cela signifie que si nous voulons trier par SalesOrderID, l'expression CASE doit d'abord convertir implicitement la valeur de SalesOrderID en DATETIME pour chaque ligne avant de la trier. Vous voyez l'opérateur Compute Scalar à droite de l'opérateur Sort dans le plan ci-dessus ? C'est exactement ce qu'il fait.
C'est un problème en soi, et cela montre à quel point il peut être dangereux de mélanger différents types de données dans une seule expression CASE.
Nous pouvons contourner ce problème en réécrivant la clause ORDER BY d'une autre manière, mais cela rendrait le code encore plus laid et difficile à lire et à maintenir. Donc, je n'irai pas dans cette direction.
Au lieu de cela, essayons la méthode suivante…
Générer la requête dynamiquement
Étant donné que notre objectif est de générer 4 structures de requêtes différentes dans une seule requête, le SQL dynamique peut être très pratique dans ce cas. L'idée est de construire la requête dynamiquement en fonction des valeurs des paramètres. De cette façon, nous pouvons construire les 4 structures de requête différentes dans un seul code, sans avoir à maintenir 4 copies de la requête. Chaque structure de requête sera compilée une fois, lors de sa première exécution, et elle obtiendra le meilleur plan car elle ne contient aucune expression complexe.
Cette solution est très similaire à la solution avec les procédures stockées multiples, mais au lieu de maintenir 8 procédures stockées pour 3 paramètres, nous ne maintenons qu'un seul code qui construit la requête de manière dynamique.
Je sais, le SQL dynamique est également moche et peut parfois être assez difficile à maintenir, mais je pense que c'est toujours plus facile que de maintenir plusieurs procédures stockées, et il n'évolue pas de manière exponentielle à mesure que le nombre de paramètres augmente.
Voici le code :
ALTER PROCEDURE Sales.GetOrders ( @CustomerID AS INT = NULL , @SortOrder AS SYSNAME = N'OrderDate' ) AS DECLARE @Command AS NVARCHAR(MAX); SET @Command = N' SELECT TOP (10) SalesOrderID = SalesOrders.SalesOrderID , OrderDate = CAST (SalesOrders.OrderDate AS DATE) , OrderStatus = SalesOrders.[Status] , CustomerID = SalesOrders.CustomerID , OrderTotal = SUM (SalesOrderDetails.LineTotal) FROM Sales.SalesOrderHeader AS SalesOrders INNER JOIN Sales.SalesOrderDetail AS SalesOrderDetails ON SalesOrders.SalesOrderID = SalesOrderDetails.SalesOrderID ' + CASE WHEN @CustomerID IS NULL THEN N'' ELSE N'WHERE SalesOrders.CustomerID = @pCustomerID ' END + N'GROUP BY SalesOrders.SalesOrderID , SalesOrders.OrderDate , SalesOrders.DueDate , SalesOrders.[Status] , SalesOrders.CustomerID ORDER BY ' + CASE @SortOrder WHEN N'OrderDate' THEN N'SalesOrders.OrderDate' WHEN N'SalesOrderID' THEN N'SalesOrders.SalesOrderID' END + N' ASC; '; EXECUTE sys.sp_executesql @stmt = @Command , @params = N'@pCustomerID AS INT' , @pCustomerID = @CustomerID; GO
Notez que j'utilise toujours un paramètre interne pour l'ID client, et j'exécute le code dynamique en utilisant sys.sp_executesql pour transmettre la valeur du paramètre. Ceci est important pour deux raisons. Tout d'abord, pour éviter plusieurs compilations de la même structure de requête pour différentes valeurs de @CustomerID. Deuxièmement, pour éviter l'injection SQL.
Si vous essayez d'exécuter la procédure stockée maintenant en utilisant différentes valeurs de paramètre, vous verrez que chaque comportement de requête ou structure de requête obtient le meilleur plan d'exécution, et chacun des 4 plans n'est compilé qu'une seule fois.
À titre d'exemple, voici le plan pour le troisième comportement :
EXECUTE Sales.GetOrders @SortOrder = N'SalesOrderID'; GO
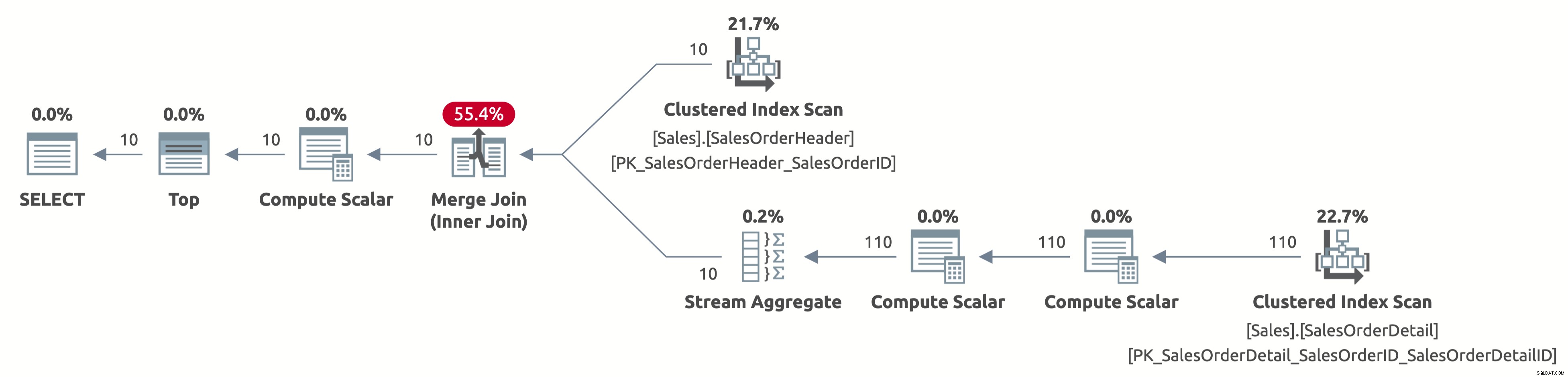
Maintenant, nous analysons uniquement les 10 premières lignes de la table Sales.SalesOrderHeader, et nous analysons également uniquement les 110 premières lignes de la table Sales.SalesOrderDetail. De plus, il n'y a pas d'opérateur de tri car les données sont déjà triées par SalesOrderID.
Voici le résultat des statistiques IO :
- Tableau 'SalesOrderDetail'. Scan compte 1, lectures logiques 4
- Tableau 'SalesOrderHeader'. Scan compte 1, lectures logiques 3
Conclusion
Lorsque vous utilisez des paramètres pour modifier la structure de votre requête, n'utilisez pas d'expressions complexes dans la requête pour dériver le comportement attendu. Dans la plupart des cas, cela entraînera de mauvaises performances, et pour de bonnes raisons. La première raison est que le plan sera généré sur la base de la première exécution, puis toutes les exécutions suivantes réutiliseront le même plan, qui ne convient qu'à une seule structure de requête. La deuxième raison est que l'optimiseur est limité dans sa capacité à évaluer ces expressions complexes au moment de la compilation.
Il existe plusieurs façons de surmonter ces problèmes, et nous les avons examinées dans cet article. Dans la plupart des cas, la meilleure méthode consiste à créer la requête de manière dynamique en fonction des valeurs des paramètres. De cette façon, chaque structure de requête sera compilée une fois avec le meilleur plan possible.
Lorsque vous créez la requête à l'aide de SQL dynamique, assurez-vous d'utiliser des paramètres le cas échéant et vérifiez que votre code est sûr.