Caméras, portes tournantes, ascenseurs, capteurs de température, alarmes :tous ces appareils produisent un grand nombre de signaux interconnectés liés aux événements qui se produisent autour de nous. Imaginez maintenant que vous êtes la personne qui a besoin de suivre les statuts, de produire des rapports en temps réel et de faire des prédictions basées sur toutes ces données de signal. Pour ce faire, vous devez d'abord stocker ces données. Un modèle de données prenant en charge un tel traitement du signal est le sujet de l'article d'aujourd'hui.
Le moyen le plus simple de stocker les signaux entrants serait de simplement stocker une représentation textuelle de ceux-ci dans une énorme liste. Cette approche nous permettrait d'effectuer des insertions rapidement, mais les mises à jour seraient problématiques. De plus, un tel modèle ne serait pas normalisé, et nous n'irons donc pas dans cette direction.
Nous allons créer un modèle de données normalisé qui pourrait être utilisé pour stocker les données générées par différents appareils et également définir comment les appareils sont liés. Un tel modèle stockerait efficacement tout ce dont nous avons besoin et pourrait également être utilisé pour l'analyse et l'analyse prédictive.
Modèle de données
Le modèle de données de traitement du signal
Le modèle se compose de trois domaines :
ComplexesInstallations & DevicesSignals & Events
Nous décrirons chacun de ces domaines dans l'ordre dans lequel ils sont répertoriés.
Complexes
Lors de la création de ce modèle de données, je suis parti du principe que nous l'utiliserons pour suivre ce qui se passe dans les grands complexes. Les complexes varient en taille d'une chambre simple à un centre commercial. Il est important que chaque complexe ait au moins un appareil/capteur, mais il en aura probablement beaucoup plus.
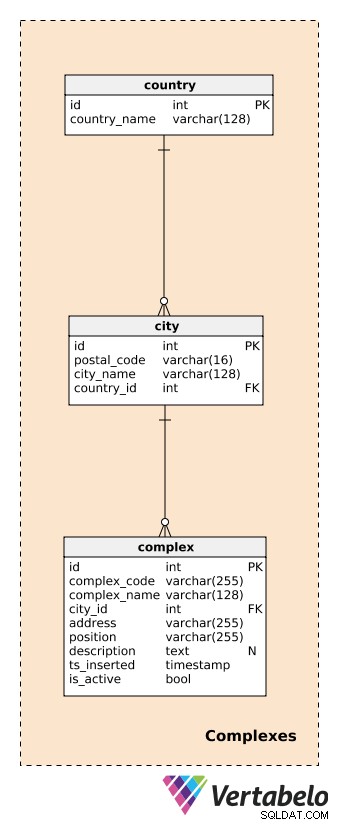
Avant de décrire les complexes, nous devons définir les tables traitant des pays et des villes. Ceux-ci fourniront une description assez détaillée de l'emplacement de chaque complexe.
Pour chaque country , nous stockerons son country_name UNIQUE; pour chaque city , nous stockerons la combinaison UNIQUE de postal_code , city_name , et country_id . Je n'entrerai pas dans les détails ici, et nous supposerons que chaque ville n'a qu'un seul code postal. En réalité, la plupart des villes auront plus d'un code postal; dans ce cas, nous pouvons utiliser le code principal pour chaque ville.
Un complex est le bâtiment ou l'emplacement réel où les dispositifs générateurs de données sont installés. Comme indiqué précédemment, les complexes peuvent varier d'une seule pièce ou d'une station de mesure à des endroits beaucoup plus grands comme des parkings, des centres commerciaux, des cinémas, etc. Ils font l'objet de notre analyse. Nous voulons être en mesure de suivre ce qui se passe au niveau complexe en temps réel et, plus tard, de produire des rapports et des analyses. Pour chaque complexe, nous définirons un :
complex_code– Un identifiant UNIQUE pour chaque complexe. Bien que nous ayons un attribut de clé primaire séparé (id) pour ce tableau, nous pouvons nous attendre à hériter d'un autre code d'identification pour chaque complexe d'un autre système.complex_name– Un nom utilisé pour décrire ce complexe. Dans le cas des centres commerciaux et des cinémas, cela pourrait être leur nom réel et bien connu; pour une station de mesure, on pourrait utiliser un nom générique.city_id– Une référence à la ville où se situe le complexe.address– L'adresse physique de ce complexe.position– La position du complexe (c'est-à-dire les coordonnées géographiques) définie sous forme textuelle.description– Une description textuelle qui décrit plus précisément ce complexe.ts_inserted– Un horodatage lorsque cet enregistrement a été inséré.is_active– Une valeur booléenne indiquant si ce complexe est toujours actif ou non.
Installations et appareils
Nous nous rapprochons maintenant du cœur de notre modèle. Nous aurons probablement un certain nombre d'appareils installés dans chaque complexe. Nous regrouperons également presque certainement ces appareils en fonction de leur objectif - par ex. nous pourrions mettre des caméras, des capteurs de porte et un moteur utilisé pour ouvrir et fermer une porte dans un groupe parce qu'ils fonctionnent ensemble.
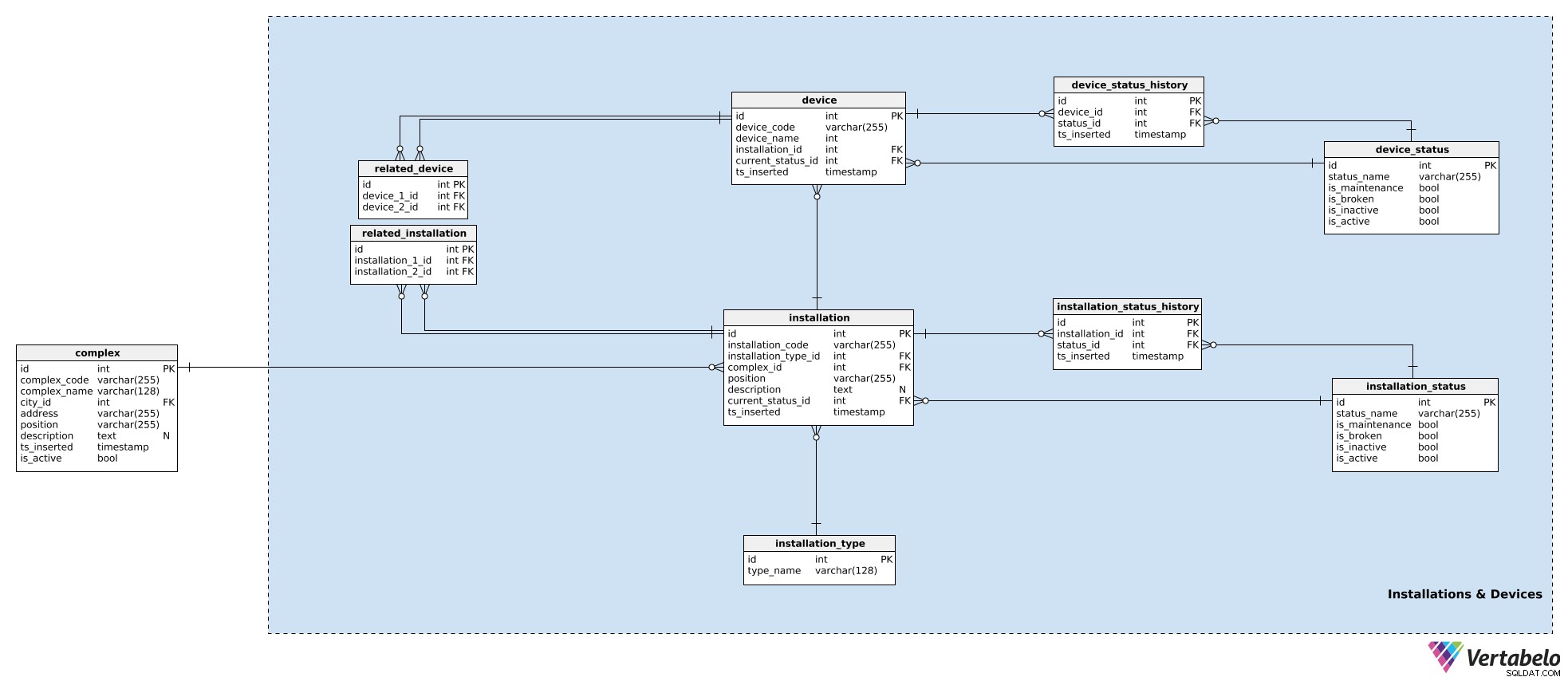
Dans notre modèle, les appareils qui fonctionnent ensemble dans un complexe sont regroupés dans des installations. Il peut s'agir de portes d'entrée, d'escaliers mécaniques, de capteurs de température, etc. Pour chaque installation, nous stockerons les détails suivants dans l'installation tableau :
installation_code– Un code UNIQUE utilisé pour désigner cette installation.installation type_id– Une référence auinstallation_typedictionnaire. Ce dictionnaire stocke uniquement untype_nameUNIQUE attribut qui décrit le type, par ex. escalator, ascenseur.complex_id– Une référence aucomplexà laquelle appartient l'installation.position– Les coordonnées, sous forme textuelle, de cette installation à l'intérieur du complexe.description– Une description textuelle de cette installation.current_status_id– Une référence à l'état actuel (à partir duinstallation_statustableau) de cette installation.ts_inserted– Un horodatage lorsque cet enregistrement a été inséré dans notre système.
Nous avons déjà mentionné les statuts d'installation. Une liste de tous les statuts possibles est stockée dans le installation_status dictionnaire. Chaque statut est UNIQUEMENT défini par son status_name . En plus de cela, nous stockerons des drapeaux indiquant si ce statut, lorsqu'il est utilisé, implique que l'installation is_broken , is_inactive , is_maintenance , ou is_active . Un seul de ces indicateurs doit être défini à la fois.
Nous avons déjà attribué un statut actuel à l'installation. Si nous voulons suivre ce qui se passe avec l'appareil, nous devons également stocker son historique. Pour ce faire, nous utiliserons une table supplémentaire, installation_status_history . Pour chaque enregistrement ici, nous stockerons les références à l'installation et au statut associés ainsi que le moment (ts_inserted ) lorsque ce statut a été attribué.
Les installations font partie de nos complexes. Bien que chaque installation soit une entité unique, elle peut toujours être liée à d'autres installations. (Par exemple, un système vidéo à l'entrée principale d'un centre commercial est évidemment lié aux portes d'entrée du centre commercial - les gens seront d'abord vus par la caméra, puis les portes s'ouvriront.) Si nous voulons garder une trace de ces relations, nous les stockerons dans le related_installation table. Veuillez noter que ce tableau ne contient que des paires UNIQUES de deux clés, toutes deux faisant référence à l'installation table.
La même logique est utilisée pour stocker les appareils. Les appareils sont des éléments matériels uniques qui produisent les signaux qui nous intéressent. Alors que les installations appartiennent à des complexes, les appareils appartiennent à des installations. Pour chaque device , nous stockerons :
device_code– Une façon UNIQUE de désigner chaque appareil.device_name– Un nom pour cet appareil.installation_id– Une référence à l'installation à laquelle appartient cet appareil.current_status_id– L'état actuel de l'appareil.ts_inserted– Un horodatage lorsque cet enregistrement a été inséré.
Les statuts sont gérés de la même manière. Nous utiliserons le device_status tableau pour stocker une liste de tous les états de périphérique possibles. Cette table a la même structure que installation_status et les attributs sont utilisés de la même manière. La raison d'avoir les deux dictionnaires d'état distincts est que les appareils et leurs installations peuvent avoir des états différents - au moins en nom.
L'état actuel est stocké dans le device.current_status_id L'attribut et l'historique des statuts sont stockés dans le device_status_history table. Pour chaque enregistrement ici, nous stockerons les relations avec l'appareil et l'état ainsi que le moment où cet enregistrement a été inséré.
Le dernier tableau de ce domaine est le related_device table. Bien qu'il soit assez évident que tous les appareils d'une même installation sont étroitement liés, je souhaite avoir la possibilité de relier deux appareils appartenant à n'importe quelle installation. Nous y parviendrons en stockant leurs deux ID d'appareil dans ce tableau.
Signaux et événements
Nous sommes maintenant prêts pour le cœur de l'ensemble du modèle.
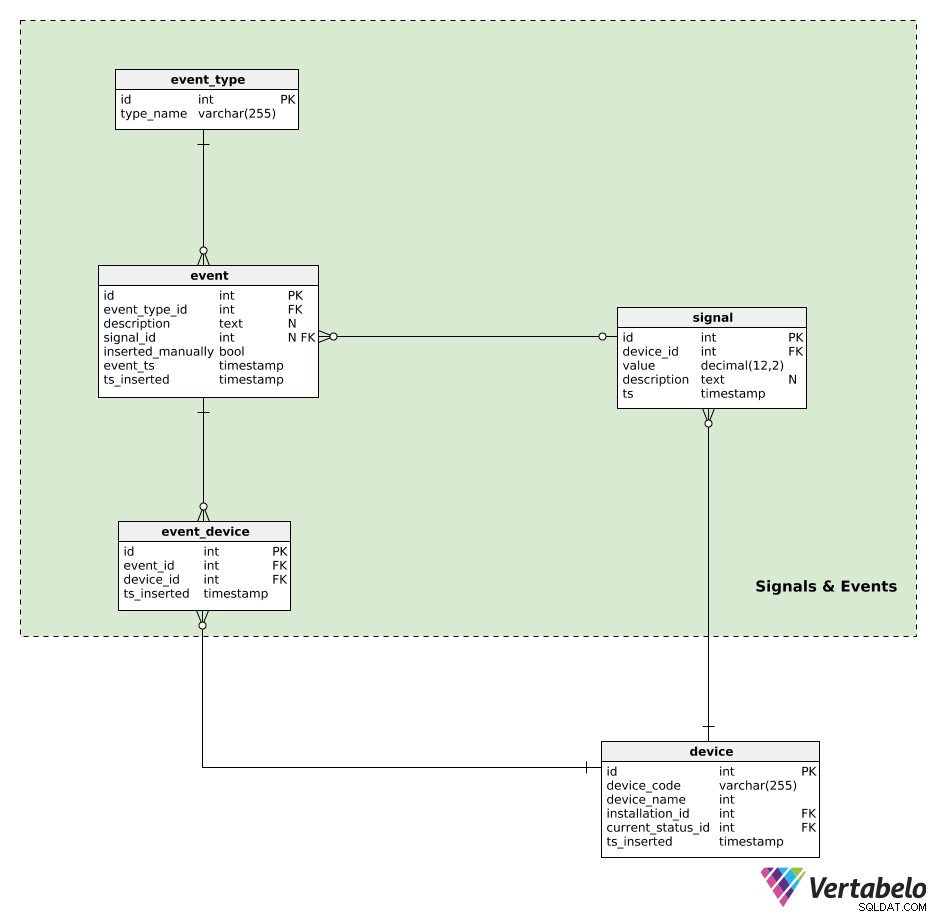
Les appareils génèrent des signaux. Toutes les données de signal sont conservées dans le signal table. Pour chaque signal, nous stockerons :
device_id– Une référence à l'appareil qui a généré ce signal.value– La valeur numérique de ce signal.description– Une valeur textuelle pouvant contenir des paramètres supplémentaires (par exemple, type de signal, valeurs, unité de mesure utilisée) liés à ce signal unique. Ces données sont stockées dans un format de type JSON.ts– Un horodatage lorsque ce signal a été inséré dans la table.
Nous pouvons nous attendre à ce que cette table soit extrêmement utilisée, avec un grand nombre d'insertions effectuées par seconde. Par conséquent, la maintenance de la base de données doit se concentrer sur le suivi de la taille de cette table.
La dernière chose que je veux faire est d'ajouter des événements à notre modèle de données. Les événements peuvent être générés automatiquement par un signal ou insérés manuellement. Un événement généré automatiquement pourrait être "porte ouverte pendant 5 minutes", tandis qu'un événement inséré manuellement pourrait être "l'appareil a dû être éteint à cause de ce signal". L'idée est de stocker les actions qui se sont produites à la suite du comportement de l'appareil. Plus tard, nous pourrions utiliser ces événements lors de l'analyse du comportement de l'appareil.
Les événements seront granulés par event_type . Chaque type est UNIQUEMENT défini par son type_name .
Tous les événements générés automatiquement ou insérés manuellement sont enregistrés dans le event table. Pour chaque enregistrement ici, nous stockerons :
event_type_id– Une référence au type d'événement associé.description– Une description textuelle de cet événement.signal_id– Une référence au signal, le cas échéant, qui a causé l'événement.inserted_manually– Un indicateur indiquant si cet enregistrement a été inséré manuellement ou non.event_tsetts_inserted– Horodatage lorsque cet événement s'est réellement produit et lorsqu'un enregistrement de celui-ci a été inséré. Ces deux éléments peuvent différer, en particulier lorsque les enregistrements d'événements sont insérés manuellement.
La dernière table de notre modèle est le event_device table. Ce tableau est utilisé pour relier les événements à tous les appareils qui ont été impliqués. Pour chaque enregistrement, nous stockerons la paire UNIQUE event_id – device_id et l'horodatage d'insertion de l'enregistrement.
Que pensez-vous de notre modèle de données de traitement du signal ?
Aujourd'hui, nous avons analysé un modèle de données simplifié que nous pourrions utiliser pour suivre les signaux d'un ensemble d'appareils installés à différents endroits. Le modèle lui-même devrait être suffisant pour stocker tout ce dont nous avons besoin pour suivre les statuts et effectuer des analyses. Pourtant, de nombreuses améliorations sont possibles. Que pourrions-nous ajouter ? Veuillez nous le dire dans les commentaires ci-dessous.



