Vous rencontrez des difficultés avec SQL UNION ? Cela se produit si les résultats que vous avez combinés immobilisent votre serveur SQL. Ou un rapport qui fonctionnait auparavant apparaît dans une boîte avec une icône X rouge. Une erreur "Operand type clash" se produit pointant vers une ligne avec UNION. Le "feu" commence. Cela vous semble familier ?
Que vous utilisiez SQL UNION depuis un certain temps ou que vous commenciez, une feuille de triche ou un ensemble concis de notes ne vous fera pas de mal. C'est ce que vous allez obtenir aujourd'hui dans ce post. Cette liste propose 10 conseils utiles pour les débutants et les vétérans. De plus, il y aura des exemples et des discussions avancées.

[sendpulse-form id="11900″]
Mais avant d'aborder le premier point, clarifions les termes.
UNION est l'un des opérateurs d'ensemble en SQL qui combine 2 ou plusieurs ensembles de résultats. Cela peut s'avérer utile lorsque vous devez combiner des noms, des statistiques mensuelles et plus encore provenant de différentes sources. Et que vous utilisiez SQL Server, MySQL ou Oracle, le but, le comportement et la syntaxe seront très similaires. Mais comment ça marche ?
1. Utiliser SQL UNION pour combiner Unique Enregistrements
L'utilisation d'UNION pour combiner des ensembles de résultats supprime les doublons.
Pourquoi est-ce important ?
La plupart du temps, vous ne voulez pas de résultats avec des doublons. Un rapport avec des lignes en double gaspille de l'encre et du papier en copies papier. Et cela va irriter vos utilisateurs.
Comment l'utiliser
Vous combinez les résultats des instructions SELECT avec UNION entre les deux.
Avant de commencer avec l'exemple, préparons nos exemples de données.
USE AdventureWorks
GO
IF OBJECT_ID ('dbo.Customer1', 'U') IS NOT NULL
DROP TABLE dbo.Customer1;
GO
IF OBJECT_ID ('dbo.Customer2', 'U') IS NOT NULL
DROP TABLE dbo.Customer2;
GO
IF OBJECT_ID ('dbo.Customer3', 'U') IS NOT NULL
DROP TABLE dbo.Customer3;
GO
-- Get 3 customer names with Andersen lastname
SELECT TOP 3
p.LastName
, p.FirstName
, c.AccountNumber
INTO dbo.Customer1
FROM Person.Person AS p
INNER JOIN Sales.Customer c
ON c.PersonID = p.BusinessEntityID
WHERE p.LastName = 'Andersen';
-- Make sure we have a duplicate in another table
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer2
FROM Customer1 c
-- Seems it's not enough. Let's have a 3rd copy
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
INTO dbo.Customer3
FROM Customer1 c
Nous utiliserons les données générées par le code ci-dessus jusqu'au troisième conseil. Maintenant que nous sommes prêts, voici l'exemple :
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
Nous avons 3 copies des mêmes noms de clients et nous nous attendons à ce que les enregistrements uniques disparaissent. Voir les résultats :
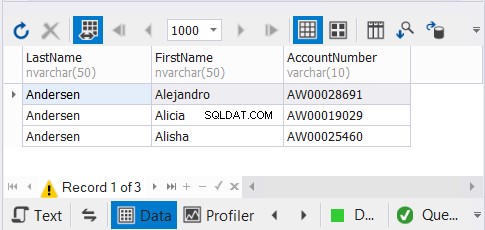
La solution dbForge Studio pour SQL Server que nous utilisons pour nos exemples n'affiche que 3 enregistrements. Cela aurait pu être 9. En appliquant UNION, nous avons supprimé les doublons.
Comment ça marche ?
Le diagramme de plan dans dbForge Studio révèle comment SQL Server produit le résultat illustré à la figure 1. Jetez un œil :
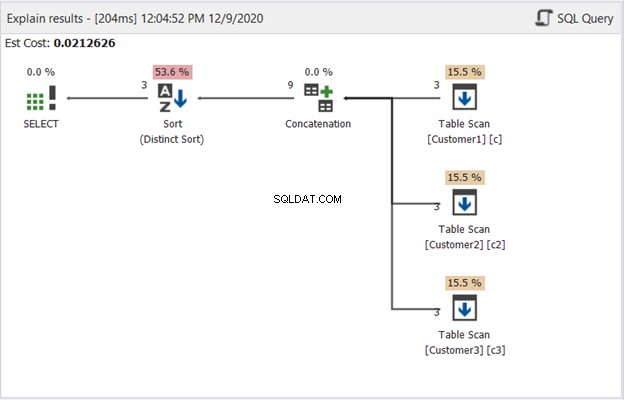
Pour interpréter la figure 2, commencez de droite à gauche :
- Nous avons récupéré 3 enregistrements de chaque opérateur Table Scan. Ce sont les 3 instructions SELECT de l'exemple ci-dessus. Chaque ligne qui en sort affiche « 3 », ce qui signifie 3 enregistrements chacun.
- L'opérateur de concaténation effectue la combinaison des résultats. La ligne qui en sort affiche "9" - une sortie de 9 enregistrements issus de la combinaison des résultats.
- L'opérateur de tri distinct garantit que des enregistrements uniques seront la sortie finale. La ligne qui en sort indique « 3 », ce qui correspond au nombre d'enregistrements de la figure 1.
Le diagramme ci-dessus montre comment UNION est traité par SQL Server. Le nombre et le type d'opérateurs utilisés peuvent être différents selon la requête et la source de données sous-jacente. Mais en résumé, une UNION fonctionne comme suit :
- Récupérer les résultats de chaque instruction SELECT.
- Combinez les résultats avec un opérateur de concaténation.
- Si les résultats combinés ne sont pas uniques, SQL Server filtrera les doublons.
Tous les exemples réussis avec UNION suivent ces étapes de base.
2. Utilisez SQL UNION ALL pour combiner des enregistrements avec des doublons
L'utilisation de UNION ALL combine les ensembles de résultats avec les doublons inclus.
Pourquoi est-ce important ?
Vous souhaiterez peut-être combiner des ensembles de résultats, puis obtenir les enregistrements avec des doublons pour un traitement ultérieur. Cette tâche est utile pour nettoyer vos données.
Comment l'utiliser
Vous combinez les résultats des instructions SELECT avec UNION ALL entre les deux. Regardez l'exemple :
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION ALL
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
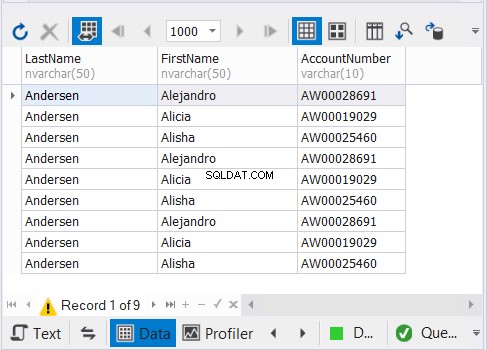
Le code ci-dessus génère 9 enregistrements, comme illustré à la figure 3 :
Comment ça marche ?
Comme précédemment, nous utilisons le schéma Plan pour savoir comment cela fonctionne :
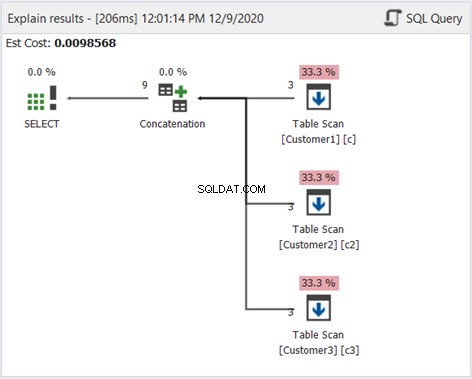
À l'exception du tri distinct de la figure 2, le diagramme ci-dessus est le même. Cela convient car nous ne voulons pas filtrer les doublons.
Le diagramme ci-dessus montre comment UNION ALL fonctionne. En résumé, voici les étapes que SQL Server suivra :
- Récupérer les résultats de chaque instruction SELECT.
- Ensuite, combinez les résultats avec un opérateur de concaténation.
Les exemples réussis avec UNION ALL suivent ce schéma.
3. Vous pouvez mélanger SQL UNION et UNION ALL mais les regrouper avec des parenthèses
Vous pouvez combiner l'utilisation de UNION et UNION ALL dans au moins trois instructions SELECT.
Comment l'utiliser ?
Vous combinez les résultats des instructions SELECT avec UNION ou UNION ALL entre les deux. Les parenthèses regroupent les résultats qui se rejoignent. Utilisons les mêmes données pour l'exemple suivant :
SELECT
c.LastName
,c.FirstName
,c.AccountNumber
FROM dbo.Customer1 c
UNION ALL
(
SELECT
c2.LastName
,c2.FirstName
,c2.AccountNumber
FROM dbo.Customer2 c2
UNION
SELECT
c3.LastName
,c3.FirstName
,c3.AccountNumber
FROM dbo.Customer3 c3
)
L'exemple ci-dessus combine les résultats des deux dernières instructions SELECT sans doublons. Ensuite, il combine cela avec le résultat de la première instruction SELECT. Le résultat est dans la figure 5 ci-dessous :
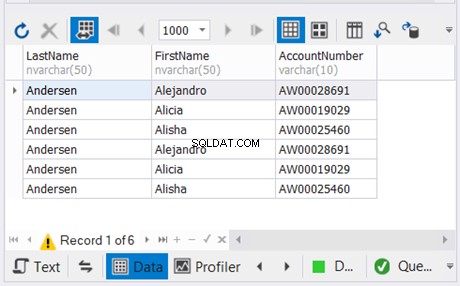
4. Les colonnes de chaque instruction SELECT doivent avoir des types de données compatibles
Les colonnes de chaque instruction SELECT qui utilise UNION peuvent avoir différents types de données. C'est acceptable tant qu'ils sont compatibles et permettent une conversion implicite sur eux. Le type de données final des résultats combinés utilisera le type de données avec la priorité la plus élevée. En outre, la base de la taille finale des données est constituée par les données ayant la plus grande taille. Dans le cas de chaînes, il utilisera les données avec le plus grand nombre de caractères.
Pourquoi est-ce important ?
Si vous devez insérer le résultat d'UNION dans une table, le type et la taille des données finales détermineront si elles tiennent ou non dans la colonne de la table cible. Sinon, une erreur se produira. Par exemple, l'une des colonnes de l'UNION a un type final de NVARCHAR(50). Si la colonne de la table cible est VARCHAR(50), vous ne pouvez pas l'insérer dans la table.
Comment ça marche ?
Il n'y a pas de meilleure façon de l'expliquer qu'un exemple :
SELECT N'김지수' AS FullName
UNION
SELECT N'김제니' AS KoreanName
UNION
SELECT N'박채영' AS KoreanName
UNION
SELECT N'ลลิษา มโนบาล' AS ThaiName
UNION
SELECT 'Kim Ji-soo' AS EnglishName
UNION
SELECT 'Jennie Kim' AS EnglishName
UNION
SELECT 'Roseanne Park' AS EnglishName
UNION
SELECT 'Lalisa Manoban' AS EnglishName
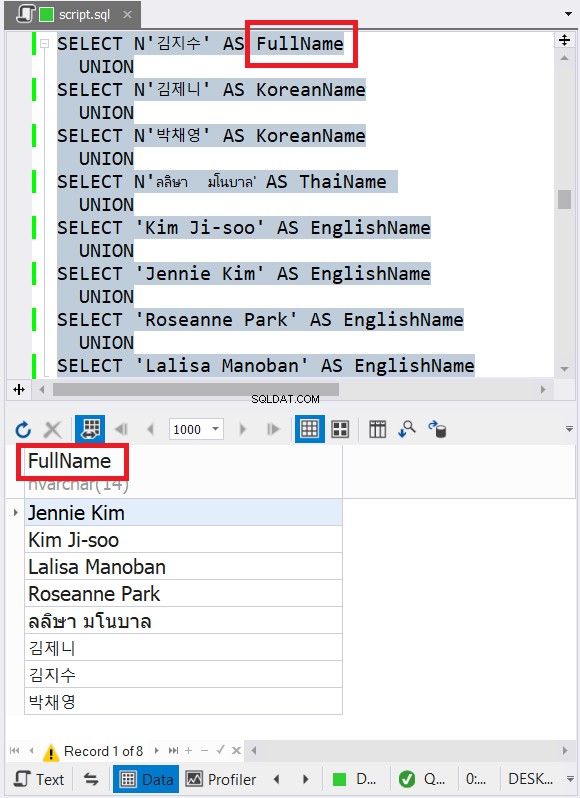
L'exemple ci-dessus contient des données avec des noms de caractères anglais, coréen et thaï. Le thaï et le coréen sont des caractères Unicode. Les caractères anglais ne le sont pas. Alors, à votre avis, quels seront le type et la taille des données finales ? dbForge Studio l'affiche dans le jeu de résultats :
Avez-vous remarqué le type de données final dans la figure 6 ? Il ne peut pas s'agir de VARCHAR à cause des caractères Unicode. Donc, il doit s'agir de NVARCHAR. Pendant ce temps, la taille ne peut pas être inférieure à 14 car les données avec le plus grand nombre de caractères ont 14 caractères. Voir les légendes en rouge dans la figure 6. Il est bon d'inclure le type et la taille des données dans l'en-tête de colonne dans dbForge Studio.
Ce n'est pas seulement le cas pour les types de données de chaîne. Cela s'applique également aux nombres et aux dates. Pendant ce temps, si vous essayez de combiner des données avec des types de données incompatibles, une erreur se produira. Voir l'exemple ci-dessous :
SELECT CAST('12/25/2020' AS DATE) AS col1
UNION
SELECT CAST('10' AS INT) AS col1
Nous ne pouvons pas combiner des dates et des nombres entiers dans une colonne. Attendez-vous donc à une erreur comme celle ci-dessous :
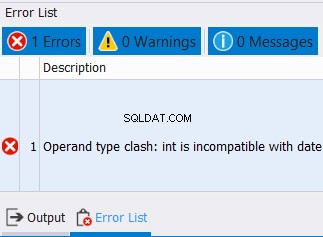
5. Les noms de colonne des résultats combinés utiliseront les noms de colonne de la première instruction SELECT
Ce problème est lié au conseil précédent. Notez les noms de colonne dans le code de l'astuce n°4. Il existe différents noms de colonne dans chaque instruction SELECT. Cependant, nous avons vu le nom de la colonne finale dans le résultat combiné de la figure 6 plus tôt. Ainsi, la base est le nom de colonne de la première instruction SELECT.
Pourquoi est-ce important ?
Cela peut être pratique lorsque vous devez vider le résultat de l'UNION dans une table temporaire. Si vous devez faire référence à ses noms de colonne dans les instructions suivantes, vous devez être certain des noms. À moins que vous n'utilisiez un éditeur de code avancé avec IntelliSense, vous risquez une autre erreur dans votre code T-SQL.
Comment ça marche ?
Voir la figure 8 pour des résultats plus clairs de l'utilisation de dbForge Studio :
6. Ajoutez ORDER BY dans la dernière instruction SELECT avec SQL UNION pour trier les résultats
Vous devez trier les résultats combinés. Dans une série d'instructions SELECT avec UNION entre les deux, vous pouvez le faire avec la clause ORDER BY dans la dernière instruction SELECT.
Pourquoi est-ce important ?
Les utilisateurs souhaitent trier les données comme ils le souhaitent dans les applications, les pages Web, les rapports, les feuilles de calcul, etc.
Comment l'utiliser
Utilisez ORDER BY dans la dernière instruction SELECT. Voici un exemple :
SELECT
e.BusinessEntityID
,p.FirstName
,p.MiddleName
,p.LastName
,'Employee' AS PersonType
FROM HumanResources.Employee e
INNER JOIN Person.Person p ON e.BusinessEntityID = p.BusinessEntityID
UNION
SELECT
c.PersonID
,p.FirstName
,p.MiddleName
,p.LastName
,'Customer' AS PersonType
FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
ORDER BY p.LastName, p.FirstName
L'exemple ci-dessus donne l'impression que le tri ne se produit que dans la dernière instruction SELECT. Mais ce n'est pas. Cela fonctionnera pour le résultat combiné. Vous aurez des problèmes si vous le placez dans chaque instruction SELECT. Voir le résultat :
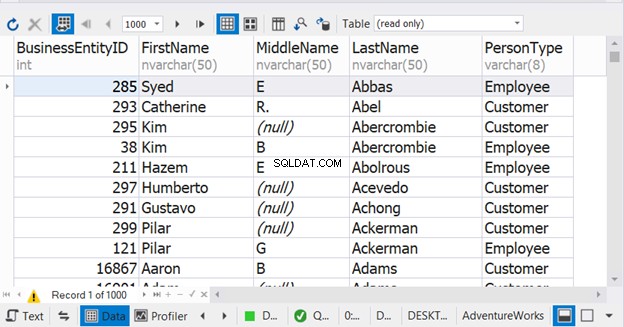
Sans ORDER BY, le jeu de résultats aura tous les Employee PersonType d'abord suivi de tous les clients PersonType . Cependant, la figure 9 montre que les noms deviennent l'ordre de tri du résultat combiné.
Si vous essayez de placer ORDER BY dans chaque instruction SELECT à trier, voici ce qui se passera :
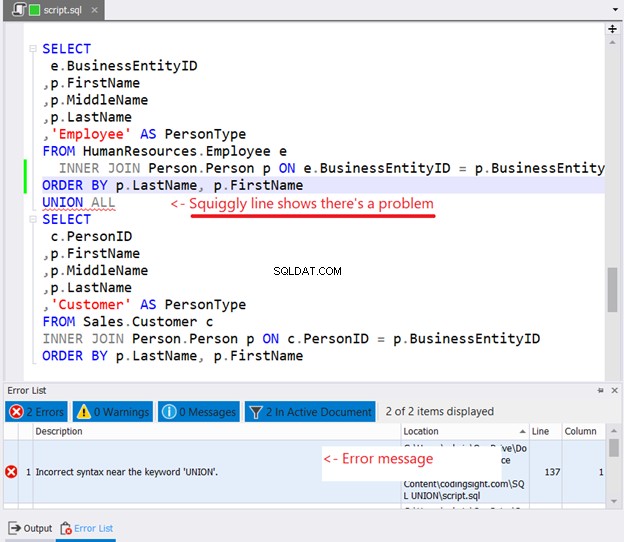
Avez-vous vu la ligne sinueuse sur la figure 10 ? C'est un avertissement. Si vous ne l'avez pas remarqué et que vous continuez, une erreur apparaîtra dans la fenêtre de liste d'erreurs de dbForge Studio.
7. Les clauses WHERE et GROUP BY peuvent être utilisées dans chaque instruction SELECT avec SQL UNION
La clause ORDER BY ne fonctionne pas dans chaque instruction SELECT avec UNION entre les deux. Cependant, les clauses WHERE et GROUP BY fonctionnent.
Pourquoi est-ce important ?
Vous souhaiterez peut-être combiner les résultats de différentes requêtes qui filtrent, comptent ou résument les données. Par exemple, vous pouvez procéder ainsi pour obtenir le total des commandes client de janvier 2012 et le comparer à janvier 2013, janvier 2014, etc.
Comment l'utiliser
Placez les clauses WHERE et/ou GROUP BY dans chaque instruction SELECT. Découvrez l'exemple ci-dessous :
USE AdventureWorks
GO
-- Get the number of orders for January 2012, 2013, 2014 for comparison
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
Le code ci-dessus combine le nombre de commandes de janvier pendant trois années consécutives. Maintenant, vérifiez la sortie :
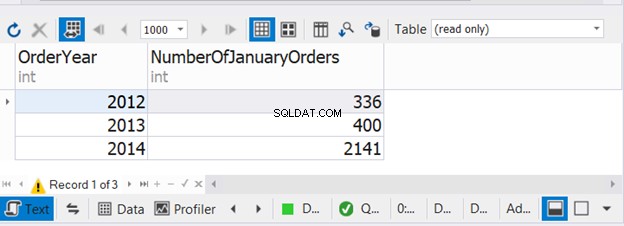
Cet exemple montre qu'il est possible d'utiliser WHERE et GROUP BY dans chacune des trois instructions SELECT avec UNION.
8. SELECT INTO Fonctionne avec SQL UNION
Lorsque vous devez insérer les résultats d'une requête avec SQL UNION dans une table, vous pouvez le faire en utilisant SELECT INTO.
Pourquoi est-ce important ?
Il y aura des moments où vous devrez mettre les résultats d'une requête avec UNION dans une table pour un traitement ultérieur.
Comment l'utiliser
Placez la clause INTO dans la première instruction SELECT. Voici un exemple :
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
INTO JanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '01/31/2012'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2013' AND '01/31/2013'
GROUP BY YEAR(soh.OrderDate)
UNION
SELECT
YEAR(soh.OrderDate) AS OrderYear
,COUNT(*) AS NumberOfJanuaryOrders
FROM Sales.SalesOrderHeader soh
WHERE soh.OrderDate BETWEEN '01/01/2014' AND '01/31/2014'
GROUP BY YEAR(soh.OrderDate)
N'oubliez pas de placer une seule clause INTO dans la première instruction SELECT.
Comment ça marche
SQL Server suit le modèle de traitement UNION. Ensuite, il insère le résultat dans la table spécifiée dans la clause INTO.
9. Différencier SQL UNION de SQL JOIN
SQL UNION et SQL JOIN combinent les données de la table, mais la différence de syntaxe et de résultats est comme le jour et la nuit.
Pourquoi est-ce important ?
Si votre rapport ou toute exigence nécessite un JOIN mais que vous avez fait un UNION, la sortie sera erronée.
Comment SQL UNION et SQL JOIN sont utilisés
C'est SQL UNION contre JOIN. Il s'agit de l'une des requêtes de recherche et des questions associées qu'un débutant fait dans Google lorsqu'il découvre SQL UNION. Voici le tableau des différences :
| UNION SQL | JOINTURE SQL | |
| Ce qui est combiné | Lignes | Colonnes (à l'aide d'une clé) |
| Nombre de colonnes par table | Le même pour toutes les tables | Variable (zéro à toutes les colonnes/table) |
Dans tous les projets avec lesquels j'ai été, SQL JOIN s'applique la plupart du temps. Je n'ai eu que quelques cas qui utilisaient SQL UNION. Mais comme vous l'avez vu jusqu'ici, SQL UNION est loin d'être inutile.
10. SQL UNION ALL est plus rapide que UNION
Les diagrammes de plan de la figure 2 et de la figure 4 ci-dessus suggèrent qu'UNION nécessite un opérateur supplémentaire pour garantir des résultats uniques. C'est pourquoi UNION ALL est plus rapide.
Pourquoi est-ce important ?
Vous, vos utilisateurs, vos clients, votre patron, voulez tous des résultats rapides. Sachant que UNION ALL est plus rapide que UNION, vous vous demandez quoi faire si vous avez besoin de résultats combinés uniques. Il existe une solution, comme vous le verrez plus tard.
SQL UNION ALL vs performances UNION
La figure 2 et la figure 4 vous ont déjà donné une idée de ce qui est le plus rapide. Mais les exemples de code utilisés sont simples avec un petit jeu de résultats. Ajoutons quelques comparaisons supplémentaires en utilisant des millions d'enregistrements pour le rendre convaincant.
Pour commencer, préparons les données :
SELECT TOP (2000000)
val = ROW_NUMBER() OVER (ORDER BY sod.SalesOrderDetailID)
INTO dbo.TestNumbers
FROM AdventureWorks.Sales.SalesOrderDetail sod
CROSS JOIN AdventureWorks.Sales.SalesOrderDetail sod2
Cela fait 2 millions d'enregistrements. J'espère que c'est assez convaincant. Passons maintenant aux deux exemples de requête suivants.
-- Using UNION ALL
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
-- Using UNION
SELECT
val
FROM TestNumbers tn
UNION
SELECT
val
FROM TestNumbers tn
Examinons les processus impliqués dans ces requêtes en commençant par le plus rapide.
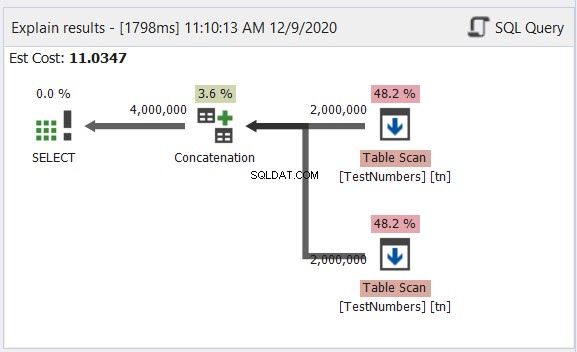
Analyse du diagramme de plan
Le diagramme de la figure 12 semble typique d'un processus UNION ALL. Cependant, le résultat est de 4 millions de résultats combinés. Voir la flèche sortant de l'opérateur de concaténation. Pourtant, c'est généralement parce qu'il ne traite pas les doublons.
Prenons maintenant le diagramme de la requête UNION de la figure 13 :
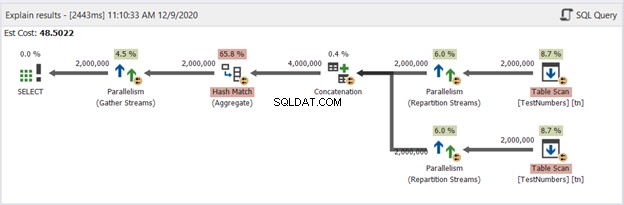
Celui-ci n'est plus typique. Le plan devient un plan de requête parallèle pour gérer la suppression des doublons dans quatre millions de lignes. Le plan de requête parallèle signifie que SQL Server doit diviser le processus par le nombre de cœurs de processeur disponibles.
Interprétons-le en partant des opérateurs de droite allant vers la gauche :
- Puisque nous combinons une table à elle-même, SQL Server doit la récupérer deux fois. Voir les deux analyses de table avec deux millions d'enregistrements chacune.
- Les opérateurs de flux de répartition contrôleront la distribution de chaque ligne vers le prochain thread disponible.
- La concaténation double le résultat à quatre millions. Cela tient toujours compte du nombre de cœurs de processeur.
- Une correspondance de hachage s'applique pour supprimer les doublons. Il s'agit d'un processus coûteux avec un coût d'opérateur de 65,8 %. En conséquence, deux millions d'enregistrements ont été supprimés.
- Gather Streams recombine les résultats obtenus dans chaque cœur ou thread de processeur en un seul.
C'est trop de travail même si le processus est divisé en plusieurs threads. Par conséquent, vous en conclurez qu'il fonctionnera plus lentement. Mais que se passe-t-il s'il existe une solution pour obtenir des enregistrements uniques avec UNION ALL mais plus rapidement que cela ?
Des résultats uniques mais une solution plus rapide avec UNION ALL – Comment ?
Je ne te ferai pas attendre. Voici le code :
SELECT DISTINCT
val
FROM
(
SELECT
val
FROM TestNumbers tn
UNION ALL
SELECT
val
FROM TestNumbers tn
) AS uniqtn
Cela peut être une solution boiteuse. Mais consultez son diagramme de plan dans la figure 14 :
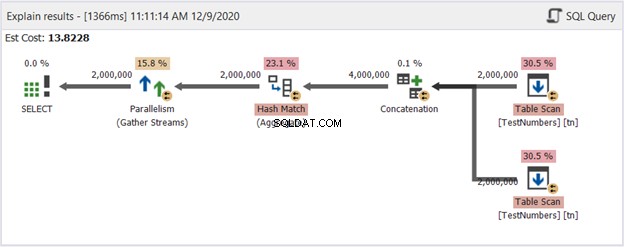
Alors, qu'est-ce qui l'a rendu meilleur? Si vous la comparez à la figure 13, vous voyez que les opérateurs de flux de répartition ont disparu. Cependant, il utilise toujours plusieurs threads pour faire le travail. D'autre part, cela implique que l'optimiseur de requête juge ce processus plus simple à réaliser que la requête utilisant UNION.
Pouvons-nous conclure en toute sécurité que nous devrions éviter d'utiliser UNION et utiliser cette approche à la place ? Pas du tout! Vérifiez toujours le diagramme du plan d'exécution ! Cela dépend toujours de ce que vous voulez que SQL Server vous donne. Celui-ci montre seulement que si vous vous heurtez à un mur de performances, vous devez modifier votre approche de requête.
Qu'en est-il des statistiques d'E/S ?
Nous ne pouvons pas ignorer la quantité de ressources dont SQL Server a besoin pour traiter nos exemples de requête. C'est pourquoi nous devons également examiner leurs STATISTICS IO. En comparant les trois requêtes ci-dessus, nous obtenons les lectures logiques ci-dessous :
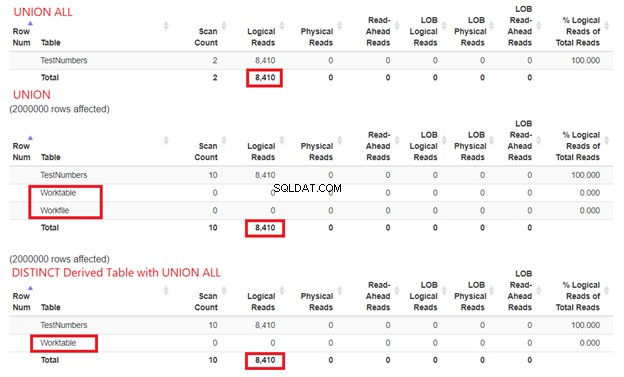
À partir de la figure 15, nous pouvons toujours conclure que UNION ALL est plus rapide que UNION bien que les lectures logiques soient les mêmes. La présence de table de travail et Fichier de travail montre en utilisant tempdb pour faire le travail. Pendant ce temps, lorsque nous utilisons SELECT DISTINCT à partir d'une table dérivée avec UNION ALL, le tempdb l'utilisation est moindre par rapport à UNION. Cela confirme en outre que notre analyse des diagrammes de plan précédents est correcte.
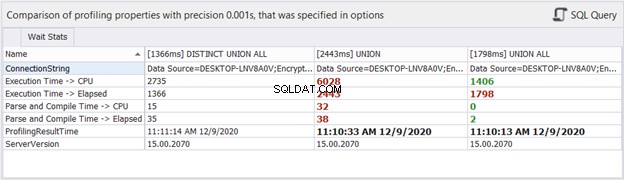
Qu'en est-il des statistiques de temps ?
Bien que le temps écoulé puisse changer à chaque exécution que nous faisons pour les mêmes requêtes, cela peut nous donner une idée et ajouter plus de preuves à notre analyse. dbForge Studio affiche les différences de temps des trois requêtes ci-dessus. Cette comparaison est cohérente avec l'analyse précédente que nous avons effectuée.
Conclusion
Nous avons couvert de nombreux éléments de fond pour vous fournir ce dont vous avez besoin pour utiliser SQL UNION et UNION ALL. Vous ne vous souviendrez peut-être pas de tout après avoir lu cet article, alors assurez-vous de mettre cette page en signet.
Si vous aimez la publication, n'hésitez pas à la partager sur les réseaux sociaux.



