Bien qu'il existe différentes façons de récupérer votre base de données PostgreSQL, l'une des approches les plus pratiques pour restaurer vos données à partir d'une sauvegarde logique. Les sauvegardes logiques jouent un rôle important pour la planification des sinistres et de la reprise (DRP). Les sauvegardes logiques sont des sauvegardes effectuées, par exemple à l'aide de pg_dump ou pg_dumpall, qui génèrent des instructions SQL pour obtenir toutes les données de table écrites dans un fichier binaire.
Il est également recommandé d'exécuter des sauvegardes logiques périodiques en cas d'échec ou d'indisponibilité de vos sauvegardes physiques. Pour PostgreSQL, la restauration peut être problématique si vous n'êtes pas sûr des outils à utiliser. L'outil de sauvegarde pg_dump est généralement associé à l'outil de restauration pg_restore.
pg_dump et pg_restore agissent en tandem si un sinistre se produit et que vous devez récupérer vos données. Bien qu'ils servent l'objectif principal de vidage et de restauration, cela vous oblige à effectuer des tâches supplémentaires lorsque vous devez récupérer votre cluster et effectuer un basculement (si votre principal ou maître actif meurt en raison d'une panne matérielle ou d'une corruption du système VM). Vous finirez par trouver et utiliser des outils tiers capables de gérer le basculement ou la récupération automatique du cluster.
Dans ce blog, nous allons examiner le fonctionnement de pg_restore et le comparer à la manière dont ClusterControl gère la sauvegarde et la restauration de vos données en cas de sinistre.
Mécanismes de pg_restore
pg_restore est utile lors de l'obtention des tâches suivantes :
- associé à pg_dump pour générer des fichiers générés par SQL contenant des données, des rôles d'accès, des définitions de base de données et de table
- restaure une base de données PostgreSQL à partir d'une archive créée par pg_dump dans l'un des formats de texte non brut.
- Il émettra les commandes nécessaires pour reconstruire la base de données dans l'état dans lequel elle se trouvait au moment de sa sauvegarde.
- a la capacité d'être sélectif ou même de réorganiser les éléments avant d'être restaurés en fonction du fichier d'archive
- Les fichiers d'archive sont conçus pour être portables d'une architecture à l'autre.
- pg_restore peut fonctionner en deux modes.
- Si un nom de base de données est spécifié, pg_restore se connecte à cette base de données et restaure le contenu de l'archive directement dans la base de données.
- ou, un script contenant les commandes SQL nécessaires pour reconstruire la base de données est créé et écrit dans un fichier ou une sortie standard. Sa sortie de script est équivalente au format généré par pg_dump
- Certaines des options contrôlant la sortie sont donc analogues aux options de pg_dump.
Une fois que vous avez restauré les données, il est préférable et conseillé d'exécuter ANALYZE sur chaque table restaurée afin que l'optimiseur dispose de statistiques utiles. Bien qu'il acquière READ LOCK, vous devrez peut-être l'exécuter pendant un faible trafic ou pendant votre période de maintenance.
Avantages de pg_restore
pg_dump et pg_restore en tandem ont des fonctionnalités pratiques à utiliser pour un DBA.
- pg_dump et pg_restore peuvent s'exécuter en parallèle en spécifiant l'option -j. L'utilisation de -j/--jobs
vous permet de spécifier le nombre de tâches en cours d'exécution en parallèle pouvant être exécutées, en particulier pour le chargement de données, la création d'index ou la création de contraintes à l'aide de plusieurs tâches simultanées. - C'est très pratique à utiliser, vous pouvez vider ou charger de manière sélective une base de données ou des tables spécifiques
- Il permet et offre une flexibilité à l'utilisateur sur la base de données, le schéma ou la réorganisation des procédures à exécuter en fonction de la liste. Vous pouvez même générer et charger la séquence de SQL de manière lâche, comme empêcher les acl ou les privilèges, en fonction de vos besoins. Il existe de nombreuses options pour répondre à vos besoins.
- Il vous permet de générer des fichiers SQL comme pg_dump à partir d'une archive. C'est très pratique si vous souhaitez charger sur une autre base de données ou un autre hôte pour provisionner un environnement distinct.
- Il est facile à comprendre en fonction de la séquence générée de procédures SQL.
- C'est un moyen pratique de charger des données dans un environnement de réplication. Vous n'avez pas besoin que votre réplica soit restauré puisque les instructions sont du SQL qui ont été répliquées jusqu'aux nœuds de secours et de récupération.
Limites de pg_restore
Pour les sauvegardes logiques, les limites évidentes de pg_restore avec pg_dump sont les performances et la vitesse d'utilisation des outils. Cela peut être utile lorsque vous souhaitez provisionner un environnement de base de données de test ou de développement et charger vos données, mais cela ne s'applique pas lorsque votre ensemble de données est volumineux. PostgreSQL doit vider vos données une par une ou exécuter et appliquer vos données séquentiellement par le moteur de base de données. Bien que vous puissiez rendre cela plus flexible pour accélérer, comme spécifier -j ou utiliser --single-transaction pour éviter tout impact sur votre base de données, le chargement à l'aide de SQL doit toujours être analysé par le moteur.
En outre, la documentation PostgreSQL indique les limitations suivantes, avec nos ajouts au fur et à mesure que nous observons ces outils (pg_dump et pg_restore) :
- Lorsque vous restaurez des données dans une table préexistante et que l'option --disable-triggers est utilisée, pg_restore émet des commandes pour désactiver les déclencheurs sur les tables utilisateur avant d'insérer les données, puis émet des commandes pour les réactiver après l'insertion des données. Si la restauration est arrêtée au milieu, les catalogues système peuvent être laissés dans le mauvais état.
- pg_restore ne peut pas restaurer les objets volumineux de manière sélective ; par exemple, uniquement ceux d'une table spécifique. Si une archive contient des objets volumineux, tous les objets volumineux seront restaurés, ou aucun d'entre eux s'ils sont exclus via -L, -t ou d'autres options.
- Les deux outils sont censés générer une énorme quantité de taille (fichiers, répertoire ou archive tar), en particulier pour une énorme base de données.
- Pour pg_dump, lors du vidage d'une seule table ou sous forme de texte brut, pg_dump ne gère pas les objets volumineux. Les objets volumineux doivent être vidés avec l'intégralité de la base de données à l'aide de l'un des formats d'archive non textuels.
- Si vous avez des archives tar générées par ces outils, notez que les archives tar sont limitées à une taille inférieure à 8 Go. Il s'agit d'une limitation inhérente au format de fichier tar. Ce format ne peut donc pas être utilisé si la représentation textuelle d'un tableau dépasse cette taille. La taille totale d'une archive tar et de tout autre format de sortie n'est pas limitée, sauf éventuellement par le système d'exploitation.
Utiliser pg_restore
Utiliser pg_restore est assez pratique et facile à utiliser. Puisqu'il est associé à pg_dump, ces deux outils fonctionnent suffisamment bien tant que la sortie cible convient à l'autre. Par exemple, le pg_dump suivant ne sera pas utile pour pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Ce résultat sera un psql compatible qui ressemblera à ceci :
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Mais cela échouera pour pg_restore car il n'y a pas de format simple à suivre :
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerPassons maintenant à des termes plus utiles pour pg_restore.
pg_restore :suppression et restauration
Envisagez une utilisation simple de pg_restore dans laquelle vous avez déposé une base de données, par exemple
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Le restaurer avec pg_restore c'est très simple,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump Le -C/--create indique ici que la base de données est créée une fois qu'elle est rencontrée dans l'en-tête. Le -d postgres pointe vers la base de données postgres mais cela ne signifie pas qu'il créera les tables dans la base de données postgres. Cela nécessite que la base de données existe. Si -C n'est pas spécifié, les tables et les enregistrements seront stockés dans cette base de données référencée avec l'argument -d.
Restauration sélective par table
Restaurer une table avec pg_restore est facile et simple. Par exemple, vous avez deux tables, à savoir les tables "b" et "d". Supposons que vous exécutiez la commande pg_dump ci-dessous,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Où le contenu de ce répertoire ressemblera à ceci,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Si vous souhaitez restaurer une table (à savoir "d" dans cet exemple),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Doit avoir,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore :copier des tables de base de données dans une autre base de données
Vous pouvez même copier le contenu de votre base de données existante et l'avoir sur votre base de données cible. Par exemple, j'ai les bases de données suivantes,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)La base de données paultest est une base de données vide alors que nous allons copier ce qu'il y a dans la base de données maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Pour le copier, nous devons vider les données de la base de données maxtest comme suit,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Puis chargez-le ou restaurez-le comme suit,
Maintenant, nous avons des données sur la base de données paultest et les tables ont été stockées en conséquence.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Générer un fichier SQL avec réorganisation
J'ai vu beaucoup d'utilisation avec pg_restore mais il semble que cette fonctionnalité ne soit généralement pas présentée. J'ai trouvé cette approche très intéressante car elle vous permet de commander en fonction de ce que vous ne souhaitez pas inclure, puis de générer un fichier SQL à partir de la commande que vous souhaitez poursuivre.
Par exemple, nous utiliserons l'exemple pgdump_data.tar que nous avons généré précédemment et créerons une liste. Pour cela, exécutez la commande suivante :
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listCela générera un fichier comme indiqué ci-dessous :
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresMaintenant, réordonnons-le ou dirons-nous que j'ai supprimé la création de SEQUENCE ainsi que la création de la contrainte. Cela ressemblerait à ceci,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresPour générer le fichier au format SQL, procédez comme suit :
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Maintenant, le fichier /tmp/selective_data.out sera un fichier généré par SQL et il est lisible si vous utilisez psql, mais pas pg_restore. Ce qui est génial, c'est que vous pouvez générer un fichier SQL conformément à votre modèle sur lequel seules les données peuvent être restaurées à partir d'une archive existante ou d'une sauvegarde effectuée à l'aide de pg_dump à l'aide de pg_restore.
Restauration PostgreSQL avec ClusterControl
ClusterControl n'utilise pas pg_restore ou pg_dump dans le cadre de son ensemble de fonctionnalités. Nous utilisons pg_dumpall pour générer des sauvegardes logiques et, malheureusement, la sortie n'est pas compatible avec pg_restore.
Il existe plusieurs autres façons de générer une sauvegarde dans PostgreSQL, comme indiqué ci-dessous.
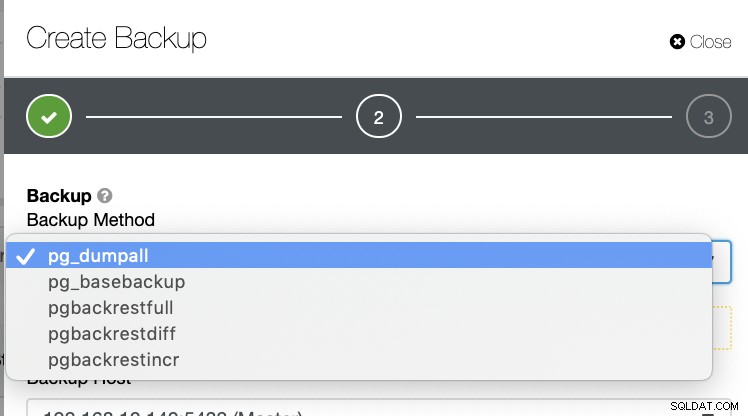
Il n'existe aucun mécanisme permettant de stocker de manière sélective une table, une base de données, ou copier d'une base de données vers une autre base de données.
ClusterControl prend en charge la récupération ponctuelle (PITR), mais cela ne vous permet pas de gérer la restauration des données de manière aussi flexible qu'avec pg_restore. Pour toute la liste des méthodes de sauvegarde, seuls pg_basebackup et pgbackrest sont compatibles PITR.
La façon dont ClusterControl gère la restauration est qu'il a la capacité de récupérer un cluster défaillant tant que la récupération automatique est activée, comme indiqué ci-dessous.

Une fois le maître défaillant, l'esclave peut automatiquement récupérer le cluster pendant que ClusterControl exécute le basculement (qui se fait automatiquement). Pour la partie récupération de données, votre seule option est d'avoir une récupération à l'échelle du cluster, ce qui signifie qu'elle provient d'une sauvegarde complète. Il n'existe aucune possibilité de restauration sélective sur la base de données ou la table cible que vous vouliez uniquement restaurer. Si vous voulez faire cela, restaurez la sauvegarde complète, c'est facile à faire avec ClusterControl. Vous pouvez accéder aux onglets de sauvegarde comme indiqué ci-dessous,
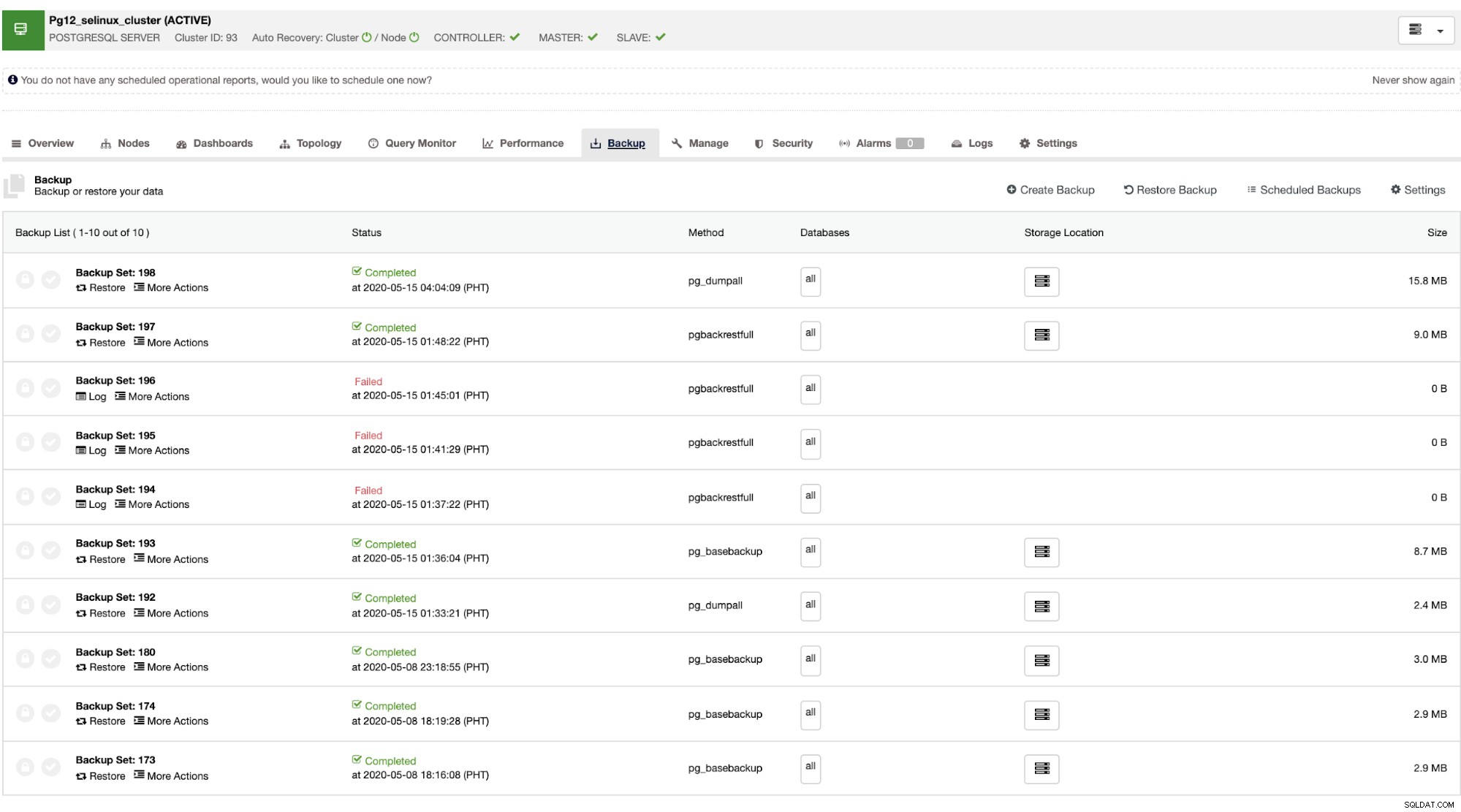
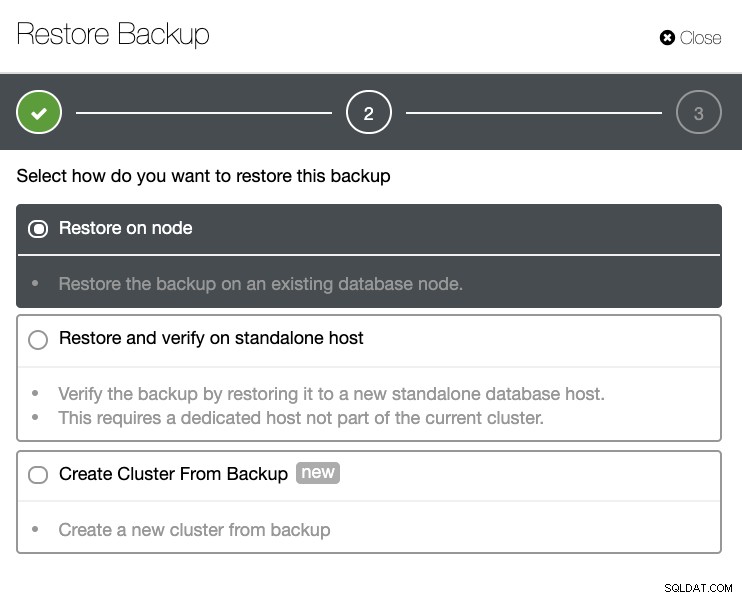
Vous aurez une liste complète des sauvegardes réussies et échouées. Ensuite, la restauration peut être effectuée en choisissant la sauvegarde cible et en cliquant sur le bouton "Restaurer". Cela vous permettra de restaurer sur un nœud existant enregistré dans ClusterControl, ou de vérifier sur un nœud autonome, ou de créer un cluster à partir de la sauvegarde.
Conclusion
L'utilisation de pg_dump et pg_restore simplifie l'approche de sauvegarde/dump et restauration. Cependant, pour un environnement de base de données à grande échelle, ce n'est peut-être pas un composant idéal pour la reprise après sinistre. Pour une procédure de sélection et de restauration minimale, l'utilisation de la combinaison de pg_dump et pg_restore vous permet de vider et de charger vos données en fonction de vos besoins.
Pour les environnements de production (en particulier pour les architectures d'entreprise), vous pouvez utiliser l'approche ClusterControl pour créer une sauvegarde et une restauration avec récupération automatique.
Une combinaison d'approches est également une bonne approche. Cela vous aide à réduire vos RTO et RPO tout en tirant parti de la manière la plus flexible de restaurer vos données en cas de besoin.