Il s'agit de la cinquième et dernière partie de la série couvrant les solutions au défi du générateur de séries de nombres. Dans les parties 1, 2, 3 et 4, j'ai couvert les solutions T-SQL pures. Dès le début, lorsque j'ai publié le puzzle, plusieurs personnes ont déclaré que la solution la plus performante serait probablement une solution basée sur le CLR. Dans cet article, nous allons tester cette hypothèse intuitive. Plus précisément, je couvrirai les solutions basées sur le CLR publiées par Kamil Kosno et Adam Machanic.
Un grand merci à Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea et Paul White pour avoir partagé vos idées et commentaires.
Je ferai mes tests dans une base de données appelée testdb. Utilisez le code suivant pour créer la base de données si elle n'existe pas et pour activer les statistiques d'E/S et de temps :
-- DB and stats
SET NOCOUNT ON;
SET STATISTICS IO, TIME ON;
GO
IF DB_ID('testdb') IS NULL CREATE DATABASE testdb;
GO
USE testdb;
GO Par souci de simplicité, je vais désactiver la sécurité stricte du CLR et rendre la base de données digne de confiance en utilisant le code suivant :
-- Enable CLR, disable CLR strict security and make db trustworthy EXEC sys.sp_configure 'show advanced settings', 1; RECONFIGURE; EXEC sys.sp_configure 'clr enabled', 1; EXEC sys.sp_configure 'clr strict security', 0; RECONFIGURE; EXEC sys.sp_configure 'show advanced settings', 0; RECONFIGURE; ALTER DATABASE testdb SET TRUSTWORTHY ON; GO
Solutions antérieures
Avant de couvrir les solutions basées sur CLR, examinons rapidement les performances de deux des solutions T-SQL les plus performantes.
La solution T-SQL la plus performante qui n'utilisait aucune table de base persistante (autre que la table columnstore vide factice pour obtenir un traitement par lots), et n'impliquait donc aucune opération d'E/S, était celle implémentée dans la fonction dbo.GetNumsAlanCharlieItzikBatch. J'ai couvert cette solution dans la partie 1.
Voici le code pour créer la table columnstore vide factice utilisée par la requête de la fonction :
DROP TABLE IF EXISTS dbo.BatchMe; GO CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE); GO
Et voici le code avec la définition de la fonction :
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Testons d'abord la fonction demandant une série de 100M de nombres, avec l'agrégat MAX appliqué à la colonne n :
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Rappelez-vous que cette technique de test évite de transmettre 100 millions de lignes à l'appelant et évite également l'effort en mode ligne impliqué dans l'affectation de variables lors de l'utilisation de la technique d'affectation de variables.
Voici les statistiques de temps que j'ai obtenues pour ce test sur ma machine :
Temps CPU =6719 ms, temps écoulé =6742 ms .L'exécution de cette fonction ne produit bien entendu aucune lecture logique.
Ensuite, testons-le avec ordre, en utilisant la technique d'affectation de variables :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =9468 ms, temps écoulé =9531 ms .Rappelez-vous que cette fonction n'entraîne pas de tri lors de la demande des données ordonnées par n ; vous obtenez essentiellement le même plan, que vous demandiez ou non les données commandées. Nous pouvons attribuer la majeure partie du temps supplémentaire de ce test par rapport au précédent aux affectations de variables basées sur le mode ligne de 100 M.
La solution T-SQL la plus performante qui utilisait une table de base persistante, et qui entraînait donc quelques opérations d'E/S, bien que très peu nombreuses, était la solution de Paul White implémentée dans la fonction dbo.GetNums_SQLkiwi. J'ai couvert cette solution dans la partie 4.
Voici le code de Paul pour créer à la fois la table columnstore utilisée par la fonction et la fonction elle-même :
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Testons-le d'abord sans commande en utilisant la technique d'agrégation, ce qui donne un plan en mode tout-batch :
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
J'ai obtenu les statistiques de temps et d'E/S suivantes pour cette exécution :
Temps CPU =2922 ms, temps écoulé =2943 ms .Tableau 'CS'. Nombre d'analyses 2, lectures logiques 0, lectures physiques 0, lectures du serveur de pages 0, lectures anticipées 0, lectures anticipées du serveur de pages 0, lob lectures logiques 44 , lob physique lit 0, lob page server lit 0, lob read-ahead lit 0, lob page server read-ahead lit 0.
Table 'CS'. Segment lit 2, segment ignoré 0.
Testons la fonction avec ordre en utilisant la technique d'affectation de variables :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n OPTION(MAXDOP 1);
Comme avec la solution précédente, cette solution évite également le tri explicite dans le plan, et obtient donc le même plan que vous demandiez les données commandées ou non. Mais encore une fois, ce test entraîne une pénalité supplémentaire principalement due à la technique d'affectation des variables utilisée ici, ce qui entraîne le traitement de la partie d'affectation des variables dans le plan en mode ligne.
Voici les statistiques de temps et d'E/S que j'ai obtenues pour cette exécution :
Temps CPU =6985 ms, temps écoulé =7033 ms .Tableau 'CS'. Nombre d'analyses 2, lectures logiques 0, lectures physiques 0, lectures du serveur de pages 0, lectures anticipées 0, lectures anticipées du serveur de pages 0, lob lectures logiques 44 , lob physique lit 0, lob page server lit 0, lob read-ahead lit 0, lob page server read-ahead lit 0.
Table 'CS'. Segment lit 2, segment ignoré 0.
Solutions CLR
Kamil Kosno et Adam Machanic ont d'abord fourni une solution simple CLR uniquement, puis ont proposé une combinaison CLR + T-SQL plus sophistiquée. Je vais commencer par les solutions de Kamil, puis couvrir les solutions d'Adam.
Solutions par Kamil Kosno
Voici le code CLR utilisé dans la première solution de Kamil pour définir une fonction appelée GetNums_KamilKosno1 :
using System;
using System.Data.SqlTypes;
using System.Collections;
public partial class GetNumsKamil1
{
[Microsoft.SqlServer.Server.SqlFunction(FillRowMethodName = "GetNums_KamilKosno1_Fill", TableDefinition = "n BIGINT")]
public static IEnumerator GetNums_KamilKosno1(SqlInt64 low, SqlInt64 high)
{
return (low.IsNull || high.IsNull) ? new GetNumsCS(0, 0) : new GetNumsCS(low.Value, high.Value);
}
public static void GetNums_KamilKosno1_Fill(Object o, out SqlInt64 n)
{
n = (long)o;
}
private class GetNumsCS : IEnumerator
{
public GetNumsCS(long from, long to)
{
_lowrange = from;
_current = _lowrange - 1;
_highrange = to;
}
public bool MoveNext()
{
_current += 1;
if (_current > _highrange) return false;
else return true;
}
public object Current
{
get
{
return _current;
}
}
public void Reset()
{
_current = _lowrange - 1;
}
long _lowrange;
long _current;
long _highrange;
}
} La fonction accepte deux entrées appelées low et high et renvoie une table avec une colonne BIGINT appelée n. La fonction est un type de flux, renvoyant une ligne avec le numéro suivant dans la série par demande de ligne de la requête appelante. Comme vous pouvez le voir, Kamil a choisi la méthode la plus formalisée d'implémentation de l'interface IEnumerator, qui implique l'implémentation des méthodes MoveNext (fait avancer l'énumérateur pour obtenir la ligne suivante), Current (obtient la ligne dans la position actuelle de l'énumérateur) et Reset (définit l'énumérateur à sa position initiale, qui est avant la première ligne).
La variable contenant le nombre actuel dans la série est appelée _current. Le constructeur définit _current sur la limite inférieure de la plage demandée moins 1, et il en va de même pour la méthode Reset. La méthode MoveNext avance _current de 1. Ensuite, si _current est supérieur à la limite supérieure de la plage demandée, la méthode renvoie false, ce qui signifie qu'elle ne sera plus appelée. Sinon, il renvoie true, ce qui signifie qu'il sera appelé à nouveau. La méthode Current renvoie naturellement _current. Comme vous pouvez le voir, une logique assez basique.
J'ai appelé le projet Visual Studio GetNumsKamil1 et utilisé le chemin C:\Temp\ pour celui-ci. Voici le code que j'ai utilisé pour déployer la fonction dans la base de données testdb :
DROP FUNCTION IF EXISTS dbo.GetNums_KamilKosno1; DROP ASSEMBLY IF EXISTS GetNumsKamil1; GO CREATE ASSEMBLY GetNumsKamil1 FROM 'C:\Temp\GetNumsKamil1\GetNumsKamil1\bin\Debug\GetNumsKamil1.dll'; GO CREATE FUNCTION dbo.GetNums_KamilKosno1(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE(n BIGINT) ORDER(n) AS EXTERNAL NAME GetNumsKamil1.GetNumsKamil1.GetNums_KamilKosno1; GO
Notez l'utilisation de la clause ORDER dans l'instruction CREATE FUNCTION. La fonction émet les lignes dans l'ordre n, donc lorsque les lignes doivent être ingérées dans le plan dans l'ordre n, sur la base de cette clause, SQL Server sait qu'il peut éviter un tri dans le plan.
Testons la fonction, d'abord avec la technique d'agrégation, lorsque la commande n'est pas nécessaire :
SELECT MAX(n) AS mx FROM dbo.GetNums_KamilKosno1(1, 100000000);
J'ai obtenu le plan illustré à la figure 1.
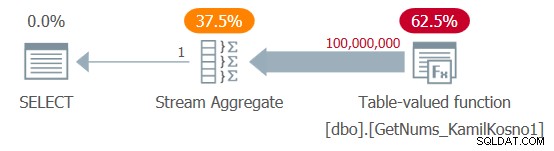 Figure 1 :Plan pour la fonction dbo.GetNums_KamilKosno1
Figure 1 :Plan pour la fonction dbo.GetNums_KamilKosno1
Il n'y a pas grand-chose à dire sur ce plan, à part le fait que tous les opérateurs utilisent le mode d'exécution en ligne.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =37375 ms, temps écoulé =37488 ms .Et bien sûr, aucune lecture logique n'était impliquée.
Testons la fonction avec ordre, en utilisant la technique d'affectation de variables :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_KamilKosno1(1, 100000000) ORDER BY n;
J'ai obtenu le plan illustré à la figure 2 pour cette exécution.
 Figure 2 :Plan pour la fonction dbo.GetNums_KamilKosno1 avec ORDER BY
Figure 2 :Plan pour la fonction dbo.GetNums_KamilKosno1 avec ORDER BY
Notez qu'il n'y a pas de tri dans le plan puisque la fonction a été créée avec la clause ORDER(n). Cependant, des efforts sont nécessaires pour s'assurer que les lignes sont bien émises par la fonction dans l'ordre promis. Cela se fait à l'aide des opérateurs Segment et Sequence Project, qui sont utilisés pour calculer les numéros de ligne, et de l'opérateur Assert, qui interrompt l'exécution de la requête si le test échoue. Ce travail a une mise à l'échelle linéaire - contrairement à la mise à l'échelle n log n que vous auriez obtenue si un tri avait été requis - mais ce n'est toujours pas bon marché. J'ai obtenu les statistiques de temps suivantes pour ce test :
Temps CPU =51531 ms, temps écoulé =51905 ms .Les résultats pourraient en surprendre certains, en particulier ceux qui supposaient intuitivement que les solutions basées sur CLR fonctionneraient mieux que celles de T-SQL. Comme vous pouvez le constater, les temps d'exécution sont d'un ordre de grandeur plus longs qu'avec notre solution T-SQL la plus performante.
La deuxième solution de Kamil est un hybride CLR-T-SQL. Au-delà des entrées basses et hautes, la fonction CLR (GetNums_KamilKosno2) ajoute une entrée de pas et renvoie des valeurs entre bas et haut qui sont espacées les unes des autres. Voici le code CLR que Kamil a utilisé dans sa deuxième solution :
using System;
using System.Data.SqlTypes;
using System.Collections;
public partial class GetNumsKamil2
{
[Microsoft.SqlServer.Server.SqlFunction(DataAccess = Microsoft.SqlServer.Server.DataAccessKind.None, IsDeterministic = true, IsPrecise = true, FillRowMethodName = "GetNums_Fill", TableDefinition = "n BIGINT")]
public static IEnumerator GetNums_KamilKosno2(SqlInt64 low, SqlInt64 high, SqlInt64 step)
{
return (low.IsNull || high.IsNull) ? new GetNumsCS(0, 0, step.Value) : new GetNumsCS(low.Value, high.Value, step.Value);
}
public static void GetNums_Fill(Object o, out SqlInt64 n)
{
n = (long)o;
}
private class GetNumsCS : IEnumerator
{
public GetNumsCS(long from, long to, long step)
{
_lowrange = from;
_step = step;
_current = _lowrange - _step;
_highrange = to;
}
public bool MoveNext()
{
_current = _current + _step;
if (_current > _highrange) return false;
else return true;
}
public object Current
{
get
{
return _current;
}
}
public void Reset()
{
_current = _lowrange - _step;
}
long _lowrange;
long _current;
long _highrange;
long _step;
}
} J'ai nommé le projet VS GetNumsKamil2, je l'ai également placé dans le chemin C:\Temp\ et j'ai utilisé le code suivant pour le déployer dans la base de données testdb :
-- Create assembly and function
DROP FUNCTION IF EXISTS dbo.GetNums_KamilKosno2;
DROP ASSEMBLY IF EXISTS GetNumsKamil2;
GO
CREATE ASSEMBLY GetNumsKamil2
FROM 'C:\Temp\GetNumsKamil2\GetNumsKamil2\bin\Debug\GetNumsKamil2.dll';
GO
CREATE FUNCTION dbo.GetNums_KamilKosno2
(@low AS BIGINT = 1, @high AS BIGINT, @step AS BIGINT)
RETURNS TABLE(n BIGINT)
ORDER(n)
AS EXTERNAL NAME GetNumsKamil2.GetNumsKamil2.GetNums_KamilKosno2;
GO A titre d'exemple d'utilisation de la fonction, voici une requête pour générer des valeurs entre 5 et 59, avec un pas de 10 :
SELECT n FROM dbo.GetNums_KamilKosno2(5, 59, 10);
Ce code génère la sortie suivante :
n --- 5 15 25 35 45 55
Quant à la partie T-SQL, Kamil a utilisé une fonction appelée dbo.GetNums_Hybrid_Kamil2, avec le code suivant :
CREATE OR ALTER FUNCTION dbo.GetNums_Hybrid_Kamil2(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
SELECT TOP (@high - @low + 1) V.n
FROM dbo.GetNums_KamilKosno2(@low, @high, 10) AS GN
CROSS APPLY (VALUES(0+GN.n),(1+GN.n),(2+GN.n),(3+GN.n),(4+GN.n),
(5+GN.n),(6+GN.n),(7+GN.n),(8+GN.n),(9+GN.n)) AS V(n);
GO Comme vous pouvez le voir, la fonction T-SQL appelle la fonction CLR avec les mêmes entrées @low et @high qu'elle obtient et, dans cet exemple, utilise une taille de pas de 10. La requête utilise CROSS APPLY entre le résultat de la fonction CLR et un table -constructeur de valeurs qui génère les nombres finaux en ajoutant des valeurs comprises entre 0 et 9 au début de l'étape. Le filtre TOP est utilisé pour s'assurer que vous n'obtenez pas plus que le nombre de numéros que vous avez demandé.
Important : Je dois souligner que Kamil fait ici une hypothèse sur l'application du filtre TOP en fonction de l'ordre des numéros de résultats, ce qui n'est pas vraiment garanti car la requête n'a pas de clause ORDER BY. Si vous ajoutez une clause ORDER BY pour prendre en charge TOP, ou remplacez TOP par un filtre WHERE, pour garantir un filtre déterministe, cela pourrait complètement changer le profil de performance de la solution.
Quoi qu'il en soit, testons d'abord la fonction sans ordre en utilisant la technique d'agrégation :
SELECT MAX(n) AS mx FROM dbo.GetNums_Hybrid_Kamil2(1, 100000000);
J'ai obtenu le plan illustré à la figure 3 pour cette exécution.
 Figure 3 :Planifier la fonction dbo.GetNums_Hybrid_Kamil2
Figure 3 :Planifier la fonction dbo.GetNums_Hybrid_Kamil2
Encore une fois, tous les opérateurs du plan utilisent le mode d'exécution de ligne.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =13985 ms, temps écoulé =14069 ms .Et naturellement aucune lecture logique.
Testons la fonction avec order :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_Hybrid_Kamil2(1, 100000000) ORDER BY n;
J'ai obtenu le plan illustré à la figure 4.
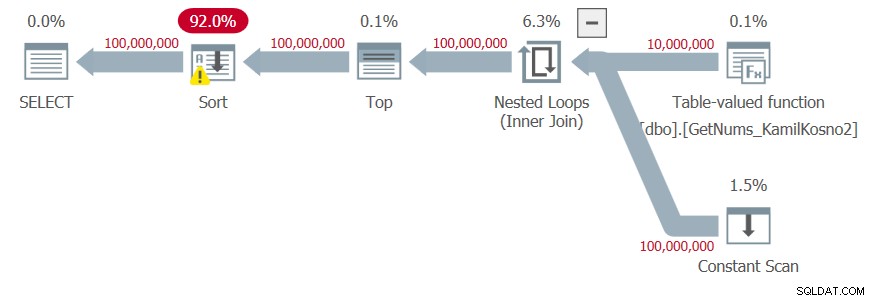 Figure 4 :Planifier la fonction dbo.GetNums_Hybrid_Kamil2 avec ORDER BY
Figure 4 :Planifier la fonction dbo.GetNums_Hybrid_Kamil2 avec ORDER BY
Étant donné que les nombres de résultats sont le résultat de la manipulation de la limite inférieure de l'étape renvoyée par la fonction CLR et du delta ajouté dans le constructeur de table-valeur, l'optimiseur ne fait pas confiance au fait que les nombres de résultats sont générés dans l'ordre demandé, et ajoute un tri explicite au plan.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =68703 ms, temps écoulé =84538 ms .Il semble donc que lorsqu'aucune commande n'est nécessaire, la deuxième solution de Kamil fait mieux que la première. Mais quand il faut commander, c'est l'inverse. Dans tous les cas, les solutions T-SQL sont plus rapides. Personnellement, je ferais confiance à l'exactitude de la première solution, mais pas à la seconde.
Solutions d'Adam Machanic
La première solution d'Adam est également une fonction CLR de base qui continue d'incrémenter un compteur. Seulement au lieu d'utiliser l'approche formalisée plus impliquée comme l'a fait Kamil, Adam a utilisé une approche plus simple qui invoque la commande yield par ligne qui doit être renvoyée.
Voici le code CLR d'Adam pour sa première solution, définissant une fonction de diffusion appelée GetNums_AdamMachanic1 :
using System.Data.SqlTypes;
using System.Collections;
public partial class GetNumsAdam1
{
[Microsoft.SqlServer.Server.SqlFunction(
FillRowMethodName = "GetNums_AdamMachanic1_fill",
TableDefinition = "n BIGINT")]
public static IEnumerable GetNums_AdamMachanic1(SqlInt64 min, SqlInt64 max)
{
var min_int = min.Value;
var max_int = max.Value;
for (; min_int <= max_int; min_int++)
{
yield return (min_int);
}
}
public static void GetNums_AdamMachanic1_fill(object o, out long i)
{
i = (long)o;
}
}; La solution est si élégante dans sa simplicité. Comme vous pouvez le voir, la fonction accepte deux entrées appelées min et max représentant les points limites bas et haut de la plage demandée, et renvoie une table avec une colonne BIGINT appelée n. La fonction initialise les variables appelées min_int et max_int avec les valeurs des paramètres d'entrée de la fonction respective. La fonction exécute ensuite une boucle tant que min_int <=max_int, qui à chaque itération donne une ligne avec la valeur actuelle de min_int et incrémente min_int de 1. C'est tout.
J'ai nommé le projet GetNumsAdam1 dans VS, je l'ai placé dans C:\Temp\ et j'ai utilisé le code suivant pour le déployer :
-- Create assembly and function DROP FUNCTION IF EXISTS dbo.GetNums_AdamMachanic1; DROP ASSEMBLY IF EXISTS GetNumsAdam1; GO CREATE ASSEMBLY GetNumsAdam1 FROM 'C:\Temp\GetNumsAdam1\GetNumsAdam1\bin\Debug\GetNumsAdam1.dll'; GO CREATE FUNCTION dbo.GetNums_AdamMachanic1(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE(n BIGINT) ORDER(n) AS EXTERNAL NAME GetNumsAdam1.GetNumsAdam1.GetNums_AdamMachanic1; GO
J'ai utilisé le code suivant pour le tester avec la technique d'agrégation, pour les cas où l'ordre n'a pas d'importance :
SELECT MAX(n) AS mx FROM dbo.GetNums_AdamMachanic1(1, 100000000);
J'ai obtenu le plan illustré à la figure 5 pour cette exécution.
 Figure 5 :Plan pour la fonction dbo.GetNums_AdamMachanic1
Figure 5 :Plan pour la fonction dbo.GetNums_AdamMachanic1
Le plan est très similaire au plan que vous avez vu plus tôt pour la première solution de Kamil, et il en va de même pour ses performances. J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =36687 ms, temps écoulé =36952 ms .Et bien sûr, aucune lecture logique n'était nécessaire.
Testons la fonction avec ordre, en utilisant la technique d'affectation de variables :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_AdamMachanic1(1, 100000000) ORDER BY n;
J'ai obtenu le plan illustré à la figure 6 pour cette exécution.
 Figure 6 :Plan pour la fonction dbo.GetNums_AdamMachanic1 avec ORDER BY
Figure 6 :Plan pour la fonction dbo.GetNums_AdamMachanic1 avec ORDER BY
Encore une fois, le plan ressemble à celui que vous avez vu plus tôt pour la première solution de Kamil. Il n'y avait pas besoin de tri explicite puisque la fonction a été créée avec la clause ORDER, mais le plan inclut un certain travail pour vérifier que les lignes sont bien renvoyées dans l'ordre promis.
J'ai obtenu les statistiques de temps suivantes pour cette exécution :
Temps CPU =55047 ms, temps écoulé =55498 ms .Dans sa deuxième solution, Adam a également combiné une partie CLR et une partie T-SQL. Voici la description d'Adam de la logique qu'il a utilisée dans sa solution :
"J'essayais de réfléchir à la façon de contourner le problème de bavardage SQLCLR, ainsi qu'au défi central de ce générateur de nombres dans T-SQL, qui est le fait que nous ne pouvons pas simplement créer des lignes magiques.
CLR est une bonne réponse pour la deuxième partie mais est bien sûr gêné par le premier problème. Donc, comme compromis, j'ai créé un T-SQL TVF [appelé GetNums_AdamMachanic2_8192] codé en dur avec les valeurs de 1 à 8192. (Choix assez arbitraire, mais trop grand et le QO commence à s'étouffer un peu.) Ensuite, j'ai modifié ma fonction CLR [ nommé GetNums_AdamMachanic2_8192_base] pour sortir deux colonnes, "max_base" et "base_add", et lui a fait sortir des lignes comme :
- max_base, base_add
——————
8191, 1
8192, 8192
8192, 16384
…
8192, 99991552
257, 99999744
Maintenant, c'est une simple boucle. La sortie CLR est envoyée au T-SQL TVF, qui est configuré pour ne renvoyer que les lignes "max_base" de son ensemble codé en dur. Et pour chaque ligne, il ajoute "base_add" à la valeur, générant ainsi les nombres requis. La clé ici, je pense, est que nous pouvons générer N lignes avec une seule jointure croisée logique, et la fonction CLR n'a qu'à renvoyer 1/8192 autant de lignes, donc c'est assez rapide pour agir comme générateur de base.
La logique semble assez simple.
Voici le code utilisé pour définir la fonction CLR appelée GetNums_AdamMachanic2_8192_base :
using System.Data.SqlTypes;
using System.Collections;
public partial class GetNumsAdam2
{
private struct row
{
public long max_base;
public long base_add;
}
[Microsoft.SqlServer.Server.SqlFunction(
FillRowMethodName = "GetNums_AdamMachanic2_8192_base_fill",
TableDefinition = "max_base int, base_add int")]
public static IEnumerable GetNums_AdamMachanic2_8192_base(SqlInt64 min, SqlInt64 max)
{
var min_int = min.Value;
var max_int = max.Value;
var min_group = min_int / 8192;
var max_group = max_int / 8192;
for (; min_group <= max_group; min_group++)
{
if (min_int > max_int)
yield break;
var max_base = 8192 - (min_int % 8192);
if (min_group == max_group && max_int < (((max_int / 8192) + 1) * 8192) - 1)
max_base = max_int - min_int + 1;
yield return (
new row()
{
max_base = max_base,
base_add = min_int
}
);
min_int = (min_group + 1) * 8192;
}
}
public static void GetNums_AdamMachanic2_8192_base_fill(object o, out long max_base, out long base_add)
{
var r = (row)o;
max_base = r.max_base;
base_add = r.base_add;
}
}; J'ai nommé le projet VS GetNumsAdam2 et placé dans le chemin C:\Temp\ comme avec les autres projets. Voici le code que j'ai utilisé pour déployer la fonction dans la base de données testdb :
-- Create assembly and function DROP FUNCTION IF EXISTS dbo.GetNums_AdamMachanic2_8192_base; DROP ASSEMBLY IF EXISTS GetNumsAdam2; GO CREATE ASSEMBLY GetNumsAdam2 FROM 'C:\Temp\GetNumsAdam2\GetNumsAdam2\bin\Debug\GetNumsAdam2.dll'; GO CREATE FUNCTION dbo.GetNums_AdamMachanic2_8192_base(@max_base AS BIGINT, @add_base AS BIGINT) RETURNS TABLE(max_base BIGINT, base_add BIGINT) ORDER(base_add) AS EXTERNAL NAME GetNumsAdam2.GetNumsAdam2.GetNums_AdamMachanic2_8192_base; GO
Voici un exemple d'utilisation de GetNums_AdamMachanic2_8192_base avec la plage de 1 à 100 M :
SELECT * FROM dbo.GetNums_AdamMachanic2_8192_base(1, 100000000);
Ce code génère la sortie suivante, présentée ici sous forme abrégée :
max_base base_add -------------------- -------------------- 8191 1 8192 8192 8192 16384 8192 24576 8192 32768 ... 8192 99966976 8192 99975168 8192 99983360 8192 99991552 257 99999744 (12208 rows affected)
Voici le code avec la définition de la fonction T-SQL GetNums_AdamMachanic2_8192 (abrégé) :
CREATE OR ALTER FUNCTION dbo.GetNums_AdamMachanic2_8192(@max_base AS BIGINT, @add_base AS BIGINT)
RETURNS TABLE
AS
RETURN
SELECT TOP (@max_base) V.i + @add_base AS val
FROM (
VALUES
(0),
(1),
(2),
(3),
(4),
...
(8187),
(8188),
(8189),
(8190),
(8191)
) AS V(i);
GO Important : Ici aussi, je dois souligner que, comme je l'ai dit à propos de la deuxième solution de Kamil, Adam suppose ici que le filtre TOP extraira les lignes supérieures en fonction de l'ordre d'apparition des lignes dans le constructeur de valeurs de table, ce qui n'est pas vraiment garanti. Si vous ajoutez une clause ORDER BY pour prendre en charge TOP ou modifiez le filtre en un filtre WHERE, vous obtiendrez un filtre déterministe, mais cela peut complètement modifier le profil de performances de la solution.
Enfin, voici la fonction T-SQL la plus externe, dbo.GetNums_AdamMachanic2, que l'utilisateur final appelle pour obtenir la série de nombres :
CREATE OR ALTER FUNCTION dbo.GetNums_AdamMachanic2(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
SELECT Y.val AS n
FROM ( SELECT max_base, base_add
FROM dbo.GetNums_AdamMachanic2_8192_base(@low, @high) ) AS X
CROSS APPLY dbo.GetNums_AdamMachanic2_8192(X.max_base, X.base_add) AS Y
GO Cette fonction utilise l'opérateur CROSS APPLY pour appliquer la fonction T-SQL interne dbo.GetNums_AdamMachanic2_8192 par ligne renvoyée par la fonction CLR interne dbo.GetNums_AdamMachanic2_8192_base.
Testons d'abord cette solution en utilisant la technique d'agrégation lorsque l'ordre n'a pas d'importance :
SELECT MAX(n) AS mx FROM dbo.GetNums_AdamMachanic2(1, 100000000);
J'ai obtenu le plan illustré à la figure 7 pour cette exécution.
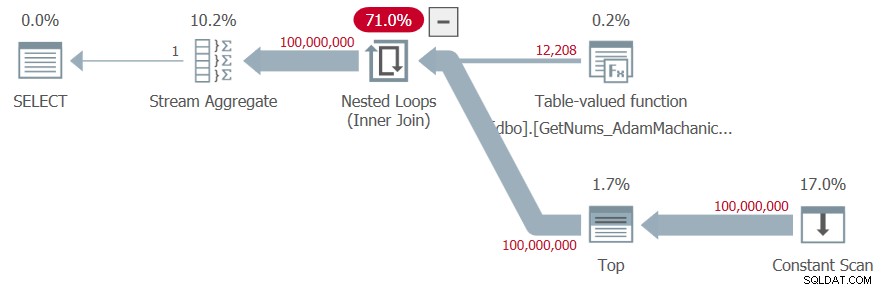 Figure 7 :Plan pour la fonction dbo.GetNums_AdamMachanic2
Figure 7 :Plan pour la fonction dbo.GetNums_AdamMachanic2
J'ai obtenu les statistiques de temps suivantes pour ce test :
SQL Server temps d'analyse et de compilation :Temps CPU =313 ms, temps écoulé =339 ms .SQL Server temps d'exécution :Temps CPU =8859 ms, temps écoulé =8849 ms .
Aucune lecture logique n'était nécessaire.
Le temps d'exécution n'est pas mauvais, mais notez le temps de compilation élevé dû au grand constructeur de table utilisé. Vous paieriez un temps de compilation aussi élevé quelle que soit la taille de la plage que vous demandez, c'est donc particulièrement délicat lorsque vous utilisez la fonction avec de très petites plages. Et cette solution est encore plus lente que celles de T-SQL.
Testons la fonction avec order :
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_AdamMachanic2(1, 100000000) ORDER BY n;
J'ai obtenu le plan illustré à la figure 8 pour cette exécution.
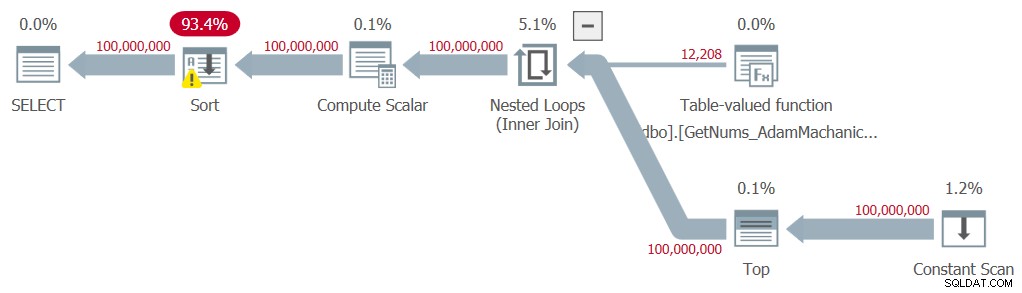 Figure 8 :Plan pour la fonction dbo.GetNums_AdamMachanic2 avec ORDER BY
Figure 8 :Plan pour la fonction dbo.GetNums_AdamMachanic2 avec ORDER BY
Comme avec la deuxième solution de Kamil, un tri explicite est nécessaire dans le plan, entraînant une pénalité de performance significative. Voici les statistiques de temps que j'ai obtenues pour ce test :
Temps d'exécution :temps CPU =54891 ms, temps écoulé =60981 ms .De plus, il y a toujours la pénalité de temps de compilation élevée d'environ un tiers de seconde.
Conclusion
Il était intéressant de tester des solutions basées sur le CLR pour relever le défi des séries de nombres, car de nombreuses personnes ont initialement supposé que la solution la plus performante serait probablement une solution basée sur le CLR. Kamil et Adam ont utilisé des approches similaires, la première tentative utilisant une boucle simple qui incrémente un compteur et produit une ligne avec la valeur suivante par itération, et la deuxième tentative plus sophistiquée qui combine les parties CLR et T-SQL. Personnellement, je ne me sens pas à l'aise avec le fait que dans les deuxièmes solutions de Kamil et d'Adam, ils s'appuyaient sur un filtre TOP non déterministe, et lorsque je l'ai converti en un filtre déterministe lors de mes propres tests, cela a eu un impact négatif sur les performances de la solution. . Either way, our two T-SQL solutions perform better than the CLR ones, and do not result in explicit sorting in the plan when you need the rows ordered. So I don’t really see the value in pursuing the CLR route any further. Figure 9 has a performance summary of the solutions that I presented in this article.
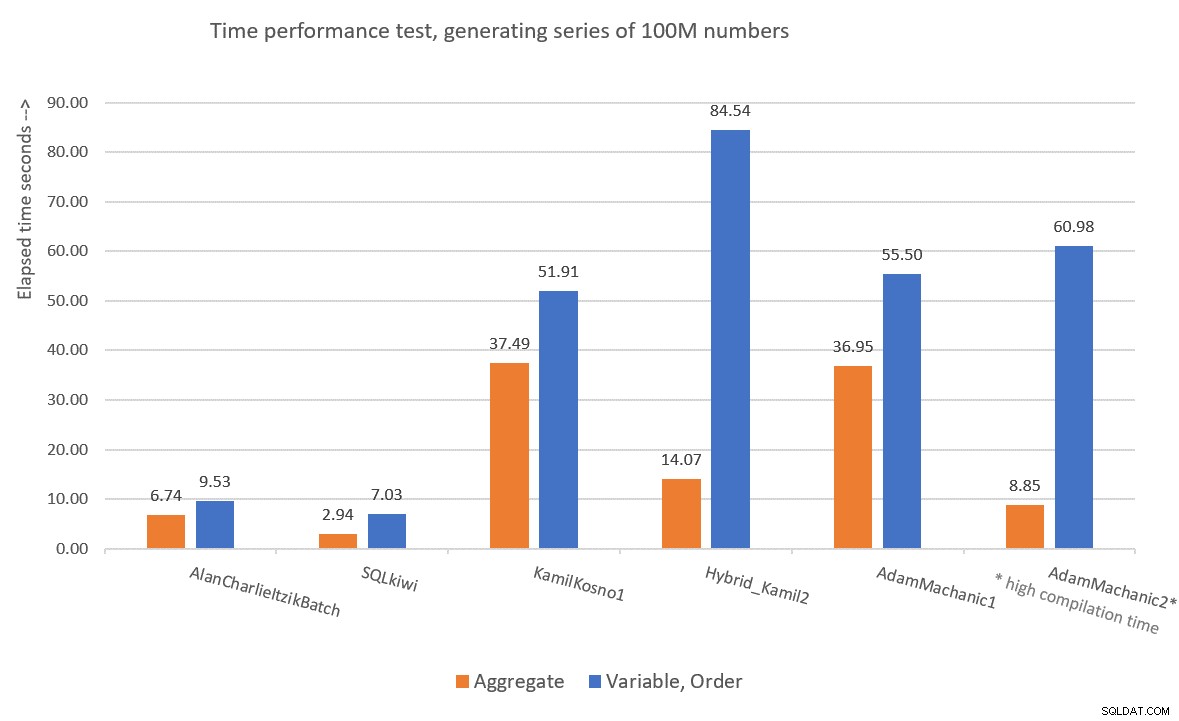 Figure 9:Time performance comparison
Figure 9:Time performance comparison
To me, GetNums_AlanCharlieItzikBatch should be the solution of choice when you require absolutely no I/O footprint, and GetNums_SQKWiki should be preferred when you don’t mind a small I/O footprint. Of course, we can always hope that one day Microsoft will add this critically useful tool as a built-in one, and hopefully if/when they do, it will be a performant solution that supports batch processing and parallelism. So don’t forget to vote for this feature improvement request, and maybe even add your comments for why it’s important for you.
I really enjoyed working on this series. I learned a lot during the process, and hope that you did too.



