Il y a presque un an jour pour jour, j'ai publié ma solution à la pagination dans SQL Server, qui impliquait d'utiliser un CTE pour localiser uniquement les valeurs clés de l'ensemble de lignes en question, puis de revenir du CTE à la table source pour récupérer les autres colonnes pour seulement cette "page" de lignes. Cela s'est avéré plus avantageux lorsqu'il y avait un index étroit qui prenait en charge le tri demandé par l'utilisateur, ou lorsque le tri était basé sur la clé de clustering, mais fonctionnait même un peu mieux sans index pour prendre en charge le tri requis.
Depuis lors, je me suis demandé si les index ColumnStore (à la fois clusterisés et non clusterisés) pourraient aider l'un de ces scénarios. TL;DR :Sur la base de cette expérience isolée, la réponse au titre de ce message est un NON retentissant . Si vous ne souhaitez pas voir la configuration du test, le code, les plans d'exécution ou les graphiques, n'hésitez pas à passer à mon résumé, en gardant à l'esprit que mon analyse est basée sur un cas d'utilisation très spécifique.
Configuration
Sur une nouvelle machine virtuelle avec SQL Server 2016 CTP 3.2 (13.0.900.73) installé, j'ai exécuté à peu près la même configuration qu'avant, mais cette fois avec trois tables. Tout d'abord, une table traditionnelle avec une clé de clustering étroite et plusieurs index de support :
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Ensuite, une table avec un index cluster ColumnStore :
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
Et enfin, une table avec un index ColumnStore non clusterisé couvrant toutes les colonnes :
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Notez que pour les deux tables avec des index ColumnStore, j'ai omis l'index qui prendrait en charge des recherches plus rapides sur le tri "PhoneBook" (nom, prénom).
Données de test
J'ai ensuite rempli le premier tableau avec 1 000 000 de lignes aléatoires, en me basant sur un script que j'ai réutilisé dans des articles précédents :
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Ensuite, j'ai utilisé cette table pour remplir les deux autres avec exactement les mêmes données, et j'ai reconstruit tous les index :
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
La taille totale de chaque tableau :
| Tableau | Réservé | Données | Index |
|---|---|---|---|
| Clients | 463 200 Ko | 154 344 Ko | 308 576 Ko |
| Clients_CCI | 117 280 Ko | 30 288 Ko | 86 536 Ko |
| Clients_NCCI | 349 480 Ko | 154 344 Ko | 194 976 Ko |
Et le nombre de lignes / nombre de pages des index pertinents (l'index unique sur les e-mails était là plus pour moi pour surveiller mon propre script de génération de données qu'autre chose) :
| Tableau | Index | Lignes | Pages |
|---|---|---|---|
| Clients | PK_Clients | 1 000 000 | 19 377 |
| Clients | PhoneBook_Customers | 1 000 000 | 17 209 |
| Clients | Clients_actifs | 808 012 | 13 977 |
| Clients_CCI | PK_CustomersCCI | 1 000 000 | 2 737 |
| Clients_CCI | Clients_CCI | 1 000 000 | 3 826 |
| Clients_NCCI | PK_CustomersNCCI | 1 000 000 | 19 377 |
| Clients_NCCI | Clients_NCCI | 1 000 000 | 16 971 |
Procédures
Ensuite, afin de voir si les index ColumnStore interviendraient et amélioreraient l'un des scénarios, j'ai exécuté le même ensemble de requêtes qu'auparavant, mais maintenant sur les trois tables. Je suis devenu au moins un peu plus intelligent et j'ai créé deux procédures stockées avec SQL dynamique pour accepter la source de la table et l'ordre de tri. (Je suis bien conscient de l'injection SQL ; ce n'est pas ce que je ferais en production si ces chaînes provenaient d'un utilisateur final, alors s'il vous plaît ne le prenez pas comme une recommandation de le faire. Je me fais juste assez confiance dans mon environnement clos que ce n'est pas un problème pour ces tests.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Ensuite, j'ai préparé du SQL plus dynamique pour générer toutes les combinaisons d'appels dont j'aurais besoin pour appeler à la fois les anciennes et les nouvelles procédures stockées, dans les trois ordres de tri souhaités et à différents numéros de page (pour simuler le besoin une page près du début, du milieu et de la fin de l'ordre de tri). Pour que je puisse copier PRINT sortie et collez-le dans SQL Sentry Plan Explorer afin d'obtenir des métriques d'exécution, j'ai exécuté ce lot deux fois, une fois avec les procedures CTE utilisant P_Old , puis à nouveau en utilisant P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Cela a produit une sortie comme celle-ci (36 appels au total pour l'ancienne méthode (P_Old ), et 36 appels pour la nouvelle méthode (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Je sais, tout cela est très lourd; nous arrivons bientôt à la punchline, je le promets.
Résultats
J'ai pris ces deux ensembles de 36 déclarations et commencé deux nouvelles sessions dans Plan Explorer, en exécutant chaque ensemble plusieurs fois pour m'assurer que nous obtenions des données d'un cache chaud et que nous prenions des moyennes (je pourrais aussi comparer le cache froid et chaud, mais je pense qu'il y a assez de variables ici).
Je peux vous dire d'emblée quelques faits simples sans même vous montrer de graphiques ou de plans à l'appui :
- Dans aucun scénario, l'"ancienne" méthode n'a battu la nouvelle méthode CTE J'ai fait la promotion dans mon post précédent, quel que soit le type d'index présents. Il est donc facile d'ignorer virtuellement la moitié des résultats, au moins en termes de durée (qui est la métrique la plus importante pour les utilisateurs finaux).
- Aucun index ColumnStore n'a bien fonctionné lors de la pagination vers la fin du résultat – ils ne fournissaient des prestations qu'au début, et seulement dans quelques cas.
- Lors du tri par clé primaire (cluster ou non), la présence d'index ColumnStore n'a pas aidé – encore une fois, en termes de durée.
Une fois ces résumés terminés, examinons quelques coupes transversales des données de durée. D'abord, les résultats de la requête triés par prénom décroissant, puis e-mail, sans espoir d'utiliser un index existant pour le tri. Comme vous pouvez le voir dans le graphique, les performances étaient incohérentes - à des numéros de page inférieurs, le ColumnStore non clusterisé s'en sortait mieux; à des numéros de page plus élevés, l'index traditionnel a toujours gagné :
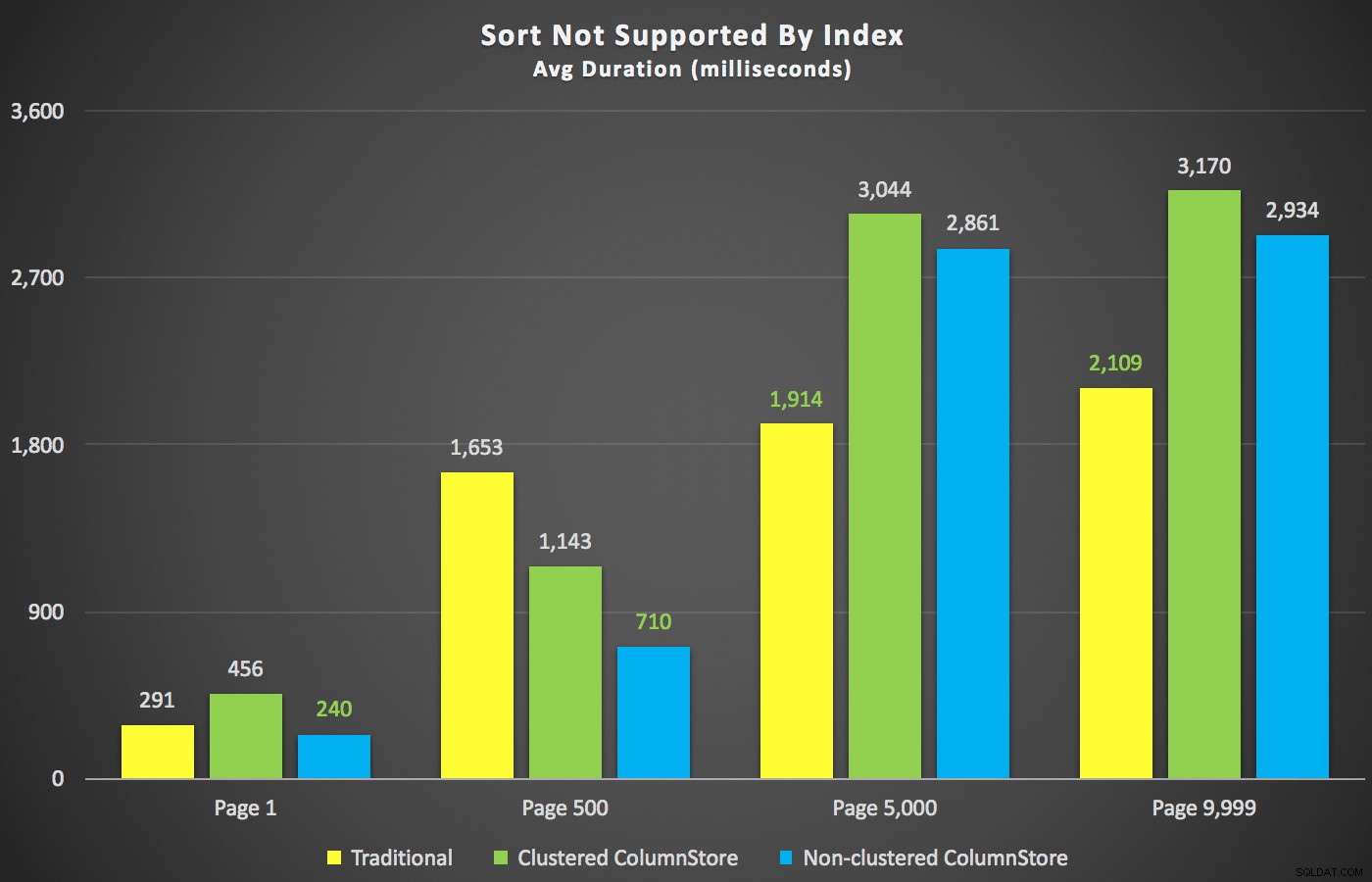 Durée (millisecondes) pour différents numéros de page et différents types d'index
Durée (millisecondes) pour différents numéros de page et différents types d'index
Et puis les trois plans représentant les trois différents types d'index (avec des niveaux de gris ajoutés par Photoshop afin de mettre en évidence les différences majeures entre les plans) :
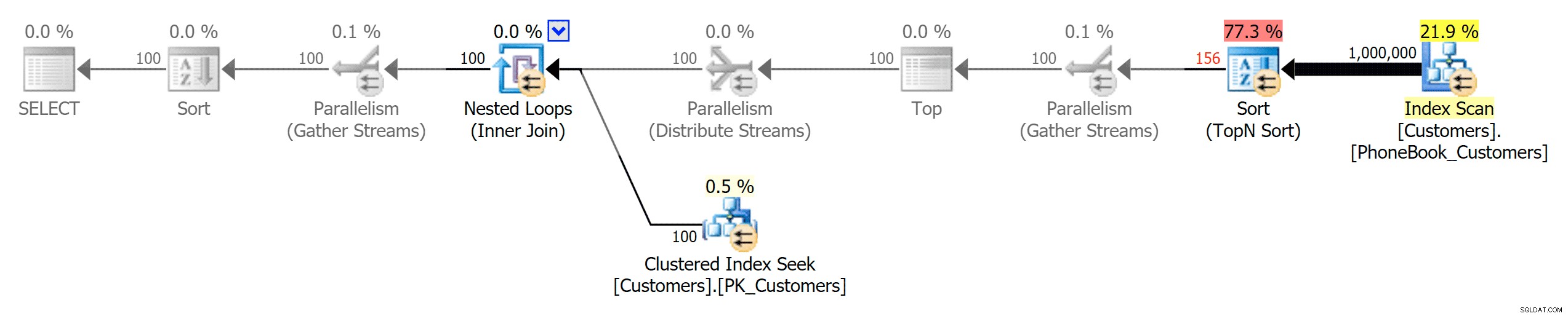 Planifier l'index traditionnel
Planifier l'index traditionnel
 Planifier l'index ColumnStore en cluster
Planifier l'index ColumnStore en cluster
 Planifier un index ColumnStore non clusterisé
Planifier un index ColumnStore non clusterisé
Un scénario qui m'intéressait davantage, avant même de commencer les tests, était l'approche de tri de l'annuaire téléphonique (nom, prénom). Dans ce cas, les index ColumnStore étaient en fait assez préjudiciables aux performances du résultat :
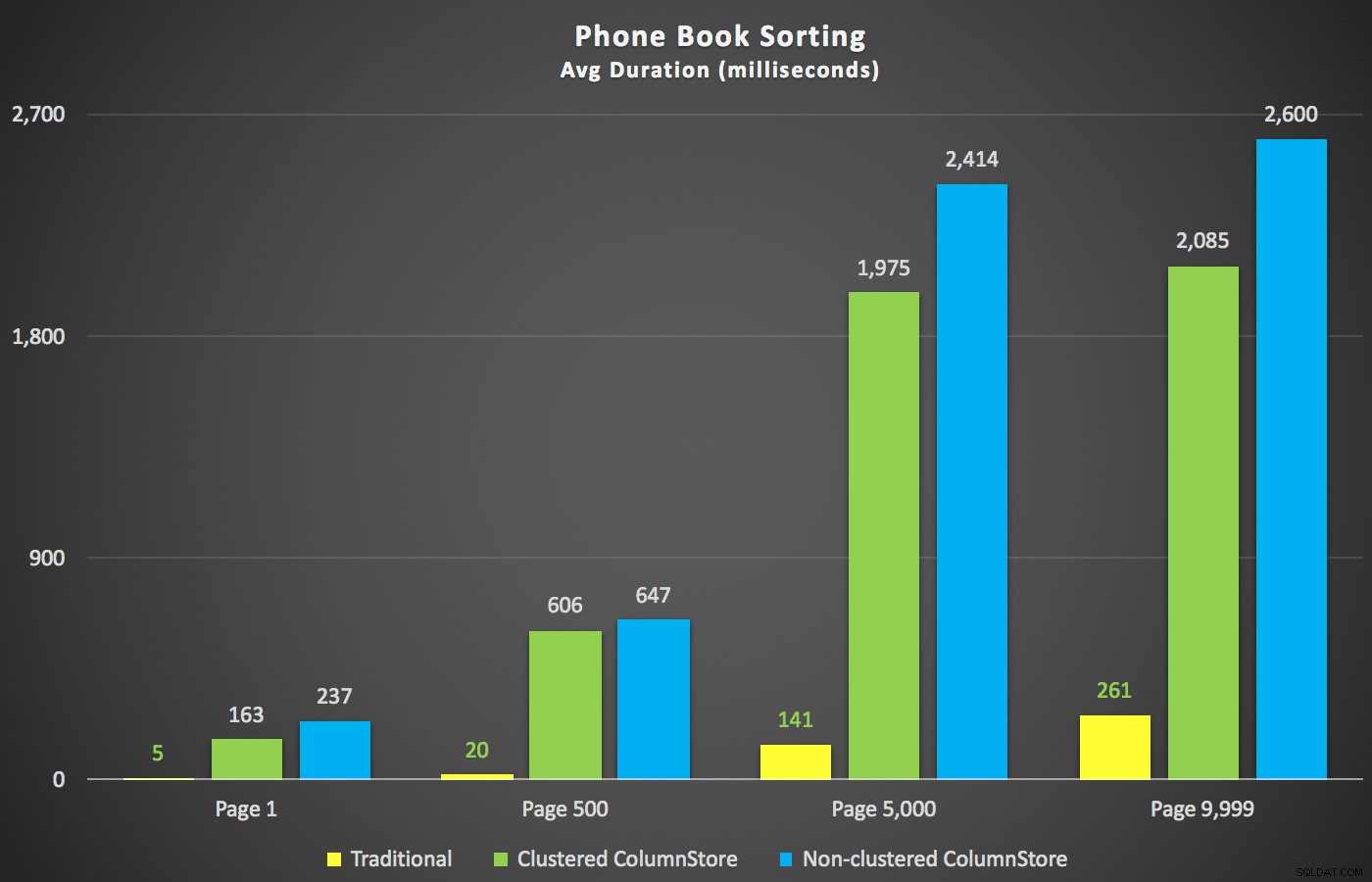
Les plans ColumnStore ici sont proches des images miroir des deux plans ColumnStore indiqués ci-dessus pour le tri non pris en charge. La raison est la même dans les deux cas :analyses ou tris coûteux en raison de l'absence d'un index prenant en charge le tri.
Ensuite, j'ai également créé des index "PhoneBook" sur les tables avec les index ColumnStore, pour voir si je pouvais obtenir un plan différent et/ou des temps d'exécution plus rapides dans l'un de ces scénarios. J'ai créé ces deux index, puis reconstruit à nouveau :
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Voici les nouvelles durées :
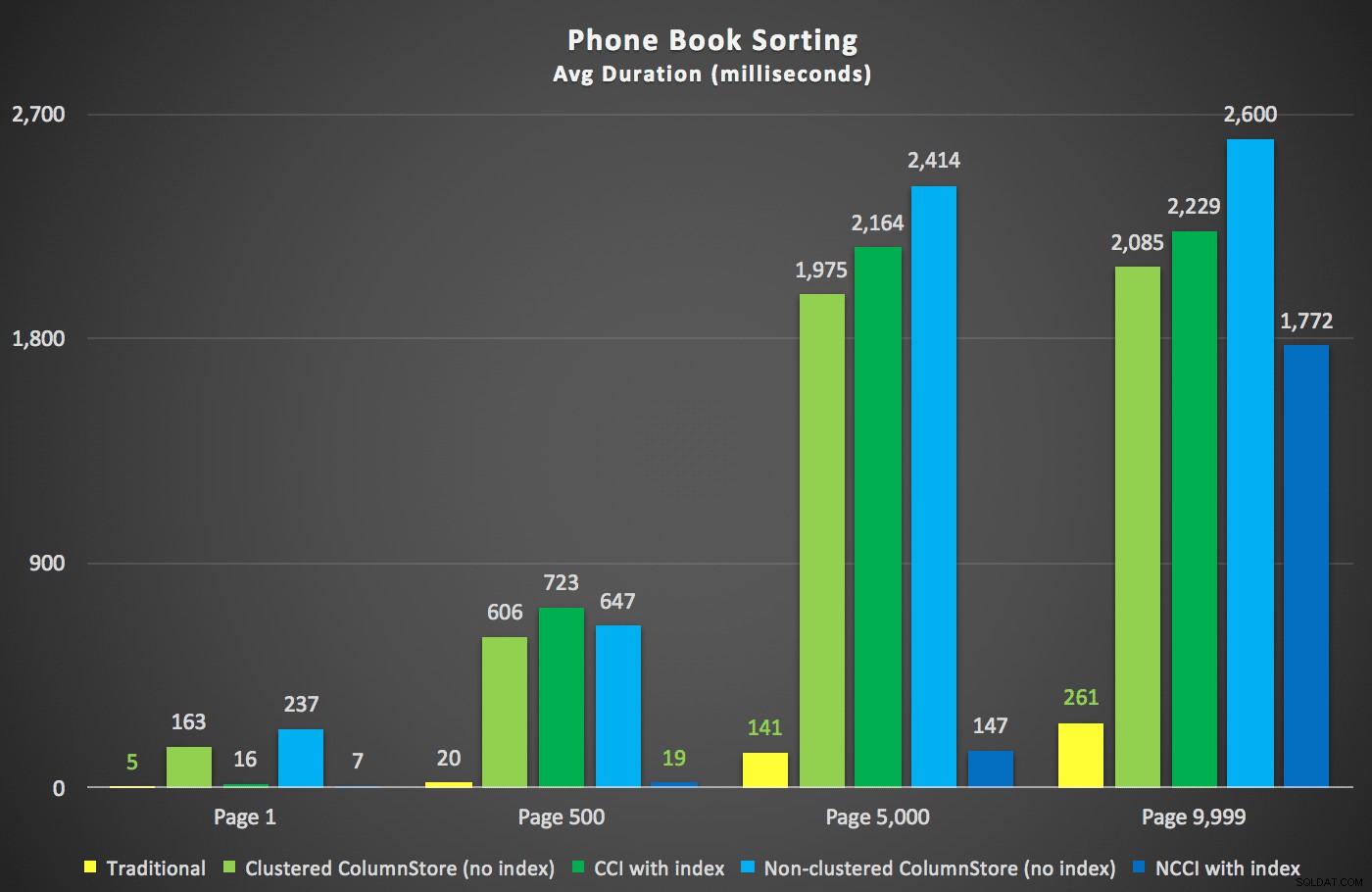
Le plus intéressant ici est que maintenant la requête de pagination sur la table avec l'index ColumnStore non clusterisé semble suivre le rythme de l'index traditionnel, jusqu'à ce que nous dépassions le milieu de la table. En regardant les plans, nous pouvons voir qu'à la page 5 000, un parcours d'index traditionnel est utilisé, et l'index ColumnStore est complètement ignoré :
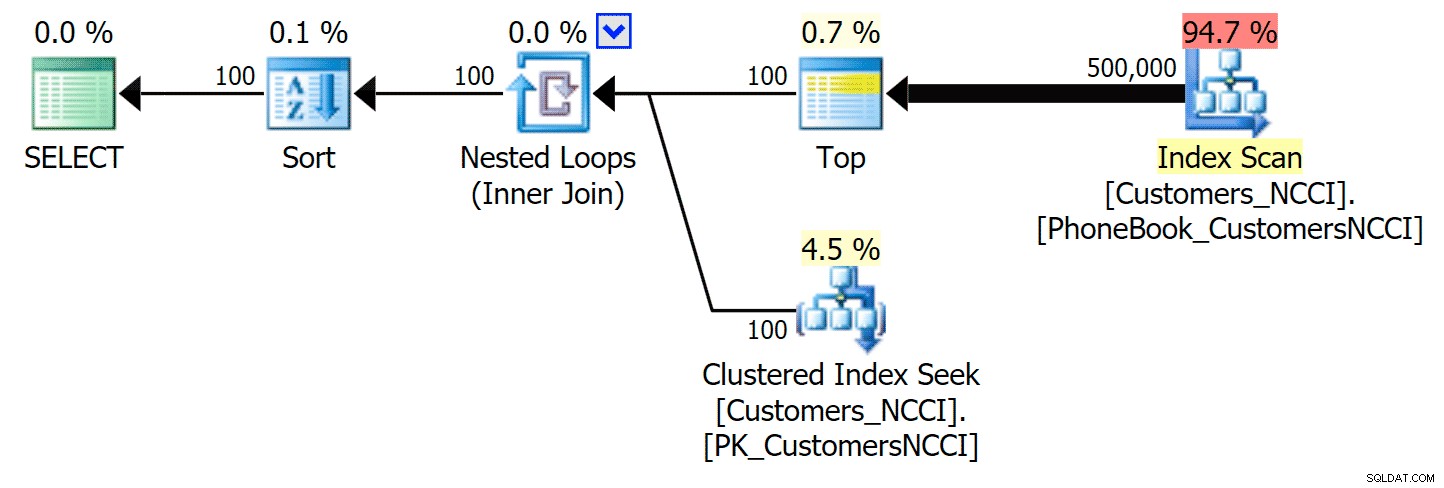 Plan d'annuaire téléphonique ignorant l'index ColumnStore non clusterisé
Plan d'annuaire téléphonique ignorant l'index ColumnStore non clusterisé
Mais quelque part entre le point médian de 5 000 pages et la "fin" du tableau à 9 999 pages, l'optimiseur a atteint une sorte de point de basculement et - pour exactement la même requête - choisit maintenant d'analyser l'index ColumnStore non clusterisé :
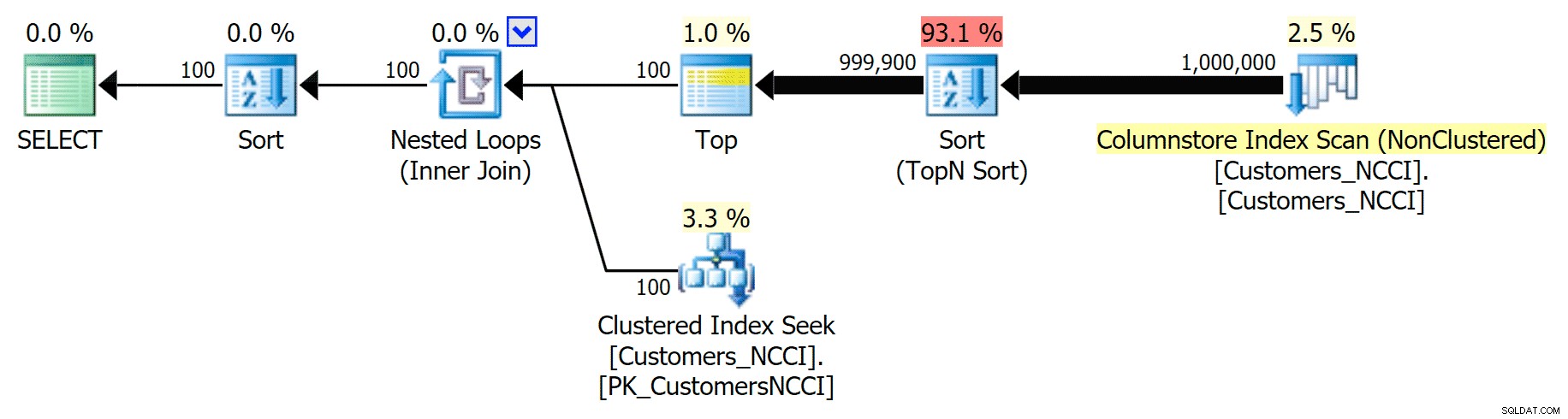 Le plan d'annuaire téléphonique 'conseils' et utilise l'index ColumnStore
Le plan d'annuaire téléphonique 'conseils' et utilise l'index ColumnStore
Cela s'avère être une décision pas si importante de la part de l'optimiseur, principalement en raison du coût de l'opération de tri. Vous pouvez voir à quel point la durée s'améliore si vous faites allusion à l'index régulier :
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Cela donne le plan suivant, presque identique au premier plan ci-dessus (un coût légèrement plus élevé pour l'analyse, simplement parce qu'il y a plus de sortie) :
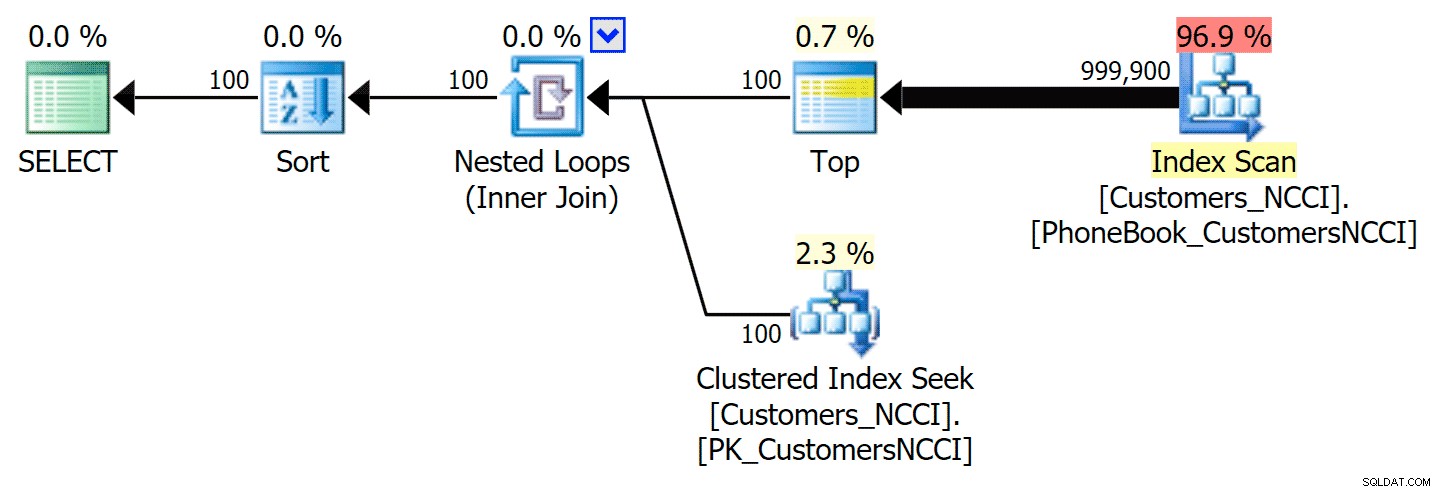 Plan d'annuaire téléphonique avec index suggéré
Plan d'annuaire téléphonique avec index suggéré
Vous pouvez obtenir la même chose en utilisant OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) au lieu de l'indication d'index explicite. Gardez simplement à l'esprit que cela revient à ne pas avoir l'index ColumnStore en premier lieu.
Conclusion
Bien qu'il existe quelques cas extrêmes ci-dessus où un index ColumnStore pourrait (à peine) être rentable, il ne me semble pas qu'ils conviennent à ce scénario de pagination spécifique. Je pense que, plus important encore, bien que ColumnStore démontre des économies d'espace importantes grâce à la compression, les performances d'exécution ne sont pas fantastiques en raison des exigences de tri (même si ces tris sont censés s'exécuter en mode batch, une nouvelle optimisation pour SQL Server 2016).
En général, cela pourrait nécessiter beaucoup plus de temps consacré à la recherche et aux tests ; en m'appuyant sur les articles précédents, je voulais changer le moins possible. J'aimerais trouver ce point de basculement, par exemple, et j'aimerais également reconnaître qu'il ne s'agit pas exactement de tests à grande échelle (en raison de la taille de la machine virtuelle et des limitations de mémoire), et que je vous ai laissé deviner beaucoup de les métriques d'exécution (principalement pour la brièveté, mais je ne sais pas si un graphique de lectures qui ne sont pas toujours proportionnelles à la durée vous le dira vraiment). Ces tests supposent également le luxe des SSD, une mémoire suffisante, un cache toujours chaud et un environnement mono-utilisateur. J'aimerais vraiment effectuer une plus grande batterie de tests sur plus de données, sur des serveurs plus gros avec des disques plus lents et des instances avec moins de mémoire, tout en simulant la simultanéité.
Cela dit, cela pourrait aussi être juste un scénario que ColumnStore n'est pas conçu pour aider à résoudre en premier lieu, car la solution sous-jacente avec des index traditionnels est déjà assez efficace pour extraire un ensemble restreint de lignes - pas exactement la timonerie de ColumnStore. Peut-être une autre variable à ajouter à la matrice est la taille de la page - tous les tests ci-dessus tirent 100 lignes à la fois, mais que se passe-t-il si nous recherchons 10 000 ou 100 000 lignes à la fois, quelle que soit la taille de la table sous-jacente ?
Avez-vous une situation où votre charge de travail OLTP a été améliorée simplement par l'ajout d'index ColumnStore ? Je sais qu'ils sont conçus pour des charges de travail de type entrepôt de données, mais si vous avez constaté des avantages ailleurs, j'aimerais connaître votre scénario et voir si je peux incorporer des différenciateurs dans mon banc de test.