[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]
Le problème d'Halloween peut avoir un certain nombre d'effets importants sur les plans d'exécution. Dans cette dernière partie de la série, nous examinons les astuces que l'optimiseur peut utiliser pour éviter le problème d'Halloween lors de la compilation de plans pour les requêtes qui ajoutent, modifient ou suppriment des données.
Contexte
Au fil des ans, un certain nombre d'approches ont été essayées pour éviter le problème d'Halloween. L'une des premières techniques consistait simplement à éviter de créer des plans d'exécution impliquant la lecture et l'écriture de clés du même index. Cela n'a pas été très efficace du point de vue des performances, notamment parce que cela impliquait souvent d'analyser la table de base au lieu d'utiliser un index sélectif non clusterisé pour localiser les lignes à modifier.
Une deuxième approche consistait à séparer complètement les phases de lecture et d'écriture d'une requête de mise à jour, en localisant d'abord toutes les lignes éligibles pour la modification, en les stockant quelque part, puis en commençant seulement à effectuer les modifications. Dans SQL Server, cette séparation de phase complète est obtenu en plaçant le désormais familier Eager Table Spool du côté entrée de l'opérateur de mise à jour :
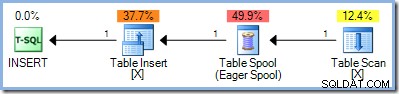
Le spool lit toutes les lignes de son entrée et les stocke dans un tempdb caché table de travail. Les pages de cette table de travail peuvent rester en mémoire ou nécessiter de l'espace disque physique si l'ensemble de lignes est volumineux ou si le serveur est sous pression mémoire.
La séparation complète des phases peut être loin d'être idéale, car nous souhaitons généralement exécuter autant de plans que possible sous forme de pipeline, où chaque ligne est entièrement traitée avant de passer à la suivante. Le pipelining présente de nombreux avantages, notamment le fait d'éviter le besoin d'un stockage temporaire et de ne toucher qu'une seule fois chaque ligne.
L'optimiseur SQL Server
SQL Server va bien plus loin que les deux techniques décrites jusqu'ici, même s'il inclut bien sûr les deux en option. L'optimiseur de requêtes SQL Server détecte les requêtes qui nécessitent la protection d'Halloween, détermine combien une protection est requise et utilise une approche basée sur les coûts analyse pour trouver la méthode la moins chère pour fournir cette protection.
La façon la plus simple de comprendre cet aspect du problème d'Halloween est de regarder quelques exemples. Dans les sections suivantes, la tâche consiste à ajouter une plage de nombres à une table existante - mais uniquement des nombres qui n'existent pas déjà :
CREATE TABLE dbo.Test( pk entier NOT NULL, CONTRAINTE PK_Test PRIMARY KEY CLUSTERED (pk));
5 lignes
Le premier exemple traite une plage de nombres de 1 à 5 inclus :
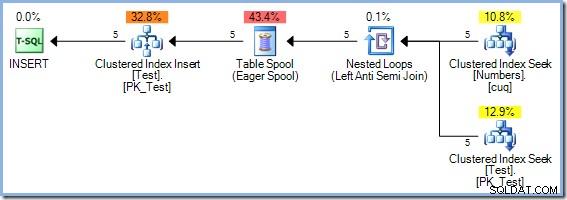
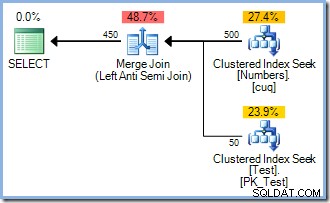
INSERT dbo.Test (pk)SELECT Num.n FROM dbo.Numbers AS NumWHERE Num.n BETWEEN 1 AND 5 AND NOT EXISTS ( SELECT NULL FROM dbo.Test AS t WHERE t.pk =Num.n );Étant donné que cette requête lit et écrit dans les clés du même index sur la table Test, le plan d'exécution nécessite la protection Halloween. Dans ce cas, l'optimiseur utilise une séparation de phase complète à l'aide d'un Eager Table Spool :
50 lignes
Avec cinq lignes maintenant dans la table Test, nous exécutons à nouveau la même requête, en modifiant le
WHEREclause pour traiter les nombres de 1 à 50 inclus :
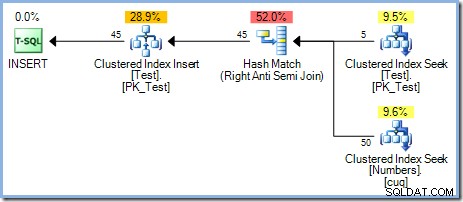
Ce plan offre une protection correcte contre le problème d'Halloween, mais il ne comporte pas de bobine de table Eager. L'optimiseur reconnaît que l'opérateur de jointure Hash Match bloque sur son entrée de génération; toutes les lignes sont lues dans une table de hachage avant que l'opérateur ne démarre le processus de correspondance en utilisant les lignes de l'entrée de la sonde. En conséquence, ce plan fournit naturellement une séparation de phase (pour la table de test uniquement) sans avoir besoin d'une bobine.
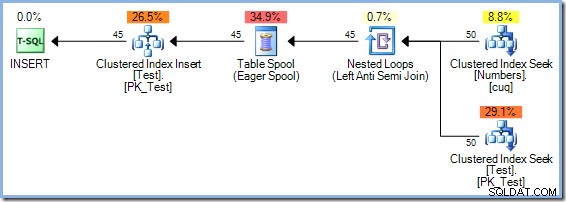
L'optimiseur a choisi un plan de jointure Hash Match plutôt que la jointure Nested Loops vue dans le plan à 5 lignes pour des raisons de coût. Le plan Hash Match à 50 lignes a un coût total estimé à 0,0347345 unités. On peut forcer le plan Nested Loops utilisé précédemment avec un indice pour voir pourquoi l'optimiseur n'a pas choisi les boucles imbriquées :
Ce forfait a un coût estimé à 0,0379063 unités, y compris la bobine, un peu plus que le plan Hash Match.
500 lignes
Avec 50 lignes maintenant dans le tableau Test, nous augmentons encore la plage de nombres à 500 :
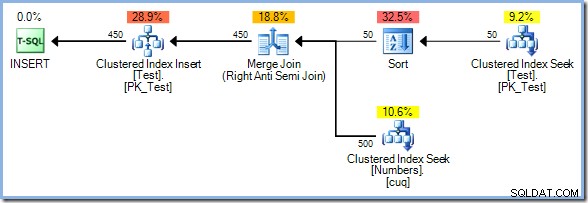
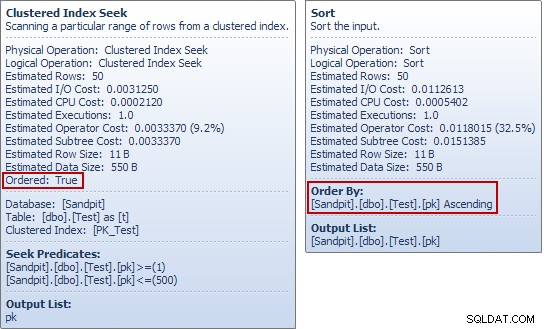
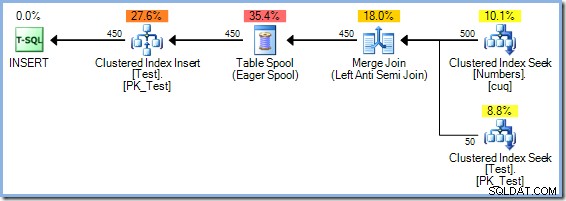
Cette fois, l'optimiseur choisit une jointure de fusion, et encore une fois, il n'y a pas de spool de table impatient. L'opérateur de tri fournit la séparation de phase nécessaire dans ce plan. Il consomme entièrement son entrée avant de renvoyer la première ligne (le tri ne peut pas savoir quelle ligne est triée en premier tant que toutes les lignes n'ont pas été vues). L'optimiseur a décidé que le tri de 50 les lignes de la table de test seraient moins chères que la mise en file d'attente de 450 lignes juste avant l'opérateur de mise à jour.
Le plan Sort plus Merge Join a un coût estimé à 0,0362708 unités. Les alternatives de plan Hash Match et Nested Loops sortent à 0.0385677 unités et 0,112433 unités respectivement.
Quelque chose d'étrange à propos du tri
Si vous avez exécuté ces exemples pour vous-même, vous avez peut-être remarqué quelque chose d'étrange à propos de ce dernier exemple, en particulier si vous avez consulté les info-bulles de l'explorateur de plans pour la recherche de table de test et le tri :
Le Seek produit un ordonné flux de pk valeurs, alors quel est l'intérêt de trier sur la même colonne immédiatement après ? Pour répondre à cette question (très raisonnable), nous commençons par examiner uniquement le
SELECTpartie deINSERTrequête :SELECT Num.n FROM dbo.Numbers AS NumWHERE Num.n BETWEEN 1 AND 500 AND NOT EXISTS ( SELECT 1 FROM dbo.Test AS t WHERE t.pk =Num.n )ORDER BY Num.n;Cette requête produit le plan d'exécution ci-dessous (avec ou sans le
ORDER BYJ'ai ajouté pour répondre à certaines objections techniques que vous pourriez avoir) :
Remarquez l'absence d'opérateur de tri. Alors pourquoi le
INSERTplan inclut un tri ? Simplement pour éviter le problème d'Halloween. L'optimiseur a considéré que l'exécution d'un tri redondant (avec sa séparation de phase intégrée) était le moyen le moins cher d'exécuter la requête et de garantir des résultats corrects. Astucieux.Niveaux de protection et propriétés d'Halloween
L'optimiseur SQL Server possède des fonctionnalités spécifiques qui lui permettent de raisonner sur le niveau de protection Halloween (HP) requis à chaque point du plan de requête et sur l'effet détaillé de chaque opérateur. Ces fonctionnalités supplémentaires sont incorporées dans le même cadre de propriétés que celui utilisé par l'optimiseur pour suivre des centaines d'autres éléments d'information importants au cours de ses activités de recherche.
Chaque opérateur a un obligatoire Propriété HP et un livré Propriété HP. Le requis La propriété indique le niveau de HP nécessaire à ce point de l'arborescence pour obtenir des résultats corrects. Le livré la propriété reflète les HP fournis par l'opérateur actuel et le cumulatif Effets HP fournis par son sous-arbre.
L'optimiseur contient une logique pour déterminer comment chaque opérateur physique (par exemple, un scalaire de calcul) affecte le niveau HP. En explorant un large éventail d'alternatives de plan et en rejetant les plans où le HP fourni est inférieur au HP requis chez l'opérateur de mise à jour, l'optimiseur dispose d'un moyen flexible pour trouver des plans corrects et efficaces qui ne nécessitent pas toujours un Eager Table Spool.
Modifications du plan pour la protection d'Halloween
Nous avons vu l'optimiseur ajouter un tri redondant pour Halloween Protection dans l'exemple précédent de Merge Join. Comment pouvons-nous être sûrs que cela est plus efficace qu'une simple bobine de table Eager ? Et comment pouvons-nous savoir quelles fonctionnalités d'un plan de mise à jour sont uniquement disponibles pour la protection d'Halloween ?
Il est possible de répondre aux deux questions (dans un environnement de test, naturellement) en utilisant l'indicateur de trace non documenté 8692 , ce qui oblige l'optimiseur à utiliser une bobine de table impatiente pour la protection d'Halloween. Rappelez-vous que le plan Merge Join avec le tri redondant avait un coût estimé de 0,0362708 unités d'optimisation magiques. Nous pouvons comparer cela à l'alternative Eager Table Spool en recompilant la requête avec l'indicateur de trace 8692 activé :
INSERT dbo.Test (pk)SELECT Num.n FROM dbo.Numbers AS NumWHERE Num.n BETWEEN 1 AND 500 AND NOT EXISTS ( SELECT 1 FROM dbo.Test AS t WHERE t.pk =Num.n )OPTION ( QUERYTRACEON 8692);
Le plan Eager Spool a un coût estimé à 0,0378719 unités (au lieu de 0,0362708 avec le tri redondant). Les différences de coût présentées ici ne sont pas très significatives en raison de la nature triviale de la tâche et de la petite taille des lignes. Les requêtes de mise à jour réelles avec des arborescences complexes et un plus grand nombre de lignes produisent souvent des plans beaucoup plus efficaces grâce à la capacité de l'optimiseur SQL Server à réfléchir en profondeur à la protection d'Halloween.
Autres options sans bobine
Le positionnement optimal d'un opérateur de blocage dans un plan n'est pas la seule stratégie ouverte à l'optimiseur pour minimiser le coût de la protection contre le problème d'Halloween. Il peut également raisonner sur la plage de valeurs en cours de traitement, comme le montre l'exemple suivant :
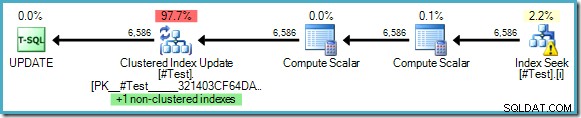
CREATE TABLE #Test( pk integer IDENTITY PRIMARY KEY, some_value integer); CREATE INDEX i ON #Test (some_value); -- Supposons que la table contienne beaucoup de donnéesUPDATE STATISTICS #TestWITH ROWCOUNT =123456, PAGECOUNT =1234; MISE À JOUR #TestSET some_value =10WHERE some_value =5;Le plan d'exécution ne montre aucun besoin de Halloween Protection, malgré le fait que nous lisons et mettons à jour les clés d'un index commun :
L'optimiseur peut voir que la modification de "some_value" de 5 à 10 ne pourrait jamais entraîner la visualisation d'une ligne mise à jour une deuxième fois par Index Seek (qui ne recherche que les lignes où some_value est 5). Ce raisonnement n'est possible que lorsque des valeurs littérales sont utilisées dans la requête, ou lorsque la requête spécifie
OPTION (RECOMPILE), permettant à l'optimiseur de détecter les valeurs des paramètres pour un plan d'exécution ponctuel.Même avec des valeurs littérales dans la requête, l'optimiseur peut être empêché d'appliquer cette logique si l'option de base de données
FORCED PARAMETERIZATIONestON. Dans ce cas, les valeurs littérales de la requête sont remplacées par des paramètres, et l'optimiseur ne peut plus être sûr que la protection Halloween n'est pas requise (ou ne sera pas requise lorsque le plan est réutilisé avec des valeurs de paramètres différentes) :
Au cas où vous vous demanderiez ce qui se passe si
FORCED PARAMETERIZATIONest activé et la requête spécifieOPTION (RECOMPILE), la réponse est que l'optimiseur compile un plan pour les valeurs reniflées et peut donc appliquer l'optimisation. Comme toujours avecOPTION (RECOMPILE), le plan de requête à valeur spécifique n'est pas mis en cache pour être réutilisé.Haut
Ce dernier exemple montre comment le
Topl'opérateur peut supprimer le besoin de protection Halloween :UPDATE TOP (1) tSET some_value +=1FROM #Test AS tWHERE some_value <=10;
Aucune protection n'est requise car nous ne mettons à jour qu'une seule ligne. La valeur mise à jour ne peut pas être rencontrée par Index Seek, car le pipeline de traitement s'arrête dès que la première ligne est mise à jour. Encore une fois, cette optimisation ne peut être appliquée que si une valeur littérale constante est utilisée dans le
TOP, ou si une variable retournant la valeur '1' est sniffée en utilisantOPTION (RECOMPILE).Si on change le
TOP (1)dans la requête à unTOP (2), l'optimiseur choisit un balayage d'index clusterisé au lieu de la recherche d'index :
Nous ne mettons pas à jour les clés de l'index clusterisé, ce plan ne nécessite donc pas la protection Halloween. Forcer l'utilisation de l'index non-cluster avec un indice dans le
TOP (2)requête rend évident le coût de la protection :
L'optimiseur a estimé que l'analyse de l'index clusterisé serait moins chère que ce plan (avec sa protection Halloween supplémentaire).
Des bric et de broc
Il y a quelques autres points que je veux souligner à propos de la protection d'Halloween qui n'ont pas trouvé de place naturelle dans la série jusqu'à présent. Le premier est la question de la protection d'Halloween lorsqu'un niveau d'isolation de version de ligne est utilisé.
Gestion des versions de ligne
SQL Server fournit deux niveaux d'isolement,
READ COMMITTED SNAPSHOTetSNAPSHOT ISOLATIONqui utilisent un magasin de versions dans tempdb pour fournir une vue cohérente de la base de données au niveau de l'instruction ou de la transaction. SQL Server pourrait éviter complètement la protection Halloween sous ces niveaux d'isolement, car le magasin de versions peut fournir des données non affectées par les modifications que l'instruction en cours d'exécution aurait pu apporter jusqu'à présent. Cette idée n'est actuellement pas implémentée dans une version publiée de SQL Server, bien que Microsoft ait déposé un brevet décrivant comment cela fonctionnerait, alors peut-être qu'une future version intégrera cette technologie.Tas et enregistrements transférés
Si vous connaissez les rouages des structures de tas, vous vous demandez peut-être si un problème Halloween particulier peut se produire lorsque des enregistrements transférés sont générés dans une table de tas. Si cela est nouveau pour vous, un enregistrement de tas sera transmis si une ligne existante est mise à jour de sorte qu'elle ne tient plus sur la page de données d'origine. Le moteur laisse derrière lui un talon de transfert et déplace l'enregistrement développé vers une autre page.
Un problème peut survenir si un plan contenant une analyse de tas met à jour un enregistrement de sorte qu'il soit transféré. L'analyse du tas peut rencontrer à nouveau la ligne lorsque la position d'analyse atteint la page avec l'enregistrement transféré. Dans SQL Server, ce problème est évité car le moteur de stockage garantit de toujours suivre immédiatement les pointeurs de transfert. Si l'analyse rencontre un enregistrement qui a été transféré, elle l'ignore. Avec cette protection en place, l'optimiseur de requête n'a pas à se soucier de ce scénario.
SCHEMABINDING et fonctions scalaires T-SQL
Il y a très peu d'occasions où l'utilisation d'une fonction scalaire T-SQL est une bonne idée, mais si vous devez en utiliser une, vous devez être conscient de l'effet important qu'elle peut avoir sur la protection d'Halloween. Sauf si une fonction scalaire est déclarée avec le
SCHEMABINDINGoption, SQL Server suppose que la fonction accède aux tables. Pour illustrer, considérez la simple fonction scalaire T-SQL ci-dessous :CREATE FUNCTION dbo.ReturnInput( @value integer)RETURNS integerASBEGIN RETURN @value;END;Cette fonction n'accède à aucune table; en fait, il ne fait rien d'autre que renvoyer la valeur du paramètre qui lui est transmise. Regardez maintenant le
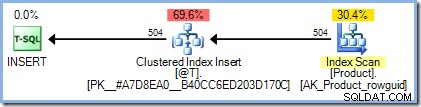
INSERTsuivant requête :DECLARE @T AS TABLE (ProductID entier PRIMARY KEY); INSERT @T (ProductID)SELECT p.ProductIDFROM AdventureWorks2012.Production.Product AS p;Le plan d'exécution est exactement ce à quoi nous nous attendions, sans qu'aucune protection d'Halloween ne soit nécessaire :
Cependant, l'ajout de notre fonction ne rien faire a un effet spectaculaire :
DECLARE @T AS TABLE (ProductID entier PRIMARY KEY); INSERT @T (ProductID)SELECT dbo.ReturnInput(p.ProductID)FROM AdventureWorks2012.Production.Product AS p ;
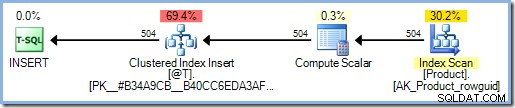
Le plan d'exécution comprend désormais une bobine de table Eager pour la protection d'Halloween. SQL Server suppose que la fonction accède aux données, ce qui peut inclure une nouvelle lecture à partir de la table Product. Comme vous vous en souvenez peut-être, un
INSERTplan qui contient une référence à la table cible du côté lecture du plan nécessite une protection Halloween complète, et pour autant que l'optimiseur le sache, cela pourrait être le cas ici.Ajout du
SCHEMABINDINGL'option à la définition de la fonction signifie que SQL Server examine le corps de la fonction pour déterminer les tables auxquelles il accède. Il ne trouve aucun accès de ce type et n'ajoute donc aucune protection Halloween :ALTER FUNCTION dbo.ReturnInput( @value integer)RETURNS integerWITH SCHEMABINDINGASBEGIN RETURN @value;END;GODECLARE @T AS TABLE (ProductID int PRIMARY KEY); INSERT @T (ProductID)SELECT p.ProductIDFROM AdventureWorks2012.Production.Product AS p;
Ce problème avec les fonctions scalaires T-SQL affecte toutes les requêtes de mise à jour -
INSERT,UPDATE,DELETE, etMERGE. Savoir quand vous rencontrez ce problème est rendu plus difficile car la protection Halloween inutile n'apparaîtra pas toujours comme un spool de table Eager supplémentaire, et les appels de fonction scalaire peuvent être masqués dans les vues ou les définitions de colonnes calculées, par exemple.[ Partie 1 | Partie 2 | Partie 3 | Partie 4 ]