En rupture avec ma série sur le "réglage des performances par réflexe", j'aimerais discuter de la façon dont la fragmentation de l'index peut vous surprendre dans certaines circonstances.
Qu'est-ce que la fragmentation d'index ?
La plupart des gens pensent que la « fragmentation de l'index » signifie le problème où les pages feuille d'index sont hors service - la page feuille d'index avec la valeur de clé suivante n'est pas celle qui est physiquement contiguë dans le fichier de données à la page feuille d'index en cours d'examen. . C'est ce qu'on appelle la fragmentation logique (et certaines personnes l'appellent fragmentation externe - un terme déroutant que je n'aime pas).
La fragmentation logique se produit lorsqu'une feuille d'index est pleine et qu'il faut de l'espace dessus, soit pour une insertion, soit pour allonger un enregistrement existant (à partir de la mise à jour d'une colonne de longueur variable). Dans ce cas, le moteur de stockage crée une nouvelle page vide et déplace 50 % des lignes (généralement, mais pas toujours) de la page complète vers la nouvelle page. Cette opération crée de l'espace dans les deux pages, permettant à l'insertion ou à la mise à jour de se poursuivre, et s'appelle un fractionnement de page. Il existe des cas pathologiques intéressants impliquant des fractionnements de page répétés à partir d'une seule opération et des fractionnements de page qui remontent les niveaux d'index, mais ils dépassent le cadre de cet article.
Lorsqu'un fractionnement de page se produit, il provoque généralement une fragmentation logique car il est très peu probable que la nouvelle page allouée soit physiquement contiguë à celle qui est fractionnée. Lorsqu'un index a beaucoup de fragmentation logique, les balayages d'index sont ralentis car les lectures physiques des pages nécessaires ne peuvent pas être effectuées aussi efficacement (en utilisant des lectures 'readahead' multi-pages) lorsque les pages feuille ne sont pas stockées dans l'ordre dans le fichier de données .
C'est la définition de base de la fragmentation d'index, mais il existe un deuxième type de fragmentation d'index que la plupart des gens ne considèrent pas :la faible densité de pages (parfois appelée fragmentation interne, encore une fois, un terme déroutant que je n'aime pas).
La densité de page est une mesure de la quantité de données stockées sur une page feuille d'index. Lorsqu'une division de page se produit avec le cas habituel 50/50, chaque page feuille (celle qui se divise et la nouvelle) se retrouve avec une densité de page de seulement 50 %. Plus la densité de page est faible, plus il y a d'espace vide dans l'index et donc plus d'espace disque et de mémoire tampon que vous pouvez considérer comme gaspillés. J'ai blogué sur ce problème il y a quelques années et vous pouvez en savoir plus ici.
Maintenant que j'ai donné une définition de base des deux types de fragmentation d'index, je vais les appeler collectivement simplement "fragmentation".
Pour le reste de cet article, j'aimerais discuter de trois cas où les index clusterisés peuvent se fragmenter même si vous évitez les opérations qui entraîneraient évidemment la fragmentation (c'est-à-dire que les insertions aléatoires et la mise à jour des enregistrements sont plus longues).
Fragmentation à partir des suppressions
"Comment une suppression d'une page feuille d'index en cluster peut-elle provoquer une division de page ?" vous demandez peut-être. Ce ne sera pas le cas, dans des circonstances normales (et j'y ai réfléchi pendant quelques minutes pour m'assurer qu'il n'y avait pas de cas pathologique étrange ! Mais voir la section ci-dessous…) Cependant, les suppressions peuvent entraîner une diminution progressive de la densité des pages.
Imaginez le cas où l'index clusterisé a une valeur de clé d'identité bigint, de sorte que les insertions iront toujours du côté droit de l'index et ne seront jamais, jamais insérées dans une partie antérieure de l'index (à moins que quelqu'un ne réensemence la valeur d'identité - potentiellement très problématique !). Imaginez maintenant que la charge de travail supprime les enregistrements de la table qui ne sont plus nécessaires, après quoi la tâche de nettoyage fantôme en arrière-plan récupérera l'espace sur la page et il deviendra de l'espace libre.
En l'absence d'insertions aléatoires (impossible dans notre scénario à moins que quelqu'un réensemence l'identité ou spécifie une valeur de clé à utiliser après avoir activé SET IDENTITY INSERT pour la table), aucun nouvel enregistrement n'utilisera jamais l'espace qui a été libéré des enregistrements supprimés. Cela signifie que la densité moyenne des pages des premières parties de l'index clusterisé diminuera régulièrement, ce qui entraînera une augmentation de l'espace disque gaspillé et de la mémoire du pool de mémoire tampon, comme je l'ai décrit précédemment.
Les suppressions peuvent entraîner une fragmentation, tant que vous considérez la densité des pages comme faisant partie de la "fragmentation".
Fragmentation à partir de l'isolement de l'instantané
SQL Server 2005 a introduit deux nouveaux niveaux d'isolement :l'isolement d'instantané et l'isolement d'instantané validé en lecture. Ces deux éléments ont une sémantique légèrement différente, mais permettent essentiellement aux requêtes de voir une vue ponctuelle d'une base de données et pour des sélections sans collision de verrouillage. C'est une vaste simplification, mais c'est suffisant pour mes besoins.
Pour faciliter ces niveaux d'isolement, l'équipe de développement de Microsoft que je dirigeais a mis en place un mécanisme appelé gestion des versions. Le fonctionnement de la gestion des versions est que chaque fois qu'un enregistrement change, la version avant modification de l'enregistrement est copiée dans le magasin de versions dans tempdb, et l'enregistrement modifié reçoit une balise de version de 14 octets ajoutée à la fin. La balise contient un pointeur vers la version précédente de l'enregistrement, ainsi qu'un horodatage qui peut être utilisé pour déterminer quelle est la version correcte d'un enregistrement pour une requête particulière à lire. Encore une fois, énormément simplifié, mais c'est seulement l'ajout des 14 octets qui nous intéresse.
Ainsi, chaque fois qu'un enregistrement change lorsque l'un de ces niveaux d'isolement est en vigueur, il peut s'étendre de 14 octets s'il n'y a pas déjà de balise de version pour l'enregistrement. Que faire s'il n'y a pas assez d'espace pour les 14 octets supplémentaires sur la page feuille d'index ? C'est vrai, un fractionnement de page se produira, provoquant une fragmentation.
Un gros problème, pourriez-vous penser, car l'enregistrement change de toute façon, donc s'il changeait de taille de toute façon, une division de page se serait probablement produite. Non - cette logique n'est valable que si la modification de l'enregistrement visait à augmenter la taille d'une colonne de longueur variable. Une balise de version sera ajoutée même si une colonne de longueur fixe est mise à jour !
C'est vrai - lorsque la gestion des versions est en jeu, les mises à jour des colonnes de longueur fixe peuvent entraîner l'expansion d'un enregistrement, entraînant potentiellement une division et une fragmentation de la page. Ce qui est encore plus intéressant, c'est qu'une suppression ajoutera également la balise de 14 octets, donc une suppression dans un index clusterisé pourrait provoquer une division de page lorsque la gestion des versions est utilisée !
L'essentiel ici est que l'activation de l'une ou l'autre forme d'isolement d'instantané peut entraîner une fragmentation soudaine dans les index clusterisés où il n'y avait auparavant aucune possibilité de fragmentation.
Fragmentation à partir de secondaires lisibles
Le dernier cas dont je souhaite discuter est l'utilisation de secondaires lisibles, une partie de la fonctionnalité de groupe de disponibilité qui a été ajoutée dans SQL Server 2012.
Lorsque vous activez un secondaire lisible, toutes les requêtes que vous effectuez sur le réplica secondaire sont converties en utilisant l'isolement d'instantané sous les couvertures. Cela empêche les requêtes de bloquer la relecture constante des enregistrements de journal à partir du réplica principal, car le code de récupération acquiert des verrous au fur et à mesure.
Pour ce faire, il doit y avoir des balises de version de 14 octets sur les enregistrements du réplica secondaire. Il y a un problème, car toutes les répliques doivent être identiques pour que la relecture du journal fonctionne. Eh bien, pas tout à fait. Le contenu de la balise de version n'est pas pertinent car il n'est utilisé que sur l'instance qui l'a créé. Mais le réplica secondaire ne peut pas ajouter de balises de version, ce qui allongerait les enregistrements, car cela modifierait la disposition physique des enregistrements sur une page et interromprait la relecture du journal. Si les balises de version étaient déjà présentes, elles pourraient utiliser l'espace sans rien casser.
C'est donc exactement ce qui se passe. Le moteur de stockage s'assure que toutes les balises de version nécessaires pour le réplica secondaire sont déjà là, en les ajoutant sur le réplica principal !
Dès qu'un réplica secondaire lisible d'une base de données est créé, toute mise à jour d'un enregistrement dans le réplica principal entraîne l'ajout d'une balise vide de 14 octets à l'enregistrement, de sorte que les 14 octets soient correctement pris en compte dans tous les enregistrements de journal. . La balise n'est utilisée pour rien (sauf si l'isolation d'instantané est activée sur le réplica principal lui-même), mais le fait qu'elle soit créée entraîne l'expansion de l'enregistrement, et si la page est déjà pleine, alors…
Oui, l'activation d'un secondaire lisible provoque le même effet sur le réplica principal que si vous y activiez l'isolement d'instantané :la fragmentation.
Résumé
Ne pensez pas que parce que vous évitez d'utiliser des GUID comme clés de cluster et que vous évitez de mettre à jour des colonnes de longueur variable dans vos tables, vos index clusterisés seront immunisés contre la fragmentation. Comme je l'ai décrit ci-dessus, il existe d'autres facteurs de charge de travail et environnementaux qui peuvent causer des problèmes de fragmentation dans vos index clusterisés dont vous devez être conscient.
Maintenant, ne vous précipitez pas et pensez que vous ne devriez pas supprimer d'enregistrements, ne devriez pas utiliser l'isolement d'instantané et ne devriez pas utiliser de secondaires lisibles. Vous devez juste être conscient qu'ils peuvent tous provoquer une fragmentation et savoir comment la détecter, la supprimer et l'atténuer.
SQL Sentry dispose d'un outil sympa, Fragmentation Manager, que vous pouvez utiliser comme module complémentaire de Performance Advisor pour vous aider à déterminer où se trouvent les problèmes de fragmentation, puis à les résoudre. Vous pourriez être surpris de la fragmentation que vous constaterez lorsque vous vérifierez ! À titre d'exemple rapide, ici, je peux voir visuellement - jusqu'au niveau de la partition individuelle - la quantité de fragmentation existante, la rapidité avec laquelle elle est devenue ainsi, tous les modèles qui existent et l'impact réel qu'elle a sur la mémoire gaspillée dans le système :
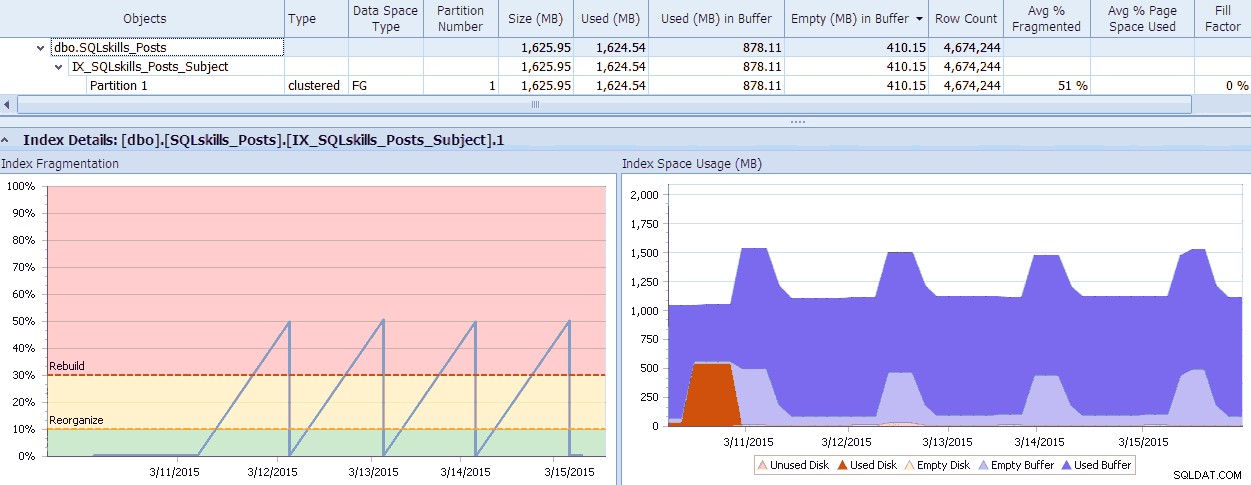 Données SQL Sentry Fragmentation Manager (cliquez pour agrandir)
Données SQL Sentry Fragmentation Manager (cliquez pour agrandir)
Dans mon prochain article, je discuterai davantage de la fragmentation et de la manière de l'atténuer pour la rendre moins problématique.