En mars, j'ai commencé une série sur les mythes omniprésents en matière de performances dans SQL Server. Une croyance que je rencontre de temps en temps est que vous pouvez surdimensionner les colonnes varchar ou nvarchar sans aucune pénalité.
Supposons que vous stockiez des adresses e-mail. Dans une vie antérieure, j'ai beaucoup traité de cela - à l'époque, la RFC 3696 stipulait qu'une adresse e-mail pouvait comporter 320 caractères (64 caractères @ 255 caractères). Une RFC plus récente, #5321, reconnaît désormais que 254 caractères est la longueur maximale d'une adresse e-mail. Et si l'un d'entre vous a une adresse aussi longue, eh bien, on devrait peut-être discuter. :-)
Maintenant, que vous suiviez l'ancienne norme ou la nouvelle, vous devez prendre en charge la possibilité que quelqu'un utilise tous les caractères autorisés. Ce qui signifie que vous devez utiliser 254 ou 320 caractères. Mais ce que j'ai vu des gens faire, c'est ne pas se soucier du tout de rechercher la norme et supposer simplement qu'ils doivent prendre en charge 1 000 caractères, 4 000 caractères ou même plus.
Examinons donc ce qui se passe lorsque nous avons des tables avec une colonne d'adresse e-mail de taille variable, mais stockant exactement les mêmes données :
CREATE TABLE dbo.Email_V320 ( id int IDENTITY PRIMARY KEY, email varchar(320) ); CREATE TABLE dbo.Email_V1000 ( id int IDENTITY PRIMARY KEY, email varchar(1000) ); CREATE TABLE dbo.Email_V4000 ( id int IDENTITY PRIMARY KEY, email varchar(4000) ); CREATE TABLE dbo.Email_Vmax ( id int IDENTITY PRIMARY KEY, email varchar(max) );
Maintenant, générons 10 000 adresses e-mail fictives à partir des métadonnées système et remplissons les quatre tables avec les mêmes données :
INSERT dbo.Email_V320(email) SELECT TOP (10000) REPLACE(LEFT(LEFT(c.name, 64) + '@' + LEFT(o.name, 128) + '.com', 254), ' ', '') FROM sys.all_columns AS c INNER JOIN sys.all_objects AS o ON c.[object_id] = o.[object_id] INNER JOIN sys.all_columns AS c2 ON c.[object_id] = c2.[object_id] ORDER BY NEWID(); INSERT dbo.Email_V1000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_V4000(email) SELECT email FROM dbo.Email_V320; INSERT dbo.Email_Vmax (email) SELECT email FROM dbo.Email_V320; -- let's rebuild ALTER INDEX ALL ON dbo.Email_V320 REBUILD; ALTER INDEX ALL ON dbo.Email_V1000 REBUILD; ALTER INDEX ALL ON dbo.Email_V4000 REBUILD; ALTER INDEX ALL ON dbo.Email_Vmax REBUILD;
Pour valider que chaque table contient exactement les mêmes données :
SELECT AVG(LEN(email)), MAX(LEN(email)) FROM dbo.Email_<size>;
Tous les quatre donnent 35 et 77 pour moi; Votre kilométrage peut varier. Assurons-nous également que les quatre tables occupent le même nombre de pages sur le disque :
SELECT o.name, COUNT(p.[object_id])
FROM sys.objects AS o
CROSS APPLY sys.dm_db_database_page_allocations
(DB_ID(), o.object_id, 1, NULL, 'LIMITED') AS p
WHERE o.name LIKE N'Email[_]V[^2]%'
GROUP BY o.name; Ces quatre requêtes génèrent 89 pages (encore une fois, votre kilométrage peut varier).
Prenons maintenant une requête typique qui aboutit à une analyse d'index cluster :
SELECT id, email FROM dbo.Email_<size>;
Si nous examinons des éléments tels que la durée, les lectures et les coûts estimés, ils semblent tous identiques :
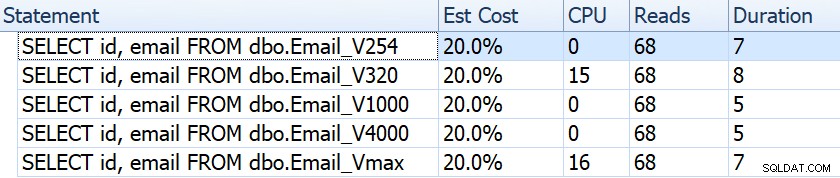
Cela peut endormir les gens dans une fausse hypothèse selon laquelle il n'y a aucun impact sur les performances. Mais si nous regardons d'un peu plus près, sur l'info-bulle de l'analyse de l'index clusterisé dans chaque plan, nous voyons une différence qui peut entrer en jeu dans d'autres requêtes plus élaborées :

À partir de là, nous voyons que plus la définition de colonne est grande, plus la taille estimée de la ligne et des données est élevée. Dans cette requête simple, le coût d'E/S (0,0512731) est le même pour toutes les requêtes, quelle que soit leur définition, car le parcours d'index clusterisé doit de toute façon lire toutes les données.
Mais il existe d'autres scénarios où cette estimation de ligne et la taille totale des données auront un impact :les opérations qui nécessitent des ressources supplémentaires, telles que les tris. Prenons cette requête ridicule qui ne sert à rien d'autre que de nécessiter plusieurs opérations de tri :
SELECT /* V<size> */ ROW_NUMBER() OVER (PARTITION BY email ORDER BY email DESC),
email, REVERSE(email), SUBSTRING(email, 1, CHARINDEX('@', email))
FROM dbo.Email_V<size>
GROUP BY REVERSE(email), email, SUBSTRING(email, 1, CHARINDEX('@', email))
ORDER BY REVERSE(email), email; Nous exécutons ces quatre requêtes et nous voyons que les plans ressemblent tous à ceci :

Cependant, cette icône d'avertissement sur l'opérateur SELECT n'apparaît que sur les tables 4000/max. Quel est l'avertissement ? Il s'agit d'un avertissement d'octroi de mémoire excessif, introduit dans SQL Server 2016. Voici l'avertissement pour varchar(4000) :

Et pour varchar(max):

Regardons d'un peu plus près et voyons ce qui se passe, du moins selon sys.dm_exec_query_stats :
SELECT [table] = SUBSTRING(t.[text], 1, CHARINDEX(N'*/', t.[text])), s.last_elapsed_time, s.last_grant_kb, s.max_ideal_grant_kb FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.[text] LIKE N'%/*%dbo.'+N'Email_V%' ORDER BY s.last_grant_kb;
Résultats :

Dans mon scénario, la durée n'a pas été affectée par les différences d'attribution de mémoire (sauf pour le cas max), mais vous pouvez clairement voir la progression linéaire qui coïncide avec la taille déclarée de la colonne. Que vous pouvez utiliser pour extrapoler ce qui se passerait sur un système avec une mémoire insuffisante. Ou une requête plus élaborée sur un ensemble de données beaucoup plus volumineux. Ou une concurrence importante. N'importe lequel de ces scénarios pourrait nécessiter des déversements afin de traiter les opérations de tri, et la durée en serait presque certainement affectée.
Mais d'où viennent ces allocations de mémoire plus importantes ? N'oubliez pas qu'il s'agit de la même requête, avec exactement les mêmes données. Le problème est que, pour certaines opérations, SQL Server doit prendre en compte la quantité de données *peut* se trouver dans une colonne. Il ne le fait pas sur la base du profilage réel des données, et il ne peut faire aucune hypothèse basée sur les valeurs de pas d'histogramme <=201. Au lieu de cela, il doit estimer que chaque ligne contient une valeur égale à la moitié de la taille de colonne déclarée . Ainsi, pour un varchar(4000), il suppose que chaque adresse e-mail comporte 2 000 caractères.
Lorsqu'il n'est pas possible d'avoir une adresse e-mail de plus de 254 ou 320 caractères, il n'y a rien à gagner à surdimensionner, et il y a potentiellement beaucoup à perdre. Augmenter ultérieurement la taille d'une colonne à largeur variable est beaucoup plus facile que de gérer tous les inconvénients maintenant.
Bien sûr, surdimensionner char ou nchar les colonnes peuvent avoir des pénalités beaucoup plus évidentes.