
Bien trop souvent, je vois des gens se plaindre de la façon dont leur journal des transactions a pris le contrôle de leur disque dur. Souvent, il s'avère qu'ils effectuaient une opération de suppression importante, telle que la purge ou l'archivage de données, en une seule transaction importante.
Je voulais exécuter des tests pour montrer l'impact, à la fois sur la durée et sur le journal des transactions, de l'exécution de la même opération de données en morceaux par rapport à une seule transaction. J'ai créé une base de données et je l'ai remplie avec une grande table SalesOrderDetailEnlarged ,
Après avoir rempli la table, j'ai sauvegardé la base de données, sauvegardé le journal et exécuté un DBCC SHRINKFILE (ne me tirez pas dessus) afin que l'impact sur le fichier journal puisse être établi à partir d'une ligne de base (sachant très bien que ces opérations *va* faire grossir le journal des transactions).
J'ai volontairement utilisé un disque mécanique plutôt qu'un SSD. Bien que nous puissions commencer à voir une tendance plus populaire à passer au SSD, cela ne s'est pas encore produit à une échelle suffisamment grande; dans de nombreux cas, il est encore trop coûteux de le faire dans de grands périphériques de stockage.
Les épreuves
Donc, ensuite, j'ai dû déterminer ce que je voulais tester pour le plus grand impact. Depuis que j'ai participé hier à une discussion avec un collègue sur la suppression de données par blocs, j'ai choisi les suppressions. Et puisque l'index clusterisé sur cette table est sur SalesOrderID , je ne voulais pas l'utiliser - ce serait trop facile (et correspondrait très rarement à la façon dont les suppressions sont gérées dans la vraie vie). J'ai donc décidé d'aller chercher une série de ProductID valeurs, ce qui garantirait que j'atteindrais un grand nombre de pages et nécessiterait beaucoup de journalisation. J'ai déterminé les produits à supprimer par la requête suivante :
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
Cela a donné les résultats suivants :
ProductID ProductCount --------- ------------ 870 187520 712 135280 873 134160
Cela supprimerait 456 960 lignes (environ 10 % du tableau), réparties sur de nombreuses commandes. Ce n'est pas une modification réaliste dans ce contexte, car cela perturbera les totaux de commande pré-calculés, et vous ne pouvez pas vraiment supprimer un produit d'une commande qui a déjà été expédiée. Mais utiliser une base de données que nous connaissons et aimons tous revient à, par exemple, supprimer un utilisateur d'un site de forum et également supprimer tous ses messages - un scénario réel que j'ai vu dans la nature.
Un test consisterait donc à effectuer la suppression unique suivante :
DELETE dbo.SalesOrderDetailEnlarged WHERE ProductID IN (712, 870, 873);
Je sais que cela va nécessiter une analyse massive et peser lourdement sur le journal des transactions. C'est un peu le point. :-)
Pendant que cela fonctionnait, j'ai créé un script différent qui effectuera cette suppression par blocs :25 000, 50 000, 75 000 et 100 000 lignes à la fois. Chaque morceau sera validé dans sa propre transaction (de sorte que si vous avez besoin d'arrêter le script, vous le pouvez, et tous les morceaux précédents seront déjà validés, au lieu de devoir recommencer), et selon le modèle de récupération, sera suivi soit par un CHECKPOINT ou un BACKUP LOG pour minimiser l'impact continu sur le journal des transactions. (Je vais également tester sans ces opérations.) Cela ressemblera à ceci (je ne vais pas m'embêter avec la gestion des erreurs et autres subtilités pour ce test, mais vous ne devriez pas être aussi cavalier) :
SET NOCOUNT ON;
DECLARE @r INT;
SET @r = 1;
WHILE @r > 0
BEGIN
BEGIN TRANSACTION;
DELETE TOP (100000) -- this will change
dbo.SalesOrderDetailEnlarged
WHERE ProductID IN (712, 870, 873);
SET @r = @@ROWCOUNT;
COMMIT TRANSACTION;
-- CHECKPOINT; -- if simple
-- BACKUP LOG ... -- if full
END
Bien sûr, après chaque test, je restaurerais la sauvegarde originale de la base de données WITH REPLACE, RECOVERY , définissez le modèle de récupération en conséquence et exécutez le test suivant.
Les résultats
Le résultat du premier test n'était pas très surprenant du tout. Pour effectuer la suppression en une seule instruction, il a fallu 42 secondes en entier et 43 secondes en simple. Dans les deux cas, cela a fait passer le journal à 579 Mo.
La prochaine série de tests a eu quelques surprises pour moi. La première est que, bien que ces méthodes de segmentation aient considérablement réduit l'impact sur le fichier journal, seules quelques combinaisons se sont rapprochées en durée, et aucune n'était en fait plus rapide. Une autre est que, en général, la segmentation en récupération complète (sans effectuer de sauvegarde du journal entre les étapes) a donné de meilleurs résultats que les opérations équivalentes en récupération simple. Voici les résultats pour la durée et l'impact sur le journal :
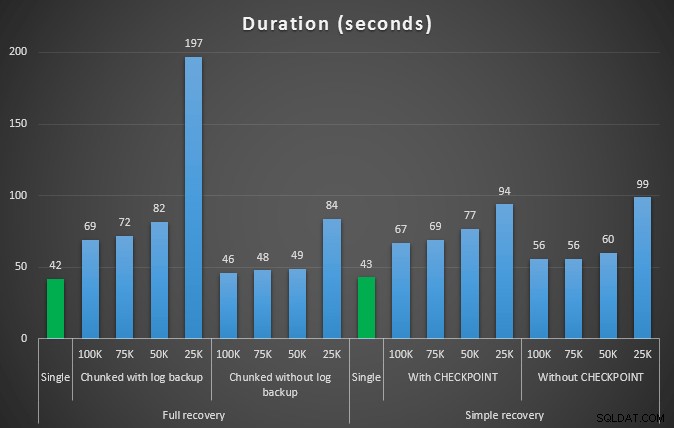
Durée, en secondes, de diverses opérations de suppression supprimant 457 000 lignes
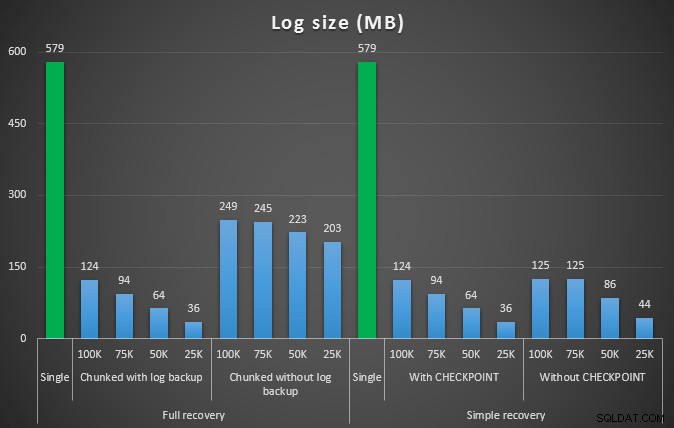
Taille du journal, en Mo, après diverses opérations de suppression supprimant 457 000 lignes
Encore une fois, en général, alors que la taille du journal est considérablement réduite, la durée est augmentée. Vous pouvez utiliser ce type d'échelle pour déterminer s'il est plus important de réduire l'impact sur l'espace disque ou de minimiser le temps passé. Pour une durée limitée (et après tout, la plupart de ces processus sont exécutés en arrière-plan), vous pouvez réaliser des économies significatives (jusqu'à 94 %, dans ces tests) dans l'utilisation de l'espace de journalisation.
Notez que je n'ai essayé aucun de ces tests avec la compression activée (peut-être un futur test !), Et j'ai laissé les paramètres de croissance automatique du journal aux terribles valeurs par défaut (10 %) - en partie par paresse et en partie parce que de nombreux environnements ont conservé ce cadre horrible.
Mais et si j'ai plus de données ?
Ensuite, j'ai pensé que je devrais tester cela sur une base de données légèrement plus grande. J'ai donc créé une autre base de données et créé une nouvelle copie plus grande de dbo.SalesOrderDetailEnlarged . Environ dix fois plus grand, en fait. Cette fois au lieu d'une clé primaire sur SalesOrderID, SalesorderDetailID , je viens d'en faire un index clusterisé (pour autoriser les doublons) et je l'ai rempli de cette façon :
SELECT c.*
INTO dbo.SalesOrderDetailReallyReallyEnlarged
FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged AS c
CROSS JOIN
(
SELECT TOP 10 Number FROM master..spt_values
) AS x;
CREATE CLUSTERED INDEX so ON dbo.SalesOrderDetailReallyReallyEnlarged
(SalesOrderID,SalesOrderDetailID);
-- I also made this index non-unique:
CREATE NONCLUSTERED INDEX rg ON dbo.SalesOrderDetailReallyReallyEnlarged(rowguid);
CREATE NONCLUSTERED INDEX p ON dbo.SalesOrderDetailReallyReallyEnlarged(ProductID); En raison des limitations d'espace disque, j'ai dû quitter la machine virtuelle de mon ordinateur portable pour ce test (et j'ai choisi une boîte à 40 cœurs, avec 128 Go de RAM, qui se trouvait juste en position quasi-inactive :-)), et toujours ce n'était en aucun cas un processus rapide. Le remplissage de la table et la création des index ont pris environ 24 minutes.
La table compte 48,5 millions de lignes et occupe 7,9 Go sur le disque (4,9 Go en données et 2,9 Go en index).
Cette fois, ma requête pour déterminer un bon ensemble de candidats ProductID valeurs à supprimer :
SELECT TOP (3) ProductID, ProductCount = COUNT(*) FROM dbo.SalesOrderDetailReallyReallyEnlarged GROUP BY ProductID ORDER BY ProductCount DESC;
A donné les résultats suivants :
ProductID ProductCount --------- ------------ 870 1828320 712 1318980 873 1308060
Nous allons donc supprimer 4 455 360 lignes, soit un peu moins de 10 % du tableau. En suivant un schéma similaire au test ci-dessus, nous allons tout supprimer d'un seul coup, puis par tranches de 500 000, 250 000 et 100 000 lignes.
Résultats :
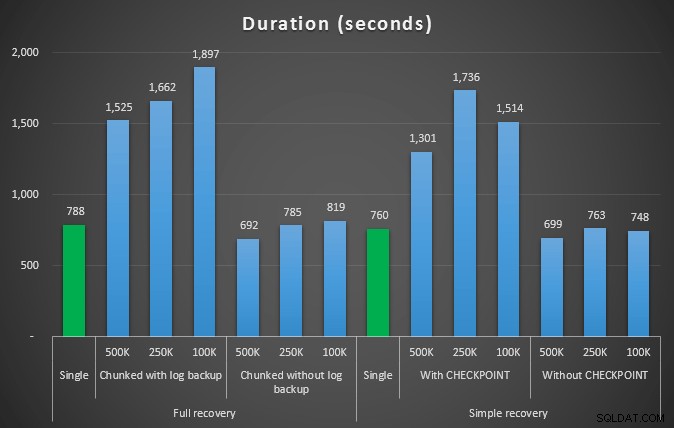 Durée, en secondes, de diverses opérations de suppression supprimant des lignes de 4,5 MM
Durée, en secondes, de diverses opérations de suppression supprimant des lignes de 4,5 MM
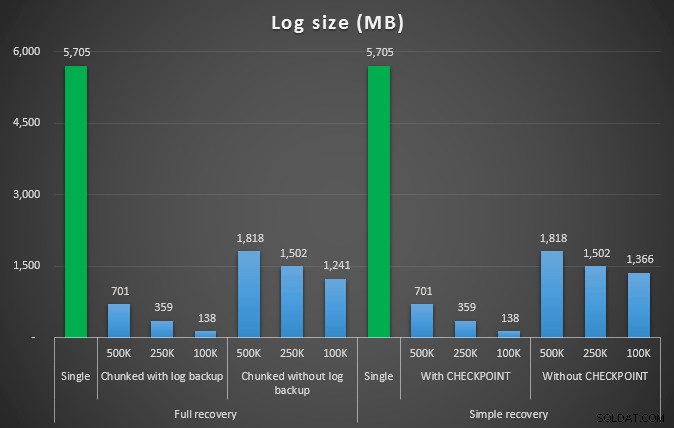 Taille du journal, en Mo, après diverses opérations de suppression supprimant 4,5 MM de lignes
Taille du journal, en Mo, après diverses opérations de suppression supprimant 4,5 MM de lignes
Encore une fois, nous constatons une réduction significative de la taille du fichier journal (plus de 97 % dans les cas avec la plus petite taille de bloc de 100 Ko) ; cependant, à cette échelle, nous voyons quelques cas où nous effectuons également la suppression en moins de temps, même avec tous les événements de croissance automatique qui ont dû se produire. Cela ressemble beaucoup à du gagnant-gagnant pour moi !
Cette fois avec un journal plus gros
Maintenant, j'étais curieux de savoir comment ces différentes suppressions se compareraient à un fichier journal pré-dimensionné pour s'adapter à des opérations aussi importantes. En m'en tenant à notre plus grande base de données, j'ai pré-étendu le fichier journal à 6 Go, l'ai sauvegardé, puis j'ai recommencé les tests :
ALTER DATABASE delete_test MODIFY FILE (NAME=delete_test_log, SIZE=6000MB);
Résultats, comparant la durée avec un fichier journal fixe au cas où le fichier devait croître automatiquement en continu :
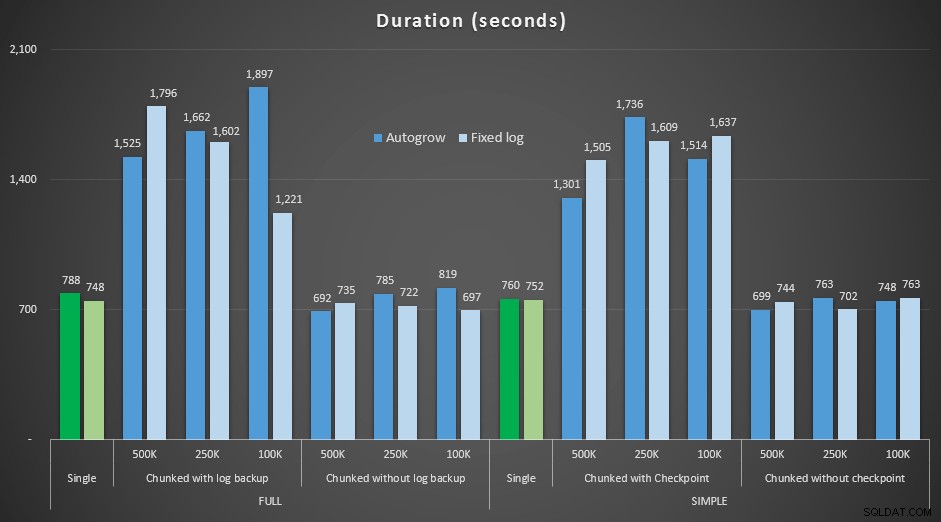
Durée, en secondes, de diverses opérations de suppression supprimant des lignes de 4,5 MM , en comparant la taille fixe du journal et la croissance automatique
Encore une fois, nous voyons que les méthodes qui suppriment par lots et n'effectuent *pas* de sauvegarde de journal ou de point de contrôle après chaque étape, rivalisent avec l'opération unique équivalente en termes de durée. En fait, voyez que la plupart s'exécutent en moins de temps global, avec l'avantage supplémentaire que d'autres transactions pourront entrer et sortir entre les étapes. Ce qui est une bonne chose, sauf si vous souhaitez que cette opération de suppression bloque toutes les transactions non liées.
Conclusion
Il est clair qu'il n'y a pas de réponse unique et correcte à ce problème - il y a beaucoup de variables inhérentes "ça dépend". Cela peut prendre quelques expériences pour trouver votre nombre magique, car il y aura un équilibre entre la surcharge nécessaire pour sauvegarder le journal et la quantité de travail et de temps que vous économisez à différentes tailles de blocs. Mais si vous envisagez de supprimer ou d'archiver un grand nombre de lignes, il est fort probable que vous feriez mieux, dans l'ensemble, d'effectuer les modifications par blocs, plutôt qu'en une seule transaction massive - même si les nombres de durée semblent faire qu'une opération moins attrayante. Ce n'est pas qu'une question de durée - si vous n'avez pas un fichier journal suffisamment pré-alloué et que vous n'avez pas l'espace pour accueillir une transaction aussi massive, il est probablement préférable de minimiser la croissance du fichier journal au détriment de la durée, dans ce cas, vous devrez ignorer les graphiques de durée ci-dessus et faire attention aux graphiques de taille de journal.
Si vous pouvez vous permettre l'espace, vous pouvez toujours ou non pré-dimensionner votre journal des transactions en conséquence. Selon le scénario, l'utilisation des paramètres de croissance automatique par défaut s'est parfois avérée légèrement plus rapide dans mes tests que l'utilisation d'un fichier journal fixe avec beaucoup d'espace. De plus, il peut être difficile de deviner exactement combien vous aurez besoin pour effectuer une transaction importante que vous n'avez pas encore exécutée. Si vous ne pouvez pas tester un scénario réaliste, faites de votre mieux pour imaginer votre pire scénario – puis, par sécurité, doublez-le. Kimberly Tripp (blog | @KimberlyLTripp) a quelques bons conseils dans cet article :8 étapes pour améliorer le débit du journal des transactions - dans ce contexte, en particulier, regardez le point #6. Quelle que soit la façon dont vous décidez de calculer vos besoins en espace de journalisation, si vous avez de toute façon besoin d'espace, mieux vaut le prendre de manière contrôlée bien à l'avance, plutôt que d'arrêter vos processus métier en attendant une croissance automatique ( tant pis pour plusieurs !).
Un autre aspect très important de cela que je n'ai pas mesuré explicitement est l'impact sur la simultanéité - un groupe de transactions plus courtes aura, en théorie, moins d'impact sur les opérations simultanées. Alors qu'une seule suppression prenait un peu moins de temps que les opérations par lots plus longues, elle conservait tous ses verrous pendant toute cette durée, tandis que les opérations fragmentées permettaient à d'autres transactions en file d'attente de se faufiler entre chaque transaction. Dans un prochain article, j'essaierai d'examiner de plus près cet impact (et j'ai également des plans pour d'autres analyses plus approfondies).



