Cet article est le troisième volet d'une série sur les complexités NULL. Dans la partie 1, j'ai couvert la signification du marqueur NULL et son comportement dans les comparaisons. Dans la partie 2, j'ai décrit les incohérences de traitement NULL dans différents éléments de langage. Ce mois-ci, je décris les puissantes fonctionnalités de gestion NULL standard qui n'ont pas encore été intégrées à T-SQL, ainsi que les solutions de contournement que les gens utilisent actuellement.
Je vais continuer à utiliser l'exemple de base de données TSQLV5 comme le mois dernier dans certains de mes exemples. Vous pouvez trouver le script qui crée et remplit cette base de données ici, et son diagramme ER ici.
Prédicat DISTINCT
Dans la partie 1 de la série, j'ai expliqué comment les valeurs NULL se comportent dans les comparaisons et les complexités autour de la logique de prédicat à trois valeurs utilisée par SQL et T-SQL. Considérez le prédicat suivant :
X =YSi un prédicande est NULL — y compris lorsque les deux sont NULL — le résultat de ce prédicat est la valeur logique UNKNOWN. À l'exception des opérateurs IS NULL et IS NOT NULL, il en va de même pour tous les autres opérateurs, y compris différent de (<>) :
X <> YSouvent, dans la pratique, vous souhaitez que les valeurs NULL se comportent comme des valeurs non NULL à des fins de comparaison. C'est particulièrement le cas lorsque vous les utilisez pour représenter manquant mais inapplicable valeurs. La norme a une solution à ce besoin sous la forme d'une fonctionnalité appelée le prédicat DISTINCT, qui utilise la forme suivante :
Au lieu d'utiliser une sémantique d'égalité ou d'inégalité, ce prédicat utilise une sémantique basée sur la distinction lors de la comparaison de prédicandes. Comme alternative à un opérateur d'égalité (=), vous utiliseriez la forme suivante pour obtenir un TRUE lorsque les deux prédicandes sont identiques, y compris lorsqu'ils sont tous les deux NULL, et un FALSE lorsqu'ils ne le sont pas, y compris lorsque l'un est NULL et que le l'autre n'est pas :
X N'EST PAS DISTINCT DE YComme alternative à un différent de (<>), vous utiliseriez la forme suivante pour obtenir un TRUE lorsque les deux prédicandes sont différents, y compris lorsque l'un est NULL et l'autre non, et un FALSE lorsqu'ils sont identiques, y compris lorsque les deux sont NULL :
X EST DISTINCT DE YAppliquons le prédicat DISTINCT aux exemples que nous avons utilisés dans la partie 1 de la série. Rappelez-vous que vous deviez écrire une requête qui, étant donné un paramètre d'entrée @dt, renvoie les commandes qui ont été expédiées à la date d'entrée si elle n'est pas NULL, ou qui n'ont pas été expédiées du tout si l'entrée est NULL. Selon la norme, vous utiliseriez le code suivant avec le prédicat DISTINCT pour gérer ce besoin :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
Pour l'instant, rappelez-vous de la partie 1 que vous pouvez utiliser une combinaison du prédicat EXISTS et de l'opérateur INTERSECT comme solution de contournement SARGable dans T-SQL, comme ceci :
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Pour renvoyer les commandes qui ont été expédiées à une date différente de (distincte de) la date d'entrée @dt, vous utiliserez la requête suivante :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
La solution de contournement qui fonctionne dans T-SQL utilise une combinaison du prédicat EXISTS et de l'opérateur EXCEPT, comme ceci :
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Dans la partie 1, j'ai également abordé des scénarios dans lesquels vous devez joindre des tables et appliquer une sémantique basée sur la distinction dans le prédicat de jointure. Dans mes exemples, j'ai utilisé des tables appelées T1 et T2, avec des colonnes de jointure NULLables appelées k1, k2 et k3 des deux côtés. Selon la norme, vous utiliseriez le code suivant pour gérer une telle jointure :
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
Pour l'instant, comme pour les tâches de filtrage précédentes, vous pouvez utiliser une combinaison du prédicat EXISTS et de l'opérateur INTERSECT dans la clause ON de la jointure pour émuler le prédicat distinct dans T-SQL, comme ceci :
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Lorsqu'il est utilisé dans un filtre, ce formulaire est SARGable, et lorsqu'il est utilisé dans des jointures, ce formulaire peut potentiellement s'appuyer sur l'ordre de l'index.
Si vous souhaitez voir le prédicat DISTINCT ajouté à T-SQL, vous pouvez voter ici.
Si après avoir lu cette section, vous vous sentez toujours un peu mal à l'aise avec le prédicat DISTINCT, vous n'êtes pas seul. Peut-être que ce prédicat est bien meilleur que n'importe quelle solution de contournement existante que nous avons actuellement dans T-SQL, mais c'est un peu verbeux et un peu déroutant. Il utilise une forme négative pour appliquer ce qui, dans notre esprit, est une comparaison positive, et vice versa. Eh bien, personne n'a dit que toutes les suggestions standard étaient parfaites. Comme Charlie l'a noté dans l'un de ses commentaires sur la partie 1, le formulaire simplifié suivant fonctionnerait mieux :
C'est concis et beaucoup plus intuitif. Au lieu de X N'EST PAS DISTINCT DE Y, vous utiliseriez :
X EST YEt au lieu de X EST DISTINCT DE Y, vous utiliseriez :
X N'EST PAS YCet opérateur proposé est en fait aligné sur les opérateurs IS NULL et IS NOT NULL déjà existants.
Appliqué à notre tâche de requête, pour renvoyer les commandes qui ont été expédiées à la date d'entrée (ou qui n'ont pas été expédiées si l'entrée est NULL), vous utiliserez le code suivant :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
Pour retourner des commandes qui ont été expédiées à une date différente de la date saisie, vous utiliserez le code suivant :
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Si Microsoft décide un jour d'ajouter le prédicat distinct, il serait bon qu'il prenne en charge à la fois la forme verbeuse standard et cette forme non standard mais plus concise et plus intuitive. Curieusement, le processeur de requêtes de SQL Server prend déjà en charge un opérateur de comparaison interne IS, qui utilise la même sémantique que l'opérateur IS souhaité que j'ai décrit ici. Vous pouvez trouver des détails sur cet opérateur dans l'article de Paul White Plans de requête non documentés :comparaisons d'égalité (recherche "IS au lieu de EQ"). Ce qui manque, c'est de l'exposer en externe dans le cadre de T-SQL.
Clause de traitement NULL (IGNORE NULLS | RESPECT NULLS)
Lorsque vous utilisez les fonctions de fenêtre de décalage LAG, LEAD, FIRST_VALUE et LAST_VALUE, vous devez parfois contrôler le comportement de traitement NULL. Par défaut, ces fonctions renvoient le résultat de l'expression demandée à la position demandée, que le résultat de l'expression soit une valeur réelle ou une valeur NULL. Cependant, vous souhaitez parfois continuer à vous déplacer dans la direction appropriée (en arrière pour LAG et LAST_VALUE, en avant pour LEAD et FIRST_VALUE) et renvoyer la première valeur non NULL si elle est présente, et NULL sinon. La norme vous donne le contrôle sur ce comportement en utilisant une clause de traitement NULL avec la syntaxe suivante :
décalage_fonction(La valeur par défaut dans le cas où la clause de traitement NULL n'est pas spécifiée est l'option RESPECT NULLS, ce qui signifie renvoyer tout ce qui est présent dans la position demandée même si NULL. Malheureusement, cette clause n'est pas encore disponible dans T-SQL. Je vais fournir des exemples pour la syntaxe standard en utilisant les fonctions LAG et FIRST_VALUE, ainsi que des solutions de contournement qui fonctionnent dans T-SQL. Vous pouvez utiliser des techniques similaires si vous avez besoin de telles fonctionnalités avec LEAD et LAST_VALUE.
Comme exemple de données, j'utiliserai une table appelée T4 que vous créez et remplissez à l'aide du code suivant :
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Il existe une tâche courante consistant à renvoyer le dernier élément pertinent valeur. Un NULL dans col1 indique aucun changement dans la valeur, alors qu'une valeur non NULL indique une nouvelle valeur pertinente. Vous devez renvoyer la dernière valeur col1 non NULL en fonction de l'ordre des identifiants. En utilisant la clause de traitement NULL standard, vous géreriez la tâche comme suit :
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Voici le résultat attendu de cette requête :
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
Il existe une solution de contournement dans T-SQL, mais elle implique deux couches de fonctions de fenêtre et une expression de table.
Dans la première étape, vous utilisez la fonction de fenêtre MAX pour calculer une colonne appelée grp contenant la valeur maximale de l'identifiant jusqu'à présent lorsque col1 n'est pas NULL, comme ceci :
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Ce code génère la sortie suivante :
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Comme vous pouvez le voir, une valeur grp unique est créée chaque fois qu'il y a un changement dans la valeur col1.
Dans la deuxième étape, vous définissez un CTE basé sur la requête de la première étape. Ensuite, dans la requête externe, vous renvoyez la valeur maximale de col1 jusqu'à présent, dans chaque partition définie par grp. C'est la dernière valeur col1 non NULL. Voici le code complet de la solution :
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; De toute évidence, cela représente beaucoup plus de code et de travail que de simplement dire IGNORE_NULLS.
Un autre besoin courant est de renvoyer la première valeur pertinente. Dans notre cas, supposons que vous deviez renvoyer la première valeur col1 non NULL jusqu'à présent en fonction de l'ordre des identifiants. En utilisant la clause de traitement NULL standard, vous géreriez la tâche avec la fonction FIRST_VALUE et l'option IGNORE NULLS, comme ceci :
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Voici le résultat attendu de cette requête :
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
La solution de contournement dans T-SQL utilise une technique similaire à celle utilisée pour la dernière valeur non NULL, seulement au lieu d'une approche double-MAX, vous utilisez la fonction FIRST_VALUE au-dessus d'une fonction MIN.
Dans la première étape, vous utilisez la fonction de fenêtre MIN pour calculer une colonne appelée grp contenant la valeur minimale de l'identifiant jusqu'à présent lorsque col1 n'est pas NULL, comme ceci :
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Ce code génère la sortie suivante :
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
S'il y a des NULL présents avant la première valeur pertinente, vous vous retrouvez avec deux groupes - le premier avec le NULL comme valeur grp et le second avec le premier identifiant non NULL comme valeur grp.
Dans la deuxième étape, vous placez le code de la première étape dans une expression de table. Ensuite, dans la requête externe, vous utilisez la fonction FIRST_VALUE, partitionnée par grp, pour collecter la première valeur pertinente (non NULL) si elle est présente, et NULL sinon, comme ceci :
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Encore une fois, cela représente beaucoup de code et de travail par rapport à la simple utilisation de l'option IGNORE_NULLS.
Si vous pensez que cette fonctionnalité peut vous être utile, vous pouvez voter pour son inclusion dans T-SQL ici.
ORDER PAR NULLS D'ABORD | NULLS EN DERNIER
Lorsque vous commandez des données, que ce soit à des fins de présentation, de fenêtrage, de filtrage TOP/OFFSET-FETCH ou à toute autre fin, se pose la question de savoir comment les NULL doivent se comporter dans ce contexte ? Le standard SQL dit que les NULL doivent être triés ensemble avant ou après les non-NULL, et ils laissent à l'implémentation le soin de déterminer d'une manière ou d'une autre. Cependant, quel que soit le choix du fournisseur, il doit être cohérent. Dans T-SQL, les NULL sont classés en premier (avant les non-NULL) lors de l'utilisation de l'ordre croissant. Considérez la requête suivante comme exemple :
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Cette requête génère la sortie suivante :
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
La sortie montre que les commandes non expédiées, qui ont une date d'expédition NULL, commandent avant les commandes expédiées, qui ont une date d'expédition applicable existante.
Mais que se passe-t-il si vous avez besoin de NULL pour commander en dernier lors de l'utilisation de l'ordre croissant ? La norme ISO/IEC SQL prend en charge une clause que vous appliquez à une expression de tri contrôlant si les valeurs NULL sont classées en premier ou en dernier. La syntaxe de cette clause est :
Pour répondre à notre besoin, en renvoyant les commandes triées par leurs dates d'expédition, par ordre croissant, mais avec les commandes non expédiées renvoyées en dernier, puis par leurs ID de commande comme critère de départage, vous utiliseriez le code suivant :
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Malheureusement, cette clause de commande NULLS n'est pas disponible dans T-SQL.
Une solution de contournement courante que les gens utilisent dans T-SQL consiste à faire précéder l'expression de commande d'une expression CASE qui renvoie une constante avec une valeur de commande inférieure pour les valeurs non NULL que pour les valeurs NULL, comme ceci (nous appellerons cette solution Requête 1) :
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Cette requête génère la sortie souhaitée avec les valeurs NULL affichées en dernier :
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
Il existe un index de couverture défini sur la table Sales.Orders, avec la colonne shipdate comme clé. Cependant, de la même manière qu'une colonne de filtrage manipulée empêche la SARGabilité du filtre et la possibilité d'appliquer une recherche à un index, une colonne de tri manipulée empêche de s'appuyer sur le tri des index pour prendre en charge la clause ORDER BY de la requête. Par conséquent, SQL Server génère un plan pour la requête 1 avec un opérateur de tri explicite, comme illustré à la figure 1.
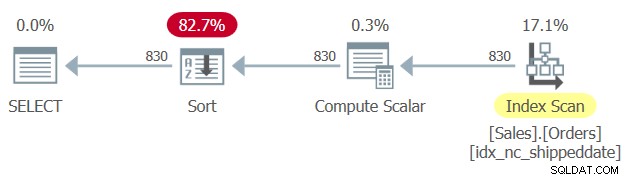 Figure 1 :Planifier la requête 1
Figure 1 :Planifier la requête 1
Parfois, la taille des données n'est pas si grande que le tri explicite pose problème. Mais parfois c'est le cas. Avec le tri explicite, l'évolutivité de la requête devient extra-linéaire (plus vous payez par ligne, plus vous avez de lignes), et le temps de réponse (le temps qu'il faut pour que la première ligne soit renvoyée) est retardé.
Il existe une astuce que vous pouvez utiliser pour éviter le tri explicite dans un tel cas avec une solution optimisée à l'aide d'un opérateur Merge Join Concatenation préservant l'ordre. Vous pouvez trouver une couverture détaillée de cette technique utilisée dans différents scénarios dans SQL Server :Éviter un tri avec fusion et concaténation. La première étape de la solution unifie les résultats de deux requêtes :une requête renvoyant les lignes où la colonne de tri n'est pas NULL avec une colonne de résultat (nous l'appellerons sortcol) basée sur une constante avec une valeur de tri, disons 0, et une autre requête renvoyant les lignes avec les valeurs NULL, avec sortcol défini sur une constante avec une valeur de classement supérieure à celle de la première requête, disons 1. Dans la deuxième étape, vous définissez ensuite une expression de table basée sur le code de la première étape, puis dans la requête externe, vous ordonnez d'abord les lignes de l'expression de table par sortcol, puis par les éléments de classement restants. Voici le code complet de la solution implémentant cette technique (nous appellerons cette solution Requête 2) :
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
Le plan de cette requête est illustré à la figure 2.
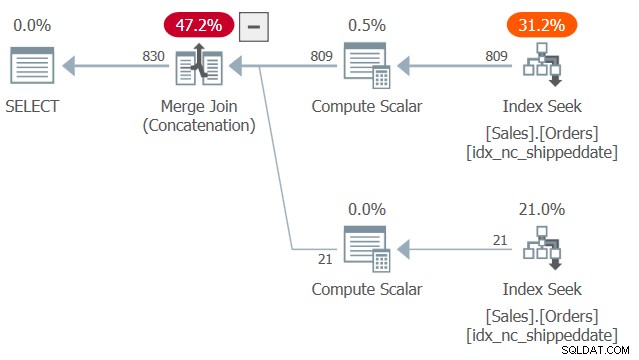 Figure 2 :Planifier la requête 2
Figure 2 :Planifier la requête 2
Remarquez deux recherches et balayages de plage ordonnés dans l'index de couverture idx_nc_shippeddate - l'un extrayant les lignes où shipdateis n'est pas NULL et l'autre extrayant les lignes où shipdate est NULL. Ensuite, de la même manière que l'algorithme Merge Join fonctionne dans une jointure, l'algorithme Merge Join (Concaténation) unifie les lignes des deux côtés ordonnés à la manière d'une fermeture éclair et préserve l'ordre ingéré pour prendre en charge les besoins d'ordre de présentation de la requête. Je ne dis pas que cette technique est toujours plus rapide que la solution plus typique avec l'expression CASE, qui utilise un tri explicite. Cependant, le premier a une échelle linéaire et le second a une échelle n log n. Ainsi, le premier aura tendance à mieux fonctionner avec un grand nombre de lignes et le second avec un petit nombre.
Évidemment, il est bon d'avoir une solution pour ce besoin commun, mais ce sera bien mieux si T-SQL ajoutait la prise en charge de la clause de commande NULL standard à l'avenir.
Conclusion
La norme ISO/IEC SQL contient de nombreuses fonctionnalités de gestion NULL qui n'ont pas encore été intégrées à T-SQL. Dans cet article, j'en ai couvert certains :le prédicat DISTINCT, la clause de traitement NULL et le contrôle de l'ordre des NULL en premier ou en dernier. J'ai également fourni des solutions de contournement pour ces fonctionnalités qui sont prises en charge dans T-SQL, mais elles sont évidemment fastidieuses. Le mois prochain, je poursuivrai la discussion en couvrant la contrainte unique standard, en quoi elle diffère de l'implémentation de T-SQL et les solutions de contournement qui peuvent être implémentées dans T-SQL.