N'importe quel programmeur vous dira qu'il peut être difficile d'écrire du code multithread sûr. Cela demande beaucoup de soin et une bonne compréhension des enjeux techniques. En tant que spécialiste des bases de données, vous pourriez penser que ces types de difficultés et de complications ne s'appliquent pas lors de l'écriture de T-SQL. Ainsi, il peut être un peu choquant de réaliser que le code T-SQL est également vulnérable au type de conditions de concurrence et autres risques d'intégrité des données les plus couramment associés à la programmation multithread. Cela est vrai, que nous parlions d'une seule instruction T-SQL ou d'un groupe d'instructions incluses dans une transaction explicite.
Au cœur du problème se trouve le fait que les systèmes de base de données permettent à plusieurs transactions de s'exécuter en même temps. Il s'agit d'un état de fait bien connu (et très souhaitable), mais une grande partie du code T-SQL de production suppose encore tranquillement que les données sous-jacentes ne changent pas pendant l'exécution d'une transaction ou d'une seule instruction DML comme SELECT , INSERT , UPDATE , DELETE , ou MERGE .
Même lorsque l'auteur du code est conscient des effets possibles des modifications simultanées des données, l'utilisation de transactions explicites est trop souvent supposée fournir plus de protection que ce qui est réellement justifié. Ces hypothèses et idées fausses peuvent être subtiles et sont certainement capables d'induire en erreur même les praticiens de bases de données expérimentés.
Maintenant, il y a des cas où ces questions n'auront pas beaucoup d'importance dans la pratique. Par exemple, la base de données peut être en lecture seule, ou il peut y avoir une autre garantie authentique que personne d'autre ne modifiera les données sous-jacentes pendant que nous travaillons dessus. De même, l'opération en question peut ne pas nécessiter des résultats qui sont exactement Corriger; nos consommateurs de données pourraient être parfaitement satisfaits d'un résultat approximatif (même s'il ne représente pas l'état engagé de la base de données à tout moment).
Problèmes de simultanéité
La question des interférences entre les tâches exécutées simultanément est un problème familier aux développeurs d'applications travaillant dans des langages de programmation comme C# ou Java. Les solutions sont nombreuses et variées, mais impliquent généralement l'utilisation d'opérations atomiques ou l'obtention d'une ressource mutuellement exclusive (telle qu'un verrou ) pendant qu'une opération sensible est en cours. Lorsque les précautions appropriées ne sont pas prises, les résultats probables sont des données corrompues, une erreur ou peut-être même un plantage complet.
De nombreux concepts identiques (par exemple, les opérations atomiques et les verrous) existent dans le monde des bases de données, mais malheureusement, ils ont souvent des différences de sens cruciales . La plupart des utilisateurs de bases de données connaissent les propriétés ACID des transactions de base de données, où le A signifie atomique . SQL Server utilise également des verrous (et autres dispositifs d'exclusion mutuelle en interne). Aucun de ces termes ne signifie tout à fait ce à quoi un programmeur C# ou Java expérimenté pourrait raisonnablement s'attendre, et de nombreux professionnels des bases de données ont également une compréhension confuse de ces sujets (comme en témoignera une recherche rapide à l'aide de votre moteur de recherche préféré).
Pour réitérer, parfois ces questions ne seront pas une préoccupation pratique. Si vous écrivez une requête pour compter le nombre de commandes actives dans un système de base de données, quelle est l'importance si le nombre est un peu décalé ? Ou s'il reflète l'état de la base de données à un autre moment ?
Il est courant que les systèmes réels fassent un compromis entre la concurrence et la cohérence (même si le concepteur n'en était pas conscient à l'époque - informé les compromis sont peut-être un animal plus rare). Les vrais systèmes fonctionnent souvent assez bien , avec des anomalies éphémères ou considérées comme sans importance. Un utilisateur voyant un état incohérent sur une page Web résoudra souvent le problème en actualisant la page. Si le problème est signalé, il sera très probablement classé comme non reproductible. Je ne dis pas que c'est une situation souhaitable, je reconnais simplement que cela se produit.
Néanmoins, il est extrêmement utile de comprendre les problèmes de concurrence à un niveau fondamental. En avoir connaissance nous permet d'écrire correctement (ou informé assez correct) T-SQL selon les circonstances. Plus important encore, cela nous permet d'éviter d'écrire du T-SQL qui pourrait compromettre l'intégrité logique de nos données.
Mais SQL Server offre des garanties ACID !
Oui, c'est le cas, mais ils ne correspondent pas toujours à ce que vous attendez et ils ne protègent pas tout. Le plus souvent, les humains lisent beaucoup plus dans ACID que ce qui est justifié.
Les composants les plus souvent mal compris de l'acronyme ACID sont les mots atomique, cohérent et isolé - nous y reviendrons dans un instant. L'autre, Durable , est assez intuitif tant que vous vous souvenez qu'il ne s'applique qu'à persistant (récupérable) utilisateur données.
Cela dit, SQL Server 2014 commence à brouiller quelque peu les limites de la propriété Durable avec l'introduction de la durabilité retardée générale et de la durabilité du schéma OLTP en mémoire uniquement. Je ne les mentionne que par souci d'exhaustivité, nous n'aborderons pas plus avant ces nouveautés. Passons aux propriétés ACID les plus problématiques :
La propriété atomique
De nombreux langages de programmation fournissent des opérations atomiques qui peut être utilisé pour se protéger contre les conditions de concurrence et d'autres effets de concurrence indésirables, où plusieurs threads d'exécution peuvent accéder ou modifier des structures de données partagées. Pour le développeur d'applications, une opération atomique est accompagnée d'une garantie explicite d'isolement complet des effets d'autres traitements simultanés dans un programme multithread.
Une situation analogue se présente dans le monde des bases de données, où plusieurs requêtes T-SQL accèdent et modifient simultanément des données partagées (c'est-à-dire la base de données) à partir de différents threads. Notez que nous ne parlons pas ici de requêtes parallèles ; les requêtes ordinaires à un seul thread sont régulièrement planifiées pour s'exécuter simultanément dans SQL Server sur des threads de travail distincts.
Malheureusement, la propriété atomique des transactions SQL garantit uniquement que les modifications de données effectuées dans une transaction réussissent ou échouent en tant qu'unité . Rien de plus que ça. Il n'y a certainement aucune garantie d'isolement complet des effets d'autres traitements simultanés. Notez également en passant que la propriété de transaction atomique ne dit rien sur les garanties de lecture données.
Relevés uniques
Il n'y a également rien de spécial à propos d'une instruction unique dans SQL Server. Où une transaction contenante explicite (BEGIN TRAN...COMMIT TRAN ) n'existe pas, une seule instruction DML s'exécute toujours dans une transaction de validation automatique. Les mêmes garanties ACID s'appliquent à un seul relevé, ainsi que les mêmes limitations. En particulier, une seule déclaration ne comporte aucune garantie particulière que les données ne changeront pas pendant qu'elle est en cours.
Considérez la requête jouet suivante d'AdventureWorks :
SELECT
TH.TransactionID,
TH.ProductID,
TH.ReferenceOrderID,
TH.ReferenceOrderLineID,
TH.TransactionDate,
TH.TransactionType,
TH.Quantity,
TH.ActualCost
FROM Production.TransactionHistory AS TH
WHERE TH.ReferenceOrderID =
(
SELECT TOP (1)
TH2.ReferenceOrderID
FROM Production.TransactionHistory AS TH2
WHERE TH2.TransactionType = N'P'
ORDER BY
TH2.Quantity DESC,
TH2.ReferenceOrderID ASC
); La requête est destinée à afficher des informations sur la commande qui est classée première par quantité. Le plan d'exécution est le suivant :
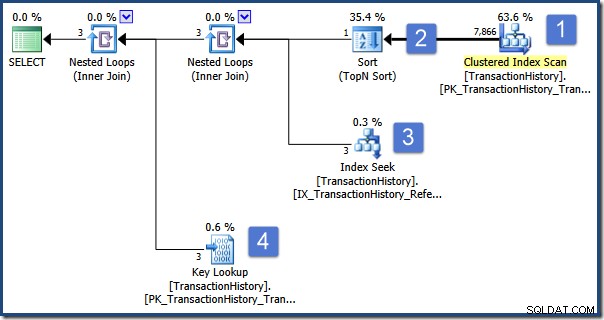
Les principales opérations de ce plan sont :
- Scanner le tableau pour trouver les lignes avec le type de transaction requis
- Trouvez l'ID de commande qui trie le plus haut selon la spécification dans la sous-requête
- Recherchez les lignes (dans la même table) avec l'ID de commande sélectionné à l'aide d'un index non clusterisé
- Rechercher les données de colonne restantes à l'aide de l'index clusterisé
Imaginez maintenant qu'un utilisateur simultané modifie la commande 495, changeant son type de transaction de P à W, et valide cette modification dans la base de données. Par chance, cette modification est effectuée pendant que notre requête effectue l'opération de tri (étape 2).
Lorsque le tri est terminé, la recherche d'index à l'étape 3 trouve les lignes avec l'ID de commande sélectionné (qui se trouve être 495) et la recherche de clé à l'étape 4 récupère les colonnes restantes de la table de base (où le type de transaction est maintenant W) .
Cette séquence d'événements signifie que notre requête produit un résultat apparemment impossible :

Au lieu de rechercher des commandes avec le type de transaction P comme requête spécifiée, les résultats affichent le type de transaction W.
La cause première est claire :notre requête supposait implicitement que les données ne pouvaient pas changer pendant que notre requête à instruction unique était en cours. La fenêtre d'opportunité dans ce cas était relativement grande en raison du tri bloquant, mais le même type de condition de concurrence peut se produire à n'importe quelle étape de l'exécution de la requête, en général. Naturellement, les risques sont généralement plus élevés avec des niveaux accrus de modifications simultanées, des tables plus volumineuses et l'apparition d'opérateurs bloquants dans le plan de requête.
Un autre mythe persistant dans le même domaine général est que MERGE doit être préféré à un INSERT séparé , UPDATE et DELETE car l'instruction unique MERGE est atomique. C'est un non-sens, bien sûr. Nous reviendrons sur ce type de raisonnement plus loin dans la série.
Le message général à ce stade est qu'à moins que des mesures explicites ne soient prises pour garantir le contraire, les lignes de données et les entrées d'index peuvent changer, changer de position ou disparaître entièrement à tout moment pendant le processus d'exécution. Une image mentale des changements constants et aléatoires dans la base de données est une bonne idée à garder à l'esprit lors de l'écriture de requêtes T-SQL.
La propriété de cohérence
Le deuxième mot de l'acronyme ACID a également une gamme d'interprétations possibles. Dans une base de données SQL Server, Cohérence signifie seulement qu'une transaction quitte la base de données dans un état qui ne viole aucune contrainte active. Il est important d'apprécier pleinement à quel point cette déclaration est limitée :les seules garanties ACID d'intégrité des données et de cohérence logique sont celles fournies par les contraintes actives.
SQL Server fournit une gamme limitée de contraintes pour appliquer l'intégrité logique, y compris PRIMARY KEY , FOREIGN KEY , CHECK , UNIQUE , et NOT NULL . Ceux-ci sont tous garantis d'être satisfaits au moment où une transaction est validée. De plus, SQL Server garantit le physique l'intégrité de la base de données à tout moment, bien sûr.
Les contraintes intégrées ne sont pas toujours suffisantes pour appliquer toutes les règles commerciales et d'intégrité des données que nous souhaitons. Il est certes possible d'être créatif avec les équipements standards, mais ceux-ci deviennent rapidement complexes et peuvent entraîner le stockage de données dupliquées.
Par conséquent, la plupart des bases de données réelles contiennent au moins quelques routines T-SQL écrites pour appliquer des règles supplémentaires, par exemple dans les procédures stockées et les déclencheurs. La responsabilité de s'assurer que ce code fonctionne correctement incombe entièrement à l'auteur - la propriété Consistency ne fournit aucune protection spécifique.
Pour souligner ce point, les pseudo-contraintes écrites en T-SQL doivent fonctionner correctement, quelles que soient les modifications simultanées pouvant se produire. Un développeur d'applications peut protéger une opération sensible comme celle-ci avec une instruction de verrouillage. La chose la plus proche que les programmeurs T-SQL ont de cette fonctionnalité pour les procédures stockées à risque et le code de déclenchement est le sp_getapplock relativement rarement utilisé. procédure stockée système. Cela ne veut pas dire qu'il s'agit de la seule option, ni même de l'option préférée, mais simplement qu'elle existe et peut être le bon choix dans certaines circonstances.
La propriété d'isolement
C'est de loin la propriété de transaction ACID la plus mal comprise.
En principe, un complètement isolé transaction s'exécute en tant que seule tâche s'exécutant sur la base de données pendant sa durée de vie. Les autres transactions ne peuvent démarrer qu'une fois que la transaction en cours est complètement terminée (c'est-à-dire validée ou annulée). Exécutée de cette façon, une transaction serait vraiment une opération atomique , au sens strict qu'une personne non spécialiste de la base de données attribuerait à l'expression.
En pratique, les transactions de base de données fonctionnent plutôt avec un degré d'isolement spécifié par le niveau d'isolation de transaction actuellement en vigueur (qui s'applique également aux instructions autonomes, rappelez-vous). Ce compromis (le degré d'isolement) est la conséquence pratique des compromis entre la concurrence et l'exactitude mentionnés précédemment. Un système qui traiterait littéralement les transactions une par une, sans chevauchement dans le temps, fournirait une isolation complète, mais le débit global du système serait probablement médiocre.
La prochaine fois
La prochaine partie de cette série continuera l'examen des problèmes de concurrence, des propriétés ACID et de l'isolation des transactions avec un aperçu détaillé du niveau d'isolation sérialisable, un autre exemple de quelque chose qui peut ne pas signifier ce que vous pensez.
[ Voir l'index pour toute la série ]