SQL Server a traditionnellement hésité à fournir des solutions natives à certaines des questions statistiques les plus courantes, telles que le calcul d'une médiane. Selon WikiPedia, "la médiane est décrite comme la valeur numérique séparant la moitié supérieure d'un échantillon, d'une population ou d'une distribution de probabilité, de la moitié inférieure. La médiane d'une liste finie de nombres peut être trouvée en organisant toutes les observations de de la valeur la plus basse à la valeur la plus élevée et en choisissant celle du milieu. S'il y a un nombre pair d'observations, alors il n'y a pas de valeur médiane unique ; la médiane est alors généralement définie comme étant la moyenne des deux valeurs médianes."
En termes de requête SQL Server, l'élément clé que vous en retirerez est que vous devez "organiser" (trier) toutes les valeurs. Le tri dans SQL Server est généralement une opération assez coûteuse s'il n'y a pas d'index de prise en charge, et l'ajout d'un index pour prendre en charge une opération qui n'est probablement pas demandée et qui peut souvent ne pas en valoir la peine.
Examinons comment nous avons généralement résolu ce problème dans les versions précédentes de SQL Server. Commençons par créer un tableau très simple afin que nous puissions constater que notre logique est correcte et dériver une médiane précise. Nous pouvons tester les deux tableaux suivants, l'un avec un nombre pair de lignes et l'autre avec un nombre impair de lignes :
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); En observant simplement, nous pouvons voir que la médiane pour le tableau avec des lignes impaires devrait être de 6, et pour le tableau pair, elle devrait être de 7,5 ((6+9)/2). Voyons maintenant quelques solutions qui ont été utilisées au fil des ans :
SQL Server 2000
Dans SQL Server 2000, nous étions contraints à un dialecte T-SQL très limité. J'étudie ces options à des fins de comparaison, car certaines personnes utilisent toujours SQL Server 2000 et d'autres ont peut-être mis à niveau, mais comme leurs calculs médians ont été écrits "à l'époque", le code pourrait encore ressembler à ceci aujourd'hui.
2000_A - max d'une moitié, min de l'autre
Cette approche prend la valeur la plus élevée des 50 premiers pour cent, la valeur la plus faible des 50 derniers pour cent, puis les divise par deux. Cela fonctionne pour les lignes paires ou impaires car, dans le cas pair, les deux valeurs sont les deux lignes du milieu, et dans le cas impair, les deux valeurs proviennent en fait de la même ligne.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #tableau temporaire
Cet exemple crée d'abord une table #temp et, en utilisant le même type de calcul que ci-dessus, détermine les deux lignes "du milieu" avec l'aide d'un IDENTITY contigu. colonne ordonnée par la colonne val. (L'ordre d'attribution de IDENTITY les valeurs ne peuvent être invoquées qu'en raison du MAXDOP réglage.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 a introduit de nouvelles fonctions de fenêtre intéressantes, telles que ROW_NUMBER() , ce qui peut aider à résoudre des problèmes statistiques comme la médiane un peu plus facilement que dans SQL Server 2000. Ces approches fonctionnent toutes dans SQL Server 2005 et versions ultérieures :
2005_A – numéros de ligne en duel
Cet exemple utilise ROW_NUMBER() pour monter et descendre les valeurs une fois dans chaque direction, puis trouve la ou les deux lignes "du milieu" en fonction de ce calcul. Ceci est assez similaire au premier exemple ci-dessus, avec une syntaxe plus simple :
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B - numéro de ligne + nombre
Celui-ci est assez similaire à celui ci-dessus, utilisant un seul calcul de ROW_NUMBER() puis en utilisant le total COUNT() pour trouver la ou les deux lignes "du milieu" :
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C - variation du nombre de lignes + nombre
Son collègue MVP Itzik Ben-Gan m'a montré cette méthode, qui donne la même réponse que les deux méthodes ci-dessus, mais d'une manière très légèrement différente :
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
Dans SQL Server 2012, nous avons de nouvelles fonctionnalités de fenêtrage dans T-SQL qui permettent d'exprimer plus directement des calculs statistiques comme la médiane. Pour calculer la médiane d'un ensemble de valeurs, nous pouvons utiliser PERCENTILE_CONT() . Nous pouvons également utiliser la nouvelle extension "paging" pour le ORDER BY clause (OFFSET / FETCH ).
2012_A – nouvelle fonctionnalité de distribution
Cette solution utilise un calcul très simple utilisant la distribution (si vous ne voulez pas la moyenne entre les deux valeurs médianes dans le cas d'un nombre pair de lignes).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B - astuce de pagination
Cet exemple implémente une utilisation intelligente de OFFSET / FETCH (et pas exactement celui pour lequel il était destiné) - nous passons simplement à la rangée qui est un avant la moitié du décompte, puis prenons la ou les deux rangées suivantes selon que le décompte était pair ou impair. Merci à Itzik Ben-Gan d'avoir signalé cette approche.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Mais lequel est le plus performant ?
Nous avons vérifié que les méthodes ci-dessus produisent toutes les résultats attendus sur notre petite table, et nous savons que la version SQL Server 2012 a la syntaxe la plus propre et la plus logique. Mais lequel devriez-vous utiliser dans votre environnement de production chargé ? Nous pouvons créer une table beaucoup plus grande à partir des métadonnées du système, en nous assurant d'avoir beaucoup de valeurs en double. Ce script produira une table avec 10 000 000 entiers non uniques :
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
Sur mon système, la médiane de ce tableau devrait être de 146 099 561. Je peux calculer cela assez rapidement sans vérification ponctuelle manuelle de 10 000 000 lignes en utilisant la requête suivante :
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Résultats :
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Nous pouvons donc maintenant créer une procédure stockée pour chaque méthode, vérifier que chacune produit la sortie correcte, puis mesurer les mesures de performances telles que la durée, le processeur et les lectures. Nous effectuerons toutes ces étapes avec la table existante, ainsi qu'avec une copie de la table qui ne bénéficie pas de l'index clusterisé (nous la supprimerons et recréerons la table sous forme de tas).
J'ai créé sept procédures implémentant les méthodes de requête ci-dessus. Par souci de brièveté, je ne les énumérerai pas ici, mais chacun est nommé dbo.Median_<version> , par exemple. dbo.Median_2000_A , dbo.Median_2000_B , etc. correspondant aux approches décrites ci-dessus. Si nous exécutons ces sept procédures à l'aide de l'explorateur de plans SQL Sentry gratuit, voici ce que nous observons en termes de durée, de CPU et de lectures (notez que nous exécutons DBCC FREEPROCCACHE et DBCC DROPCLEANBUFFERS entre les exécutions) :
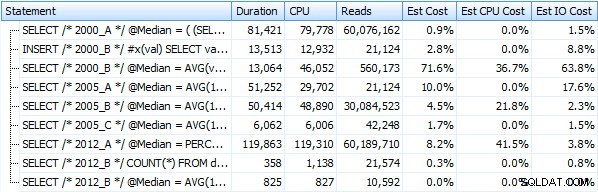
Et ces métriques ne changent pas beaucoup si nous opérons plutôt sur un tas. Le changement le plus important en pourcentage était la méthode qui s'est avérée être la plus rapide :l'astuce de pagination utilisant OFFSET/FETCH :
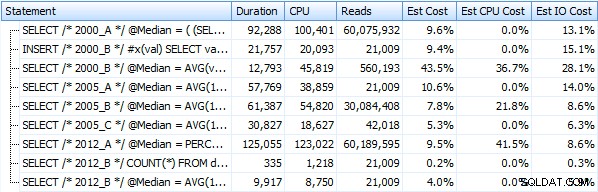
Voici une représentation graphique des résultats. Pour que ce soit plus clair, j'ai mis en surbrillance l'interprète le plus lent en rouge et l'approche la plus rapide en vert.
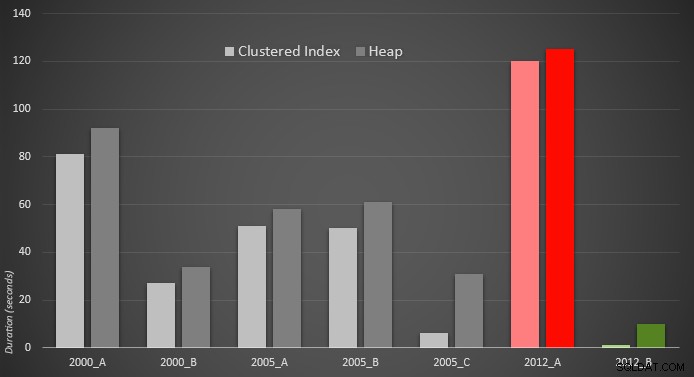
J'ai été surpris de voir que, dans les deux cas, PERCENTILE_CONT() – qui a été conçu pour ce type de calcul – est en fait pire que toutes les autres solutions antérieures. Je suppose que cela montre simplement que même si parfois une syntaxe plus récente peut faciliter notre codage, cela ne garantit pas toujours que les performances s'amélioreront. J'ai également été surpris de voir OFFSET / FETCH se révéler si utile dans des scénarios qui ne semblent généralement pas correspondre à son objectif - la pagination.
Dans tous les cas, j'espère avoir démontré quelle approche vous devez utiliser, en fonction de votre version de SQL Server (et que le choix doit être le même, que vous ayez ou non un index de support pour le calcul).



